 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchINR: Patch-Based Implicit Neural Representations for Efficient and Scalable Inference
Jun 24, 2026Implicit Neural Representation (INR) provides an effective approach for continuous signal modeling, but classical per-pixel inference results in quadratic growth in inference count, leading to dramatically increased computational costs in high-resolution application scenarios. To address this issue, we propose a patch-based approach that treats non-overlapping patches as fundamental processing units and predicts entire pixel patches in a single forward pass, significantly reducing the number of inference queries required. To validate the effectiveness of our approach, we propose a hardware acceleration architecture on the Field Programmable Gate Array (FPGA) platform for the INR model, which features a configurable pipeline and supports dual-precision computation. Our patch-based INR achieves comparable reconstruction quality to pixel-level INR (34.97 dB PSNR with 2 x 2 patches) while reducing inference latency by 75% with only 0.6% parameter overhead.
Model Evolution Under Zeroth-Order Optimization: A Neural Tangent Kernel Perspective
Mar 22, 2026Zeroth-order (ZO) optimization enables memory-efficient training of neural networks by estimating gradients via forward passes only, eliminating the need for backpropagation. However, the stochastic nature of gradient estimation significantly obscures the training dynamics, in contrast to the well-characterized behavior of first-order methods under Neural Tangent Kernel (NTK) theory. To address this, we introduce the Neural Zeroth-order Kernel (NZK) to describe model evolution in function space under ZO updates. For linear models, we prove that the expected NZK remains constant throughout training and depends explicitly on the first and second moments of the random perturbation directions. This invariance yields a closed-form expression for model evolution under squared loss. We further extend the analysis to linearized neural networks. Interpreting ZO updates as kernel gradient descent via NZK provides a novel perspective for potentially accelerating convergence. Extensive experiments across synthetic and real-world datasets (including MNIST, CIFAR-10, and Tiny ImageNet) validate our theoretical results and demonstrate acceleration when using a single shared random vector.
Can We Trust LLMs on Memristors? Diving into Reasoning Ability under Non-Ideality
Mar 14, 2026Memristor-based analog compute-in-memory (CIM) architectures provide a promising substrate for the efficient deployment of Large Language Models (LLMs), owing to superior energy efficiency and computational density. However, these architectures suffer from precision issues caused by intrinsic non-idealities of memristors. In this paper, we first conduct a comprehensive investigation into the impact of such typical non-idealities on LLM reasoning. Empirical results indicate that reasoning capability decreases significantly but varies for distinct benchmarks. Subsequently, we systematically appraise three training-free strategies, including thinking mode, in-context learning, and module redundancy. We thus summarize valuable guidelines, i.e., shallow layer redundancy is particularly effective for improving robustness, thinking mode performs better under low noise levels but degrades at higher noise, and in-context learning reduces output length with a slight performance trade-off. Our findings offer new insights into LLM reasoning under non-ideality and practical strategies to improve robustness.
UIS-Digger: Towards Comprehensive Research Agent Systems for Real-world Unindexed Information Seeking
Mar 11, 2026Recent advancements in LLM-based information-seeking agents have achieved record-breaking performance on established benchmarks. However, these agents remain heavily reliant on search-engine-indexed knowledge, leaving a critical blind spot: Unindexed Information Seeking (UIS). This paper identifies and explores the UIS problem, where vital information is not captured by search engine crawlers, such as overlooked content, dynamic webpages, and embedded files. Despite its significance, UIS remains an underexplored challenge. To address this gap, we introduce UIS-QA, the first dedicated UIS benchmark, comprising 110 expert-annotated QA pairs. Notably, even state-of-the-art agents experience a drastic performance drop on UIS-QA (e.g., from 70.90 on GAIA and 46.70 on BrowseComp-zh to 24.55 on UIS-QA), underscoring the severity of the problem. To mitigate this, we propose UIS-Digger, a novel multi-agent framework that incorporates dual-mode browsing and enables simultaneous webpage searching and file parsing. With a relatively small $\sim$30B-parameter backbone LLM optimized using SFT and RFT training strategies, UIS-Digger sets a strong baseline at 27.27\%, outperforming systems integrating sophisticated LLMs such as O3 and GPT-4.1. This demonstrates the importance of proactive interaction with unindexed sources for effective and comprehensive information-seeking. Our work not only uncovers a fundamental limitation in current agent evaluation paradigms but also provides the first toolkit for advancing UIS research, defining a new and promising direction for robust information-seeking systems.
