 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Targeted Universal Adversarial Perturbations to End-to-end ASR Models
Apr 06, 2021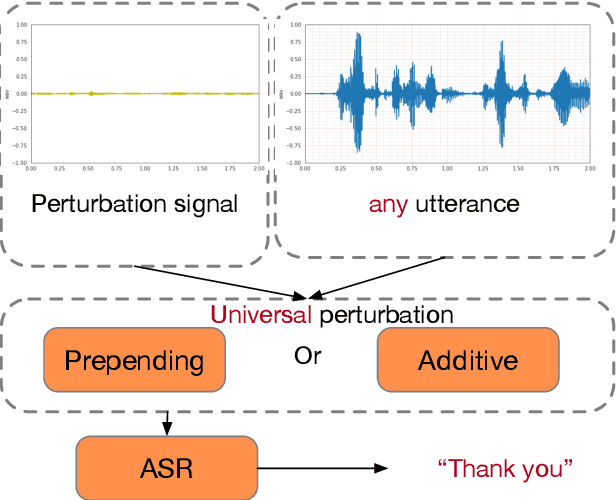
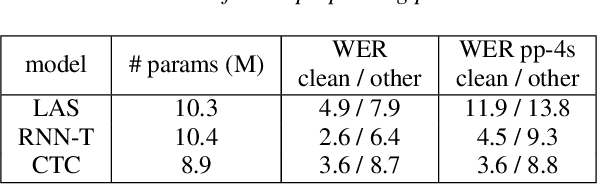
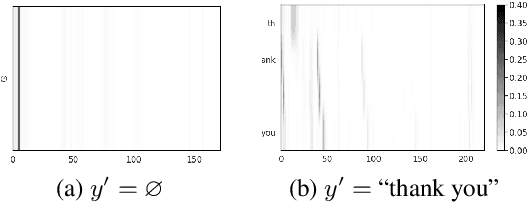
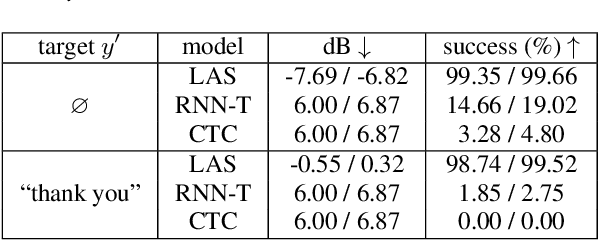
Although end-to-end automatic speech recognition (e2e ASR) models are widely deployed in many applications, there have been very few studies to understand models' robustness against adversarial perturbations. In this paper, we explore whether a targeted universal perturbation vector exists for e2e ASR models. Our goal is to find perturbations that can mislead the models to predict the given targeted transcript such as "thank you" or empty string on any input utterance. We study two different attacks, namely additive and prepending perturbations, and their performances on the state-of-the-art LAS, CTC and RNN-T models. We find that LAS is the most vulnerable to perturbations among the three models. RNN-T is more robust against additive perturbations, especially on long utterances. And CTC is robust against both additive and prepending perturbations. To attack RNN-T, we find prepending perturbation is more effective than the additive perturbation, and can mislead the models to predict the same short target on utterances of arbitrary length.
