 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Compatible Fine-tuning for Vision-Language Model Updates
Dec 30, 2024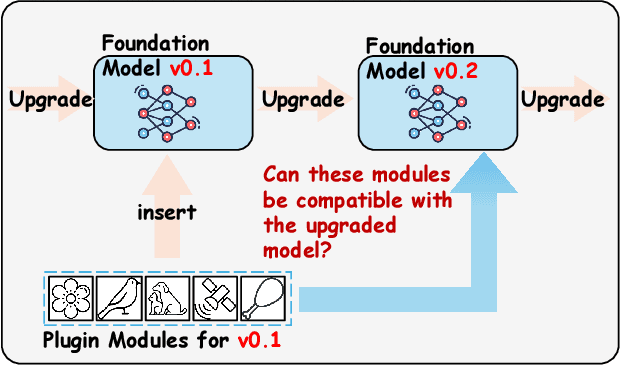
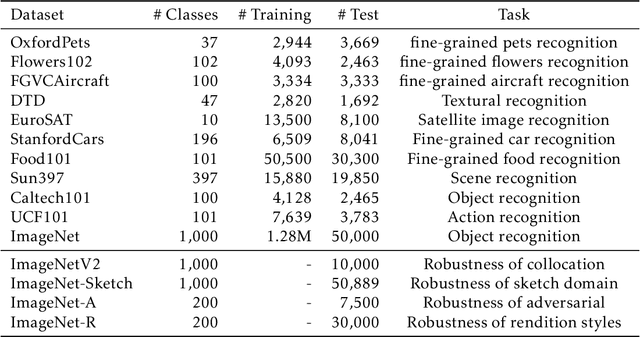
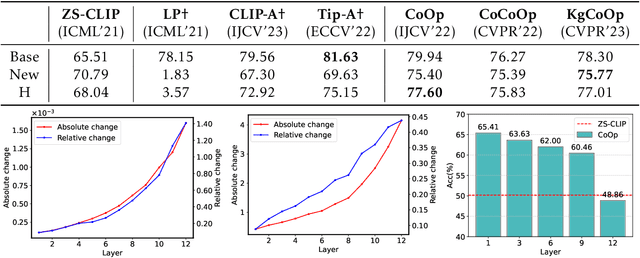
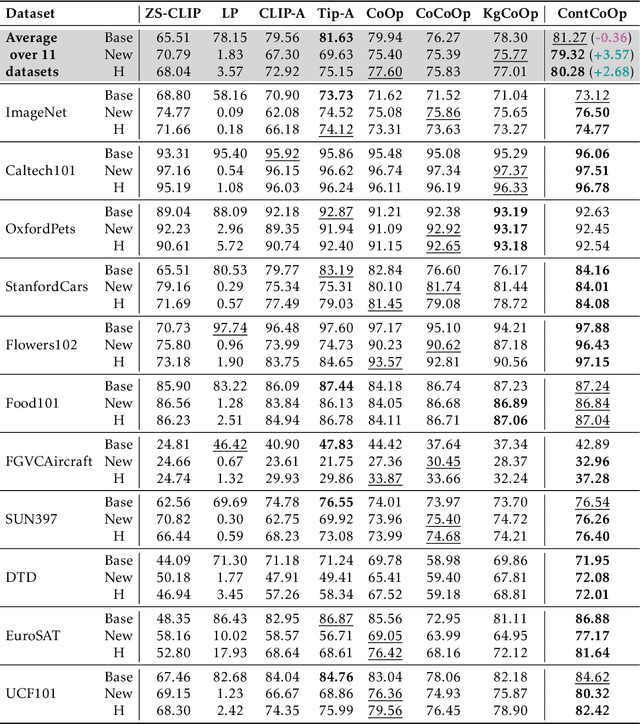
So far, efficient fine-tuning has become a popular strategy for enhancing the capabilities of foundation models on downstream tasks by learning plug-and-play modules. However, existing methods overlook a crucial issue: if the underlying foundation model is updated, are these plug-and-play modules still effective? In this paper, we first conduct a detailed analysis of various fine-tuning methods on the CLIP in terms of their compatibility with model updates. The study reveals that many high-performing fine-tuning methods fail to be compatible with the upgraded models. To address this, we propose a novel approach, Class-conditioned Context Optimization (ContCoOp), which integrates learnable prompts with class embeddings using an attention layer before inputting them into the text encoder. Consequently, the prompts can dynamically adapt to the changes in embedding space (due to model updates), ensuring continued effectiveness. Extensive experiments over 15 datasets show that our ContCoOp achieves the highest compatibility over the baseline methods, and exhibits robust out-of-distribution generalization.
