 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagining new futures beyond predictive systems in child welfare: A qualitative study with impacted stakeholders
May 18, 2022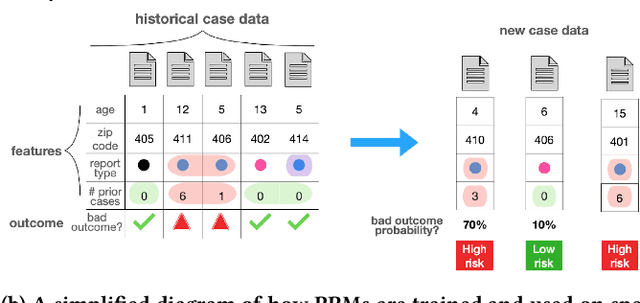

Child welfare agencies across the United States are turning to data-driven predictive technologies (commonly called predictive analytics) which use government administrative data to assist workers' decision-making. While some prior work has explored impacted stakeholders' concerns with current uses of data-driven predictive risk models (PRMs), less work has asked stakeholders whether such tools ought to be used in the first place. In this work, we conducted a set of seven design workshops with 35 stakeholders who have been impacted by the child welfare system or who work in it to understand their beliefs and concerns around PRMs, and to engage them in imagining new uses of data and technologies in the child welfare system. We found that participants worried current PRMs perpetuate or exacerbate existing problems in child welfare. Participants suggested new ways to use data and data-driven tools to better support impacted communities and suggested paths to mitigate possible harms of these tools. Participants also suggested low-tech or no-tech alternatives to PRMs to address problems in child welfare. Our study sheds light on how researchers and designers can work in solidarity with impacted communities, possibly to circumvent or oppose child welfare agencies.
Exploring How Machine Learning Practitioners (Try To) Use Fairness Toolkits
May 13, 2022
Recent years have seen the development of many open-source ML fairness toolkits aimed at helping ML practitioners assess and address unfairness in their systems. However, there has been little research investigating how ML practitioners actually use these toolkits in practice. In this paper, we conducted the first in-depth empirical exploration of how industry practitioners (try to) work with existing fairness toolkits. In particular, we conducted think-aloud interviews to understand how participants learn about and use fairness toolkits, and explored the generality of our findings through an anonymous online survey. We identified several opportunities for fairness toolkits to better address practitioner needs and scaffold them in using toolkits effectively and responsibly. Based on these findings, we highlight implications for the design of future open-source fairness toolkits that can support practitioners in better contextualizing, communicating, and collaborating around ML fairness efforts.
Improving Human-AI Partnerships in Child Welfare: Understanding Worker Practices, Challenges, and Desires for Algorithmic Decision Support
Apr 05, 2022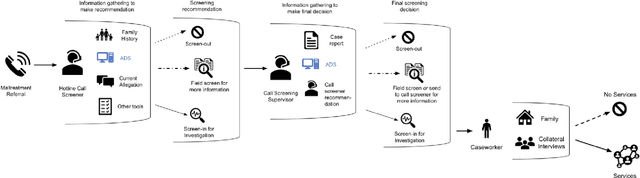
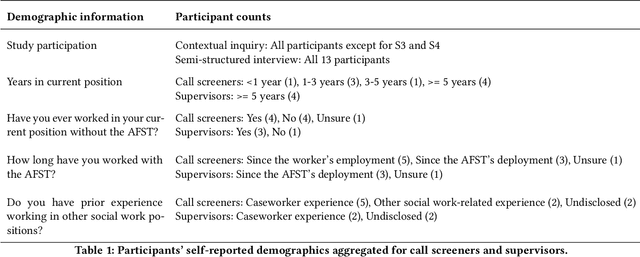
AI-based decision support tools (ADS) are increasingly used to augment human decision-making in high-stakes, social contexts. As public sector agencies begin to adopt ADS, it is critical that we understand workers' experiences with these systems in practice. In this paper, we present findings from a series of interviews and contextual inquiries at a child welfare agency, to understand how they currently make AI-assisted child maltreatment screening decisions. Overall, we observe how workers' reliance upon the ADS is guided by (1) their knowledge of rich, contextual information beyond what the AI model captures, (2) their beliefs about the ADS's capabilities and limitations relative to their own, (3) organizational pressures and incentives around the use of the ADS, and (4) awareness of misalignments between algorithmic predictions and their own decision-making objectives. Drawing upon these findings, we discuss design implications towards supporting more effective human-AI decision-making.
