 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Memorization Effect of Neural Networks in Adversarial Training
Jun 09, 2021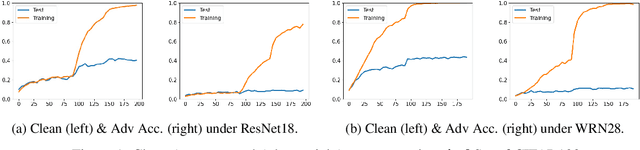

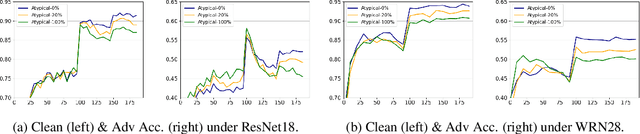
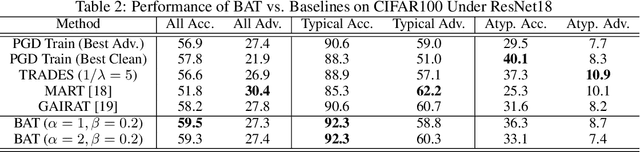
Recent studies suggest that ``memorization'' is one important factor for overparameterized deep neural networks (DNNs) to achieve optimal performance. Specifically, the perfectly fitted DNNs can memorize the labels of many atypical samples, generalize their memorization to correctly classify test atypical samples and enjoy better test performance. While, DNNs which are optimized via adversarial training algorithms can also achieve perfect training performance by memorizing the labels of atypical samples, as well as the adversarially perturbed atypical samples. However, adversarially trained models always suffer from poor generalization, with both relatively low clean accuracy and robustness on the test set. In this work, we study the effect of memorization in adversarial trained DNNs and disclose two important findings: (a) Memorizing atypical samples is only effective to improve DNN's accuracy on clean atypical samples, but hardly improve their adversarial robustness and (b) Memorizing certain atypical samples will even hurt the DNN's performance on typical samples. Based on these two findings, we propose Benign Adversarial Training (BAT) which can facilitate adversarial training to avoid fitting ``harmful'' atypical samples and fit as more ``benign'' atypical samples as possible. In our experiments, we validate the effectiveness of BAT, and show it can achieve better clean accuracy vs. robustness trade-off than baseline methods, in benchmark datasets such as CIFAR100 and Tiny~ImageNet.
Long Text Generation by Modeling Sentence-Level and Discourse-Level Coherence
May 19, 2021
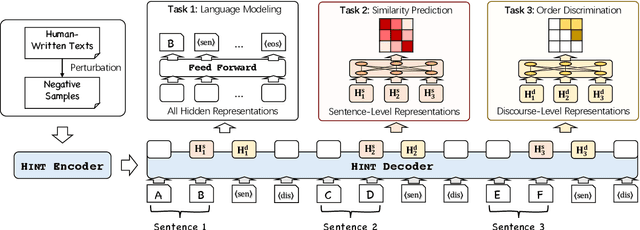
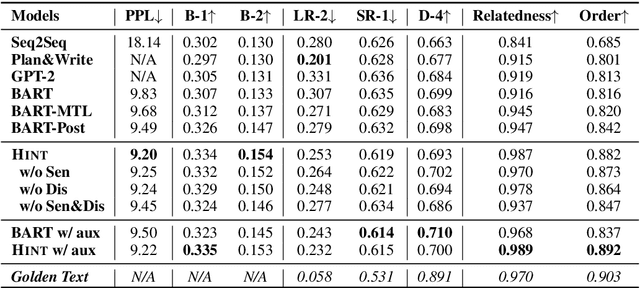
Generating long and coherent text is an important but challenging task, particularly for open-ended language generation tasks such as story generation. Despite the success in modeling intra-sentence coherence, existing generation models (e.g., BART) still struggle to maintain a coherent event sequence throughout the generated text. We conjecture that this is because of the difficulty for the decoder to capture the high-level semantics and discourse structures in the context beyond token-level co-occurrence. In this paper, we propose a long text generation model, which can represent the prefix sentences at sentence level and discourse level in the decoding process. To this end, we propose two pretraining objectives to learn the representations by predicting inter-sentence semantic similarity and distinguishing between normal and shuffled sentence orders. Extensive experiments show that our model can generate more coherent texts than state-of-the-art baselines.
