 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource Consumption Threats in Large Language Models
Mar 17, 2026Given limited and costly computational infrastructure, resource efficiency is a key requirement for large language models (LLMs). Efficient LLMs increase service capacity for providers and reduce latency and API costs for users. Recent resource consumption threats induce excessive generation, degrading model efficiency and harming both service availability and economic sustainability. This survey presents a systematic review of threats to resource consumption in LLMs. We further establish a unified view of this emerging area by clarifying its scope and examining the problem along the full pipeline from threat induction to mechanism understanding and mitigation. Our goal is to clarify the problem landscape for this emerging area, thereby providing a clearer foundation for characterization and mitigation.
Ego to World: Collaborative Spatial Reasoning in Embodied Systems via Reinforcement Learning
Mar 16, 2026Understanding the world from distributed, partial viewpoints is a fundamental challenge for embodied multi-agent systems. Each agent perceives the environment through an ego-centric view that is often limited by occlusion and ambiguity. To study this problem, we introduce the Ego-to-World (E2W) benchmark, which evaluates a vision-language model's ability to fuse heterogeneous viewpoints across three tasks: (i) global counting, (ii) relational location reasoning, and (iii) action-oriented grasping that requires predicting view-specific image coordinates. To address this setting, we propose CoRL, a two-stage framework that combines Chain-of-Thought supervised fine-tuning with reinforcement learning using Group-Relative Policy Optimization. Its core component, the Cross-View Spatial Reward (CVSR), provides dense task-aligned feedback by linking reasoning steps to visual evidence, ensuring coherent cross-view entity resolution, and guiding the model toward correct final predictions. Experiments on E2W show that CoRL consistently surpasses strong proprietary and open-source baselines on both reasoning and perception-grounding metrics, while ablations further confirm the necessity of each CVSR component. Beyond that, CoRL generalizes to external spatial reasoning benchmarks and enables effective real-world multi-robot manipulation with calibrated multi-camera rigs, demonstrating cross-view localization and successful grasp-and-place execution. Together, E2W and CoRL provide a principled foundation for learning world-centric scene understanding from distributed, ego-centric observations, advancing collaborative embodied AI.
HomeSafe-Bench: Evaluating Vision-Language Models on Unsafe Action Detection for Embodied Agents in Household Scenarios
Mar 12, 2026The rapid evolution of embodied agents has accelerated the deployment of household robots in real-world environments. However, unlike structured industrial settings, household spaces introduce unpredictable safety risks, where system limitations such as perception latency and lack of common sense knowledge can lead to dangerous errors. Current safety evaluations, often restricted to static images, text, or general hazards, fail to adequately benchmark dynamic unsafe action detection in these specific contexts. To bridge this gap, we introduce \textbf{HomeSafe-Bench}, a challenging benchmark designed to evaluate Vision-Language Models (VLMs) on unsafe action detection in household scenarios. HomeSafe-Bench is contrusted via a hybrid pipeline combining physical simulation with advanced video generation and features 438 diverse cases across six functional areas with fine-grained multidimensional annotations. Beyond benchmarking, we propose \textbf{Hierarchical Dual-Brain Guard for Household Safety (HD-Guard)}, a hierarchical streaming architecture for real-time safety monitoring. HD-Guard coordinates a lightweight FastBrain for continuous high-frequency screening with an asynchronous large-scale SlowBrain for deep multimodal reasoning, effectively balancing inference efficiency with detection accuracy. Evaluations demonstrate that HD-Guard achieves a superior trade-off between latency and performance, while our analysis identifies critical bottlenecks in current VLM-based safety detection.