Provably Fair Federated Learning via Bounded Group Loss
Mar 18, 2022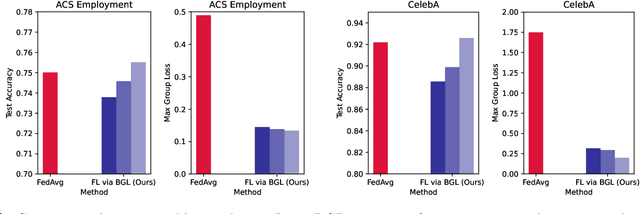

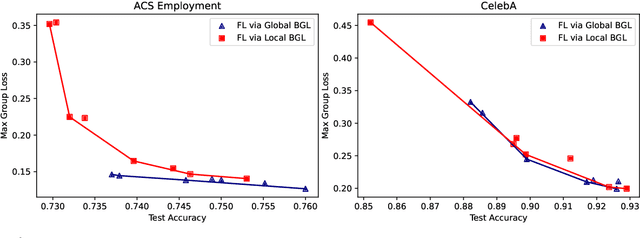
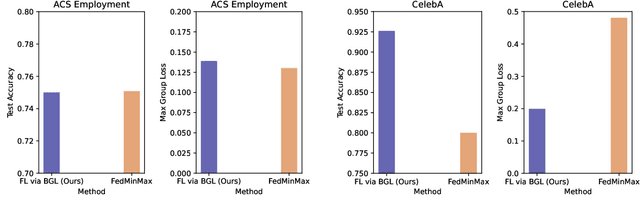
In federated learning, fair prediction across various protected groups (e.g., gender, race) is an important constraint for many applications. Unfortunately, prior work studying group fair federated learning lacks formal convergence or fairness guarantees. Our work provides a new definition for group fairness in federated learning based on the notion of Bounded Group Loss (BGL), which can be easily applied to common federated learning objectives. Based on our definition, we propose a scalable algorithm that optimizes the empirical risk and global fairness constraints, which we evaluate across common fairness and federated learning benchmarks. Our resulting method and analysis are the first we are aware of to provide formal theoretical guarantees for training a fair federated learning model.
Fully Adaptive Composition in Differential Privacy
Mar 10, 2022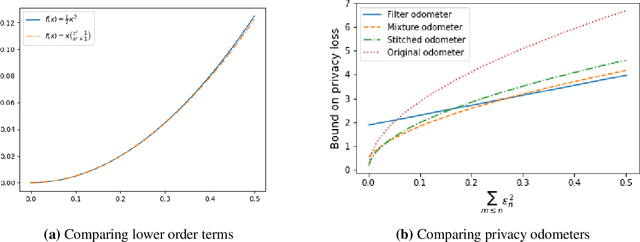
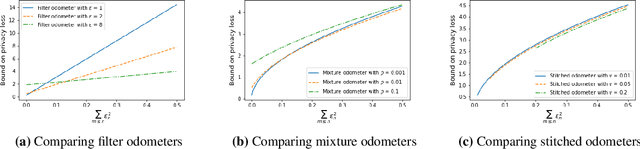
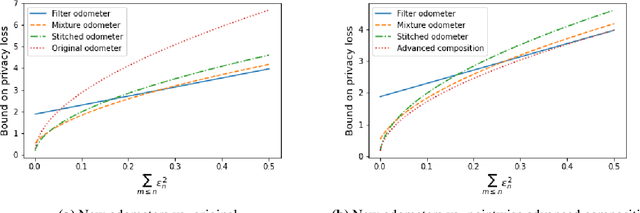
Composition is a key feature of differential privacy. Well-known advanced composition theorems allow one to query a private database quadratically more times than basic privacy composition would permit. However, these results require that the privacy parameters of all algorithms be fixed before interacting with the data. To address this, Rogers et al. introduced fully adaptive composition, wherein both algorithms and their privacy parameters can be selected adaptively. The authors introduce two probabilistic objects to measure privacy in adaptive composition: privacy filters, which provide differential privacy guarantees for composed interactions, and privacy odometers, time-uniform bounds on privacy loss. There are substantial gaps between advanced composition and existing filters and odometers. First, existing filters place stronger assumptions on the algorithms being composed. Second, these odometers and filters suffer from large constants, making them impractical. We construct filters that match the tightness of advanced composition, including constants, despite allowing for adaptively chosen privacy parameters. We also construct several general families of odometers. These odometers can match the tightness of advanced composition at an arbitrary, preselected point in time, or at all points in time simultaneously, up to a doubly-logarithmic factor. We obtain our results by leveraging recent advances in time-uniform martingale concentration. In sum, we show that fully adaptive privacy is obtainable at almost no loss, and conjecture that our results are essentially unimprovable (even in constants) in general.
