 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Coding for Machines with Omnipotent Feature Learning
Jul 07, 2022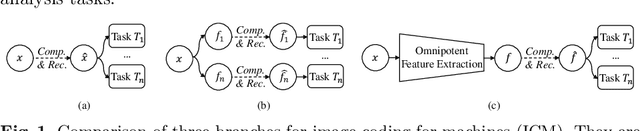


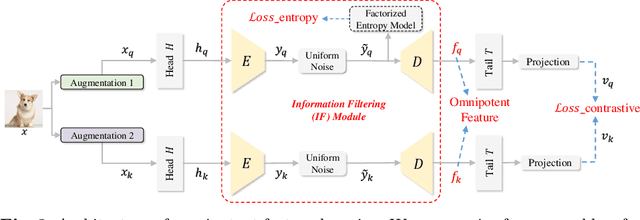
Image Coding for Machines (ICM) aims to compress images for AI tasks analysis rather than meeting human perception. Learning a kind of feature that is both general (for AI tasks) and compact (for compression) is pivotal for its success. In this paper, we attempt to develop an ICM framework by learning universal features while also considering compression. We name such features as omnipotent features and the corresponding framework as Omni-ICM. Considering self-supervised learning (SSL) improves feature generalization, we integrate it with the compression task into the Omni-ICM framework to learn omnipotent features. However, it is non-trivial to coordinate semantics modeling in SSL and redundancy removing in compression, so we design a novel information filtering (IF) module between them by co-optimization of instance distinguishment and entropy minimization to adaptively drop information that is weakly related to AI tasks (e.g., some texture redundancy). Different from previous task-specific solutions, Omni-ICM could directly support AI tasks analysis based on the learned omnipotent features without joint training or extra transformation. Albeit simple and intuitive, Omni-ICM significantly outperforms existing traditional and learning-based codecs on multiple fundamental vision tasks.
Deep Frequency Filtering for Domain Generalization
Mar 23, 2022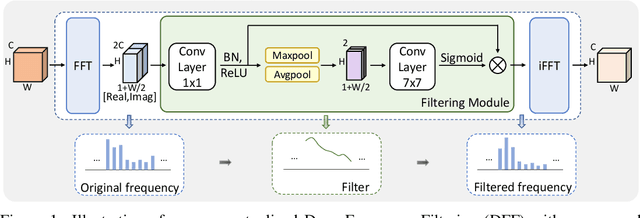
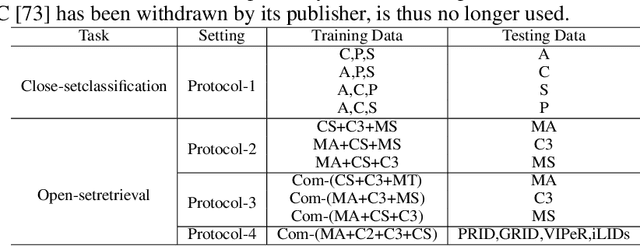
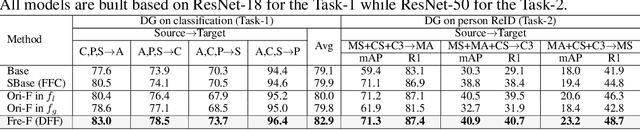

Improving the generalization capability of Deep Neural Networks (DNNs) is critical for their practical uses, which has been a longstanding challenge. Some theoretical studies have revealed that DNNs have preferences to different frequency components in the learning process and indicated that this may affect the robustness of learned features. In this paper, we propose Deep Frequency Filtering (DFF) for learning domain-generalizable features, which is the first endeavour to explicitly modulate frequency components of different transfer difficulties across domains during training. To achieve this, we perform Fast Fourier Transform (FFT) on feature maps at different layers, then adopt a light-weight module to learn the attention masks from frequency representations after FFT to enhance transferable frequency components while suppressing the components not conductive to generalization. Further, we empirically compare different types of attention for implementing our conceptualized DFF. Extensive experiments demonstrate the effectiveness of the proposed DFF and show that applying DFF on a plain baseline outperforms the state-of-the-art methods on different domain generalization tasks, including close-set classification and open-set retrieval.
