 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepLatent: Think with Images via Parallel Latent Visual Reasoning
May 30, 2026The emerging paradigm of "thinking with images" embeds visual states into intermediate reasoning steps, defining a new frontier for Vision-Language Models. Existing approaches diverge along two lines. Tool-assisted methods apply explicit visual operations but suffer from high latency and restricted manipulation types. Latent reasoning methods autoregressively produce implicit visual states, but underperform tool-assisted methods, and their latent tokens fail to capture effective visual information. In this work, we propose DeepLatent, a parallel framework for latent visual reasoning. First, we introduce LatentFormer. It uses learnable 2D tokens to generate context-conditioned latent states in parallel, anchoring every visual update directly in the original image features. Second, we design a continuous-space reinforcement learning algorithm. It optimizes latent modulation parameters directly in the embedding space, significantly improving latent representation quality. The framework is trained via knowledge distillation followed by this continuous-space RL algorithm. Furthermore, we contribute DeepLatent-180K, a large-scale dataset tailored for latent visual reasoning. Extensive evaluations across multiple benchmarks demonstrate that DeepLatent achieves state-of-the-art performance.
RT-DATR:Real-time Unsupervised Domain Adaptive Detection Transformer with Adversarial Feature Learning
Apr 12, 2025



Despite domain-adaptive object detectors based on CNN and transformers have made significant progress in cross-domain detection tasks, it is regrettable that domain adaptation for real-time transformer-based detectors has not yet been explored. Directly applying existing domain adaptation algorithms has proven to be suboptimal. In this paper, we propose RT-DATR, a simple and efficient real-time domain adaptive detection transformer. Building on RT-DETR as our base detector, we first introduce a local object-level feature alignment module to significantly enhance the feature representation of domain invariance during object transfer. Additionally, we introduce a scene semantic feature alignment module designed to boost cross-domain detection performance by aligning scene semantic features. Finally, we introduced a domain query and decoupled it from the object query to further align the instance feature distribution within the decoder layer, reduce the domain gap, and maintain discriminative ability. Experimental results on various benchmarks demonstrate that our method outperforms current state-of-the-art approaches. Our code will be released soon.
InternVL-X: Advancing and Accelerating InternVL Series with Efficient Visual Token Compression
Mar 27, 2025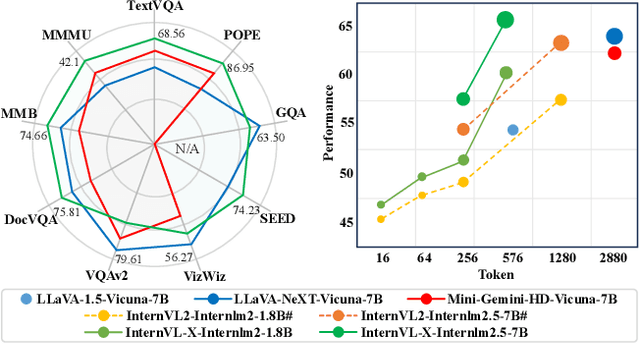
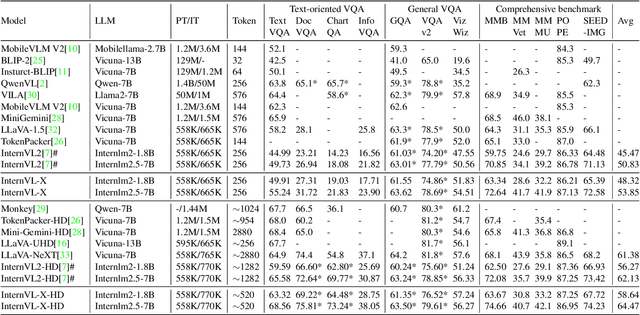


Most multimodal large language models (MLLMs) treat visual tokens as "a sequence of text", integrating them with text tokens into a large language model (LLM). However, a great quantity of visual tokens significantly increases the demand for computational resources and time. In this paper, we propose InternVL-X, which outperforms the InternVL model in both performance and efficiency by incorporating three visual token compression methods. First, we propose a novel vision-language projector, PVTC. This component integrates adjacent visual embeddings to form a local query and utilizes the transformed CLS token as a global query, then performs point-to-region cross-attention through these local and global queries to more effectively convert visual features. Second, we present a layer-wise visual token compression module, LVTC, which compresses tokens in the LLM shallow layers and then expands them through upsampling and residual connections in the deeper layers. This significantly enhances the model computational efficiency. Futhermore, we propose an efficient high resolution slicing method, RVTC, which dynamically adjusts the number of visual tokens based on image area or length filtering. RVTC greatly enhances training efficiency with only a slight reduction in performance. By utilizing 20% or fewer visual tokens, InternVL-X achieves state-of-the-art performance on 7 public MLLM benchmarks, and improves the average metric by 2.34% across 12 tasks.