Improving Streaming Automatic Speech Recognition With Non-Streaming Model Distillation On Unsupervised Data
Oct 22, 2020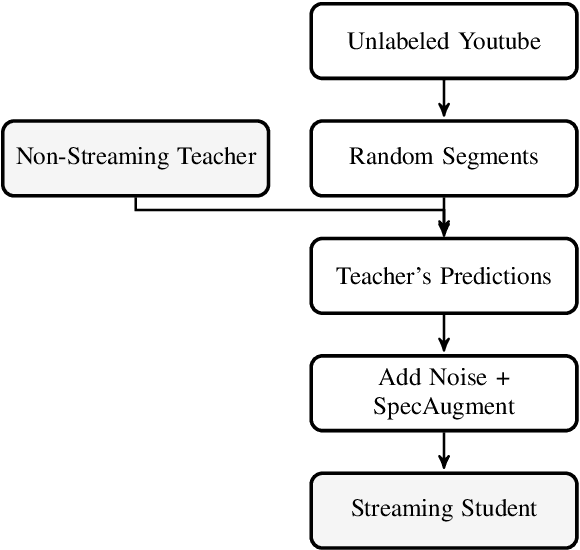
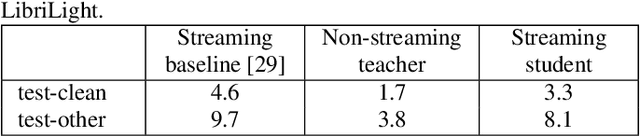
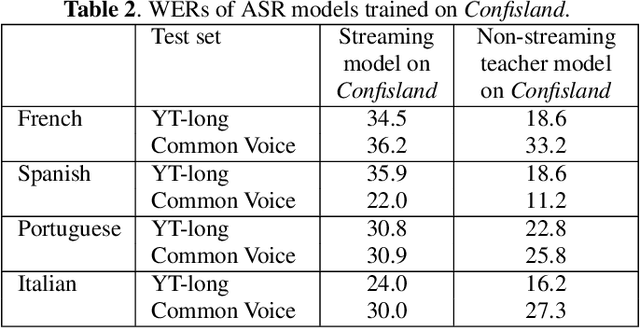
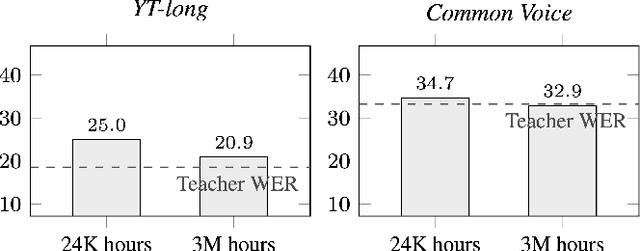
Streaming end-to-end automatic speech recognition (ASR) models are widely used on smart speakers and on-device applications. Since these models are expected to transcribe speech with minimal latency, they are constrained to be causal with no future context, compared to their non-streaming counterparts. Consequently, streaming models usually perform worse than non-streaming models. We propose a novel and effective learning method by leveraging a non-streaming ASR model as a teacher to generate transcripts on an arbitrarily large data set, which is then used to distill knowledge into streaming ASR models. This way, we scale the training of streaming models to up to 3 million hours of YouTube audio. Experiments show that our approach can significantly reduce the word error rate (WER) of RNNT models not only on LibriSpeech but also on YouTube data in four languages. For example, in French, we are able to reduce the WER by 16.4% relatively to a baseline streaming model by leveraging a non-streaming teacher model trained on the same amount of labeled data as the baseline.
Uncertainty Estimation with Infinitesimal Jackknife, Its Distribution and Mean-Field Approximation
Jun 13, 2020
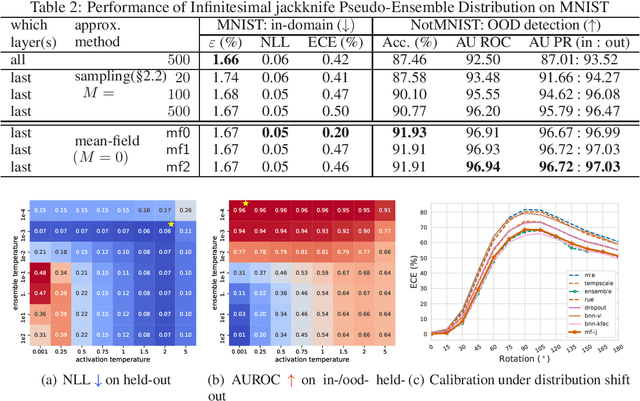
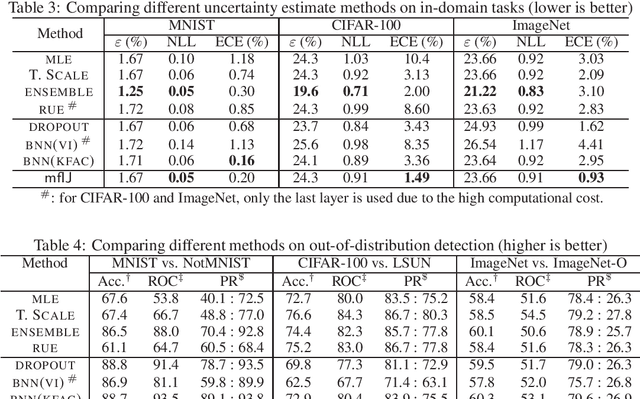

Uncertainty quantification is an important research area in machine learning. Many approaches have been developed to improve the representation of uncertainty in deep models to avoid overconfident predictions. Existing ones such as Bayesian neural networks and ensemble methods require modifications to the training procedures and are computationally costly for both training and inference. Motivated by this, we propose mean-field infinitesimal jackknife (mfIJ) -- a