ActiveMLP: An MLP-like Architecture with Active Token Mixer
Mar 11, 2022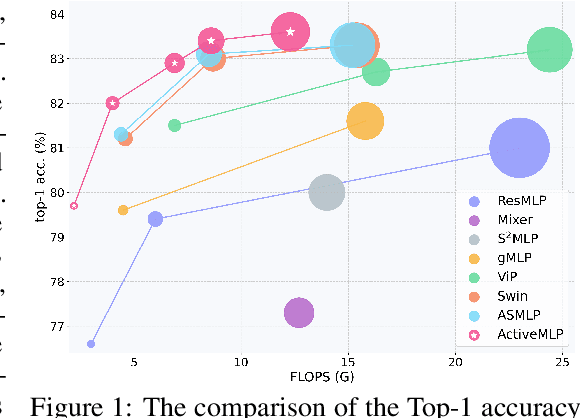

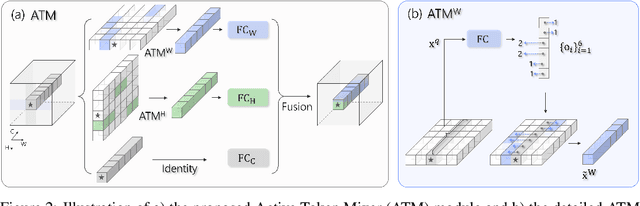
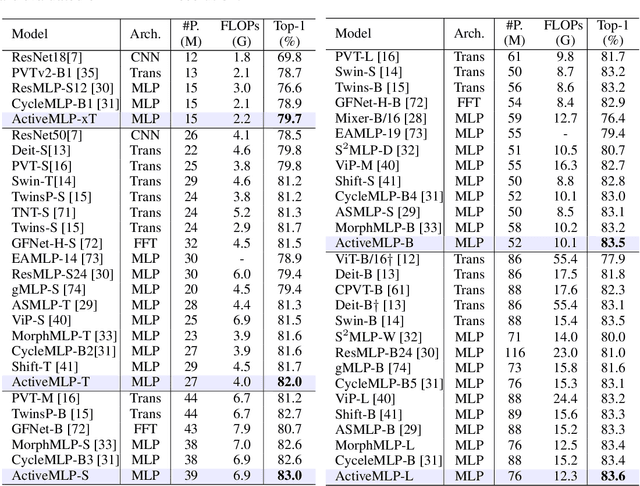
This paper presents ActiveMLP, a general MLP-like backbone for computer vision. The three existing dominant network families, i.e., CNNs, Transformers and MLPs, differ from each other mainly in the ways to fuse contextual information into a given token, leaving the design of more effective token-mixing mechanisms at the core of backbone architecture development. In ActiveMLP, we propose an innovative token-mixer, dubbed Active Token Mixer (ATM), to actively incorporate contextual information from other tokens in the global scope into the given one. This fundamental operator actively predicts where to capture useful contexts and learns how to fuse the captured contexts with the original information of the given token at channel levels. In this way, the spatial range of token-mixing is expanded and the way of token-mixing is reformed. With this design, ActiveMLP is endowed with the merits of global receptive fields and more flexible content-adaptive information fusion. Extensive experiments demonstrate that ActiveMLP is generally applicable and comprehensively surpasses different families of SOTA vision backbones by a clear margin on a broad range of vision tasks, including visual recognition and dense prediction tasks. The code and models will be available at https://github.com/microsoft/ActiveMLP.
