 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCs-mri
Papers and Code
Scalable Hessian-free Proximal Conjugate Gradient Method for Nonconvex and Nonsmooth Optimization
Sep 19, 2025


This work studies a composite minimization problem involving a differentiable function q and a nonsmooth function h, both of which may be nonconvex. This problem is ubiquitous in signal processing and machine learning yet remains challenging to solve efficiently, particularly when large-scale instances, poor conditioning, and nonconvexity coincide. To address these challenges, we propose a proximal conjugate gradient method (PCG) that matches the fast convergence of proximal (quasi-)Newton algorithms while reducing computation and memory complexity, and is especially effective for spectrally clustered Hessians. Our key innovation is to form, at each iteration, an approximation to the Newton direction based on CG iterations to build a majorization surrogate. We define this surrogate in a curvature-aware manner and equip it with a CG-derived isotropic weight, guaranteeing majorization of a local second-order model of q along the given direction. To better preserve majorization after the proximal step and enable further approximation refinement, we scale the CG direction by the ratio between the Cauchy step length and a step size derived from the largest Ritz value of the CG tridiagonal. All curvature is accessed via Hessian-vector products computed by automatic differentiation, keeping the method Hessian-free. Convergence to first-order critical points is established. Numerical experiments on CS-MRI with nonconvex regularization and on dictionary learning, against benchmark methods, demonstrate the efficiency of the proposed approach.
GroupCDL: Interpretable Denoising and Compressed Sensing MRI via Learned Group-Sparsity and Circulant Attention
Jul 19, 2024



Nonlocal self-similarity within images has become an increasingly popular prior in deep-learning models. Despite their successful image restoration performance, such models remain largely uninterpretable due to their black-box construction. Our previous studies have shown that interpretable construction of a fully convolutional denoiser (CDLNet), with performance on par with state-of-the-art black-box counterparts, is achievable by unrolling a convolutional dictionary learning algorithm. In this manuscript, we seek an interpretable construction of a convolutional network with a nonlocal self-similarity prior that performs on par with black-box nonlocal models. We show that such an architecture can be effectively achieved by upgrading the L1 sparsity prior (soft-thresholding) of CDLNet to an image-adaptive group-sparsity prior (group-thresholding). The proposed learned group-thresholding makes use of nonlocal attention to perform spatially varying soft-thresholding on the latent representation. To enable effective training and inference on large images with global artifacts, we propose a novel circulant-sparse attention. We achieve competitive natural-image denoising performance compared to black-box nonlocal DNNs and transformers. The interpretable construction of our network allows for a straightforward extension to Compressed Sensing MRI (CS-MRI), yielding state-of-the-art performance. Lastly, we show robustness to noise-level mismatches between training and inference for denoising and CS-MRI reconstruction.
Adaptive Self-Supervised Consistency-Guided Diffusion Model for Accelerated MRI Reconstruction
Jun 21, 2024Purpose: To propose a self-supervised deep learning-based compressed sensing MRI (DL-based CS-MRI) method named "Adaptive Self-Supervised Consistency Guided Diffusion Model (ASSCGD)" to accelerate data acquisition without requiring fully sampled datasets. Materials and Methods: We used the fastMRI multi-coil brain axial T2-weighted (T2-w) dataset from 1,376 cases and single-coil brain quantitative magnetization prepared 2 rapid acquisition gradient echoes (MP2RAGE) T1 maps from 318 cases to train and test our model. Robustness against domain shift was evaluated using two out-of-distribution (OOD) datasets: multi-coil brain axial postcontrast T1 -weighted (T1c) dataset from 50 cases and axial T1-weighted (T1-w) dataset from 50 patients. Data were retrospectively subsampled at acceleration rates R in {2x, 4x, 8x}. ASSCGD partitions a random sampling pattern into two disjoint sets, ensuring data consistency during training. We compared our method with ReconFormer Transformer and SS-MRI, assessing performance using normalized mean squared error (NMSE), peak signal-to-noise ratio (PSNR), and structural similarity index (SSIM). Statistical tests included one-way analysis of variance (ANOVA) and multi-comparison Tukey's Honesty Significant Difference (HSD) tests. Results: ASSCGD preserved fine structures and brain abnormalities visually better than comparative methods at R = 8x for both multi-coil and single-coil datasets. It achieved the lowest NMSE at R in {4x, 8x}, and the highest PSNR and SSIM values at all acceleration rates for the multi-coil dataset. Similar trends were observed for the single-coil dataset, though SSIM values were comparable to ReconFormer at R in {2x, 8x}. These results were further confirmed by the voxel-wise correlation scatter plots. OOD results showed significant (p << 10^-5 ) improvements in undersampled image quality after reconstruction.
Single Image Compressed Sensing MRI via a Self-Supervised Deep Denoising Approach
Nov 22, 2023