Task Preference Optimization: Improving Multimodal Large Language Models with Vision Task Alignment
Dec 26, 2024Current multimodal large language models (MLLMs) struggle with fine-grained or precise understanding of visuals though they give comprehensive perception and reasoning in a spectrum of vision applications. Recent studies either develop tool-using or unify specific visual tasks into the autoregressive framework, often at the expense of overall multimodal performance. To address this issue and enhance MLLMs with visual tasks in a scalable fashion, we propose Task Preference Optimization (TPO), a novel method that utilizes differentiable task preferences derived from typical fine-grained visual tasks. TPO introduces learnable task tokens that establish connections between multiple task-specific heads and the MLLM. By leveraging rich visual labels during training, TPO significantly enhances the MLLM's multimodal capabilities and task-specific performance. Through multi-task co-training within TPO, we observe synergistic benefits that elevate individual task performance beyond what is achievable through single-task training methodologies. Our instantiation of this approach with VideoChat and LLaVA demonstrates an overall 14.6% improvement in multimodal performance compared to baseline models. Additionally, MLLM-TPO demonstrates robust zero-shot capabilities across various tasks, performing comparably to state-of-the-art supervised models. The code will be released at https://github.com/OpenGVLab/TPO
DIVE: Subgraph Disagreement for Graph Out-of-Distribution Generalization
Aug 08, 2024This paper addresses the challenge of out-of-distribution (OOD) generalization in graph machine learning, a field rapidly advancing yet grappling with the discrepancy between source and target data distributions. Traditional graph learning algorithms, based on the assumption of uniform distribution between training and test data, falter in real-world scenarios where this assumption fails, resulting in suboptimal performance. A principal factor contributing to this suboptimal performance is the inherent simplicity bias of neural networks trained through Stochastic Gradient Descent (SGD), which prefer simpler features over more complex yet equally or more predictive ones. This bias leads to a reliance on spurious correlations, adversely affecting OOD performance in various tasks such as image recognition, natural language understanding, and graph classification. Current methodologies, including subgraph-mixup and information bottleneck approaches, have achieved partial success but struggle to overcome simplicity bias, often reinforcing spurious correlations. To tackle this, we propose DIVE, training a collection of models to focus on all label-predictive subgraphs by encouraging the models to foster divergence on the subgraph mask, which circumvents the limitation of a model solely focusing on the subgraph corresponding to simple structural patterns. Specifically, we employs a regularizer to punish overlap in extracted subgraphs across models, thereby encouraging different models to concentrate on distinct structural patterns. Model selection for robust OOD performance is achieved through validation accuracy. Tested across four datasets from GOOD benchmark and one dataset from DrugOOD benchmark, our approach demonstrates significant improvement over existing methods, effectively addressing the simplicity bias and enhancing generalization in graph machine learning.