Mask-based Latent Reconstruction for Reinforcement Learning
Jan 28, 2022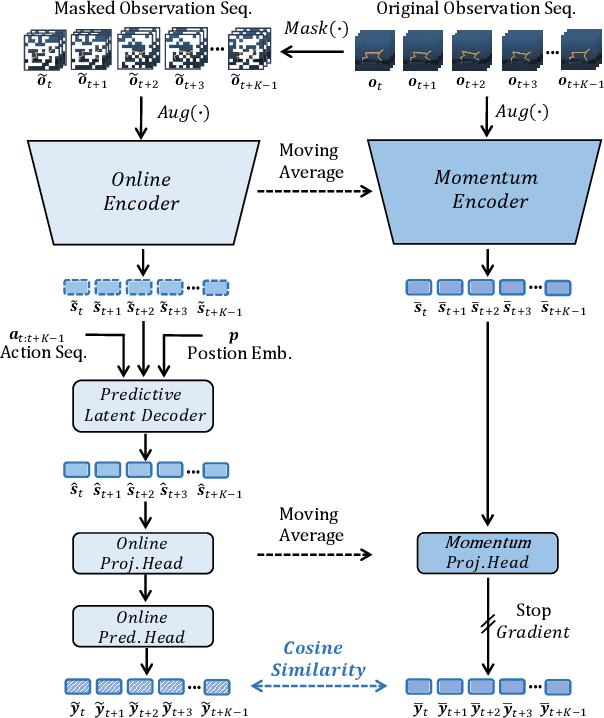
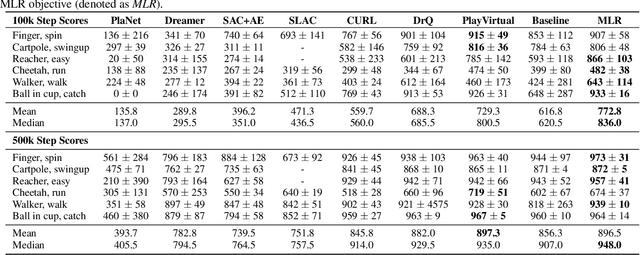
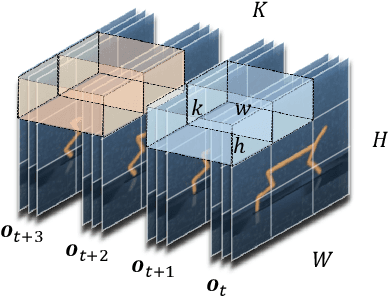
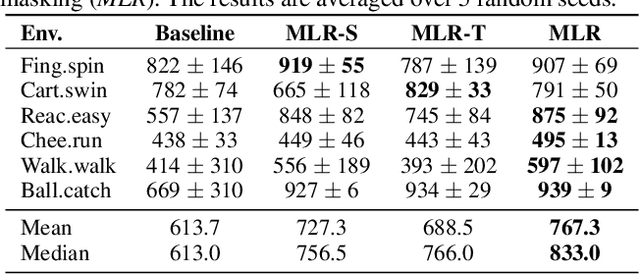
For deep reinforcement learning (RL) from pixels, learning effective state representations is crucial for achieving high performance. However, in practice, limited experience and high-dimensional input prevent effective representation learning. To address this, motivated by the success of masked modeling in other research fields, we introduce mask-based reconstruction to promote state representation learning in RL. Specifically, we propose a simple yet effective self-supervised method, Mask-based Latent Reconstruction (MLR), to predict the complete state representations in the latent space from the observations with spatially and temporally masked pixels. MLR enables the better use of context information when learning state representations to make them more informative, which facilitates RL agent training. Extensive experiments show that our MLR significantly improves the sample efficiency in RL and outperforms the state-of-the-art sample-efficient RL methods on multiple continuous benchmark environments.
