 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantumSEA: In-Time Sparse Exploration for Noise Adaptive Quantum Circuits
Jan 10, 2024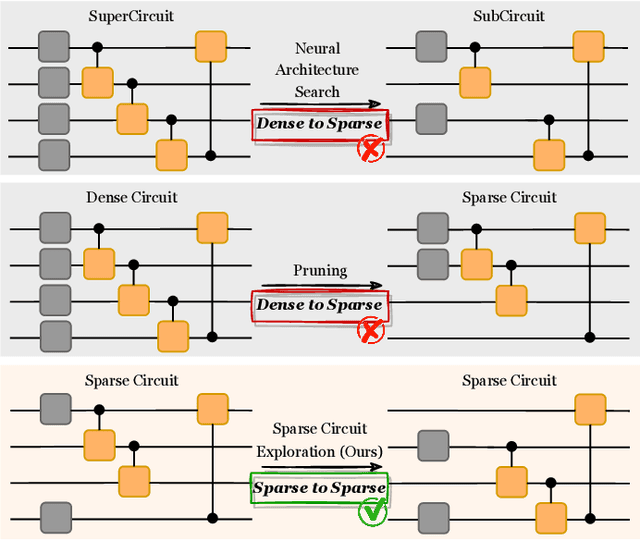
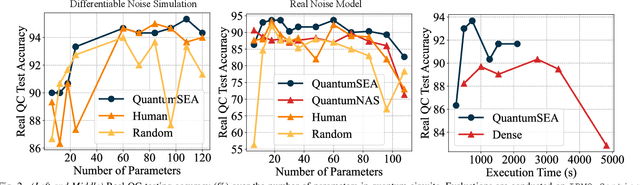
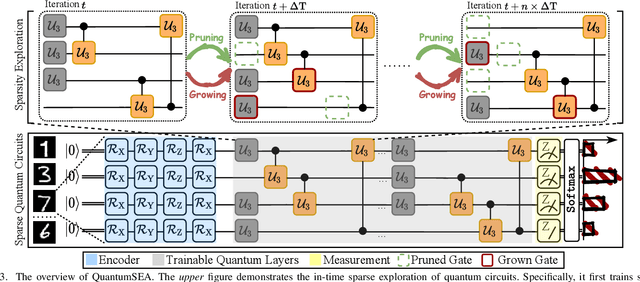
Parameterized Quantum Circuits (PQC) have obtained increasing popularity thanks to their great potential for near-term Noisy Intermediate-Scale Quantum (NISQ) computers. Achieving quantum advantages usually requires a large number of qubits and quantum circuits with enough capacity. However, limited coherence time and massive quantum noises severely constrain the size of quantum circuits that can be executed reliably on real machines. To address these two pain points, we propose QuantumSEA, an in-time sparse exploration for noise-adaptive quantum circuits, aiming to achieve two key objectives: (1) implicit circuits capacity during training - by dynamically exploring the circuit's sparse connectivity and sticking a fixed small number of quantum gates throughout the training which satisfies the coherence time and enjoy light noises, enabling feasible executions on real quantum devices; (2) noise robustness - by jointly optimizing the topology and parameters of quantum circuits under real device noise models. In each update step of sparsity, we leverage the moving average of historical gradients to grow necessary gates and utilize salience-based pruning to eliminate insignificant gates. Extensive experiments are conducted with 7 Quantum Machine Learning (QML) and Variational Quantum Eigensolver (VQE) benchmarks on 6 simulated or real quantum computers, where QuantumSEA consistently surpasses noise-aware search, human-designed, and randomly generated quantum circuit baselines by a clear performance margin. For example, even in the most challenging on-chip training regime, our method establishes state-of-the-art results with only half the number of quantum gates and ~2x time saving of circuit executions. Codes are available at https://github.com/VITA-Group/QuantumSEA.
Spatiotemporal-Linear: Towards Universal Multivariate Time Series Forecasting
Dec 22, 2023Within the field of complicated multivariate time series forecasting (TSF), popular techniques frequently rely on intricate deep learning architectures, ranging from transformer-based designs to recurrent neural networks. However, recent findings suggest that simple Linear models can surpass sophisticated constructs on diverse datasets. These models directly map observation to multiple future time steps, thereby minimizing error accumulation in iterative multi-step prediction. Yet, these models fail to incorporate spatial and temporal information within the data, which is critical for capturing patterns and dependencies that drive insightful predictions. This oversight often leads to performance bottlenecks, especially under specific sequence lengths and dataset conditions, preventing their universal application. In response, we introduce the SpatioTemporal-Linear (STL) framework. STL seamlessly integrates time-embedded and spatially-informed bypasses to augment the Linear-based architecture. These extra routes offer a more robust and refined regression to the data, particularly when the amount of observation is limited and the capacity of simple linear layers to capture dependencies declines. Empirical evidence highlights STL's prowess, outpacing both Linear and Transformer benchmarks across varied observation and prediction durations and datasets. Such robustness accentuates its suitability across a spectrum of applications, including but not limited to, traffic trajectory and rare disease progression forecasting. Through this discourse, we not only validate the STL's distinctive capacities to become a more general paradigm in multivariate time-series prediction using deep-learning techniques but also stress the need to tackle data-scarce prediction scenarios for universal application. Code will be made available.
