 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeaveBench: A Long-Horizon, Real-World Benchmark for Computer-Use Agents with Hybrid Interfaces
Jun 08, 2026Computer-use agents (CUAs) increasingly operate in runtimes that combine visual desktop control, command-line execution, code editing, browsers, and external tools. Existing benchmarks, however, often evaluate these interfaces as separable capabilities, leaving long-horizon cross-interface orchestration under-tested. Thus, we introduce WeaveBench, a long-horizon hybrid-interface benchmark with 114 tasks across 8 real-world work domains, grounded in real user requests and publicly verifiable artifacts. Each task requires agents to combine GUI observations/actions with CLI/code operations within a single trajectory. We evaluate these tasks on a real Ubuntu desktop inside deployed CLI-agent runtimes, augmented with a minimal desktop-control plugin. We also propose a companion trajectory-aware judge that inspects deliverables, files, screenshots, logs, and action traces, while detecting shortcut behaviors such as fabricated visual evidence or hard-coded metrics. Across frontier model-runtime pairings, the best PassRate reaches only 41.2%, showing the benchmark remains far from saturated. The trajectory-aware judge further reveals that outcome-only grading substantially overestimates agent performance. Overall, WeaveBench exposes a critical gap in CUA evaluation and provides an effective testbed to measure whether agents can orchestrate GUI, CLI, and code operations across long-horizon real-world tasks.
Efficient Long-Horizon GUI Agents via Training-Free KV Cache Compression
Feb 27, 2026Large Vision-Language Models (VLMs) have emerged as powerful engines for autonomous GUI agents, yet their deployment is severely constrained by the substantial memory footprint and latency of the Key-Value (KV) cache during long-horizon interactions. While existing cache compression methods have proven effective for LLMs, we empirically demonstrate that they suffer from suboptimal performance in GUI scenarios due to a fundamental misalignment: unlike general visual tasks where attention sparsity varies across layers, GUI attention patterns exhibit uniform high-sparsity across all transformer layers. Motivated by this insight, we propose ST-Lite, a training-free KV cache compression framework tailored for efficient GUI agents that explicitly addresses the dynamic spatio-trajectory dependencies within GUI data streams. ST-Lite introduces a novel dual-branch scoring policy incorporating Component-centric Spatial Saliency (CSS) and Trajectory-aware Semantic Gating (TSG). Specifically, CSS preserves the structural integrity of interactive UI elements by evaluating local neighborhood saliency, while TSG mitigates historical redundancy by dynamically filtering visually repetitive KV pairs within the interaction trajectory. Extensive evaluations demonstrate that with only a 10-20% cache budget, ST-Lite achieves a 2.45x decoding acceleration while maintaining comparable or even superior performance compared to full-cache baselines, offering a scalable solution for resource-constrained GUI agents.
Spatio-Temporal Token Pruning for Efficient High-Resolution GUI Agents
Feb 26, 2026Pure-vision GUI agents provide universal interaction capabilities but suffer from severe efficiency bottlenecks due to the massive spatiotemporal redundancy inherent in high-resolution screenshots and historical trajectories. We identify two critical misalignments in existing compression paradigms: the temporal mismatch, where uniform history encoding diverges from the agent's "fading memory" attention pattern, and the spatial topology conflict, where unstructured pruning compromises the grid integrity required for precise coordinate grounding, inducing spatial hallucinations. To address these challenges, we introduce GUIPruner, a training-free framework tailored for high-resolution GUI navigation. It synergizes Temporal-Adaptive Resolution (TAR), which eliminates historical redundancy via decay-based resizing, and Stratified Structure-aware Pruning (SSP), which prioritizes interactive foregrounds and semantic anchors while safeguarding global layout. Extensive evaluations across diverse benchmarks demonstrate that GUIPruner consistently achieves state-of-the-art performance, effectively preventing the collapse observed in large-scale models under high compression. Notably, on Qwen2-VL-2B, our method delivers a 3.4x reduction in FLOPs and a 3.3x speedup in vision encoding latency while retaining over 94% of the original performance, enabling real-time, high-precision navigation with minimal resource consumption.
Target-Balanced Score Distillation
Nov 12, 2025Score Distillation Sampling (SDS) enables 3D asset generation by distilling priors from pretrained 2D text-to-image diffusion models, but vanilla SDS suffers from over-saturation and over-smoothing. To mitigate this issue, recent variants have incorporated negative prompts. However, these methods face a critical trade-off: limited texture optimization, or significant texture gains with shape distortion. In this work, we first conduct a systematic analysis and reveal that this trade-off is fundamentally governed by the utilization of the negative prompts, where Target Negative Prompts (TNP) that embed target information in the negative prompts dramatically enhancing texture realism and fidelity but inducing shape distortions. Informed by this key insight, we introduce the Target-Balanced Score Distillation (TBSD). It formulates generation as a multi-objective optimization problem and introduces an adaptive strategy that effectively resolves the aforementioned trade-off. Extensive experiments demonstrate that TBSD significantly outperforms existing state-of-the-art methods, yielding 3D assets with high-fidelity textures and geometrically accurate shape.
Co-Learning: Code Learning for Multi-Agent Reinforcement Collaborative Framework with Conversational Natural Language Interfaces
Sep 02, 2024