Learning Cross-Scale Prediction for Efficient Neural Video Compression
Dec 26, 2021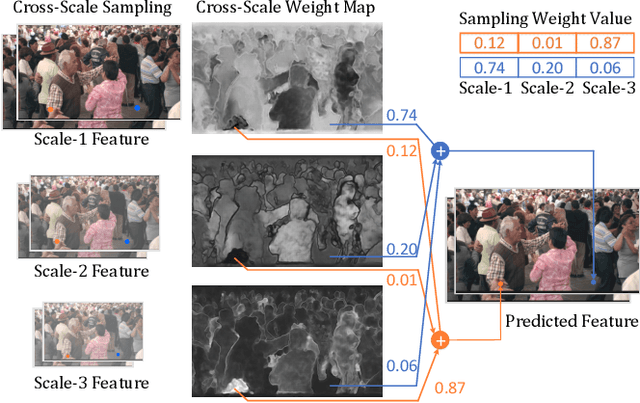
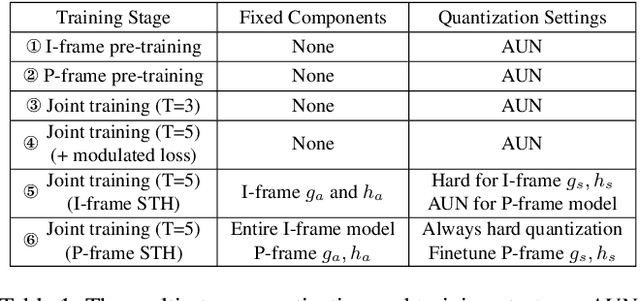
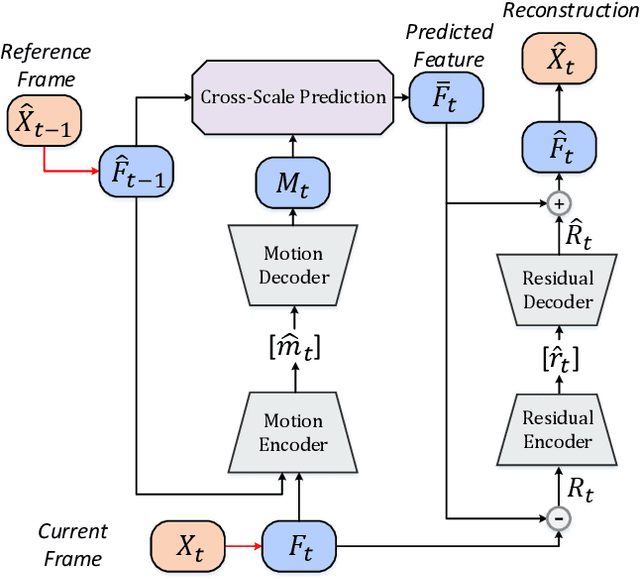
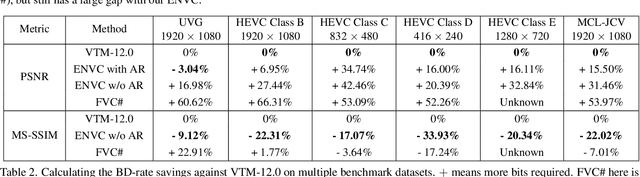
In this paper, we present the first neural video codec that can compete with the latest coding standard H.266/VVC in terms of sRGB PSNR on UVG dataset for the low-latency mode. Existing neural hybrid video coding approaches rely on optical flow or Gaussian-scale flow for prediction, which cannot support fine-grained adaptation to diverse motion content. Towards more content-adaptive prediction, we propose a novel cross-scale prediction module that achieves more effective motion compensation. Specifically, on the one hand, we produce a reference feature pyramid as prediction sources, then transmit cross-scale flows that leverage the feature scale to control the precision of prediction. On the other hand, we introduce the mechanism of weighted prediction into the scenario of prediction with a single reference frame, where cross-scale weight maps are transmitted to synthesize a fine prediction result. In addition to the cross-scale prediction module, we further propose a multi-stage quantization strategy, which improves the rate-distortion performance with no extra computational penalty during inference. We show the encouraging performance of our efficient neural video codec (ENVC) on several common benchmark datasets and analyze in detail the effectiveness of every important component.