RobustState: Boosting Fidelity of Quantum State Preparation via Noise-Aware Variational Training
Nov 27, 2023



Quantum state preparation, a crucial subroutine in quantum computing, involves generating a target quantum state from initialized qubits. Arbitrary state preparation algorithms can be broadly categorized into arithmetic decomposition (AD) and variational quantum state preparation (VQSP). AD employs a predefined procedure to decompose the target state into a series of gates, whereas VQSP iteratively tunes ansatz parameters to approximate target state. VQSP is particularly apt for Noisy-Intermediate Scale Quantum (NISQ) machines due to its shorter circuits. However, achieving noise-robust parameter optimization still remains challenging. We present RobustState, a novel VQSP training methodology that combines high robustness with high training efficiency. The core idea involves utilizing measurement outcomes from real machines to perform back-propagation through classical simulators, thus incorporating real quantum noise into gradient calculations. RobustState serves as a versatile, plug-and-play technique applicable for training parameters from scratch or fine-tuning existing parameters to enhance fidelity on target machines. It is adaptable to various ansatzes at both gate and pulse levels and can even benefit other variational algorithms, such as variational unitary synthesis. Comprehensive evaluation of RobustState on state preparation tasks for 4 distinct quantum algorithms using 10 real quantum machines demonstrates a coherent error reduction of up to 7.1 $\times$ and state fidelity improvement of up to 96\% and 81\% for 4-Q and 5-Q states, respectively. On average, RobustState improves fidelity by 50\% and 72\% for 4-Q and 5-Q states compared to baseline approaches.
Reachability-Based Confidence-Aware Probabilistic Collision Detection in Highway Driving
Feb 14, 2023Risk assessment is a crucial component of collision warning and avoidance systems in intelligent vehicles. To accurately detect potential vehicle collisions, reachability-based formal approaches have been developed to ensure driving safety, but suffer from over-conservatism, potentially leading to false-positive risk events in complicated real-world applications. In this work, we combine two reachability analysis techniques, i.e., backward reachable set (BRS) and stochastic forward reachable set (FRS), and propose an integrated probabilistic collision detection framework in highway driving. Within the framework, we can firstly use a BRS to formally check whether a two-vehicle interaction is safe; otherwise, a prediction-based stochastic FRS is employed to estimate a collision probability at each future time step. In doing so, the framework can not only identify non-risky events with guaranteed safety, but also provide accurate collision risk estimation in safety-critical events. To construct the stochastic FRS, we develop a neural network-based acceleration model for surrounding vehicles, and further incorporate confidence-aware dynamic belief to improve the prediction accuracy. Extensive experiments are conducted to validate the performance of the acceleration prediction model based on naturalistic highway driving data, and the efficiency and effectiveness of the framework with the infused confidence belief are tested both in naturalistic and simulated highway scenarios. The proposed risk assessment framework is promising in real-world applications.