OpenMEVA: A Benchmark for Evaluating Open-ended Story Generation Metrics
May 19, 2021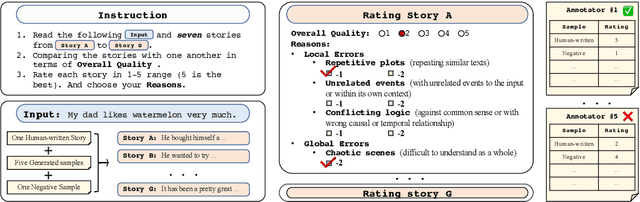
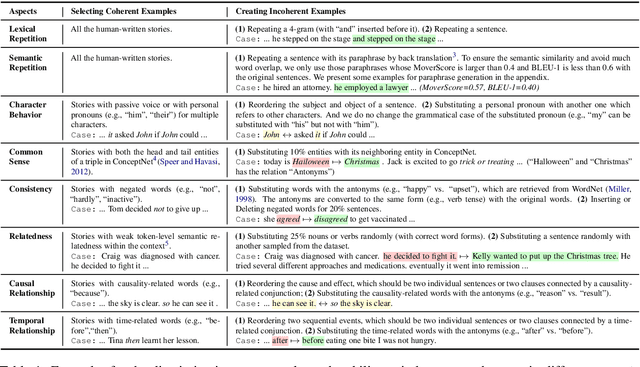
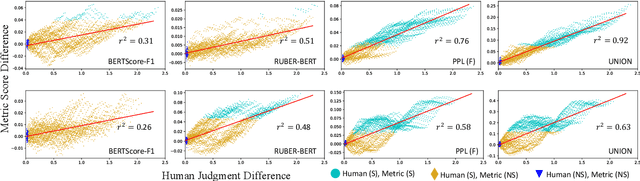
Automatic metrics are essential for developing natural language generation (NLG) models, particularly for open-ended language generation tasks such as story generation. However, existing automatic metrics are observed to correlate poorly with human evaluation. The lack of standardized benchmark datasets makes it difficult to fully evaluate the capabilities of a metric and fairly compare different metrics. Therefore, we propose OpenMEVA, a benchmark for evaluating open-ended story generation metrics. OpenMEVA provides a comprehensive test suite to assess the capabilities of metrics, including (a) the correlation with human judgments, (b) the generalization to different model outputs and datasets, (c) the ability to judge story coherence, and (d) the robustness to perturbations. To this end, OpenMEVA includes both manually annotated stories and auto-constructed test examples. We evaluate existing metrics on OpenMEVA and observe that they have poor correlation with human judgments, fail to recognize discourse-level incoherence, and lack inferential knowledge (e.g., causal order between events), the generalization ability and robustness. Our study presents insights for developing NLG models and metrics in further research.
The Authors Matter: Understanding and Mitigating Implicit Bias in Deep Text Classification
May 06, 2021
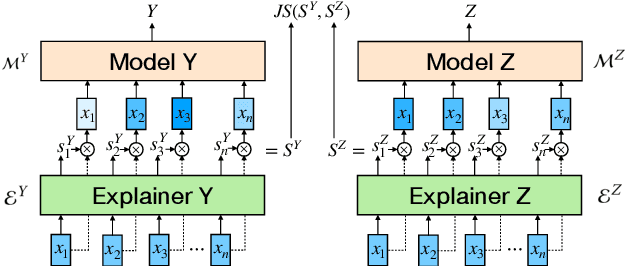
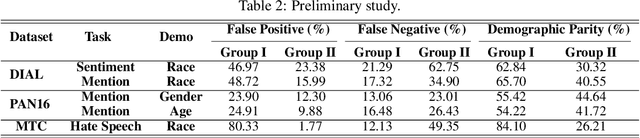
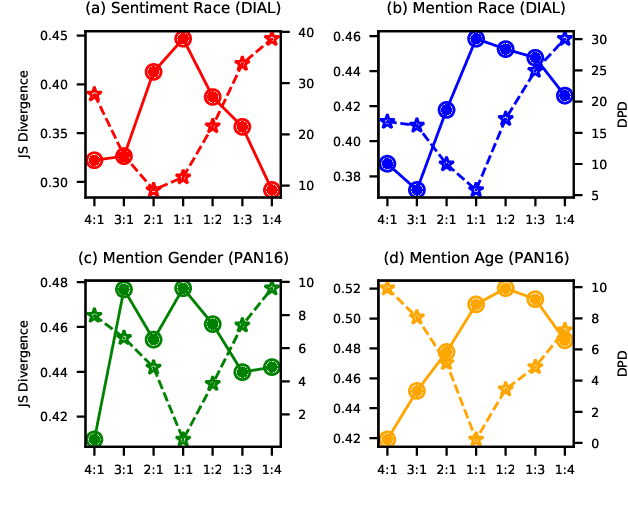
It is evident that deep text classification models trained on human data could be biased. In particular, they produce biased outcomes for texts that explicitly include identity terms of certain demographic groups. We refer to this type of bias as explicit bias, which has been extensively studied. However, deep text classification models can also produce biased outcomes for texts written by authors of certain demographic groups. We refer to such bias as implicit bias of which we still have a rather limited understanding. In this paper, we first demonstrate that implicit bias exists in different text classification tasks for different demographic groups. Then, we build a learning-based interpretation method to deepen our knowledge of implicit bias. Specifically, we verify that classifiers learn to make predictions based on language features that are related to the demographic attributes of the authors. Next, we propose a framework Debiased-TC to train deep text classifiers to make predictions on the right features and consequently mitigate implicit bias. We conduct extensive experiments on three real-world datasets. The results show that the text classification models trained under our proposed framework outperform traditional models significantly in terms of fairness, and also slightly in terms of classification performance.