Lifelong Unsupervised Domain Adaptive Person Re-identification with Coordinated Anti-forgetting and Adaptation
Dec 13, 2021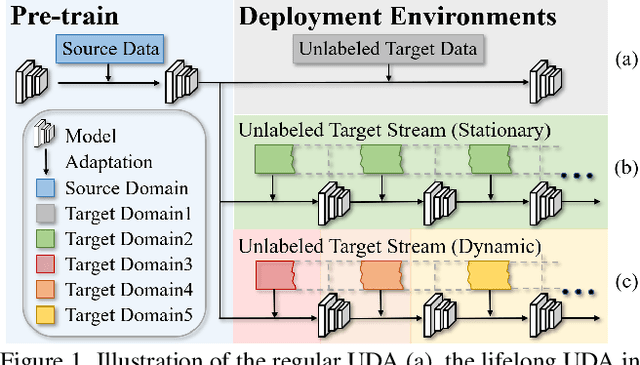

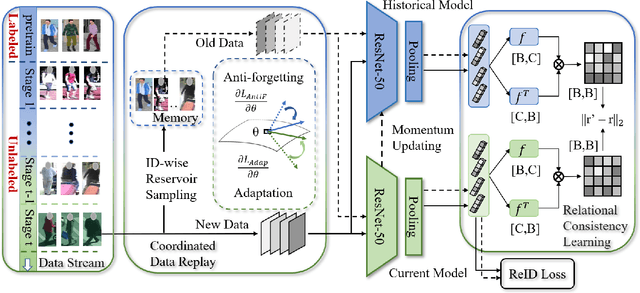
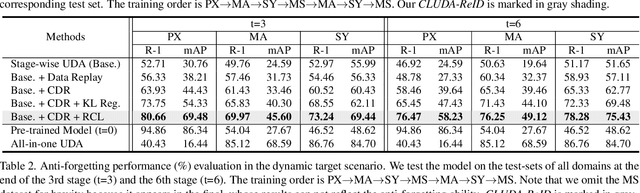
Unsupervised domain adaptive person re-identification (ReID) has been extensively investigated to mitigate the adverse effects of domain gaps. Those works assume the target domain data can be accessible all at once. However, for the real-world streaming data, this hinders the timely adaptation to changing data statistics and sufficient exploitation of increasing samples. In this paper, to address more practical scenarios, we propose a new task, Lifelong Unsupervised Domain Adaptive (LUDA) person ReID. This is challenging because it requires the model to continuously adapt to unlabeled data of the target environments while alleviating catastrophic forgetting for such a fine-grained person retrieval task. We design an effective scheme for this task, dubbed CLUDA-ReID, where the anti-forgetting is harmoniously coordinated with the adaptation. Specifically, a meta-based Coordinated Data Replay strategy is proposed to replay old data and update the network with a coordinated optimization direction for both adaptation and memorization. Moreover, we propose Relational Consistency Learning for old knowledge distillation/inheritance in line with the objective of retrieval-based tasks. We set up two evaluation settings to simulate the practical application scenarios. Extensive experiments demonstrate the effectiveness of our CLUDA-ReID for both scenarios with stationary target streams and scenarios with dynamic target streams.
SelectAugment: Hierarchical Deterministic Sample Selection for Data Augmentation
Dec 06, 2021
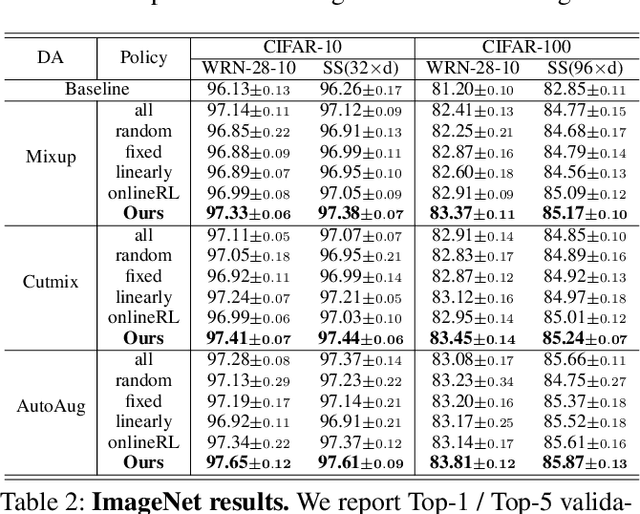
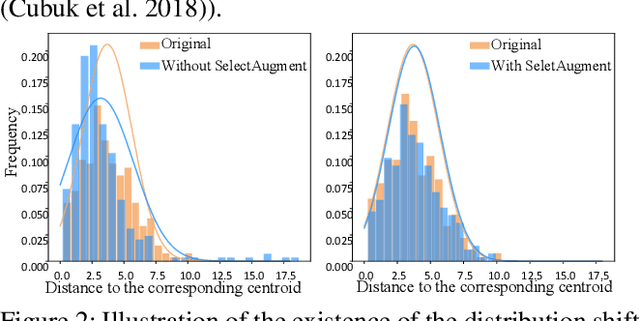
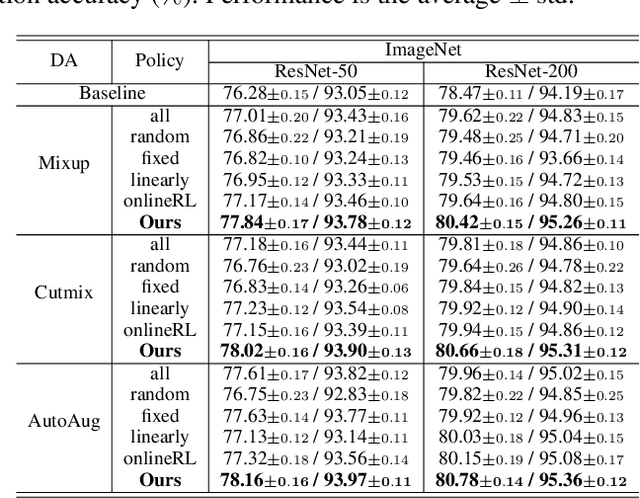