Continual Interactive Behavior Learning With Traffic Divergence Measurement: A Dynamic Gradient Scenario Memory Approach
Dec 21, 2022



Developing autonomous vehicles (AVs) helps improve the road safety and traffic efficiency of intelligent transportation systems (ITS). Accurately predicting the trajectories of traffic participants is essential to the decision-making and motion planning of AVs in interactive scenarios. Recently, learning-based trajectory predictors have shown state-of-the-art performance in highway or urban areas. However, most existing learning-based models trained with fixed datasets may perform poorly in continuously changing scenarios. Specifically, they may not perform well in learned scenarios after learning the new one. This phenomenon is called "catastrophic forgetting". Few studies investigate trajectory predictions in continuous scenarios, where catastrophic forgetting may happen. To handle this problem, first, a novel continual learning (CL) approach for vehicle trajectory prediction is proposed in this paper. Then, inspired by brain science, a dynamic memory mechanism is developed by utilizing the measurement of traffic divergence between scenarios, which balances the performance and training efficiency of the proposed CL approach. Finally, datasets collected from different locations are used to design continual training and testing methods in experiments. Experimental results show that the proposed approach achieves consistently high prediction accuracy in continuous scenarios without re-training, which mitigates catastrophic forgetting compared to non-CL approaches. The implementation of the proposed approach is publicly available at https://github.com/BIT-Jack/D-GSM
Leveraging Multi-stream Information Fusion for Trajectory Prediction in Low-illumination Scenarios: A Multi-channel Graph Convolutional Approach
Nov 18, 2022



Trajectory prediction is a fundamental problem and challenge for autonomous vehicles. Early works mainly focused on designing complicated architectures for deep-learning-based prediction models in normal-illumination environments, which fail in dealing with low-light conditions. This paper proposes a novel approach for trajectory prediction in low-illumination scenarios by leveraging multi-stream information fusion, which flexibly integrates image, optical flow, and object trajectory information. The image channel employs Convolutional Neural Network (CNN) and Long Short-term Memory (LSTM) networks to extract temporal information from the camera. The optical flow channel is applied to capture the pattern of relative motion between adjacent camera frames and modelled by Spatial-Temporal Graph Convolutional Network (ST-GCN). The trajectory channel is used to recognize high-level interactions between vehicles. Finally, information from all the three channels is effectively fused in the prediction module to generate future trajectories of surrounding vehicles in low-illumination conditions. The proposed multi-channel graph convolutional approach is validated on HEV-I and newly generated Dark-HEV-I, egocentric vision datasets that primarily focus on urban intersection scenarios. The results demonstrate that our method outperforms the baselines, in standard and low-illumination scenarios. Additionally, our approach is generic and applicable to scenarios with different types of perception data. The source code of the proposed approach is available at https://github.com/TommyGong08/MSIF}{https://github.com/TommyGong08/MSIF.
Graph Reinforcement Learning Application to Co-operative Decision-Making in Mixed Autonomy Traffic: Framework, Survey, and Challenges
Nov 06, 2022Proper functioning of connected and automated vehicles (CAVs) is crucial for the safety and efficiency of future intelligent transport systems. Meanwhile, transitioning to fully autonomous driving requires a long period of mixed autonomy traffic, including both CAVs and human-driven vehicles. Thus, collaboration decision-making for CAVs is essential to generate appropriate driving behaviors to enhance the safety and efficiency of mixed autonomy traffic. In recent years, deep reinforcement learning (DRL) has been widely used in solving decision-making problems. However, the existing DRL-based methods have been mainly focused on solving the decision-making of a single CAV. Using the existing DRL-based methods in mixed autonomy traffic cannot accurately represent the mutual effects of vehicles and model dynamic traffic environments. To address these shortcomings, this article proposes a graph reinforcement learning (GRL) approach for multi-agent decision-making of CAVs in mixed autonomy traffic. First, a generic and modular GRL framework is designed. Then, a systematic review of DRL and GRL methods is presented, focusing on the problems addressed in recent research. Moreover, a comparative study on different GRL methods is further proposed based on the designed framework to verify the effectiveness of GRL methods. Results show that the GRL methods can well optimize the performance of multi-agent decision-making for CAVs in mixed autonomy traffic compared to the DRL methods. Finally, challenges and future research directions are summarized. This study can provide a valuable research reference for solving the multi-agent decision-making problems of CAVs in mixed autonomy traffic and can promote the implementation of GRL-based methods into intelligent transportation systems. The source code of our work can be found at https://github.com/Jacklinkk/Graph_CAVs.
QuEst: Graph Transformer for Quantum Circuit Reliability Estimation
Oct 30, 2022Among different quantum algorithms, PQC for QML show promises on near-term devices. To facilitate the QML and PQC research, a recent python library called TorchQuantum has been released. It can construct, simulate, and train PQC for machine learning tasks with high speed and convenient debugging supports. Besides quantum for ML, we want to raise the community's attention on the reversed direction: ML for quantum. Specifically, the TorchQuantum library also supports using data-driven ML models to solve problems in quantum system research, such as predicting the impact of quantum noise on circuit fidelity and improving the quantum circuit compilation efficiency. This paper presents a case study of the ML for quantum part. Since estimating the noise impact on circuit reliability is an essential step toward understanding and mitigating noise, we propose to leverage classical ML to predict noise impact on circuit fidelity. Inspired by the natural graph representation of quantum circuits, we propose to leverage a graph transformer model to predict the noisy circuit fidelity. We firstly collect a large dataset with a variety of quantum circuits and obtain their fidelity on noisy simulators and real machines. Then we embed each circuit into a graph with gate and noise properties as node features, and adopt a graph transformer to predict the fidelity. Evaluated on 5 thousand random and algorithm circuits, the graph transformer predictor can provide accurate fidelity estimation with RMSE error 0.04 and outperform a simple neural network-based model by 0.02 on average. It can achieve 0.99 and 0.95 R$^2$ scores for random and algorithm circuits, respectively. Compared with circuit simulators, the predictor has over 200X speedup for estimating the fidelity.
