 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Bad: A Dataset for Geometric Fracture and Reassembly
Oct 20, 2022

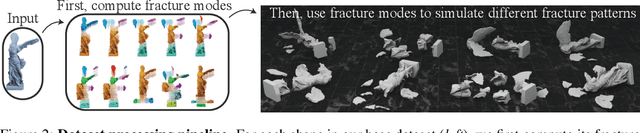

We introduce Breaking Bad, a large-scale dataset of fractured objects. Our dataset consists of over one million fractured objects simulated from ten thousand base models. The fracture simulation is powered by a recent physically based algorithm that efficiently generates a variety of fracture modes of an object. Existing shape assembly datasets decompose objects according to semantically meaningful parts, effectively modeling the construction process. In contrast, Breaking Bad models the destruction process of how a geometric object naturally breaks into fragments. Our dataset serves as a benchmark that enables the study of fractured object reassembly and presents new challenges for geometric shape understanding. We analyze our dataset with several geometry measurements and benchmark three state-of-the-art shape assembly deep learning methods under various settings. Extensive experimental results demonstrate the difficulty of our dataset, calling on future research in model designs specifically for the geometric shape assembly task. We host our dataset at https://breaking-bad-dataset.github.io/.
SlotFormer: Unsupervised Visual Dynamics Simulation with Object-Centric Models
Oct 12, 2022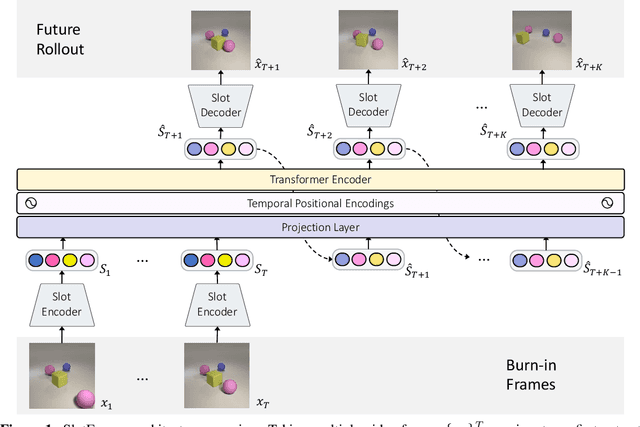
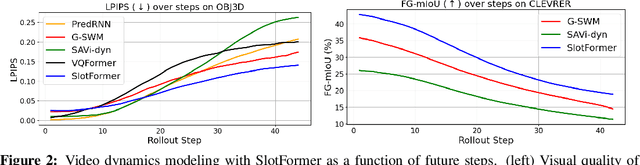
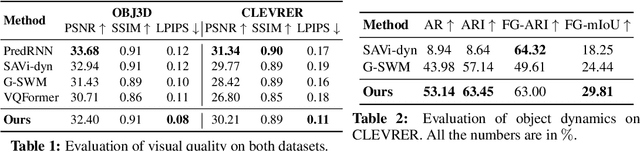
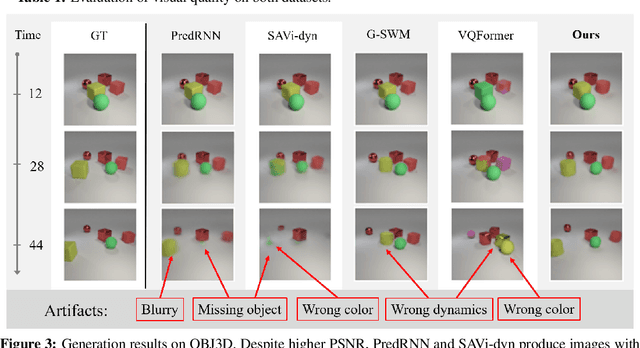