Data augmentation (DA) has been widely investigated to facilitate model optimization in many tasks. However, in most cases, data augmentation is randomly performed for each training sample with a certain probability, which might incur content destruction and visual ambiguities. To eliminate this, in this paper, we propose an effective approach, dubbed SelectAugment, to select samples to be augmented in a deterministic and online manner based on the sample contents and the network training status. Specifically, in each batch, we first determine the augmentation ratio, and then decide whether to augment each training sample under this ratio. We model this process as a two-step Markov decision process and adopt Hierarchical Reinforcement Learning (HRL) to learn the augmentation policy. In this way, the negative effects of the randomness in selecting samples to augment can be effectively alleviated and the effectiveness of DA is improved. Extensive experiments demonstrate that our proposed SelectAugment can be adapted upon numerous commonly used DA methods, e.g., Mixup, Cutmix, AutoAugment, etc, and improve their performance on multiple benchmark datasets of image classification and fine-grained image recognition.
MMPTRACK: Large-scale Densely Annotated Multi-camera Multiple People Tracking Benchmark
Nov 30, 2021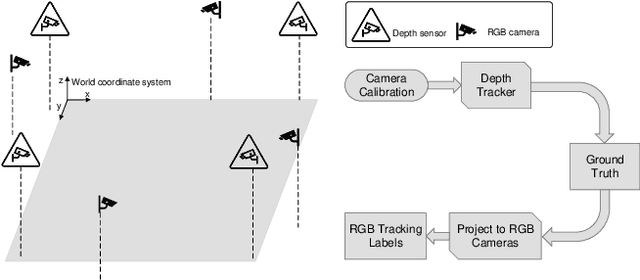
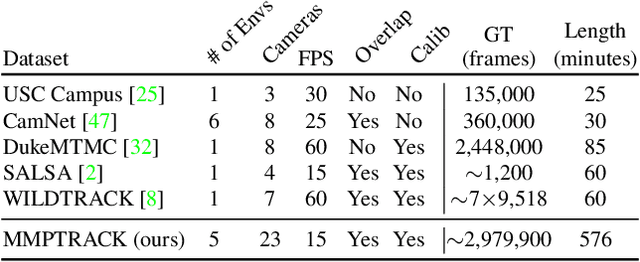

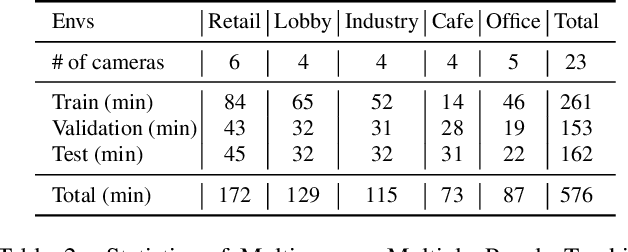
Multi-camera tracking systems are gaining popularity in applications that demand high-quality tracking results, such as frictionless checkout because monocular multi-object tracking (MOT) systems often fail in cluttered and crowded environments due to occlusion. Multiple highly overlapped cameras can significantly alleviate the problem by recovering partial 3D information. However, the cost of creating a high-quality multi-camera tracking dataset with diverse camera settings and backgrounds has limited the dataset scale in this domain. In this paper, we provide a large-scale densely-labeled multi-camera tracking dataset in five different environments with the help of an auto-annotation system. The system uses overlapped and calibrated depth and RGB cameras to build