Popular methods in compressed sensing (CS) are dependent on deep learning (DL), where large amounts of data are used to train non-linear reconstruction models. However, ensuring generalisability over and access to multiple datasets is challenging to realise for real-world applications. To address these concerns, this paper proposes a single image, self-supervised (SS) CS-MRI framework that enables a joint deep and sparse regularisation of CS artefacts. The approach effectively dampens structured CS artefacts, which can be difficult to remove assuming sparse reconstruction, or relying solely on the inductive biases of CNN to produce noise-free images. Image quality is thereby improved compared to either approach alone. Metrics are evaluated using Cartesian 1D masks on a brain and knee dataset, with PSNR improving by 2-4dB on average.
Finite Compressive Sensing
Sep 15, 2023



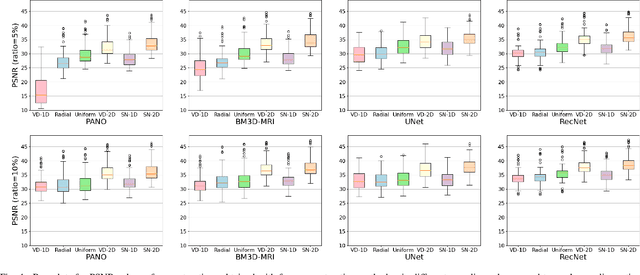
This paper introduces a sparse projection matrix composed of discrete (digital) periodic lines that create a pseudo-random (p.frac) sampling scheme. Our approach enables random Cartesian sampling whilst employing deterministic and one-dimensional (1D) trajectories derived from the discrete Radon transform (DRT). Unlike radial trajectories, DRT projections can be back-projected without interpolation. Thus, we also propose a novel reconstruction method based on the exact projections of the DRT called finite Fourier reconstruction (FFR). We term this combined p.frac and FFR strategy Finite Compressive Sensing (FCS), with image recovery demonstrated on experimental and simulated data; image quality comparisons are made with Cartesian random sampling in 1D and two-dimensional (2D), as well as radial under-sampling in a more constrained experiment. Our experiments indicate FCS enables 3-5dB gain in peak signal-to-noise ratio (PSNR) for 2-, 4- and 8-fold under-sampling compared to 1D Cartesian random sampling. This paper aims to: Review common sampling strategies for compressed sensing (CS)-magnetic resonance imaging (MRI) to inform the motivation of a projective and Cartesian sampling scheme. Compare the incoherence of these sampling strategies and the proposed p.frac. Compare reconstruction quality of the sampling schemes under various reconstruction strategies to determine the suitability of p.frac for CS-MRI. It is hypothesised that because p.frac is a highly incoherent sampling scheme, that reconstructions will be of high quality compared to 1D Cartesian phase-encode under-sampling.
Learning Task-Specific Strategies for Accelerated MRI
Apr 25, 2023