Understanding dynamics from visual observations is a challenging problem that requires disentangling individual objects from the scene and learning their interactions. While recent object-centric models can successfully decompose a scene into objects, modeling their dynamics effectively still remains a challenge. We address this problem by introducing SlotFormer -- a Transformer-based autoregressive model operating on learned object-centric representations. Given a video clip, our approach reasons over object features to model spatio-temporal relationships and predicts accurate future object states. In this paper, we successfully apply SlotFormer to perform video prediction on datasets with complex object interactions. Moreover, the unsupervised SlotFormer's dynamics model can be used to improve the performance on supervised downstream tasks, such as Visual Question Answering (VQA), and goal-conditioned planning. Compared to past works on dynamics modeling, our method achieves significantly better long-term synthesis of object dynamics, while retaining high quality visual generation. Besides, SlotFormer enables VQA models to reason about the future without object-level labels, even outperforming counterparts that use ground-truth annotations. Finally, we show its ability to serve as a world model for model-based planning, which is competitive with methods designed specifically for such tasks.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Unsupervised Domain Adaptive Salient Object Detection Through Uncertainty-Aware Pseudo-Label Learning
Feb 26, 2022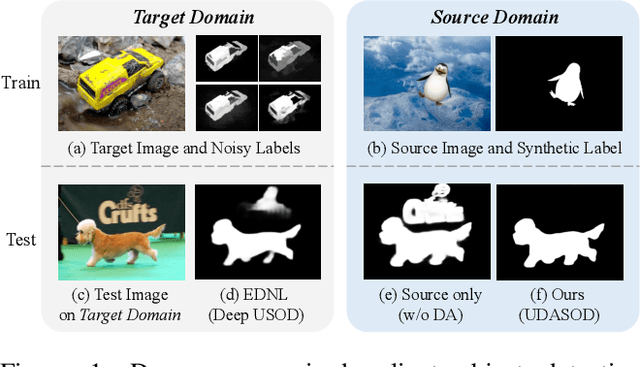


Recent advances in deep learning significantly boost the performance of salient object detection (SOD) at the expense of labeling larger-scale per-pixel annotations. To relieve the burden of labor-intensive labeling, deep unsupervised SOD methods have been proposed to exploit noisy labels generated by handcrafted saliency methods. However, it is still