a high-performance 3D tracker that automatically generates the 3D tracking results. The 3D tracking results are projected to each RGB camera view using camera parameters to create 2D tracking results. Then, we manually check and correct the 3D tracking results to ensure the label quality, which is much cheaper than fully manual annotation. We have conducted extensive experiments using two real-time multi-camera trackers and a person re-identification (ReID) model with different settings. This dataset provides a more reliable benchmark of multi-camera, multi-object tracking systems in cluttered and crowded environments. Also, our results demonstrate that adapting the trackers and ReID models on this dataset significantly improves their performance. Our dataset will be publicly released upon the acceptance of this work.
Confounder Identification-free Causal Visual Feature Learning
Nov 26, 2021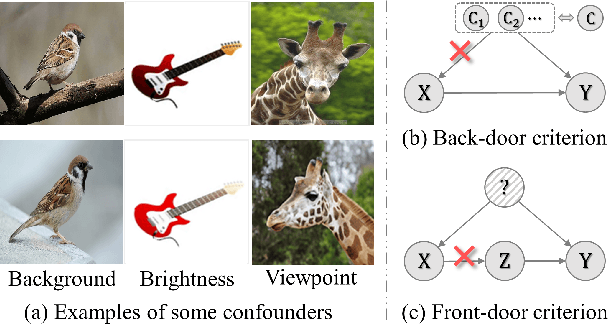
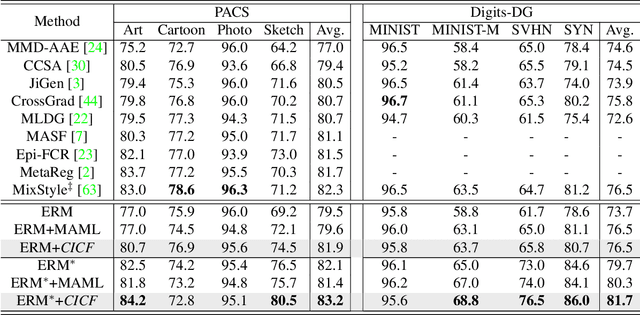
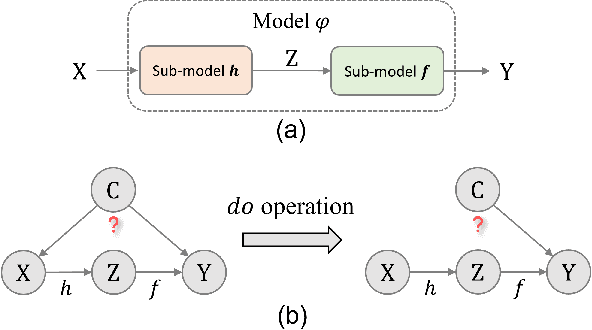
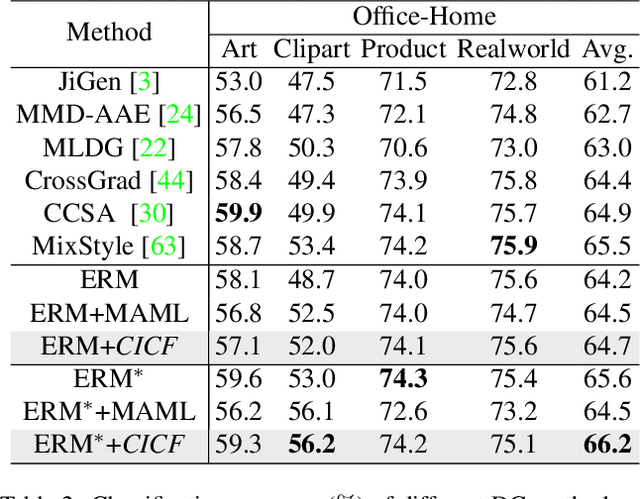
Confounders in deep learning are in general detrimental to model's generalization where they infiltrate feature representations. Therefore, learning causal features that are free of interference from confounders is important. Most previous causal learning based approaches employ back-door criterion to mitigate the adverse effect of certain specific confounder, which require the explicit identification of confounder. However, in real scenarios, confounders are typically diverse and difficult to be identified. In this paper, we propose a novel Confounder Identification-free Causal Visual Feature Learning (CICF) method, which obviates the need for identifying confounders. CICF models the interventions among different samples based on front-door criterion, and then approximates the global-scope intervening effect upon the instance-level interventions from the perspective of optimization. In this way, we aim to find a reliable optimization direction, which avoids the intervening effects