Compressed sensing magnetic resonance imaging (CS-MRI) seeks to recover visual information from subsampled measurements for diagnostic tasks. Traditional CS-MRI methods often separately address measurement subsampling, image reconstruction, and task prediction, resulting in suboptimal end-to-end performance. In this work, we propose TACKLE as a unified framework for designing CS-MRI systems tailored to specific tasks. Leveraging recent co-design techniques, TACKLE jointly optimizes subsampling, reconstruction, and prediction strategies to enhance the performance on the downstream task. Our results on multiple public MRI datasets show that the proposed framework achieves improved performance on various tasks over traditional CS-MRI methods. We also evaluate the generalization ability of TACKLE by experimentally collecting a new dataset using different acquisition setups from the training data. Without additional fine-tuning, TACKLE functions robustly and leads to both numerical and visual improvements.
Hybrid Parallel Imaging and Compressed Sensing MRI Reconstruction with GRAPPA Integrated Multi-loss Supervised GAN
Sep 19, 2022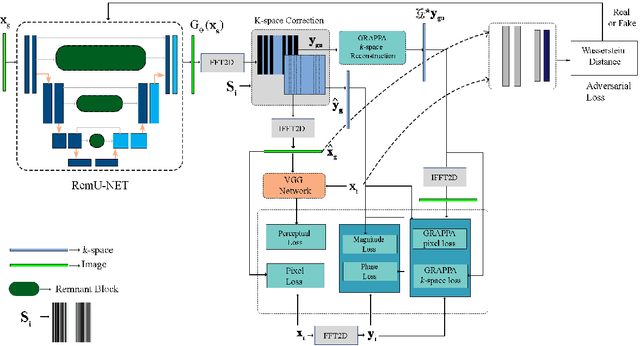



Objective: Parallel imaging accelerates the acquisition of magnetic resonance imaging (MRI) data by acquiring additional sensitivity information with an array of receiver coils resulting in reduced phase encoding steps. Compressed sensing magnetic resonance imaging (CS-MRI) has achieved popularity in the field of medical imaging because of its less data requirement than parallel imaging. Parallel imaging and compressed sensing (CS) both speed up traditional MRI acquisition by minimizing the amount of data captured in the k-space. As acquisition time is inversely proportional to the number of samples, the inverse formation of an image from reduced k-space samples leads to faster acquisition but with aliasing artifacts. This paper proposes a novel Generative Adversarial Network (GAN) namely RECGAN-GR supervised with multi-modal losses for de-aliasing the reconstructed image. Methods: In contrast to existing GAN networks, our proposed method introduces a novel generator network namely RemU-Net integrated with dual-domain loss functions including weighted magnitude and phase loss functions along with parallel imaging-based loss i.e., GRAPPA consistency loss. A k-space correction block is proposed as refinement learning to make the GAN network self-resistant to generating unnecessary data which drives the convergence of the reconstruction process faster. Results: Comprehensive results show that the proposed RECGAN-GR achieves a 4 dB improvement in the PSNR among the GAN-based methods and a 2 dB improvement among conventional state-of-the-art CNN methods available in the literature. Conclusion and significance: The proposed work contributes to significant improvement in the image quality for low retained data leading to 5x or 10x faster acquisition.
A Unifying Multi-sampling-ratio CS-MRI Framework With Two-grid-cycle Correction and Geometric Prior Distillation
May 14, 2022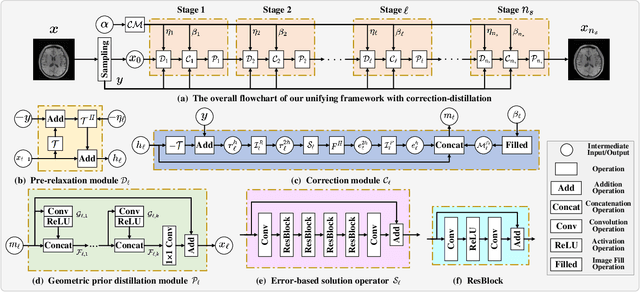
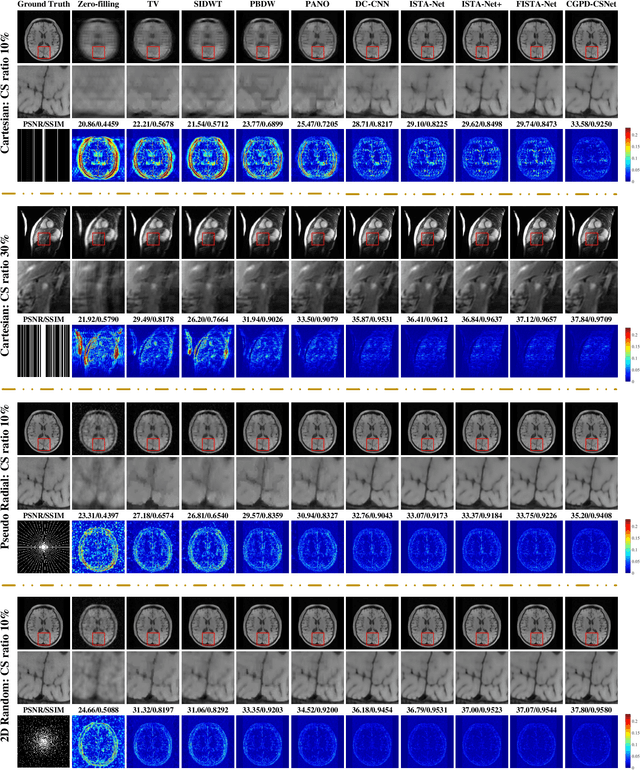
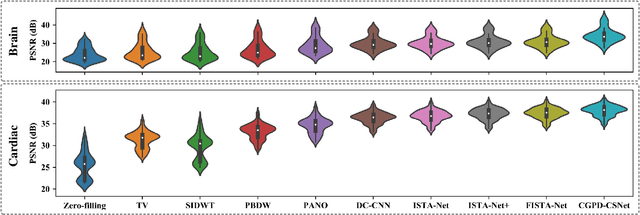