difficult to learn accurate saliency details from rough noisy labels. In this paper, we propose to learn saliency from synthetic but clean labels, which naturally has higher pixel-labeling quality without the effort of manual annotations. Specifically, we first construct a novel synthetic SOD dataset by a simple copy-paste strategy. Considering the large appearance differences between the synthetic and real-world scenarios, directly training with synthetic data will lead to performance degradation on real-world scenarios. To mitigate this problem, we propose a novel unsupervised domain adaptive SOD method to adapt between these two domains by uncertainty-aware self-training. Experimental results show that our proposed method outperforms the existing state-of-the-art deep unsupervised SOD methods on several benchmark datasets, and is even comparable to fully-supervised ones.
Dynamics-aware Adversarial Attack of 3D Sparse Convolution Network
Dec 17, 2021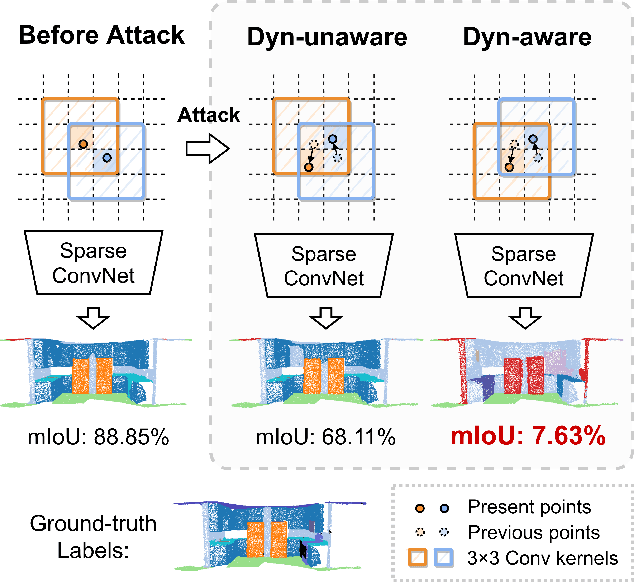

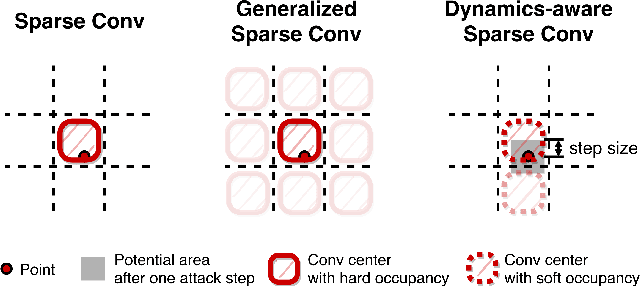
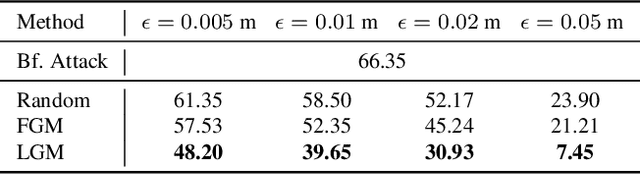
In this paper, we investigate the dynamics-aware adversarial attack problem in deep neural networks. Most existing adversarial attack algorithms are designed under a basic assumption -- the network architecture is fixed throughout the attack process. However, this assumption does not hold for many recently proposed networks, e.g. 3D sparse convolution network, which contains input-dependent execution to improve computational efficiency. It results in a serious issue of lagged gradient, making the learned attack at the current step ineffective due to the architecture changes afterward. To address this issue, we propose a Leaded Gradient Method (LGM) and show