simple, efficient, and general-purpose plug-in estimator for uncertainty estimation. The main idea is to use infinitesimal jackknife, a classical tool from statistics for uncertainty estimation to construct a pseudo-ensemble that can be described with a closed-form Gaussian distribution, without retraining. We then use this Gaussian distribution for uncertainty estimation. While the standard way is to sample models from this distribution and combine each sample's prediction, we develop a mean-field approximation to the inference where Gaussian random variables need to be integrated with the softmax nonlinear functions to generate probabilities for multinomial variables. The approach has many appealing properties: it functions as an ensemble without requiring multiple models, and it enables closed-form approximate inference using only the first and second moments of Gaussians. Empirically, mfIJ performs competitively when compared to state-of-the-art methods, including deep ensembles, temperature scaling, dropout and Bayesian NNs, on important uncertainty tasks. It especially outperforms many methods on out-of-distribution detection.
Speech Sentiment Analysis via Pre-trained Features from End-to-end ASR Models
Nov 21, 2019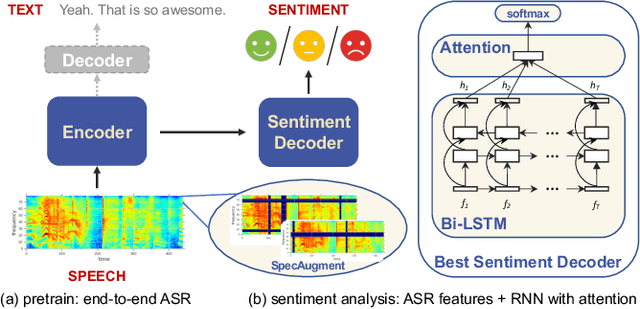

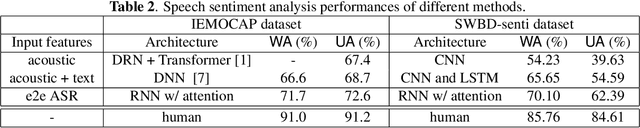

In this paper, we propose to use pre-trained features from end-to-end ASR models to solve the speech sentiment analysis problem as a down-stream task. We show that end-to-end ASR features, which integrate both acoustic and text information from speech, achieve promising results. We use RNN with self-attention as the sentiment classifier, which also provides an easy visualization through attention weights to help interpret model predictions. We use well benchmarked IEMOCAP dataset and a new large-scale sentiment analysis dataset SWBD-senti for evaluation. Our approach improves the-state-of-the-art accuracy on IEMOCAP from 66.6% to 71.7%, and achieves an accuracy of 70.10% on SWBD-senti with more than 49,500 utterances.