CS is an efficient method to accelerate the acquisition of MR images from under-sampled k-space data. Although existing deep learning CS-MRI methods have achieved considerably impressive performance, explainability and generalizability continue to be challenging for such methods since most of them are not flexible enough to handle multi-sampling-ratio reconstruction assignments, often the transition from mathematical analysis to network design not always natural enough. In this work, to tackle explainability and generalizability, we propose a unifying deep unfolding multi-sampling-ratio CS-MRI framework, by merging advantages of model-based and deep learning-based methods. The combined approach offers more generalizability than previous works whereas deep learning gains explainability through a geometric prior module. Inspired by multigrid algorithm, we first embed the CS-MRI-based optimization algorithm into correction-distillation scheme that consists of three ingredients: pre-relaxation module, correction module and geometric prior distillation module. Furthermore, we employ a condition module to learn adaptively step-length and noise level from compressive sampling ratio in every stage, which enables the proposed framework to jointly train multi-ratio tasks through a single model. The proposed model can not only compensate the lost contextual information of reconstructed image which is refined from low frequency error in geometric characteristic k-space, but also integrate the theoretical guarantee of model-based methods and the superior reconstruction performances of deep learning-based methods. All physical-model parameters are learnable, and numerical experiments show that our framework outperforms state-of-the-art methods in terms of qualitative and quantitative evaluations.
PUERT: Probabilistic Under-sampling and Explicable Reconstruction Network for CS-MRI
Apr 24, 2022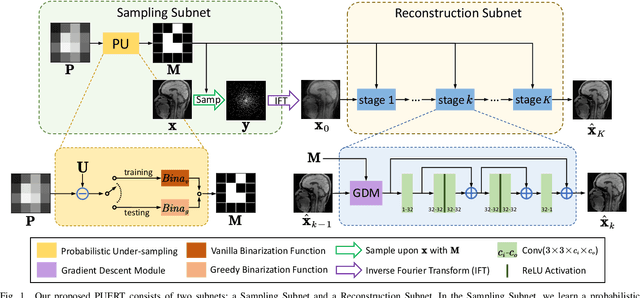
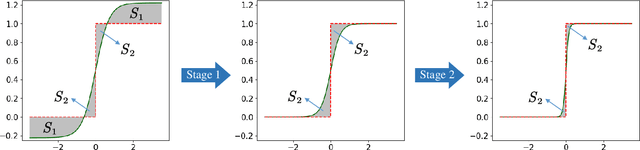