AdvExpander: Generating Natural Language Adversarial Examples by Expanding Text
Dec 18, 2020
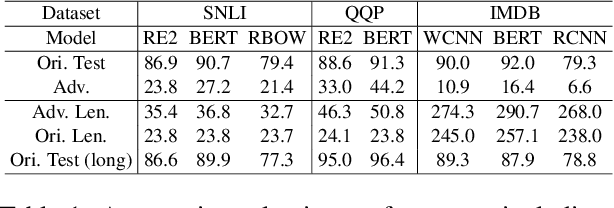
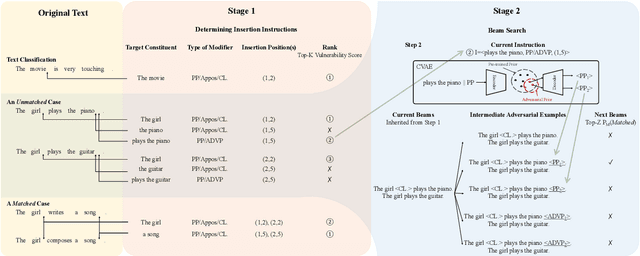
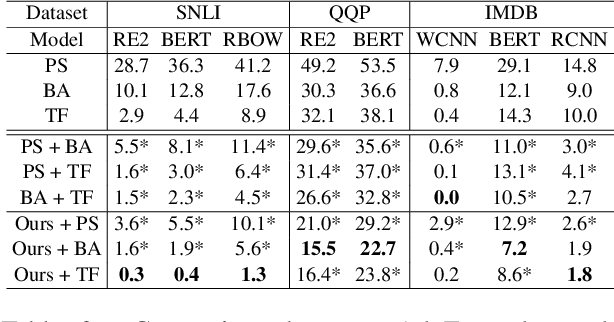
Adversarial examples are vital to expose the vulnerability of machine learning models. Despite the success of the most popular substitution-based methods which substitutes some characters or words in the original examples, only substitution is insufficient to uncover all robustness issues of models. In this paper, we present AdvExpander, a method that crafts new adversarial examples by expanding text, which is complementary to previous substitution-based methods. We first utilize linguistic rules to determine which constituents to expand and what types of modifiers to expand with. We then expand each constituent by inserting an adversarial modifier searched from a CVAE-based generative model which is pre-trained on a large scale corpus. To search adversarial modifiers, we directly search adversarial latent codes in the latent space without tuning the pre-trained parameters. To ensure that our adversarial examples are label-preserving for text matching, we also constrain the modifications with a heuristic rule. Experiments on three classification tasks verify the effectiveness of AdvExpander and the validity of our adversarial examples. AdvExpander crafts a new type of adversarial examples by text expansion, thereby promising to reveal new robustness issues.
