 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Attention: Cross-Layer Value Mixing for Language Models
Jun 03, 2026Self-attention selects information freely across the sequence, but across depth, Transformers merely add each layer's output to the residual stream, so later layers cannot selectively reuse earlier-layer representations. Recent cross-layer methods improve this flow but operate on hidden states outside attention, adding state beyond the key-value cache at inference--a cost that becomes increasingly salient as modern LLMs compress the cache with grouped-query and multi-head latent attention. We introduce Depth-Attention, which performs this selection inside the attention module itself: before a layer attends over the sequence, its query attends over the keys of earlier layers at the same token position and mixes their values into the value that self-attention then reads. Because Depth-Attention reuses the standard attention queries, keys, and value-cache slots, storing depth-mixed values in place of the original values, it adds no parameters and introduces no persistent inference state beyond the standard key-value cache--the same cache size as a vanilla decoder and less than hidden-state-based cross-layer methods. On Qwen3-style decoders at 1.5B and 3B parameters, Depth-Attention attains the lowest perplexity and the highest average downstream accuracy, improving over the vanilla Transformer by up to 2.3 accuracy points and surpassing strong cross-layer baselines in perplexity and average accuracy, while adding under 0.01% extra arithmetic FLOPs and no additional persistent inference state. The gains hold from 360M to 3B parameters and extend to looped Transformers.
VQKV: High-Fidelity and High-Ratio Cache Compression via Vector-Quantization
Mar 17, 2026The growing context length of Large Language Models (LLMs) enlarges the Key-Value (KV) cache, limiting deployment in resource-limited environments. Prior training-free approaches for KV cache compression typically rely on low-rank approximation or scalar quantization, which fail to simultaneously achieve high compression ratios and high reconstruction fidelity. We propose VQKV, a novel, training-free method introducing vector quantization (VQ) to obtain highly compressed KV representations while preserving high model fidelity, allowing for the representation of thousands of floating-point values with just a few integer indices. As a result, VQKV achieves an 82.8\% compression ratio on LLaMA3.1-8B while retaining 98.6\% of the baseline performance on LongBench and enabling 4.3x longer generation length on the same memory footprint.
CoDAR: Continuous Diffusion Language Models are More Powerful Than You Think
Mar 03, 2026We study why continuous diffusion language models (DLMs) have lagged behind discrete diffusion approaches despite their appealing continuous generative dynamics. Under a controlled token--recovery study, we identify token rounding, the final projection from denoised embeddings to tokens, as a primary bottleneck. Building on these insights, we propose CoDAR (Continuous Diffusion with Contextual AutoRegressive Decoder), a two--stage framework that keeps diffusion entirely continuous in an embedding space while learning a strong, context--conditional discretizer: an autoregressive Transformer decoder that cross--attends to the denoised embedding sequence and performs contextualized rounding to tokens. Experiments on LM1B and OpenWebText demonstrate that CoDAR substantially improves generation quality over latent diffusion and becomes competitive with strong discrete DLMs, while exposing a simple decoder--temperature knob to navigate the fluency--diversity trade off.
AdaPonderLM: Gated Pondering Language Models with Token-Wise Adaptive Depth
Mar 02, 2026Test-time scaling via recurrent/iterative Transformers enables large language models to spend more computation at inference, but most pretrained recurrent LMs run a fixed number of iterations, wasting compute on easy tokens and lacking token-wise adaptivity. Following the core idea of Adaptive Computation Time(ACT) and Early Exit(EE), we propose AdaPonderLM, a self-supervised recurrent language model that learns token-wise early exiting during pretraining without manually tuned per-token/per-layer pruning ratios. AdaPonderLM uses iteration-specific MLP gates with a monotonic halting mask to decide when each token stops recurring, and introduces a KV reuse mechanism that reuses cached key/value states for halted tokens, ensuring train--test consistency and practical acceleration. Across Pythia backbones from 70M to 410M (pretraining) and up to 2.8B (continued pretraining), AdaPonderLM reduces inference compute at about 10% while maintaining comparable language modeling perplexity and competitive downstream accuracy. Our analysis shows the learned gates allocate more computation to high-NLL (hard) tokens, exhibiting adaptive computation time behavior in a fully self-supervised setting. Meanwhile, under iso-FLOPs, the learned halting policy consistently outperforms fixed pruning, showing AdaPonderLM allocates compute to the right tokens rather than just reducing average depth.