the significant effects of the lagged gradient. More specifically, we re-formulate the gradients to be aware of the potential dynamic changes of network architectures, so that the learned attack better "leads" the next step than the dynamics-unaware methods when network architecture changes dynamically. Extensive experiments on various datasets show that our LGM achieves impressive performance on semantic segmentation and classification. Compared with the dynamic-unaware methods, LGM achieves about 20% lower mIoU averagely on the ScanNet and S3DIS datasets. LGM also outperforms the recent point cloud attacks.
Road Network Guided Fine-Grained Urban Traffic Flow Inference
Sep 29, 2021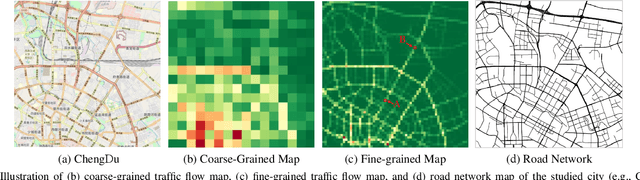
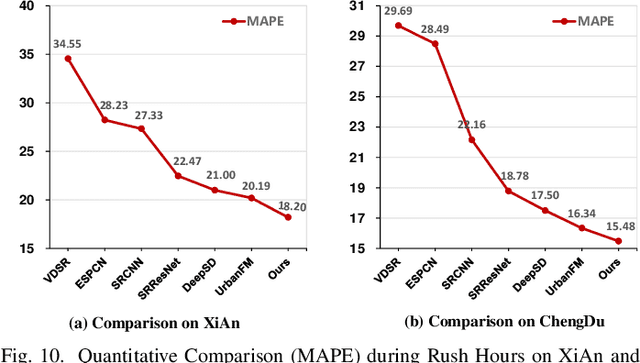
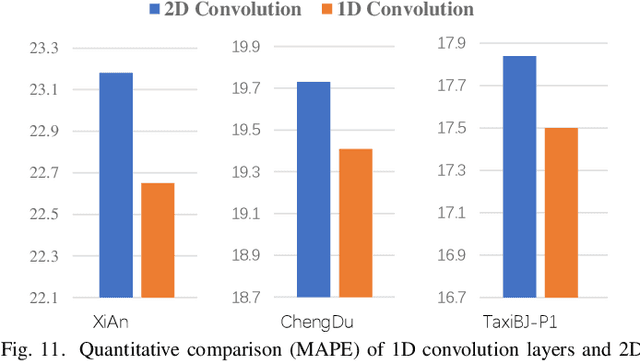
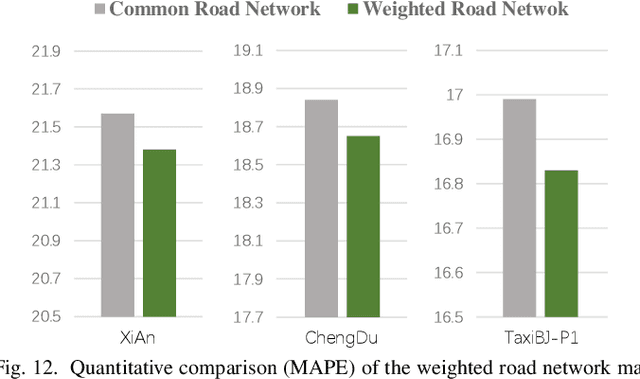
Accurate inference of fine-grained traffic flow from coarse-grained one is an emerging yet crucial problem, which can help greatly reduce the number of traffic monitoring sensors for cost savings. In this work, we notice that traffic flow has a high correlation with road network, which was either completely ignored or simply treated as an external factor in previous works. To facilitate this problem, we propose a novel Road-Aware Traffic Flow Magnifier (RATFM) that explicitly exploits the prior knowledge of road networks to fully learn the road-aware spatial distribution of fine-grained traffic flow. Specifically, a multi-directional 1D convolutional layer is first introduced to extract the semantic feature of the road network. Subsequently, we incorporate the road network feature and coarse-grained flow feature to regularize the short-range spatial distribution modeling of road-relative