Node Similarity Preserving Graph Convolutional Networks
Nov 19, 2020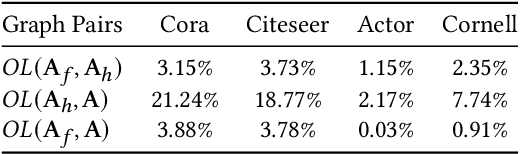
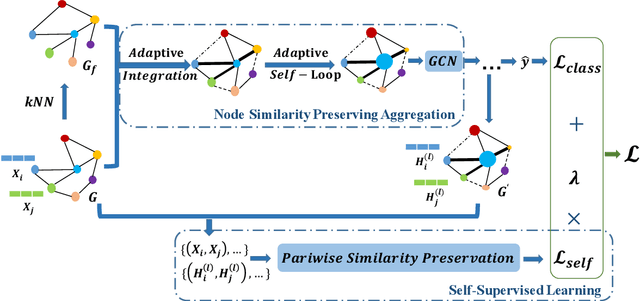
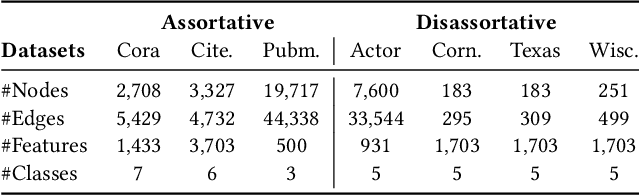
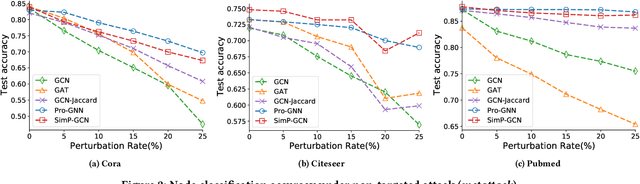
Graph Neural Networks (GNNs) have achieved tremendous success in various real-world applications due to their strong ability in graph representation learning. GNNs explore the graph structure and node features by aggregating and transforming information within node neighborhoods. However, through theoretical and empirical analysis, we reveal that the aggregation process of GNNs tends to destroy node similarity in the original feature space. There are many scenarios where node similarity plays a crucial role. Thus, it has motivated the proposed framework SimP-GCN that can effectively and efficiently preserve node similarity while exploiting graph structure. Specifically, to balance information from graph structure and node features, we propose a feature similarity preserving aggregation which adaptively integrates graph structure and node features. Furthermore, we employ self-supervised learning to explicitly capture the complex feature similarity and dissimilarity relations between nodes. We validate the effectiveness of SimP-GCN on seven benchmark datasets including three assortative and four disassorative graphs. The results demonstrate that SimP-GCN outperforms representative baselines. Further probe shows various advantages of the proposed framework. The implementation of SimP-GCN is available at \url{https://github.com/ChandlerBang/SimP-GCN}.
Personalized Multimodal Feedback Generation in Education
Oct 31, 2020



The automatic evaluation for school assignments is an important application of AI in the education field. In this work, we focus on the task of personalized multimodal feedback generation, which aims to generate personalized feedback for various teachers to evaluate students' assignments involving multimodal inputs such as images, audios, and texts. This task involves the representation and fusion of multimodal information and natural language generation, which presents the challenges from three aspects: 1) how to encode and integrate multimodal inputs; 2) how to generate feedback specific to each modality; and 3) how to realize personalized feedback generation. In this paper, we propose a novel Personalized Multimodal Feedback Generation Network (PMFGN) armed with a modality gate mechanism and a personalized bias mechanism to address these challenges. The extensive experiments on real-world K-12 education data show that our model significantly outperforms several baselines by generating more accurate and diverse feedback. In addition, detailed ablation experiments are conducted to deepen our understanding of the proposed framework.
Mathematical Word Problem Generation from Commonsense Knowledge Graph and Equations
Oct 13, 2020
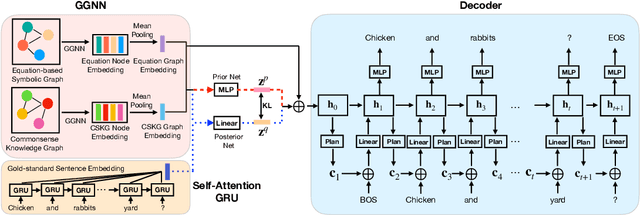
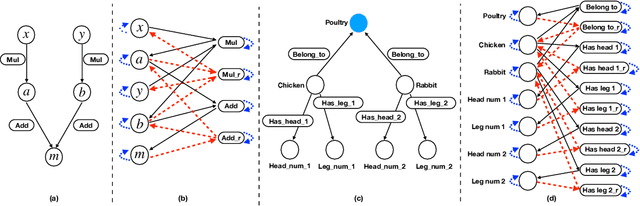
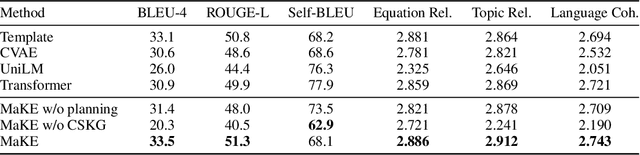
There is an increasing interest in the use of automatic mathematical word problem (MWP) generation in educational assessment. Different from standard natural question generation, MWP generation needs to maintain the underlying mathematical operations between quantities and variables, while at the same time ensuring the relevance between the output and the given topic. To address above problem we develop an end-to-end neural model to generate personalized and diverse MWPs in real-world scenarios from commonsense knowledge graph and equations. The proposed model (1) learns both representations from edge-enhanced Levi graphs of symbolic equations and commonsense knowledge; (2) automatically fuses equation and commonsense knowledge information via a self-planning module when generating the MWPs. Experiments on an educational gold-standard set and a large-scale generated MWP set show that our approach is superior on the MWP generation task, and it outperforms the state-of-the-art models in terms of both automatic evaluation metrics, i.e., BLEU-4, ROUGE-L, Self-BLEU, and human evaluation metrics, i.e, equation relevance, topic relevance, and language coherence.