PonderLM-3: Adaptive Token-Wise Pondering with Differentiable Masking
Mar 02, 2026Test-time scaling has shown that allocating more additional computation at inference can improve generation quality, motivating a natural follow-up question: where should this computation be spent? Building on this insight, we introduce PonderLM-3, a pretraining framework for token-wise adaptive pondering that learns to selectively allocate additional computation under purely self-supervised objectives, built on top of the PonderLM-2 backbone. This makes additional inference computation an allocatable per-token resource, so tokens receive more computation only when it is beneficial, rather than paying a uniform extra cost. To make this allocation learnable while maintaining train-inference consistency, PonderLM-3 injects a differentiable attention mask during pretraining and pairs it with a matching hard pruning rule at inference. PonderLM-3 defines a stronger Pareto frontier: compared with existing recursive or adaptive baselines, it achieves lower pretraining perplexity at equal inference FLOPs. On downstream benchmarks, PonderLM-3 attains comparable performance to fixed-step PonderLM-2 under the same maximum number of additional computation steps, while using fewer inference FLOPs in practice. Overall, PonderLM-3 provides an end-to-end differentiable and train-inference consistent framework for token-wise adaptive computation, enabling additional inference compute to be allocated where it is most useful rather than paid uniformly by every token.
MOVA: Towards Scalable and Synchronized Video-Audio Generation
Feb 09, 2026Audio is indispensable for real-world video, yet generation models have largely overlooked audio components. Current approaches to producing audio-visual content often rely on cascaded pipelines, which increase cost, accumulate errors, and degrade overall quality. While systems such as Veo 3 and Sora 2 emphasize the value of simultaneous generation, joint multimodal modeling introduces unique challenges in architecture, data, and training. Moreover, the closed-source nature of existing systems limits progress in the field. In this work, we introduce MOVA (MOSS Video and Audio), an open-source model capable of generating high-quality, synchronized audio-visual content, including realistic lip-synced speech, environment-aware sound effects, and content-aligned music. MOVA employs a Mixture-of-Experts (MoE) architecture, with a total of 32B parameters, of which 18B are active during inference. It supports IT2VA (Image-Text to Video-Audio) generation task. By releasing the model weights and code, we aim to advance research and foster a vibrant community of creators. The released codebase features comprehensive support for efficient inference, LoRA fine-tuning, and prompt enhancement.
FourierSampler: Unlocking Non-Autoregressive Potential in Diffusion Language Models via Frequency-Guided Generation
Jan 30, 2026Despite the non-autoregressive potential of diffusion language models (dLLMs), existing decoding strategies demonstrate positional bias, failing to fully unlock the potential of arbitrary generation. In this work, we delve into the inherent spectral characteristics of dLLMs and present the first frequency-domain analysis showing that low-frequency components in hidden states primarily encode global structural information and long-range dependencies, while high-frequency components are responsible for characterizing local details. Based on this observation, we propose FourierSampler, which leverages a frequency-domain sliding window mechanism to dynamically guide the model to achieve a "structure-to-detail" generation. FourierSampler outperforms other inference enhancement strategies on LLADA and SDAR, achieving relative improvements of 20.4% on LLaDA1.5-8B and 16.0% on LLaDA-8B-Instruct. It notably surpasses similarly sized autoregressive models like Llama3.1-8B-Instruct.
DiRL: An Efficient Post-Training Framework for Diffusion Language Models
Dec 23, 2025Diffusion Language Models (dLLMs) have emerged as promising alternatives to Auto-Regressive (AR) models. While recent efforts have validated their pre-training potential and accelerated inference speeds, the post-training landscape for dLLMs remains underdeveloped. Existing methods suffer from computational inefficiency and objective mismatches between training and inference, severely limiting performance on complex reasoning tasks such as mathematics. To address this, we introduce DiRL, an efficient post-training framework that tightly integrates FlexAttention-accelerated blockwise training with LMDeploy-optimized inference. This architecture enables a streamlined online model update loop, facilitating efficient two-stage post-training (Supervised Fine-Tuning followed by Reinforcement Learning). Building on this framework, we propose DiPO, the first unbiased Group Relative Policy Optimization (GRPO) implementation tailored for dLLMs. We validate our approach by training DiRL-8B-Instruct on high-quality math data. Our model achieves state-of-the-art math performance among dLLMs and surpasses comparable models in the Qwen2.5 series on several benchmarks.