Connecting the Dots: Collaborative Fine-tuning for Black-Box Vision-Language Models
Feb 06, 2024With the emergence of pretrained vision-language models (VLMs), considerable efforts have been devoted to fine-tuning them for downstream tasks. Despite the progress made in designing efficient fine-tuning methods, such methods require access to the model's parameters, which can be challenging as model owners often opt to provide their models as a black box to safeguard model ownership. This paper proposes a \textbf{C}ollabo\textbf{ra}tive \textbf{F}ine-\textbf{T}uning (\textbf{CraFT}) approach for fine-tuning black-box VLMs to downstream tasks, where one only has access to the input prompts and the output predictions of the model. CraFT comprises two modules, a prompt generation module for learning text prompts and a prediction refinement module for enhancing output predictions in residual style. Additionally, we introduce an auxiliary prediction-consistent loss to promote consistent optimization across these modules. These modules are optimized by a novel collaborative training algorithm. Extensive experiments on few-shot classification over 15 datasets demonstrate the superiority of CraFT. The results show that CraFT achieves a decent gain of about 12\% with 16-shot datasets and only 8,000 queries. Moreover, CraFT trains faster and uses only about 1/80 of the memory footprint for deployment, while sacrificing only 1.62\% compared to the white-box method.
A Hard-to-Beat Baseline for Training-free CLIP-based Adaptation
Feb 06, 2024



Contrastive Language-Image Pretraining (CLIP) has gained popularity for its remarkable zero-shot capacity. Recent research has focused on developing efficient fine-tuning methods, such as prompt learning and adapter, to enhance CLIP's performance in downstream tasks. However, these methods still require additional training time and computational resources, which is undesirable for devices with limited resources. In this paper, we revisit a classical algorithm, Gaussian Discriminant Analysis (GDA), and apply it to the downstream classification of CLIP. Typically, GDA assumes that features of each class follow Gaussian distributions with identical covariance. By leveraging Bayes' formula, the classifier can be expressed in terms of the class means and covariance, which can be estimated from the data without the need for training. To integrate knowledge from both visual and textual modalities, we ensemble it with the original zero-shot classifier within CLIP. Extensive results on 17 datasets validate that our method surpasses or achieves comparable results with state-of-the-art methods on few-shot classification, imbalanced learning, and out-of-distribution generalization. In addition, we extend our method to base-to-new generalization and unsupervised learning, once again demonstrating its superiority over competing approaches. Our code is publicly available at \url{https://github.com/mrflogs/ICLR24}.
Not all Minorities are Equal: Empty-Class-Aware Distillation for Heterogeneous Federated Learning
Jan 04, 2024



Data heterogeneity, characterized by disparities in local data distribution across clients, poses a significant challenge in federated learning. Substantial efforts have been devoted to addressing the heterogeneity in local label distribution. As minority classes suffer from worse accuracy due to overfitting on local imbalanced data, prior methods often incorporate class-balanced learning techniques during local training. Despite the improved mean accuracy across all classes, we observe that empty classes-referring to categories absent from a client's data distribution-are still not well recognized. This paper introduces FedED, a novel approach in heterogeneous federated learning that integrates both empty-class distillation and logit suppression simultaneously. Specifically, empty-class distillation leverages knowledge distillation during local training on each client to retain essential information related to empty classes from the global model. Moreover, logit suppression directly penalizes network logits for non-label classes, effectively addressing misclassifications in minority classes that may be biased toward majority classes. Extensive experiments validate the efficacy of FedED, surpassing previous state-of-the-art methods across diverse datasets with varying degrees of label distribution shift.
TagAlign: Improving Vision-Language Alignment with Multi-Tag Classification
Dec 26, 2023



The crux of learning vision-language models is to extract semantically aligned information from visual and linguistic data. Existing attempts usually face the problem of coarse alignment, e.g., the vision encoder struggles in localizing an attribute-specified object. In this work, we propose an embarrassingly simple approach to better align image and text features with no need of additional data formats other than image-text pairs. Concretely, given an image and its paired text, we manage to parse objects (e.g., cat) and attributes (e.g., black) from the description, which are highly likely to exist in the image. It is noteworthy that the parsing pipeline is fully automatic and thus enjoys good scalability. With these parsed semantics as supervision signals, we can complement the commonly used image-text contrastive loss with the multi-tag classification loss. Extensive experimental results on a broad suite of semantic segmentation datasets substantiate the average 3.65\% improvement of our framework over existing alternatives. Furthermore, the visualization results indicate that attribute supervision makes vision-language models accurately localize attribute-specified objects. Project page and code can be found at https://qinying-liu.github.io/Tag-Align.
