 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Image Deblurring
Blind image deblurring is the process of removing blur from images without knowing the blur kernel.
Papers and Code
Physics-consistent deep learning for blind aberration recovery in mobile optics
Mar 05, 2026Mobile photography is often limited by complex, lens-specific optical aberrations. While recent deep learning methods approach this as an end-to-end deblurring task, these "black-box" models lack explicit optical modeling and can hallucinate details. Conversely, classical blind deconvolution remains highly unstable. To bridge this gap, we present Lens2Zernike, a deep learning framework that blindly recovers physical optical parameters from a single blurred image. To the best of our knowledge, no prior work has simultaneously integrated supervision across three distinct optical domains. We introduce a novel physics-consistent strategy that explicitly minimizes errors via direct Zernike coefficient regression (z), differentiable physics constraints encompassing both wavefront and point spread function derivations (p), and auxiliary multi-task spatial map predictions (m). Through an ablation study on a ResNet-18 backbone, we demonstrate that our full multi-task framework (z+p+m) yields a 35% improvement over coefficient-only baselines. Crucially, comparative analysis reveals that our approach outperforms two established deep learning methods from previous literature, achieving significantly lower regression errors. Ultimately, we demonstrate that these recovered physical parameters enable stable non-blind deconvolution, providing substantial in-domain improvement on the patented Institute for Digital Molecular Analytics and Science (IDMxS) Mobile Camera Lens Database for restoring diffraction-limited details from severely aberrated mobile captures.
DeblurSDI: Blind Image Deblurring Using Self-diffusion
Oct 31, 2025Blind image deconvolution is a challenging ill-posed inverse problem, where both the latent sharp image and the blur kernel are unknown. Traditional methods often rely on handcrafted priors, while modern deep learning approaches typically require extensive pre-training on large external datasets, limiting their adaptability to real-world scenarios. In this work, we propose DeblurSDI, a zero-shot, self-supervised framework based on self-diffusion (SDI) that requires no prior training. DeblurSDI formulates blind deconvolution as an iterative reverse self-diffusion process that starts from pure noise and progressively refines the solution. At each step, two randomly-initialized neural networks are optimized continuously to refine the sharp image and the blur kernel. The optimization is guided by an objective function combining data consistency with a sparsity-promoting L1-norm for the kernel. A key innovation is our noise scheduling mechanism, which stabilizes the optimization and provides remarkable robustness to variations in blur kernel size. These allow DeblurSDI to dynamically learn an instance-specific prior tailored to the input image. Extensive experiments demonstrate that DeblurSDI consistently achieves superior performance, recovering sharp images and accurate kernels even in highly degraded scenarios.
MoTDiff: High-resolution Motion Trajectory estimation from a single blurred image using Diffusion models
Oct 30, 2025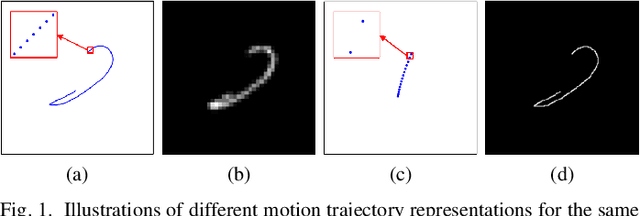
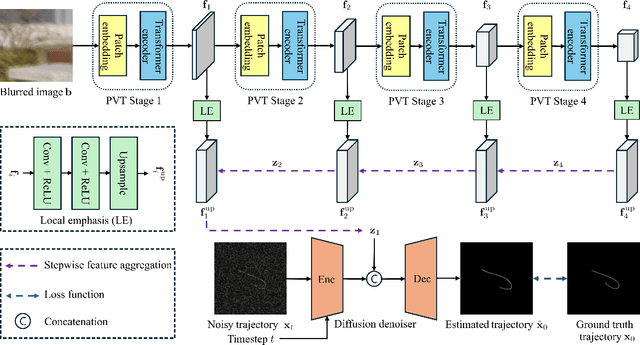


Accurate estimation of motion information is crucial in diverse computational imaging and computer vision applications. Researchers have investigated various methods to extract motion information from a single blurred image, including blur kernels and optical flow. However, existing motion representations are often of low quality, i.e., coarse-grained and inaccurate. In this paper, we propose the first high-resolution (HR) Motion Trajectory estimation framework using Diffusion models (MoTDiff). Different from existing motion representations, we aim to estimate an HR motion trajectory with high-quality from a single motion-blurred image. The proposed MoTDiff consists of two key components: 1) a new conditional diffusion framework that uses multi-scale feature maps extracted from a single blurred image as a condition, and 2) a new training method that can promote precise identification of a fine-grained motion trajectory, consistent estimation of overall shape and position of a motion path, and pixel connectivity along a motion trajectory. Our experiments demonstrate that the proposed MoTDiff can outperform state-of-the-art methods in both blind image deblurring and coded exposure photography applications.