Beyond Real: Imaginary Extension of Rotary Position Embeddings for Long-Context LLMs
Dec 08, 2025Rotary Position Embeddings (RoPE) have become a standard for encoding sequence order in Large Language Models (LLMs) by applying rotations to query and key vectors in the complex plane. Standard implementations, however, utilize only the real component of the complex-valued dot product for attention score calculation. This simplification discards the imaginary component, which contains valuable phase information, leading to a potential loss of relational details crucial for modeling long-context dependencies. In this paper, we propose an extension that re-incorporates this discarded imaginary component. Our method leverages the full complex-valued representation to create a dual-component attention score. We theoretically and empirically demonstrate that this approach enhances the modeling of long-context dependencies by preserving more positional information. Furthermore, evaluations on a suite of long-context language modeling benchmarks show that our method consistently improves performance over the standard RoPE, with the benefits becoming more significant as context length increases. The code is available at https://github.com/OpenMOSS/rope_pp.
LongLLaDA: Unlocking Long Context Capabilities in Diffusion LLMs
Jun 17, 2025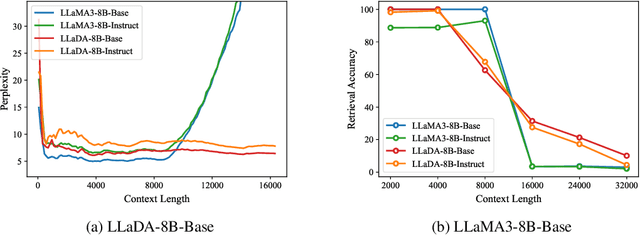

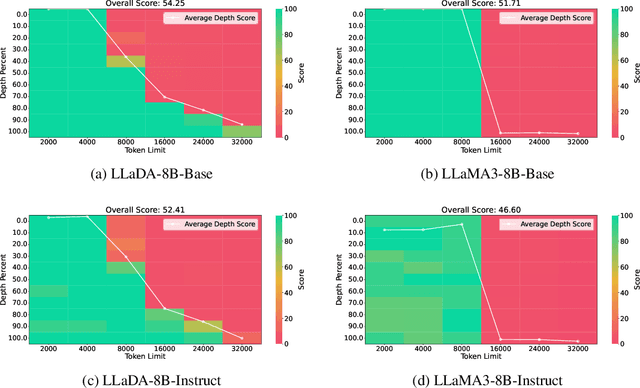

Large Language Diffusion Models, or diffusion LLMs, have emerged as a significant focus in NLP research, with substantial effort directed toward understanding their scalability and downstream task performance. However, their long-context capabilities remain unexplored, lacking systematic analysis or methods for context extension. In this work, we present the first systematic investigation comparing the long-context performance of diffusion LLMs and traditional auto-regressive LLMs. We first identify a unique characteristic of diffusion LLMs, unlike auto-regressive LLMs, they maintain remarkably \textbf{\textit{stable perplexity}} during direct context extrapolation. Furthermore, where auto-regressive models fail outright during the Needle-In-A-Haystack task with context exceeding their pretrained length, we discover diffusion LLMs exhibit a distinct \textbf{\textit{local perception}} phenomenon, enabling successful retrieval from recent context segments. We explain both phenomena through the lens of Rotary Position Embedding (RoPE) scaling theory. Building on these observations, we propose LongLLaDA, a training-free method that integrates LLaDA with the NTK-based RoPE extrapolation. Our results validate that established extrapolation scaling laws remain effective for extending the context windows of diffusion LLMs. Furthermore, we identify long-context tasks where diffusion LLMs outperform auto-regressive LLMs and others where they fall short. Consequently, this study establishes the first context extrapolation method for diffusion LLMs while providing essential theoretical insights and empirical benchmarks critical for advancing future research on long-context diffusion LLMs.