Text2Traffic: A Text-to-Image Generation and Editing Method for Traffic Scenes
Nov 17, 2025With the rapid advancement of intelligent transportation systems, text-driven image generation and editing techniques have demonstrated significant potential in providing rich, controllable visual scene data for applications such as traffic monitoring and autonomous driving. However, several challenges remain, including insufficient semantic richness of generated traffic elements, limited camera viewpoints, low visual fidelity of synthesized images, and poor alignment between textual descriptions and generated content. To address these issues, we propose a unified text-driven framework for both image generation and editing, leveraging a controllable mask mechanism to seamlessly integrate the two tasks. Furthermore, we incorporate both vehicle-side and roadside multi-view data to enhance the geometric diversity of traffic scenes. Our training strategy follows a two-stage paradigm: first, we perform conceptual learning using large-scale coarse-grained text-image data; then, we fine-tune with fine-grained descriptive data to enhance text-image alignment and detail quality. Additionally, we introduce a mask-region-weighted loss that dynamically emphasizes small yet critical regions during training, thereby substantially enhancing the generation fidelity of small-scale traffic elements. Extensive experiments demonstrate that our method achieves leading performance in text-based image generation and editing within traffic scenes.
InternVL-X: Advancing and Accelerating InternVL Series with Efficient Visual Token Compression
Mar 27, 2025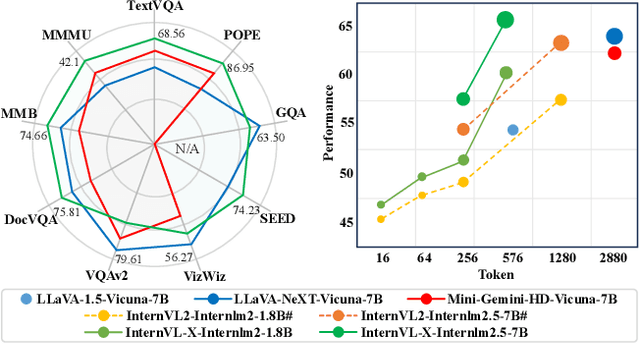
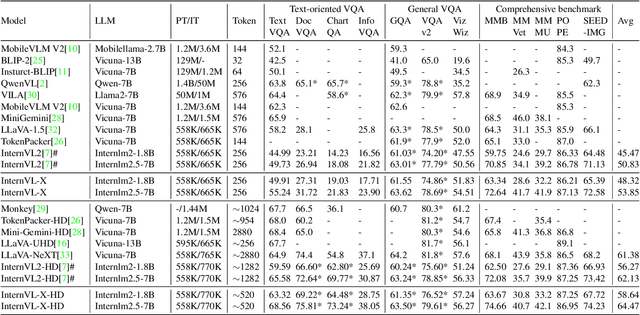


Most multimodal large language models (MLLMs) treat visual tokens as "a sequence of text", integrating them with text tokens into a large language model (LLM). However, a great quantity of visual tokens significantly increases the demand for computational resources and time. In this paper, we propose InternVL-X, which outperforms the InternVL model in both performance and efficiency by incorporating three visual token compression methods. First, we propose a novel vision-language projector, PVTC. This component integrates adjacent visual embeddings to form a local query and utilizes the transformed CLS token as a global query, then performs point-to-region cross-attention through these local and global queries to more effectively convert visual features. Second, we present a layer-wise visual token compression module, LVTC, which compresses tokens in the LLM shallow layers and then expands them through upsampling and residual connections in the deeper layers. This significantly enhances the model computational efficiency. Futhermore, we propose an efficient high resolution slicing method, RVTC, which dynamically adjusts the number of visual tokens based on image area or length filtering. RVTC greatly enhances training efficiency with only a slight reduction in performance. By utilizing 20% or fewer visual tokens, InternVL-X achieves state-of-the-art performance on 7 public MLLM benchmarks, and improves the average metric by 2.34% across 12 tasks.
A Semantic Loss Function for Deep Learning with Symbolic Knowledge
Jun 08, 2018

This paper develops a novel methodology for using symbolic knowledge in deep learning. From first principles, we derive a semantic loss function that bridges between neural output vectors and logical constraints. This loss function captures how close the neural network is to satisfying the constraints on its output. An experimental evaluation shows that it effectively guides the learner to achieve (near-)state-of-the-art results on semi-supervised multi-class classification. Moreover, it significantly increases the ability of the neural network to predict structured objects, such as rankings and paths. These discrete concepts are tremendously difficult to learn, and benefit from a tight integration of deep learning and symbolic reasoning methods.