Blur2seq: Blind Deblurring and Camera Trajectory Estimation from a Single Camera Motion-blurred Image
Oct 23, 2025Motion blur caused by camera shake, particularly under large or rotational movements, remains a major challenge in image restoration. We propose a deep learning framework that jointly estimates the latent sharp image and the underlying camera motion trajectory from a single blurry image. Our method leverages the Projective Motion Blur Model (PMBM), implemented efficiently using a differentiable blur creation module compatible with modern networks. A neural network predicts a full 3D rotation trajectory, which guides a model-based restoration network trained end-to-end. This modular architecture provides interpretability by revealing the camera motion that produced the blur. Moreover, this trajectory enables the reconstruction of the sequence of sharp images that generated the observed blurry image. To further refine results, we optimize the trajectory post-inference via a reblur loss, improving consistency between the blurry input and the restored output. Extensive experiments show that our method achieves state-of-the-art performance on both synthetic and real datasets, particularly in cases with severe or spatially variant blur, where end-to-end deblurring networks struggle. Code and trained models are available at https://github.com/GuillermoCarbajal/Blur2Seq/
PRISM: Probabilistic and Robust Inverse Solver with Measurement-Conditioned Diffusion Prior for Blind Inverse Problems
Sep 19, 2025Diffusion models are now commonly used to solve inverse problems in computational imaging. However, most diffusion-based inverse solvers require complete knowledge of the forward operator to be used. In this work, we introduce a novel probabilistic and robust inverse solver with measurement-conditioned diffusion prior (PRISM) to effectively address blind inverse problems. PRISM offers a technical advancement over current methods by incorporating a powerful measurement-conditioned diffusion model into a theoretically principled posterior sampling scheme. Experiments on blind image deblurring validate the effectiveness of the proposed method, demonstrating the superior performance of PRISM over state-of-the-art baselines in both image and blur kernel recovery.
A novel method and dataset for depth-guided image deblurring from smartphone Lidar
Sep 11, 2025Modern smartphones are equipped with Lidar sensors providing depth-sensing capabilities. Recent works have shown that this complementary sensor allows to improve various tasks in image processing, including deblurring. However, there is a current lack of datasets with realistic blurred images and paired mobile Lidar depth maps to further study the topic. At the same time, there is also a lack of blind zero-shot methods that can deblur a real image using the depth guidance without requiring extensive training sets of paired data. In this paper, we propose an image deblurring method based on denoising diffusion models that can leverage the Lidar depth guidance and does not require training data with paired Lidar depth maps. We also present the first dataset with real blurred images with corresponding Lidar depth maps and sharp ground truth images, acquired with an Apple iPhone 15 Pro, for the purpose of studying Lidar-guided deblurring. Experimental results on this novel dataset show that Lidar guidance is effective and the proposed method outperforms state-of-the-art deblurring methods in terms of perceptual quality.