traffic flow. Furthermore, we take the road network feature as a query to capture the long-range spatial distribution of traffic flow with a transformer architecture. Benefiting from the road-aware inference mechanism, our method can generate high-quality fine-grained traffic flow maps. Extensive experiments on three real-world datasets show that the proposed RATFM outperforms state-of-the-art models under various scenarios.
Instance Similarity Learning for Unsupervised Feature Representation
Aug 05, 2021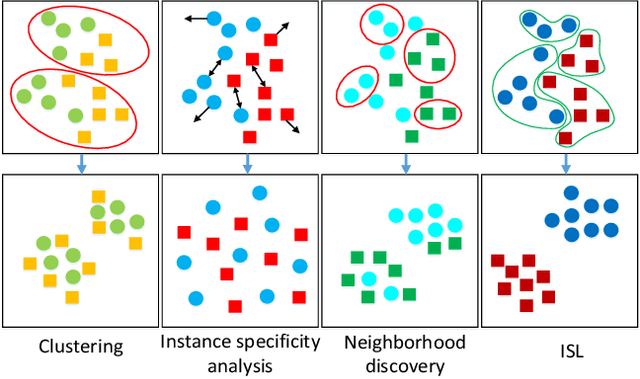
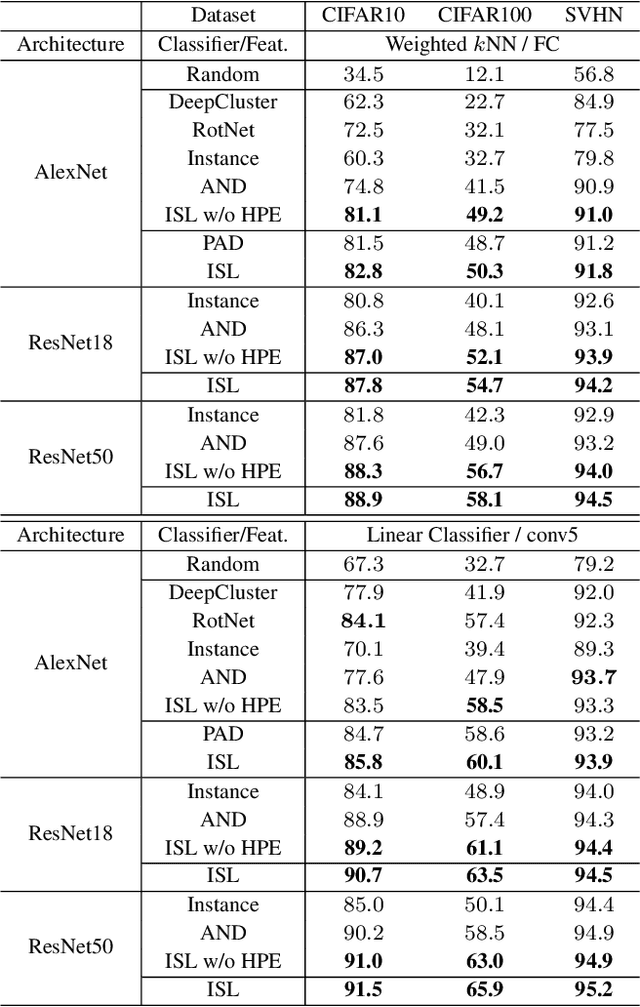
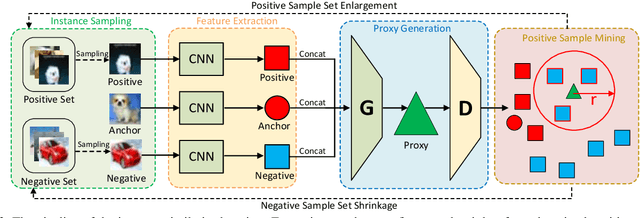
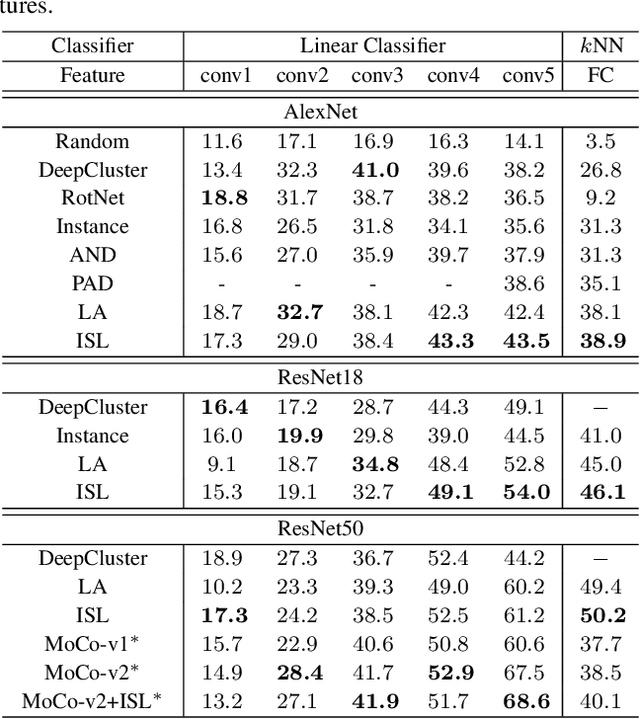
In this paper, we propose an instance similarity learning (ISL) method for unsupervised feature representation. Conventional methods assign close instance pairs in the feature space with high similarity, which usually leads to wrong pairwise relationship for large neighborhoods because the Euclidean distance fails to depict the true semantic similarity on the feature manifold. On the contrary, our method mines the feature manifold in an unsupervised manner, through which the semantic similarity among instances is learned in order to obtain discriminative representations. Specifically, we employ the Generative Adversarial Networks (GAN) to mine the underlying feature manifold, where the generated features are applied as the proxies to progressively explore the feature manifold so that the semantic similarity among instances is acquired as reliable pseudo supervision. Extensive experiments on image classification demonstrate the superiority of our method compared with the state-of-the-art methods. The code is available at https://github.com/ZiweiWangTHU/ISL.git.