Hyper-parameter Tuning under a Budget Constraint
Feb 01, 2019
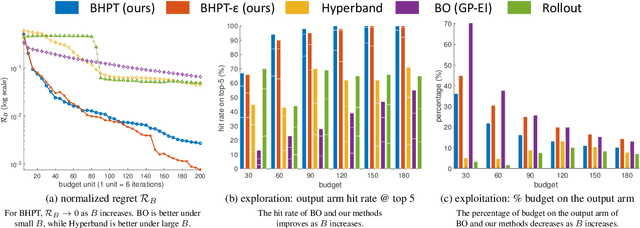
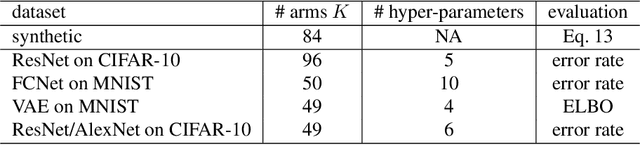
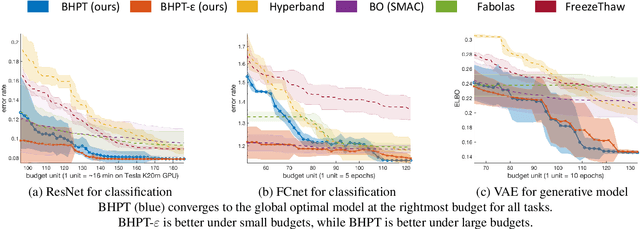
We study a budgeted hyper-parameter tuning problem, where we optimize the tuning result under a hard resource constraint. We propose to solve it as a sequential decision making problem, such that we can use the partial training progress of configurations to dynamically allocate the remaining budget. Our algorithm combines a Bayesian belief model which estimates the future performance of configurations, with an action-value function which balances exploration-exploitation tradeoff, to optimize the final output. It automatically adapts the tuning behaviors to different constraints, which is useful in practice. Experiment results demonstrate superior performance over existing algorithms, including the-state-of-the-art one, on real-world tuning tasks across a range of different budgets.
Kernel Approximation Methods for Speech Recognition
Jan 13, 2017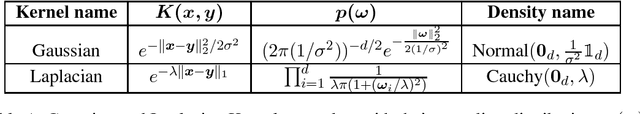
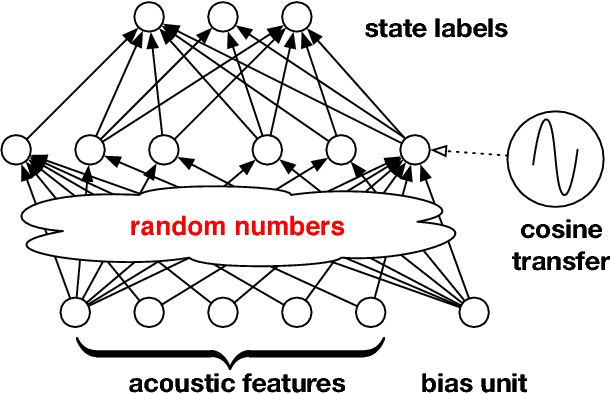
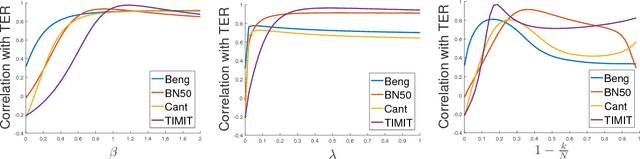

We study large-scale kernel methods for acoustic modeling in speech recognition and compare their performance to deep neural networks (DNNs). We perform experiments on four speech recognition datasets, including the TIMIT and Broadcast News benchmark tasks, and compare these two types of models on frame-level performance metrics (accuracy, cross-entropy), as well as on recognition metrics (word/character error rate). In order to scale kernel methods to these large datasets, we use the random Fourier feature method of Rahimi and Recht (2007). We propose two novel techniques for improving the performance of kernel acoustic models. First, in order to reduce the number of random features required by kernel models, we propose a simple but effective method for feature selection. The method is able to explore a large number of non-linear features while maintaining a compact model more efficiently than existing approaches. Second, we present a number of frame-level metrics which correlate very strongly with recognition performance when computed on the heldout set; we take advantage of these correlations by monitoring these metrics during training in order to decide when to stop learning. This technique can noticeably improve the recognition performance of both DNN and kernel models, while narrowing the gap between them. Additionally, we show that the linear bottleneck method of Sainath et al. (2013) improves the performance of our kernel models significantly, in addition to speeding up training and making the models more compact. Together, these three methods dramatically improve the performance of kernel acoustic models, making their performance comparable to DNNs on the tasks we explored.