Adaptive Decision Making at the Intersection for Autonomous Vehicles Based on Skill Discovery
Jul 24, 2022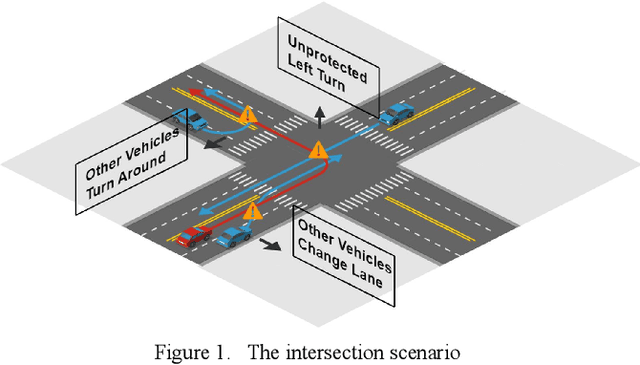
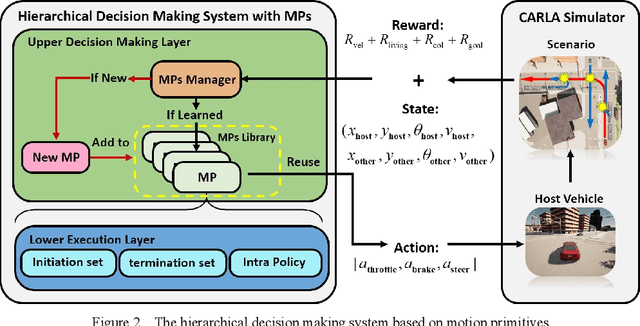
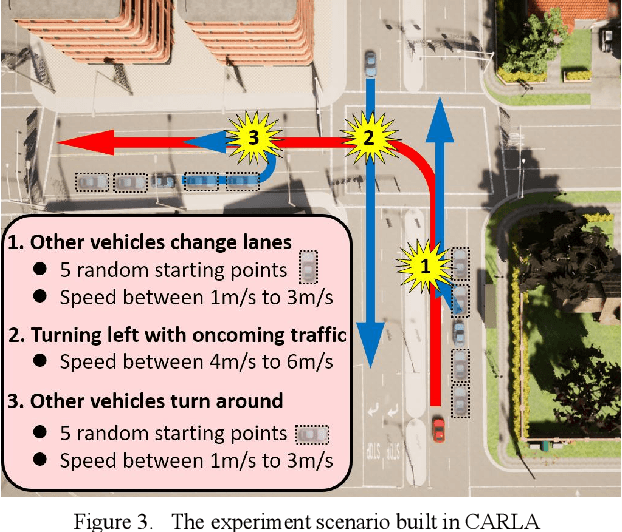
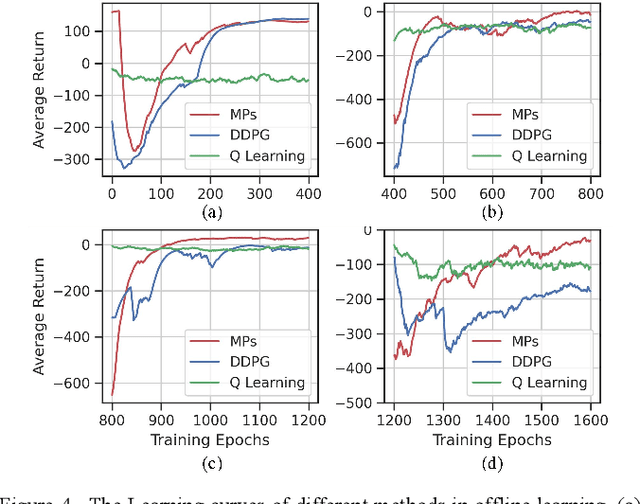
In urban environments, the complex and uncertain intersection scenarios are challenging for autonomous driving. To ensure safety, it is crucial to develop an adaptive decision making system that can handle the interaction with other vehicles. Manually designed model-based methods are reliable in common scenarios. But in uncertain environments, they are not reliable, so learning-based methods are proposed, especially reinforcement learning (RL) methods. However, current RL methods need retraining when the scenarios change. In other words, current RL methods cannot reuse accumulated knowledge. They forget learned knowledge when new scenarios are given. To solve this problem, we propose a hierarchical framework that can autonomously accumulate and reuse knowledge. The proposed method combines the idea of motion primitives (MPs) with hierarchical reinforcement learning (HRL). It decomposes complex problems into multiple basic subtasks to reduce the difficulty. The proposed method and other baseline methods are tested in a challenging intersection scenario based on the CARLA simulator. The intersection scenario contains three different subtasks that can reflect the complexity and uncertainty of real traffic flow. After offline learning and testing, the proposed method is proved to have the best performance among all methods.
