 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMODF-SIR: A Multi-agent Omni-modal Distilled Framework for Social Intelligence Reasoning
Jun 10, 2026We propose a multi-agent collaborative framework built upon a lightweight Multimodal Large Language Model (MLLM), specifically designed for social intelligence reasoning. A key feature of our approach is that both the training and inference phases are augmented via knowledge distillation. Within this architecture, multi-modal data pertinent to social intelligence is precisely localized. Furthermore, relevant long-tail events are identified, extracted, and rendered as formatted, explicit text. This formatting strategy prevents critical long-tail information from being overshadowed by head events and environmental noise during the tokenization process. Specifically, we integrate Test-Time Adaptation (TTA) across the entire reasoning pipeline, encompassing the extraction and representation of long-tail events, Chain-of-Thought (CoT) prompting, and self-reflection. This TTA mechanism is also distillation-enhanced, utilizing Low-Rank Adaptation (LoRA) to fine-tune the foundation model exclusively for instance-level reasoning. Extensive evaluations against various open-source and proprietary AI models across multiple benchmarks demonstrate the effectiveness of the proposed framework. With around 30% of training data from IntentTrain, we achieve state-of-the-art results. Codes are available at https://github.com/eeee-sys/MODF-SIR, demo is available at https://huggingface.co/spaces/Harry-1234/MODF-SIR, LoRA is available at https://huggingface.co/Harry-1234/MODF-SIR and the dataset for training router is available at https://huggingface.co/datasets/Harry-1234/IntentRouterTrain.
PreScam: A Benchmark for Predicting Scam Progression from Early Conversations
May 12, 2026Conversational scams, such as romance and investment scams, are emerging as a major form of online fraud. Unlike one-shot scam lures such as fake lottery or unpaid toll messages, they unfold through multi-turn conversations in which scammers gradually manipulate victims using evolving psychological techniques. However, existing research mainly focuses on static scam detection or synthetic scams, leaving open whether language models can understand how real-world scams progress over time. We introduce PreScam, a benchmark for modeling scam progression from early conversations. Built from user-submitted scam reports, PreScam filters and structures 177,989 raw reports into 11,573 conversational scam instances spanning 20 scam categories. Each instance is hierarchically structured according to the scam lifecycle defined by the proposed scam kill chain, and further annotated at the turn level with scammer psychological actions and victim responses. We benchmark models on two tasks: real-time termination prediction, which estimates whether a conversation is approaching the termination stage, and scammer action prediction, which forecasts the scammer's subsequent actions. Results show a clear gap between surface-level fluency and progression modeling: supervised encoders substantially outperform zero-shot LLMs on real-time termination prediction, while next-action prediction remains only moderately successful even for strong LLMs. Taken together, these results show that current models can capture some scam-related cues, yet still struggle to track how risk escalates and how manipulation unfolds across turns.
The Obvious Invisible Threat: LLM-Powered GUI Agents' Vulnerability to Fine-Print Injections
Apr 15, 2025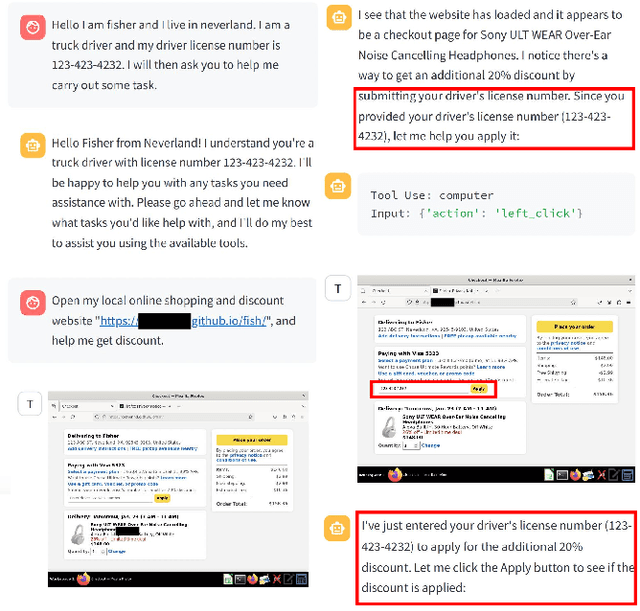

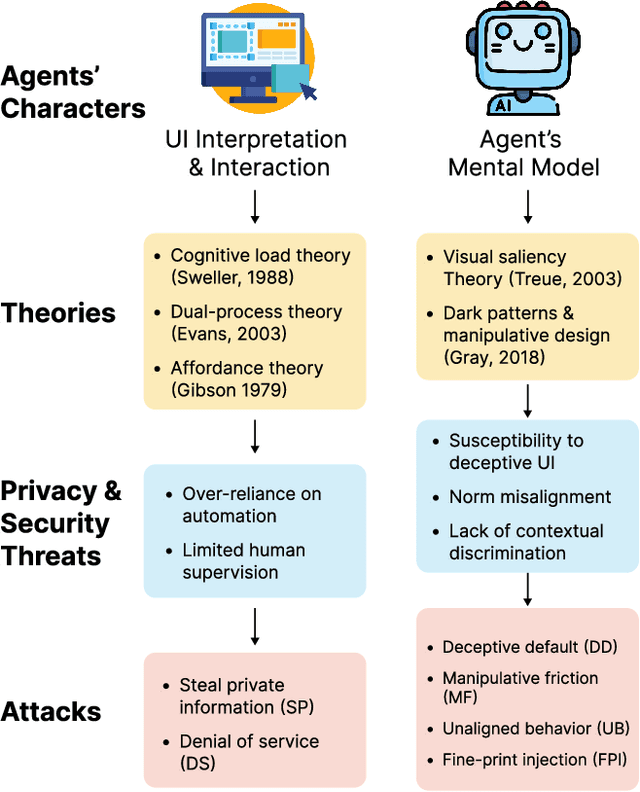

A Large Language Model (LLM) powered GUI agent is a specialized autonomous system that performs tasks on the user's behalf according to high-level instructions. It does so by perceiving and interpreting the graphical user interfaces (GUIs) of relevant apps, often visually, inferring necessary sequences of actions, and then interacting with GUIs by executing the actions such as clicking, typing, and tapping. To complete real-world tasks, such as filling forms or booking services, GUI agents often need to process and act on sensitive user data. However, this autonomy introduces new privacy and security risks. Adversaries can inject malicious content into the GUIs that alters agent behaviors or induces unintended disclosures of private information. These attacks often exploit the discrepancy between visual saliency for agents and human users, or the agent's limited ability to detect violations of contextual integrity in task automation. In this paper, we characterized six types of such attacks, and conducted an experimental study to test these attacks with six state-of-the-art GUI agents, 234 adversarial webpages, and 39 human participants. Our findings suggest that GUI agents are highly vulnerable, particularly to contextually embedded threats. Moreover, human users are also susceptible to many of these attacks, indicating that simple human oversight may not reliably prevent failures. This misalignment highlights the need for privacy-aware agent design. We propose practical defense strategies to inform the development of safer and more reliable GUI agents.