Learning Compact Recurrent Neural Networks
Apr 09, 2016
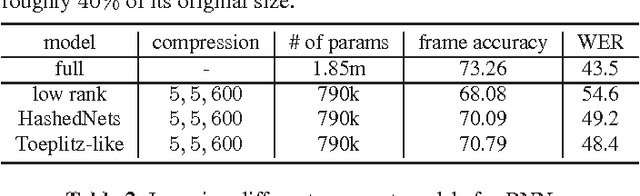
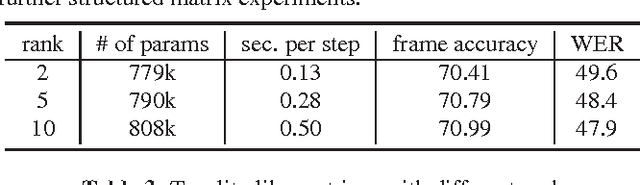
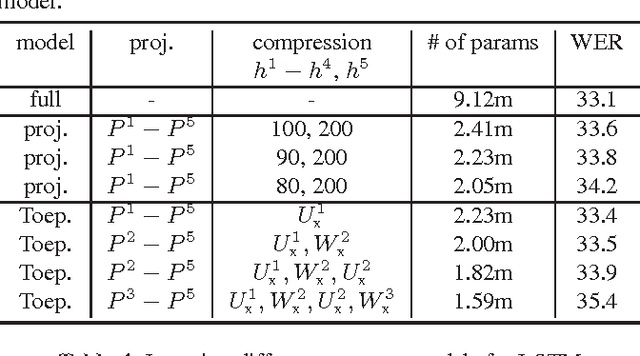
Recurrent neural networks (RNNs), including long short-term memory (LSTM) RNNs, have produced state-of-the-art results on a variety of speech recognition tasks. However, these models are often too large in size for deployment on mobile devices with memory and latency constraints. In this work, we study mechanisms for learning compact RNNs and LSTMs via low-rank factorizations and parameter sharing schemes. Our goal is to investigate redundancies in recurrent architectures where compression can be admitted without losing performance. A hybrid strategy of using structured matrices in the bottom layers and shared low-rank factors on the top layers is found to be particularly effective, reducing the parameters of a standard LSTM by 75%, at a small cost of 0.3% increase in WER, on a 2,000-hr English Voice Search task.
A Comparison between Deep Neural Nets and Kernel Acoustic Models for Speech Recognition
Mar 18, 2016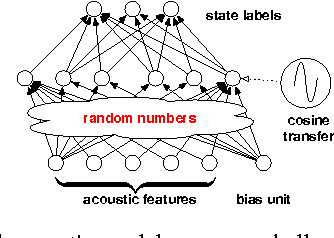


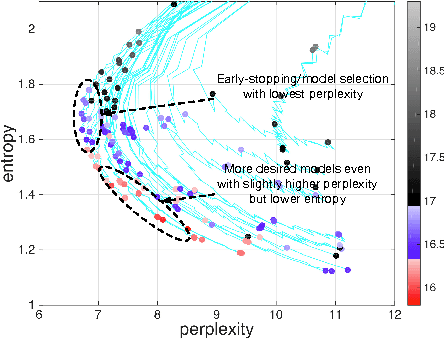
We study large-scale kernel methods for acoustic modeling and compare to DNNs on performance metrics related to both acoustic modeling and recognition. Measuring perplexity and frame-level classification accuracy, kernel-based acoustic models are as effective as their DNN counterparts. However, on token-error-rates DNN models can be significantly better. We have discovered that this might be attributed to DNN's unique strength in reducing both the perplexity and the entropy of the predicted posterior probabilities. Motivated by our findings, we propose a new technique, entropy regularized perplexity, for model selection. This technique can noticeably improve the recognition performance of both types of models, and reduces the gap between them. While effective on Broadcast News, this technique could be also applicable to other tasks.
