 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaSolidGeo: A Dynamic Benchmark for Genuine Spatial Mathematical Reasoning of VLMs in Solid Geometry
Oct 25, 2025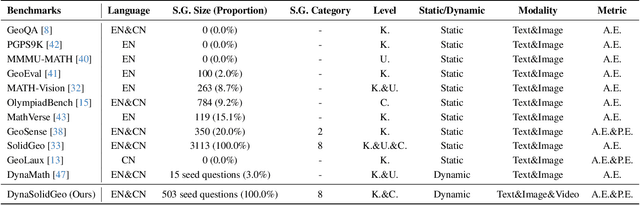

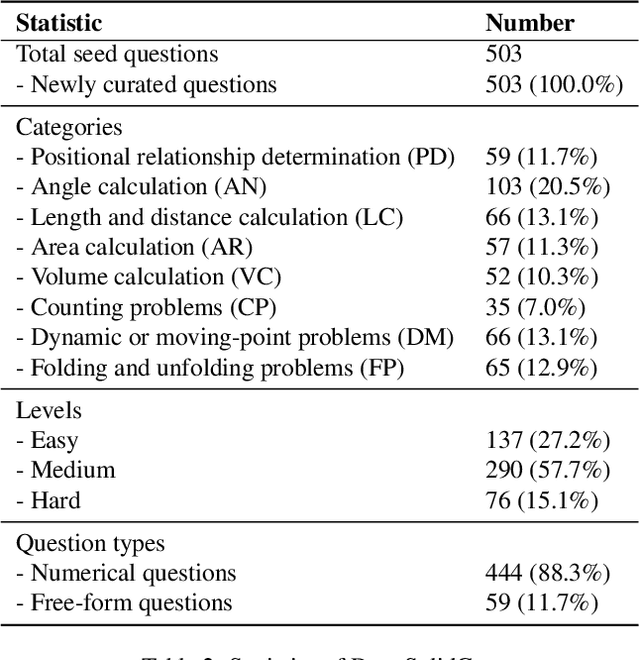

Solid geometry problem solving demands spatial mathematical reasoning that integrates spatial intelligence and symbolic reasoning. However, most existing multimodal mathematical reasoning benchmarks focus primarily on 2D plane geometry, rely on static datasets prone to data contamination and memorization, and evaluate models solely by final answers, overlooking the reasoning process. To address these limitations, we introduce DynaSolidGeo, the first dynamic benchmark for evaluating genuine spatial reasoning in Vision-Language Models (VLMs). Constructed through a semi-automatic annotation pipeline, DynaSolidGeo contains 503 expert-curated seed questions that can, in principle, dynamically generate an unbounded number of diverse multimodal text-visual instances. Beyond answer accuracy, we incorporate process evaluation based on expert-annotated reasoning chains to measure logical validity and causal coherence. Experiments across representative open-source and closed-source VLMs reveal large performance gaps, severe degradation in dynamic settings, and poor performance on tasks requiring high-level spatial intelligence, such as mental rotation and visualization. The code and dataset are available at \href{https://zgca-ai4edu.github.io/DynaSolidGeo/}{DynaSolidGeo}.
MLVTG: Mamba-Based Feature Alignment and LLM-Driven Purification for Multi-Modal Video Temporal Grounding
Jun 10, 2025Video Temporal Grounding (VTG), which aims to localize video clips corresponding to natural language queries, is a fundamental yet challenging task in video understanding. Existing Transformer-based methods often suffer from redundant attention and suboptimal multi-modal alignment. To address these limitations, we propose MLVTG, a novel framework that integrates two key modules: MambaAligner and LLMRefiner. MambaAligner uses stacked Vision Mamba blocks as a backbone instead of Transformers to model temporal dependencies and extract robust video representations for multi-modal alignment. LLMRefiner leverages the specific frozen layer of a pre-trained Large Language Model (LLM) to implicitly transfer semantic priors, enhancing multi-modal alignment without fine-tuning. This dual alignment strategy, temporal modeling via structured state-space dynamics and semantic purification via textual priors, enables more precise localization. Extensive experiments on QVHighlights, Charades-STA, and TVSum demonstrate that MLVTG achieves state-of-the-art performance and significantly outperforms existing baselines.
Rethinking Metrics and Benchmarks of Video Anomaly Detection
May 25, 2025Video Anomaly Detection (VAD), which aims to detect anomalies that deviate from expectation, has attracted increasing attention in recent years. Existing advancements in VAD primarily focus on model architectures and training strategies, while devoting insufficient attention to evaluation metrics and benchmarks. In this paper, we rethink VAD evaluation protocols through comprehensive experimental analyses, revealing three critical limitations in current practices: 1) existing metrics are significantly influenced by single annotation bias; 2) current metrics fail to reward early detection of anomalies; 3) available benchmarks lack the capability to evaluate scene overfitting. To address these limitations, we propose three novel evaluation methods: first, we establish averaged AUC/AP metrics over multi-round annotations to mitigate single annotation bias; second, we develop a Latency-aware Average Precision (LaAP) metric that rewards early and accurate anomaly detection; and finally, we introduce two hard normal benchmarks (UCF-HN, MSAD-HN) with videos specifically designed to evaluate scene overfitting. We report performance comparisons of ten state-of-the-art VAD approaches using our proposed evaluation methods, providing novel perspectives for future VAD model development.
Separate to Collaborate: Dual-Stream Diffusion Model for Coordinated Piano Hand Motion Synthesis