Revisiting Foreground and Background Separation in Weakly-supervised Temporal Action Localization: A Clustering-based Approach
Dec 21, 2023



Weakly-supervised temporal action localization aims to localize action instances in videos with only video-level action labels. Existing methods mainly embrace a localization-by-classification pipeline that optimizes the snippet-level prediction with a video classification loss. However, this formulation suffers from the discrepancy between classification and detection, resulting in inaccurate separation of foreground and background (F\&B) snippets. To alleviate this problem, we propose to explore the underlying structure among the snippets by resorting to unsupervised snippet clustering, rather than heavily relying on the video classification loss. Specifically, we propose a novel clustering-based F\&B separation algorithm. It comprises two core components: a snippet clustering component that groups the snippets into multiple latent clusters and a cluster classification component that further classifies the cluster as foreground or background. As there are no ground-truth labels to train these two components, we introduce a unified self-labeling mechanism based on optimal transport to produce high-quality pseudo-labels that match several plausible prior distributions. This ensures that the cluster assignments of the snippets can be accurately associated with their F\&B labels, thereby boosting the F\&B separation. We evaluate our method on three benchmarks: THUMOS14, ActivityNet v1.2 and v1.3. Our method achieves promising performance on all three benchmarks while being significantly more lightweight than previous methods. Code is available at https://github.com/Qinying-Liu/CASE
Exploiting Low-confidence Pseudo-labels for Source-free Object Detection
Oct 19, 2023Source-free object detection (SFOD) aims to adapt a source-trained detector to an unlabeled target domain without access to the labeled source data. Current SFOD methods utilize a threshold-based pseudo-label approach in the adaptation phase, which is typically limited to high-confidence pseudo-labels and results in a loss of information. To address this issue, we propose a new approach to take full advantage of pseudo-labels by introducing high and low confidence thresholds. Specifically, the pseudo-labels with confidence scores above the high threshold are used conventionally, while those between the low and high thresholds are exploited using the Low-confidence Pseudo-labels Utilization (LPU) module. The LPU module consists of Proposal Soft Training (PST) and Local Spatial Contrastive Learning (LSCL). PST generates soft labels of proposals for soft training, which can mitigate the label mismatch problem. LSCL exploits the local spatial relationship of proposals to improve the model's ability to differentiate between spatially adjacent proposals, thereby optimizing representational features further. Combining the two components overcomes the challenges faced by traditional methods in utilizing low-confidence pseudo-labels. Extensive experiments on five cross-domain object detection benchmarks demonstrate that our proposed method outperforms the previous SFOD methods, achieving state-of-the-art performance.
Improving Zero-Shot Generalization for CLIP with Synthesized Prompts
Jul 14, 2023With the growing interest in pretrained vision-language models like CLIP, recent research has focused on adapting these models to downstream tasks. Despite achieving promising results, most existing methods require labeled data for all classes, which may not hold in real-world applications due to the long tail and Zipf's law. For example, some classes may lack labeled data entirely, such as emerging concepts. To address this problem, we propose a plug-and-play generative approach called \textbf{S}ynt\textbf{H}es\textbf{I}zed \textbf{P}rompts~(\textbf{SHIP}) to improve existing fine-tuning methods. Specifically, we follow variational autoencoders to introduce a generator that reconstructs the visual features by inputting the synthesized prompts and the corresponding class names to the textual encoder of CLIP. In this manner, we easily obtain the synthesized features for the remaining label-only classes. Thereafter, we fine-tune CLIP with off-the-shelf methods by combining labeled and synthesized features. Extensive experiments on base-to-new generalization, cross-dataset transfer learning, and generalized zero-shot learning demonstrate the superiority of our approach. The code is available at \url{https://github.com/mrflogs/SHIP}.