InjectRBP: Steering Large Language Model Reasoning Behavior via Pattern Injection
Feb 12, 2026Reasoning can significantly enhance the performance of Large Language Models. While recent studies have exploited behavior-related prompts adjustment to enhance reasoning, these designs remain largely intuitive and lack a systematic analysis of the underlying behavioral patterns. Motivated by this, we investigate how models' reasoning behaviors shape reasoning from the perspective of behavioral patterns. We observe that models exhibit adaptive distributions of reasoning behaviors when responding to specific types of questions, and that structurally injecting these patterns can substantially influence the quality of the models' reasoning processes and outcomes. Building on these findings, we propose two optimization methods that require no parameter updates: InjectCorrect and InjectRLOpt. InjectCorrect guides the model by imitating behavioral patterns derived from its own past correct answers. InjectRLOpt learns a value function from historical behavior-pattern data and, via our proposed Reliability-Aware Softmax Policy, generates behavioral injectant during inference to steer the reasoning process. Our experiments demonstrate that both methods can improve model performance across various reasoning tasks without requiring any modifications to model parameters, achieving gains of up to 5.34% and 8.67%, respectively.
OVD: On-policy Verbal Distillation
Jan 29, 2026Knowledge distillation offers a promising path to transfer reasoning capabilities from large teacher models to efficient student models; however, existing token-level on-policy distillation methods require token-level alignment between the student and teacher models, which restricts the student model's exploration ability, prevent effective use of interactive environment feedback, and suffer from severe memory bottlenecks in reinforcement learning. We introduce On-policy Verbal Distillation (OVD), a memory-efficient framework that replaces token-level probability matching with trajectory matching using discrete verbal scores (0--9) from teacher models. OVD dramatically reduces memory consumption while enabling on-policy distillation from teacher models with verbal feedback, and avoids token-level alignment, allowing the student model to freely explore the output space. Extensive experiments on Web question answering and mathematical reasoning tasks show that OVD substantially outperforms existing methods, delivering up to +12.9% absolute improvement in average EM on Web Q&A tasks and a up to +25.7% gain on math benchmarks (when trained with only one random samples), while also exhibiting superior training efficiency. Our project page is available at https://OVD.github.io
Hybrid Mesh-Gaussian Representation for Efficient Indoor Scene Reconstruction
Jun 08, 20253D Gaussian splatting (3DGS) has demonstrated exceptional performance in image-based 3D reconstruction and real-time rendering. However, regions with complex textures require numerous Gaussians to capture significant color variations accurately, leading to inefficiencies in rendering speed. To address this challenge, we introduce a hybrid representation for indoor scenes that combines 3DGS with textured meshes. Our approach uses textured meshes to handle texture-rich flat areas, while retaining Gaussians to model intricate geometries. The proposed method begins by pruning and refining the extracted mesh to eliminate geometrically complex regions. We then employ a joint optimization for 3DGS and mesh, incorporating a warm-up strategy and transmittance-aware supervision to balance their contributions seamlessly.Extensive experiments demonstrate that the hybrid representation maintains comparable rendering quality and achieves superior frames per second FPS with fewer Gaussian primitives.
PhyX: Does Your Model Have the "Wits" for Physical Reasoning?
May 21, 2025



Existing benchmarks fail to capture a crucial aspect of intelligence: physical reasoning, the integrated ability to combine domain knowledge, symbolic reasoning, and understanding of real-world constraints. To address this gap, we introduce PhyX: the first large-scale benchmark designed to assess models capacity for physics-grounded reasoning in visual scenarios. PhyX includes 3K meticulously curated multimodal questions spanning 6 reasoning types across 25 sub-domains and 6 core physics domains: thermodynamics, electromagnetism, mechanics, modern physics, optics, and wave\&acoustics. In our comprehensive evaluation, even state-of-the-art models struggle significantly with physical reasoning. GPT-4o, Claude3.7-Sonnet, and GPT-o4-mini achieve only 32.5\%, 42.2\%, and 45.8\% accuracy respectively-performance gaps exceeding 29\% compared to human experts. Our analysis exposes critical limitations in current models: over-reliance on memorized disciplinary knowledge, excessive dependence on mathematical formulations, and surface-level visual pattern matching rather than genuine physical understanding. We provide in-depth analysis through fine-grained statistics, detailed case studies, and multiple evaluation paradigms to thoroughly examine physical reasoning capabilities. To ensure reproducibility, we implement a compatible evaluation protocol based on widely-used toolkits such as VLMEvalKit, enabling one-click evaluation.