Prediction-Based Reachability Analysis for Collision Risk Assessment on Highways
May 03, 2022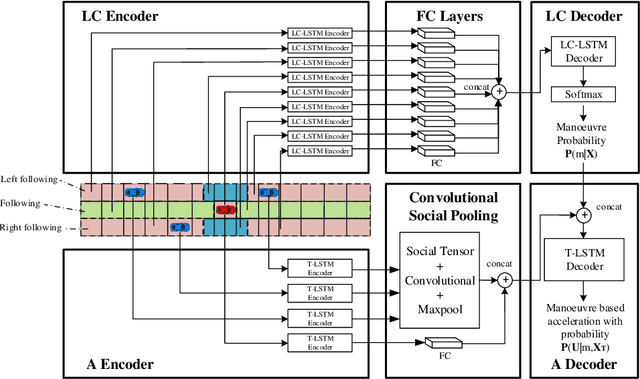
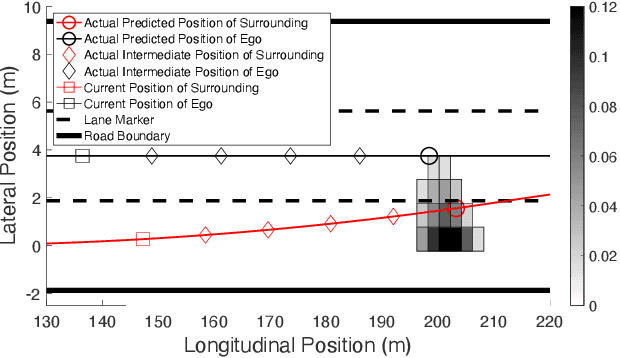
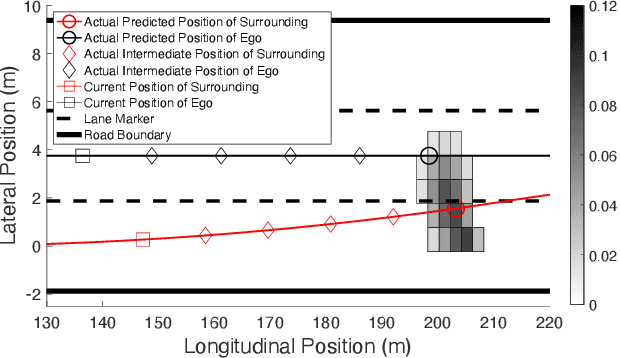
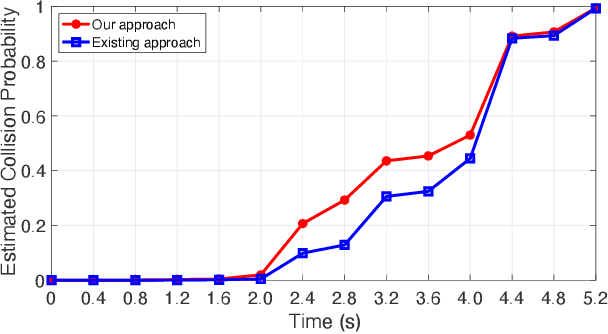
Real-time safety systems are crucial components of intelligent vehicles. This paper introduces a prediction-based collision risk assessment approach on highways. Given a point mass vehicle dynamics system, a stochastic forward reachable set considering two-dimensional motion with vehicle state probability distributions is firstly established. We then develop an acceleration prediction model, which provides multi-modal probabilistic acceleration distributions to propagate vehicle states. The collision probability is calculated by summing up the probabilities of the states where two vehicles spatially overlap. Simulation results show that the prediction model has superior performance in terms of vehicle motion position errors, and the proposed collision detection approach is agile and effective to identify the collision in cut-in crash events.