How to Scale Up Kernel Methods to Be As Good As Deep Neural Nets
Jun 17, 2015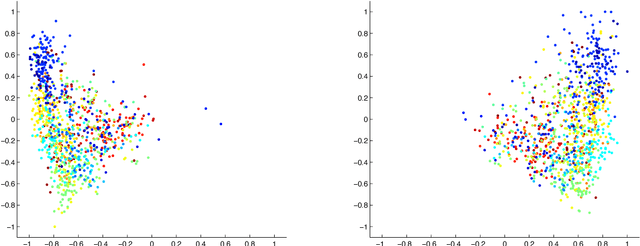
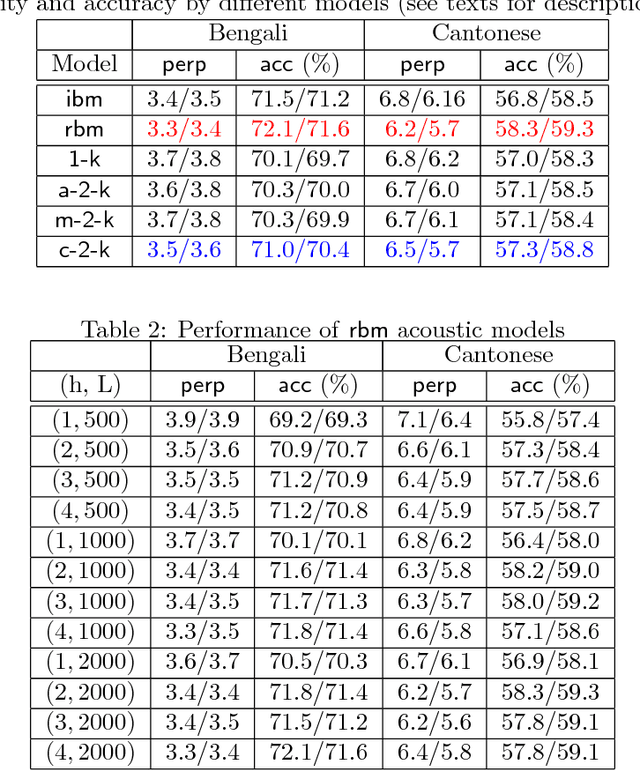
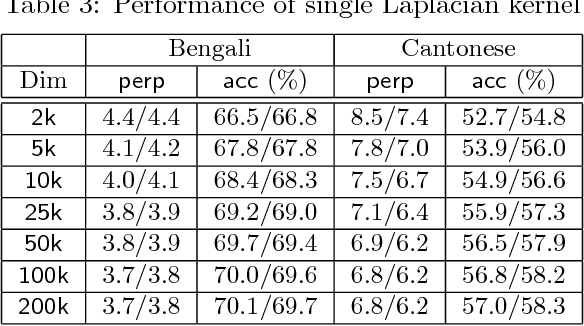
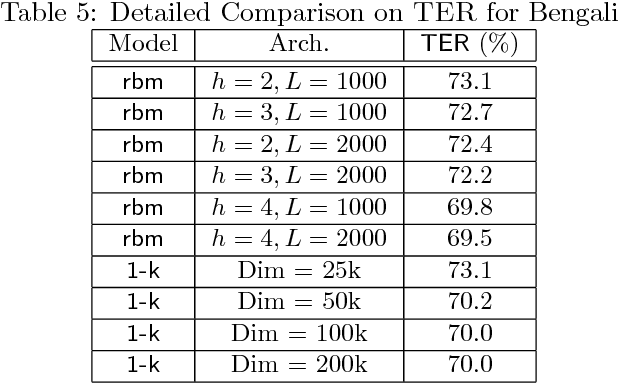
The computational complexity of kernel methods has often been a major barrier for applying them to large-scale learning problems. We argue that this barrier can be effectively overcome. In particular, we develop methods to scale up kernel models to successfully tackle large-scale learning problems that are so far only approachable by deep learning architectures. Based on the seminal work by Rahimi and Recht on approximating kernel functions with features derived from random projections, we advance the state-of-the-art by proposing methods that can efficiently train models with hundreds of millions of parameters, and learn optimal representations from multiple kernels. We conduct extensive empirical studies on problems from image recognition and automatic speech recognition, and show that the performance of our kernel models matches that of well-engineered deep neural nets (DNNs). To the best of our knowledge, this is the first time that a direct comparison between these two methods on large-scale problems is reported. Our kernel methods have several appealing properties: training with convex optimization, cost for training a single model comparable to DNNs, and significantly reduced total cost due to fewer hyperparameters to tune for model selection. Our contrastive study between these two very different but equally competitive models sheds light on fundamental questions such as how to learn good representations.