HaLoRA: Hardware-aware Low-Rank Adaptation for Large Language Models Based on Hybrid Compute-in-Memory Architecture
Feb 27, 2025
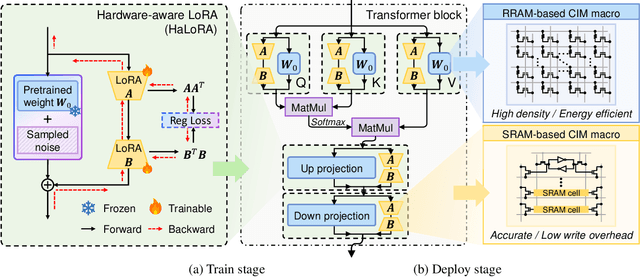
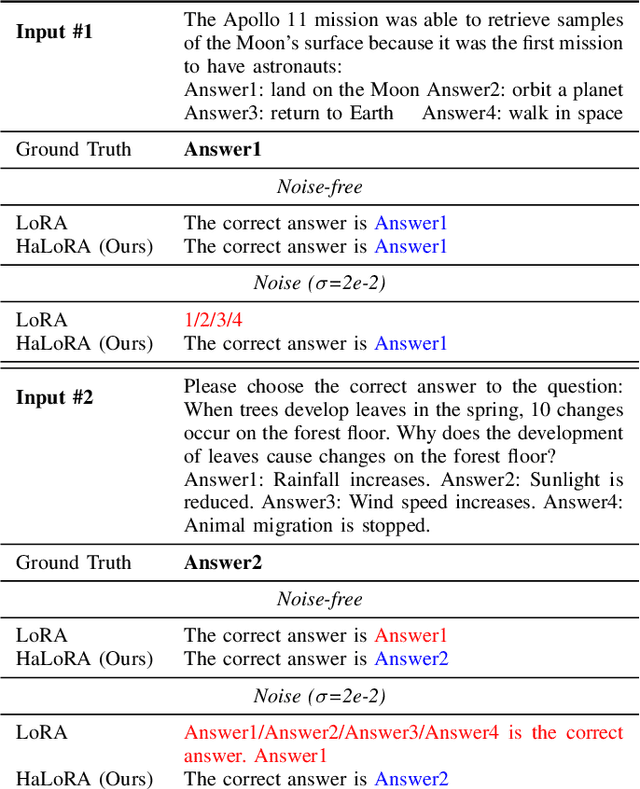
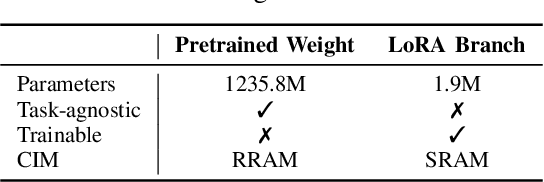
Low-rank adaptation (LoRA) is a predominant parameter-efficient finetuning method to adapt large language models (LLMs) for downstream tasks. In this paper, we first propose to deploy the LoRA-finetuned LLMs on the hybrid compute-in-memory (CIM) architecture (i.e., pretrained weights onto RRAM and LoRA onto SRAM). To address performance degradation from RRAM's inherent noise, we design a novel Hardware-aware Low-rank Adaption (HaLoRA) method, aiming to train a LoRA branch that is both robust and accurate by aligning the training objectives under both ideal and noisy conditions. Experiments finetuning LLaMA 3.2 1B and 3B demonstrate HaLoRA's effectiveness across multiple reasoning tasks, achieving up to 22.7 improvement in average score while maintaining robustness at various noise levels.
Instance by Instance: An Iterative Framework for Multi-instance 3D Registration
Feb 06, 2024



Multi-instance registration is a challenging problem in computer vision and robotics, where multiple instances of an object need to be registered in a standard coordinate system. In this work, we propose the first iterative framework called instance-by-instance (IBI) for multi-instance 3D registration (MI-3DReg). It successively registers all instances in a given scenario, starting from the easiest and progressing to more challenging ones. Throughout the iterative process, outliers are eliminated continuously, leading to an increasing inlier rate for the remaining and more challenging instances. Under the IBI framework, we further propose a sparse-to-dense-correspondence-based multi-instance registration method (IBI-S2DC) to achieve robust MI-3DReg. Experiments on the synthetic and real datasets have demonstrated the effectiveness of IBI and suggested the new state-of-the-art performance of IBI-S2DC, e.g., our MHF1 is 12.02%/12.35% higher than the existing state-of-the-art method ECC on the synthetic/real datasets.