of confounders, to learn causal features. Furthermore, we uncover the relation between CICF and the popular meta-learning strategy MAML, and provide an interpretation of why MAML works from the theoretical perspective of causal learning for the first time. Thanks to the effective learning of causal features, our CICF enables models to have superior generalization capability. Extensive experiments on domain generalization benchmark datasets demonstrate the effectiveness of our CICF, which achieves the state-of-the-art performance.
Versatile Learned Video Compression
Nov 05, 2021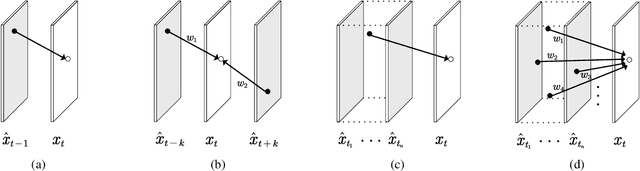

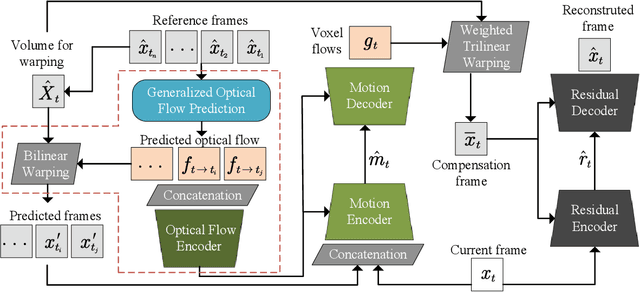

Learned video compression methods have demonstrated great promise in catching up with traditional video codecs in their rate-distortion (R-D) performance. However, existing learned video compression schemes are limited by the binding of the prediction mode and the fixed network framework. They are unable to support various inter prediction modes and thus inapplicable for various scenarios. In this paper, to break this limitation, we propose a versatile learned video compression (VLVC) framework that uses one model to support all possible prediction modes. Specifically, to realize versatile compression, we first build a motion compensation module that applies multiple 3D motion vector fields (i.e., voxel flows) for weighted trilinear warping in spatial-temporal space. The voxel flows convey the information of temporal reference position that helps to decouple inter prediction modes away from framework designing. Secondly, in case of multiple-reference-frame prediction, we apply a flow prediction module to predict accurate motion trajectories with a unified polynomial function. We show that the flow prediction module can largely reduce the transmission cost of voxel flows. Experimental results demonstrate that our proposed VLVC not only supports versatile compression in various settings but also achieves comparable R-D performance with the latest VVC standard in terms of MS-SSIM.