NPN: Non-Linear Projections of the Null-Space for Imaging Inverse Problems
Oct 02, 2025Imaging inverse problems aims to recover high-dimensional signals from undersampled, noisy measurements, a fundamentally ill-posed task with infinite solutions in the null-space of the sensing operator. To resolve this ambiguity, prior information is typically incorporated through handcrafted regularizers or learned models that constrain the solution space. However, these priors typically ignore the task-specific structure of that null-space. In this work, we propose \textit{Non-Linear Projections of the Null-Space} (NPN), a novel class of regularization that, instead of enforcing structural constraints in the image domain, promotes solutions that lie in a low-dimensional projection of the sensing matrix's null-space with a neural network. Our approach has two key advantages: (1) Interpretability: by focusing on the structure of the null-space, we design sensing-matrix-specific priors that capture information orthogonal to the signal components that are fundamentally blind to the sensing process. (2) Flexibility: NPN is adaptable to various inverse problems, compatible with existing reconstruction frameworks, and complementary to conventional image-domain priors. We provide theoretical guarantees on convergence and reconstruction accuracy when used within plug-and-play methods. Empirical results across diverse sensing matrices demonstrate that NPN priors consistently enhance reconstruction fidelity in various imaging inverse problems, such as compressive sensing, deblurring, super-resolution, computed tomography, and magnetic resonance imaging, with plug-and-play methods, unrolling networks, deep image prior, and diffusion models.
Learning Deblurring Texture Prior from Unpaired Data with Diffusion Model
Jul 18, 2025



Since acquiring large amounts of realistic blurry-sharp image pairs is difficult and expensive, learning blind image deblurring from unpaired data is a more practical and promising solution. Unfortunately, dominant approaches rely heavily on adversarial learning to bridge the gap from blurry domains to sharp domains, ignoring the complex and unpredictable nature of real-world blur patterns. In this paper, we propose a novel diffusion model (DM)-based framework, dubbed \ours, for image deblurring by learning spatially varying texture prior from unpaired data. In particular, \ours performs DM to generate the prior knowledge that aids in recovering the textures of blurry images. To implement this, we propose a Texture Prior Encoder (TPE) that introduces a memory mechanism to represent the image textures and provides supervision for DM training. To fully exploit the generated texture priors, we present the Texture Transfer Transformer layer (TTformer), in which a novel Filter-Modulated Multi-head Self-Attention (FM-MSA) efficiently removes spatially varying blurring through adaptive filtering. Furthermore, we implement a wavelet-based adversarial loss to preserve high-frequency texture details. Extensive evaluations show that \ours provides a promising unsupervised deblurring solution and outperforms SOTA methods in widely-used benchmarks.
Plug-and-Play Posterior Sampling for Blind Inverse Problems
May 28, 2025


We introduce Blind Plug-and-Play Diffusion Models (Blind-PnPDM) as a novel framework for solving blind inverse problems where both the target image and the measurement operator are unknown. Unlike conventional methods that rely on explicit priors or separate parameter estimation, our approach performs posterior sampling by recasting the problem into an alternating Gaussian denoising scheme. We leverage two diffusion models as learned priors: one to capture the distribution of the target image and another to characterize the parameters of the measurement operator. This PnP integration of diffusion models ensures flexibility and ease of adaptation. Our experiments on blind image deblurring show that Blind-PnPDM outperforms state-of-the-art methods in terms of both quantitative metrics and visual fidelity. Our results highlight the effectiveness of treating blind inverse problems as a sequence of denoising subproblems while harnessing the expressive power of diffusion-based priors.
Frequency-domain Learning with Kernel Prior for Blind Image Deblurring
Apr 20, 2025



While achieving excellent results on various datasets, many deep learning methods for image deblurring suffer from limited generalization capabilities with out-of-domain data. This limitation is likely caused by their dependence on certain domain-specific datasets. To address this challenge, we argue that it is necessary to introduce the kernel prior into deep learning methods, as the kernel prior remains independent of the image context. For effective fusion of kernel prior information, we adopt a rational implementation method inspired by traditional deblurring algorithms that perform deconvolution in the frequency domain. We propose a module called Frequency Integration Module (FIM) for fusing the kernel prior and combine it with a frequency-based deblurring Transfomer network. Experimental results demonstrate that our method outperforms state-of-the-art methods on multiple blind image deblurring tasks, showcasing robust generalization abilities. Source code will be available soon.