Compressed Sensing MRI (CS-MRI) aims at reconstructing de-aliased images from sub-Nyquist sampling k-space data to accelerate MR Imaging, thus presenting two basic issues, i.e., where to sample and how to reconstruct. To deal with both problems simultaneously, we propose a novel end-to-end Probabilistic Under-sampling and Explicable Reconstruction neTwork, dubbed PUERT, to jointly optimize the sampling pattern and the reconstruction network. Instead of learning a deterministic mask, the proposed sampling subnet explores an optimal probabilistic sub-sampling pattern, which describes independent Bernoulli random variables at each possible sampling point, thus retaining robustness and stochastics for a more reliable CS reconstruction. A dynamic gradient estimation strategy is further introduced to gradually approximate the binarization function in backward propagation, which efficiently preserves the gradient information and further improves the reconstruction quality. Moreover, in our reconstruction subnet, we adopt a model-based network design scheme with high efficiency and interpretability, which is shown to assist in further exploitation for the sampling subnet. Extensive experiments on two widely used MRI datasets demonstrate that our proposed PUERT not only achieves state-of-the-art results in terms of both quantitative metrics and visual quality but also yields a sub-sampling pattern and a reconstruction model that are both customized to training data.
Transformer Compressed Sensing via Global Image Tokens
Mar 27, 2022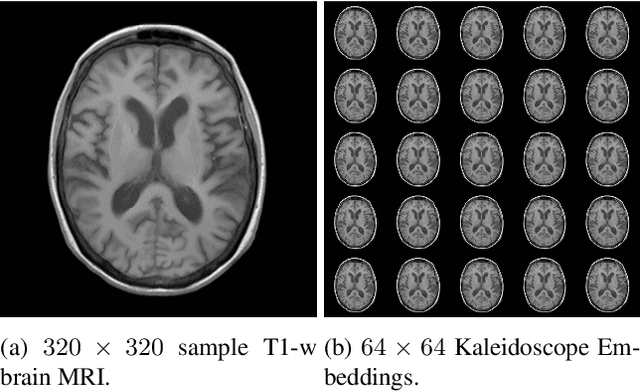

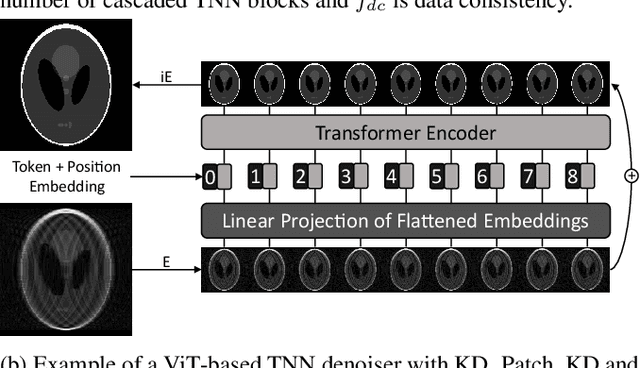
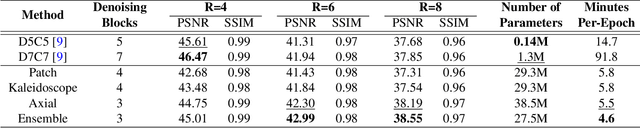
Convolutional neural networks (CNN) have demonstrated outstanding Compressed Sensing (CS) performance compared to traditional, hand-crafted methods. However, they are broadly limited in terms of generalisability, inductive bias and difficulty to model long distance relationships. Transformer neural networks (TNN) overcome such issues by implementing an attention mechanism designed to capture dependencies between inputs. However, high-resolution tasks typically require vision Transformers (ViT) to decompose an image into patch-based tokens, limiting inputs to inherently local contexts. We propose a novel image decomposition that naturally embeds images into low-resolution inputs. These Kaleidoscope tokens (KD) provide a mechanism for global attention, at the same computational cost as a patch-based approach. To showcase this development, we replace CNN components in a well-known CS-MRI neural network with TNN blocks and demonstrate the improvements afforded by KD. We also propose an ensemble of image tokens, which enhance overall image quality and reduces model size. Supplementary material is available: https://github.com/uqmarlonbran/TCS.git