Apr 14, 2025Automating the synthesis of coordinated bimanual piano performances poses significant challenges, particularly in capturing the intricate choreography between the hands while preserving their distinct kinematic signatures. In this paper, we propose a dual-stream neural framework designed to generate synchronized hand gestures for piano playing from audio input, addressing the critical challenge of modeling both hand independence and coordination. Our framework introduces two key innovations: (i) a decoupled diffusion-based generation framework that independently models each hand's motion via dual-noise initialization, sampling distinct latent noise for each while leveraging a shared positional condition, and (ii) a Hand-Coordinated Asymmetric Attention (HCAA) mechanism suppresses symmetric (common-mode) noise to highlight asymmetric hand-specific features, while adaptively enhancing inter-hand coordination during denoising. The system operates hierarchically: it first predicts 3D hand positions from audio features and then generates joint angles through position-aware diffusion models, where parallel denoising streams interact via HCAA. Comprehensive evaluations demonstrate that our framework outperforms existing state-of-the-art methods across multiple metrics.
Curiosity-Diffuser: Curiosity Guide Diffusion Models for Reliability
Mar 19, 2025One of the bottlenecks in robotic intelligence is the instability of neural network models, which, unlike control models, lack a well-defined convergence domain and stability. This leads to risks when applying intelligence in the physical world. Specifically, imitation policy based on neural network may generate hallucinations, leading to inaccurate behaviors that impact the safety of real-world applications. To address this issue, this paper proposes the Curiosity-Diffuser, aimed at guiding the conditional diffusion model to generate trajectories with lower curiosity, thereby improving the reliability of policy. The core idea is to use a Random Network Distillation (RND) curiosity module to assess whether the model's behavior aligns with the training data, and then minimize curiosity by classifier guidance diffusion to reduce overgeneralization during inference. Additionally, we propose a computationally efficient metric for evaluating the reliability of the policy, measuring the similarity between the generated behaviors and the training dataset, to facilitate research about reliability learning. Finally, simulation verify the effectiveness and applicability of the proposed method to a variety of scenarios, showing that Curiosity-Diffuser significantly improves task performance and produces behaviors that are more similar to the training data. The code for this work is available at: github.com/CarlDegio/Curiosity-Diffuser
Language-guided Open-world Video Anomaly Detection
Mar 17, 2025



Video anomaly detection models aim to detect anomalies that deviate from what is expected. In open-world scenarios, the expected events may change as requirements change. For example, not wearing a mask is considered abnormal during a flu outbreak but normal otherwise. However, existing methods assume that the definition of anomalies is invariable, and thus are not applicable to the open world. To address this, we propose a novel open-world VAD paradigm with variable definitions, allowing guided detection through user-provided natural language at inference time. This paradigm necessitates establishing a robust mapping from video and textual definition to anomaly score. Therefore, we propose LaGoVAD (Language-guided Open-world VAD), a model that dynamically adapts anomaly definitions through two regularization strategies: diversifying the relative durations of anomalies via dynamic video synthesis, and enhancing feature robustness through contrastive learning with negative mining. Training such adaptable models requires diverse anomaly definitions, but existing datasets typically provide given labels without semantic descriptions. To bridge this gap, we collect PreVAD (Pre-training Video Anomaly Dataset), the largest and most diverse video anomaly dataset to date, featuring 35,279 annotated videos with multi-level category labels and descriptions that explicitly define anomalies. Zero-shot experiments on seven datasets demonstrate SOTA performance. Data and code will be released.
DNMDR: Dynamic Networks and Multi-view Drug Representations for Safe Medication Recommendation
Jan 15, 2025