Online Metro Origin-Destination Prediction via Heterogeneous Information Aggregation
Aug 02, 2021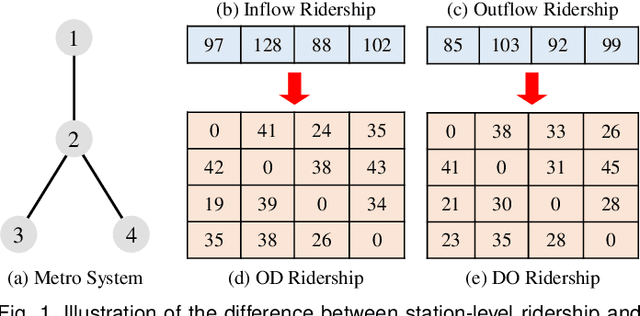
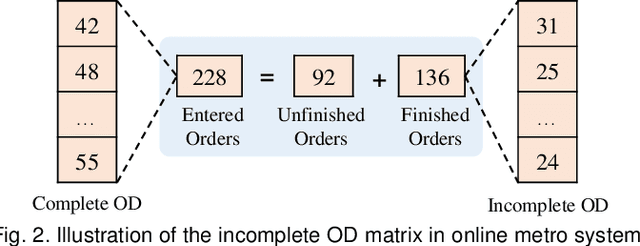
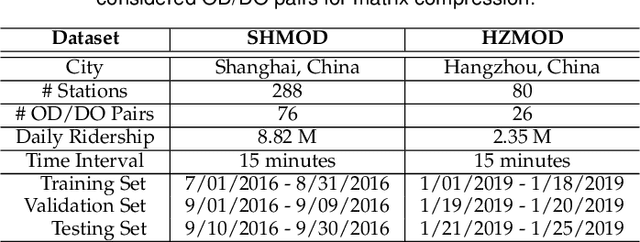
Metro origin-destination prediction is a crucial yet challenging time-series analysis task in intelligent transportation systems, which aims to accurately forecast two specific types of cross-station ridership, i.e., Origin-Destination (OD) one and Destination-Origin (DO) one. However, complete OD matrices of previous time intervals can not be obtained immediately in online metro systems, and conventional methods only used limited information to forecast the future OD and DO ridership separately. In this work, we proposed a novel neural network module termed Heterogeneous Information Aggregation Machine (HIAM), which fully exploits heterogeneous information of historical data (e.g., incomplete OD matrices, unfinished order vectors, and DO matrices) to jointly learn the evolutionary patterns of OD and DO ridership. Specifically, an OD modeling branch estimates the potential destinations of unfinished orders explicitly to complement the information of incomplete OD matrices, while a DO modeling branch takes DO matrices as input to capture the spatial-temporal distribution of DO ridership. Moreover, a Dual Information Transformer is introduced to propagate the mutual information among OD features and DO features for modeling the OD-DO causality and correlation. Based on the proposed HIAM, we develop a unified Seq2Seq network to forecast the future OD and DO ridership simultaneously. Extensive experiments conducted on two large-scale benchmarks demonstrate the effectiveness of our method for online metro origin-destination prediction.
RiddleSense: Answering Riddle Questions as Commonsense Reasoning
Jan 02, 2021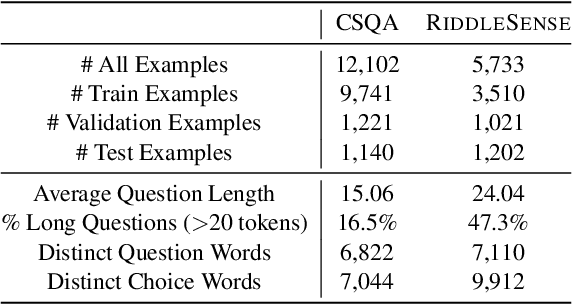
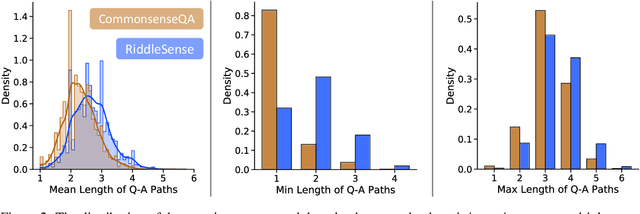
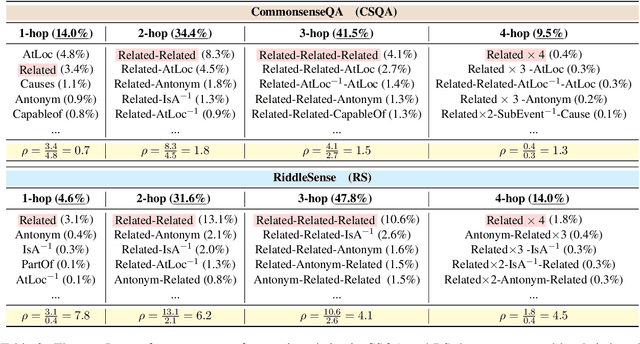
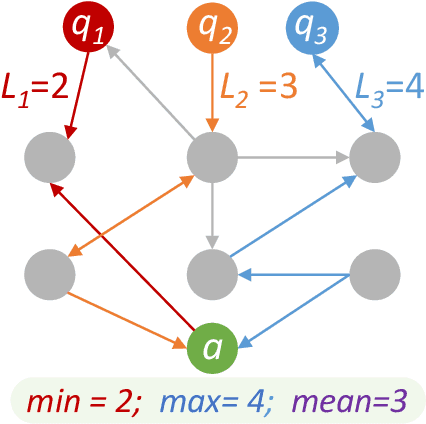