Mitigating Gender Bias for Neural Dialogue Generation with Adversarial Learning
Sep 28, 2020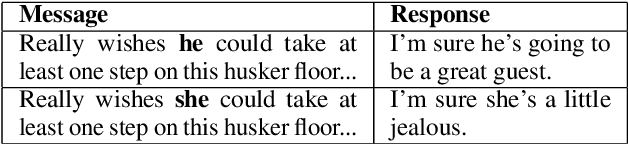
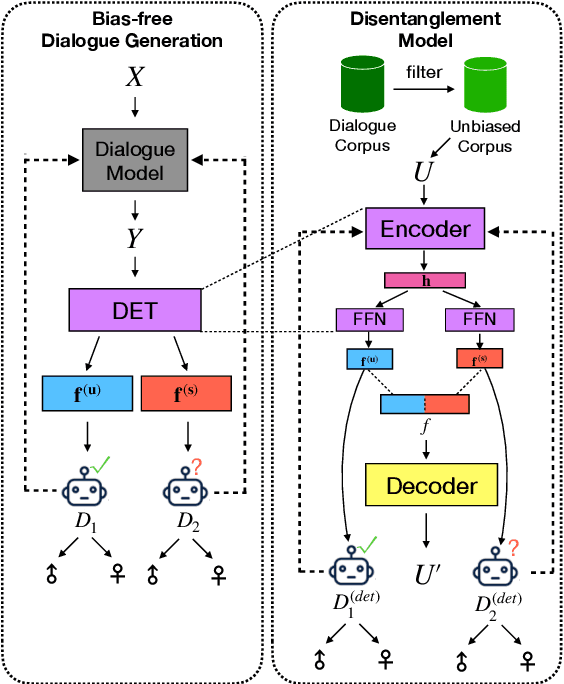
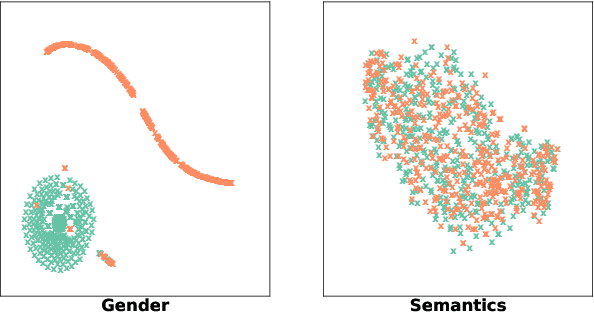

Dialogue systems play an increasingly important role in various aspects of our daily life. It is evident from recent research that dialogue systems trained on human conversation data are biased. In particular, they can produce responses that reflect people's gender prejudice. Many debiasing methods have been developed for various natural language processing tasks, such as word embedding. However, they are not directly applicable to dialogue systems because they are likely to force dialogue models to generate similar responses for different genders. This greatly degrades the diversity of the generated responses and immensely hurts the performance of the dialogue models. In this paper, we propose a novel adversarial learning framework Debiased-Chat to train dialogue models free from gender bias while keeping their performance. Extensive experiments on two real-world conversation datasets show that our framework significantly reduces gender bias in dialogue models while maintaining the response quality.