Online question-and-answer (Q\&A) systems based on the Large Language Model (LLM) have progressively diverged from recreational to professional use. This paper proposed a Multi-Agent framework with environmentally reinforcement learning (E-RL) for code correction called Code Learning (Co-Learning) community, assisting beginners to correct code errors independently. It evaluates the performance of multiple LLMs from an original dataset with 702 error codes, uses it as a reward or punishment criterion for E-RL; Analyzes input error codes by the current agent; selects the appropriate LLM-based agent to achieve optimal error correction accuracy and reduce correction time. Experiment results showed that 3\% improvement in Precision score and 15\% improvement in time cost as compared with no E-RL method respectively. Our source code is available at: https://github.com/yuqian2003/Co_Learning
DailyDVS-200: A Comprehensive Benchmark Dataset for Event-Based Action Recognition
Jul 06, 2024



Neuromorphic sensors, specifically event cameras, revolutionize visual data acquisition by capturing pixel intensity changes with exceptional dynamic range, minimal latency, and energy efficiency, setting them apart from conventional frame-based cameras. The distinctive capabilities of event cameras have ignited significant interest in the domain of event-based action recognition, recognizing their vast potential for advancement. However, the development in this field is currently slowed by the lack of comprehensive, large-scale datasets, which are critical for developing robust recognition frameworks. To bridge this gap, we introduces DailyDVS-200, a meticulously curated benchmark dataset tailored for the event-based action recognition community. DailyDVS-200 is extensive, covering 200 action categories across real-world scenarios, recorded by 47 participants, and comprises more than 22,000 event sequences. This dataset is designed to reflect a broad spectrum of action types, scene complexities, and data acquisition diversity. Each sequence in the dataset is annotated with 14 attributes, ensuring a detailed characterization of the recorded actions. Moreover, DailyDVS-200 is structured to facilitate a wide range of research paths, offering a solid foundation for both validating existing approaches and inspiring novel methodologies. By setting a new benchmark in the field, we challenge the current limitations of neuromorphic data processing and invite a surge of new approaches in event-based action recognition techniques, which paves the way for future explorations in neuromorphic computing and beyond. The dataset and source code are available at https://github.com/QiWang233/DailyDVS-200.
Non-negative Sparse and Collaborative Representation for Pattern Classification
Aug 29, 2019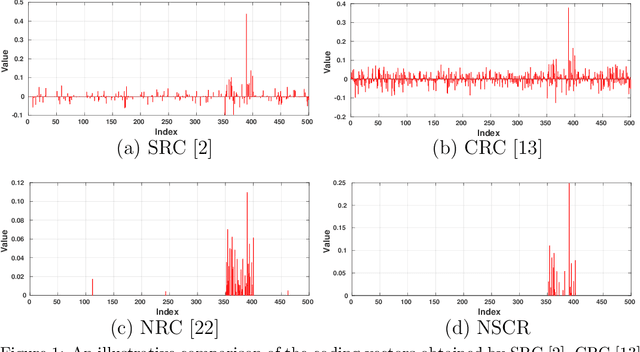

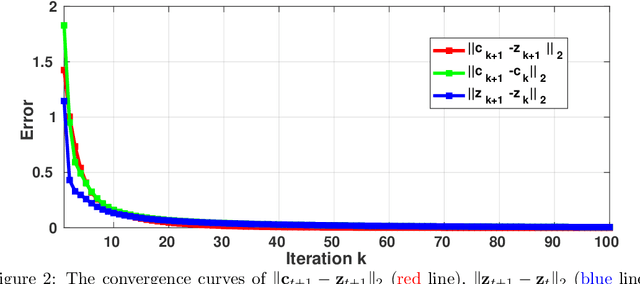

Sparse representation (SR) and collaborative representation (CR) have been successfully applied in many pattern classification tasks such as face recognition. In this paper, we propose a novel Non-negative Sparse and Collaborative Representation (NSCR) for pattern classification. The NSCR representation of each test sample is obtained by seeking a non-negative sparse and collaborative representation vector that represents the test sample as a linear combination of training samples. We observe that the non-negativity can make the SR and CR more discriminative and effective for pattern classification. Based on the proposed NSCR, we propose a NSCR based classifier for pattern classification. Extensive experiments on benchmark datasets demonstrate that the proposed NSCR based classifier outperforms the previous SR or CR based approach, as well as state-of-the-art deep approaches, on diverse challenging pattern classification tasks.