A riddle is a mystifying, puzzling question about everyday concepts. For example, the riddle "I have five fingers but I am not alive. What am I?" asks about the concept of a glove. Solving riddles is a challenging cognitive process for humans, in that it requires complex commonsense reasoning abilities and an understanding of figurative language. However, there are currently no commonsense reasoning datasets that test these abilities. We propose RiddleSense, a novel multiple-choice question answering challenge for benchmarking higher-order commonsense reasoning models, which is the first large dataset for riddle-style commonsense question answering, where the distractors are crowdsourced from human annotators. We systematically evaluate a wide range of reasoning models over it and point out that there is a large gap between the best-supervised model and human performance -- pointing to interesting future research for higher-order commonsense reasoning and computational creativity.
IF-Defense: 3D Adversarial Point Cloud Defense via Implicit Function based Restoration
Oct 11, 2020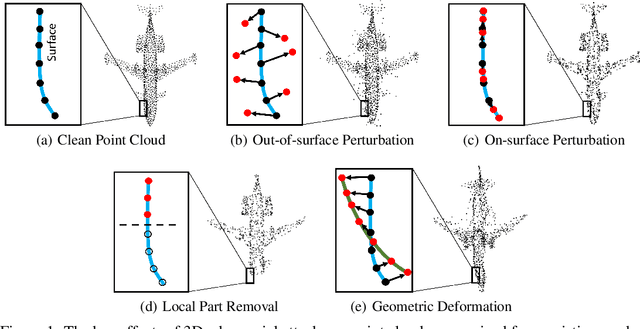

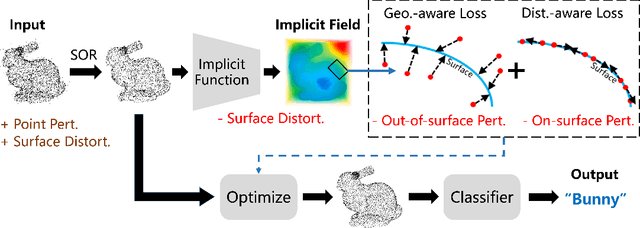
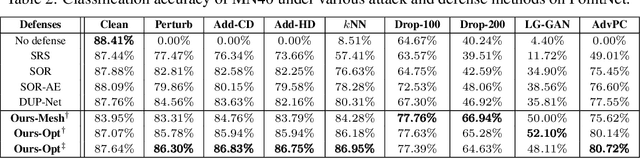
Point cloud is an important 3D data representation widely used in many essential applications. Leveraging deep neural networks, recent works have shown great success in processing 3D point clouds. However, those deep neural networks are vulnerable to various 3D adversarial attacks, which can be summarized as two primary types: point perturbation that affects local point distribution, and surface distortion that causes dramatic changes in geometry. In this paper, we propose a novel 3D adversarial point cloud defense method leveraging implicit function based restoration (IF-Defense) to address both the aforementioned attacks. It is composed of two steps: 1) it predicts an implicit function that captures the clean shape through a surface recovery module, and 2) restores a clean and complete point cloud via minimizing the difference between the attacked point cloud and the predicted implicit function under geometry- and distribution- aware constraints. Our experimental results show that IF-Defense achieves the state-of-the-art defense performance against all existing adversarial attacks on PointNet, PointNet++, DGCNN and PointConv. Comparing with previous methods, IF-Defense presents 20.02% improvement in classification accuracy against salient point dropping attack and 16.29% against LG-GAN attack on PointNet.