Representation Learning from Limited Educational Data with Crowdsourced Labels
Sep 23, 2020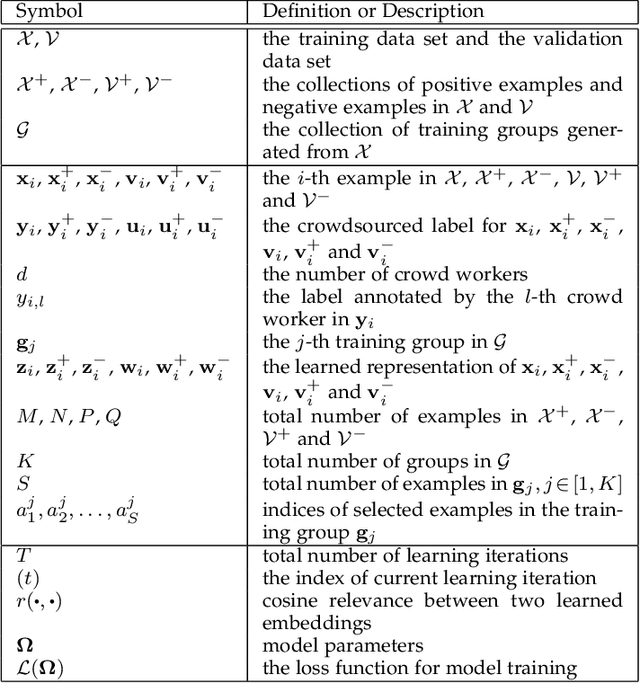
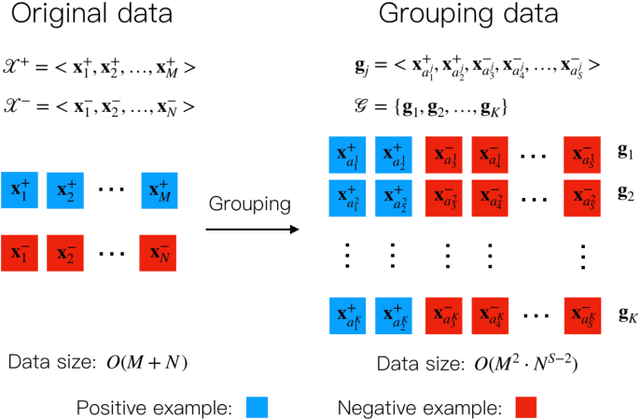
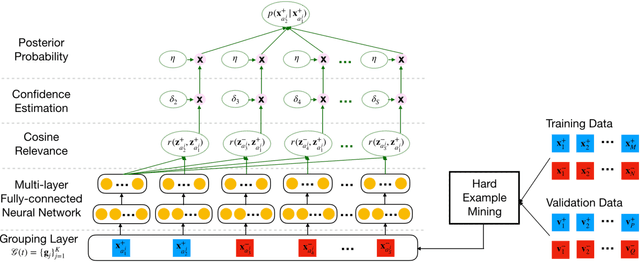
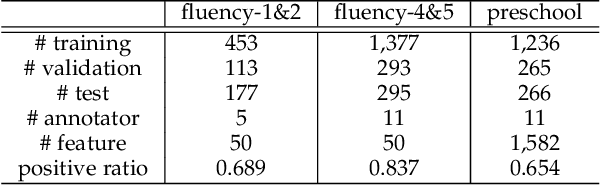
Representation learning has been proven to play an important role in the unprecedented success of machine learning models in numerous tasks, such as machine translation, face recognition and recommendation. The majority of existing representation learning approaches often require a large number of consistent and noise-free labels. However, due to various reasons such as budget constraints and privacy concerns, labels are very limited in many real-world scenarios. Directly applying standard representation learning approaches on small labeled data sets will easily run into over-fitting problems and lead to sub-optimal solutions. Even worse, in some domains such as education, the limited labels are usually annotated by multiple workers with diverse expertise, which yields noises and inconsistency in such crowdsourcing settings. In this paper, we propose a novel framework which aims to learn effective representations from limited data with crowdsourced labels. Specifically, we design a grouping based deep neural network to learn embeddings from a limited number of training samples and present a Bayesian confidence estimator to capture the inconsistency among crowdsourced labels. Furthermore, to expedite the training process, we develop a hard example selection procedure to adaptively pick up training examples that are misclassified by the model. Extensive experiments conducted on three real-world data sets demonstrate the superiority of our framework on learning representations from limited data with crowdsourced labels, comparing with various state-of-the-art baselines. In addition, we provide a comprehensive analysis on each of the main components of our proposed framework and also introduce the promising results it achieved in our real production to fully understand the proposed framework.