Medication Recommendation (MR) is a promising research topic which booms diverse applications in the healthcare and clinical domains. However, existing methods mainly rely on sequential modeling and static graphs for representation learning, which ignore the dynamic correlations in diverse medical events of a patient's temporal visits, leading to insufficient global structural exploration on nodes. Additionally, mitigating drug-drug interactions (DDIs) is another issue determining the utility of the MR systems. To address the challenges mentioned above, this paper proposes a novel MR method with the integration of dynamic networks and multi-view drug representations (DNMDR). Specifically, weighted snapshot sequences for dynamic heterogeneous networks are constructed based on discrete visits in temporal EHRs, and all the dynamic networks are jointly trained to gain both structural correlations in diverse medical events and temporal dependency in historical health conditions, for achieving comprehensive patient representations with both semantic features and structural relationships. Moreover, combining the drug co-occurrences and adverse drug-drug interactions (DDIs) in internal view of drug molecule structure and interactive view of drug pairs, the safe drug representations are available to obtain high-quality medication combination recommendation. Finally, extensive experiments on real world datasets are conducted for performance evaluation, and the experimental results demonstrate that the proposed DNMDR method outperforms the state-of-the-art baseline models with a large margin on various metrics such as PRAUC, Jaccard, DDI rates and so on.
Unicorn: Unified Neural Image Compression with One Number Reconstruction
Dec 11, 2024Prevalent lossy image compression schemes can be divided into: 1) explicit image compression (EIC), including traditional standards and neural end-to-end algorithms; 2) implicit image compression (IIC) based on implicit neural representations (INR). The former is encountering impasses of either leveling off bitrate reduction at a cost of tremendous complexity while the latter suffers from excessive smoothing quality as well as lengthy decoder models. In this paper, we propose an innovative paradigm, which we dub \textbf{Unicorn} (\textbf{U}nified \textbf{N}eural \textbf{I}mage \textbf{C}ompression with \textbf{O}ne \textbf{N}number \textbf{R}econstruction). By conceptualizing the images as index-image pairs and learning the inherent distribution of pairs in a subtle neural network model, Unicorn can reconstruct a visually pleasing image from a randomly generated noise with only one index number. The neural model serves as the unified decoder of images while the noises and indexes corresponds to explicit representations. As a proof of concept, we propose an effective and efficient prototype of Unicorn based on latent diffusion models with tailored model designs. Quantitive and qualitative experimental results demonstrate that our prototype achieves significant bitrates reduction compared with EIC and IIC algorithms. More impressively, benefitting from the unified decoder, our compression ratio escalates as the quantity of images increases. We envision that more advanced model designs will endow Unicorn with greater potential in image compression. We will release our codes in \url{https://github.com/uniqzheng/Unicorn-Laduree}.
Asynchronous Event-Inertial Odometry using a Unified Gaussian Process Regression Framework
Dec 04, 2024



Recent works have combined monocular event camera and inertial measurement unit to estimate the $SE(3)$ trajectory. However, the asynchronicity of event cameras brings a great challenge to conventional fusion algorithms. In this paper, we present an asynchronous event-inertial odometry under a unified Gaussian Process (GP) regression framework to naturally fuse asynchronous data associations and inertial measurements. A GP latent variable model is leveraged to build data-driven motion prior and acquire the analytical integration capacity. Then, asynchronous event-based feature associations and integral pseudo measurements are tightly coupled using the same GP framework. Subsequently, this fusion estimation problem is solved by underlying factor graph in a sliding-window manner. With consideration of sparsity, those historical states are marginalized orderly. A twin system is also designed for comparison, where the traditional inertial preintegration scheme is embedded in the GP-based framework to replace the GP latent variable model. Evaluations on public event-inertial datasets demonstrate the validity of both systems. Comparison experiments show competitive precision compared to the state-of-the-art synchronous scheme.
Self-reconfiguration Strategies for Space-distributed Spacecraft
Nov 26, 2024



This paper proposes a distributed on-orbit spacecraft assembly algorithm, where future spacecraft can assemble modules with different functions on orbit to form a spacecraft structure with specific functions. This form of spacecraft organization has the advantages of reconfigurability, fast mission response and easy maintenance. Reasonable and efficient on-orbit self-reconfiguration algorithms play a crucial role in realizing the benefits of distributed spacecraft. This paper adopts the framework of imitation learning combined with reinforcement learning for strategy learning of module handling order. A robot arm motion algorithm is then designed to execute the handling sequence. We achieve the self-reconfiguration handling task by creating a map on the surface of the module, completing the path point planning of the robotic arm using A*. The joint planning of the robotic arm is then accomplished through forward and reverse kinematics. Finally, the results are presented in Unity3D.