Locally private nonparametric confidence intervals and sequences
Feb 17, 2022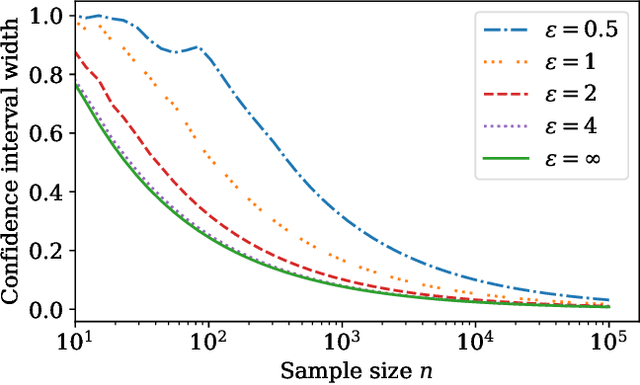
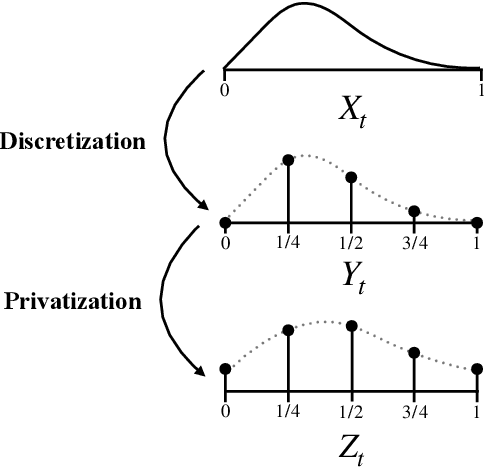
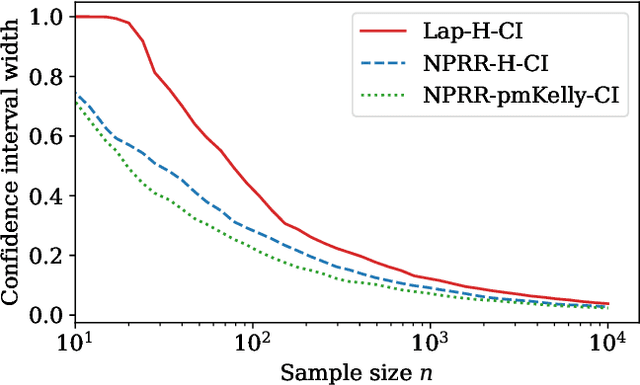
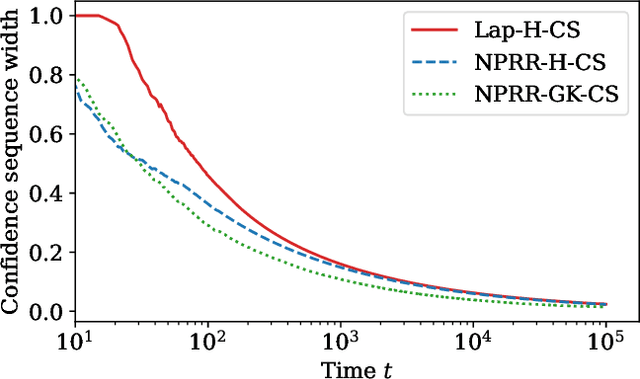
This work derives methods for performing nonparametric, nonasymptotic statistical inference for population parameters under the constraint of local differential privacy (LDP). Given observations $(X_1, \dots, X_n)$ with mean $\mu^\star$ that are privatized into $(Z_1, \dots, Z_n)$, we introduce confidence intervals (CI) and time-uniform confidence sequences (CS) for $\mu^\star \in \mathbb R$ when only given access to the privatized data. We introduce a nonparametric and sequentially interactive generalization of Warner's famous "randomized response" mechanism, satisfying LDP for arbitrary bounded random variables, and then provide CIs and CSs for their means given access to the resulting privatized observations. We extend these CSs to capture time-varying (non-stationary) means, and conclude by illustrating how these methods can be used to conduct private online A/B tests.
Personalization Improves Privacy-Accuracy Tradeoffs in Federated Optimization
Feb 10, 2022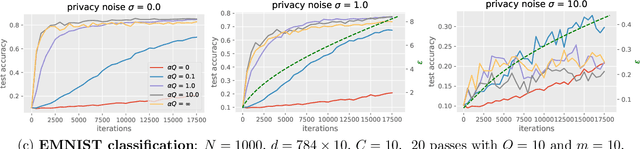
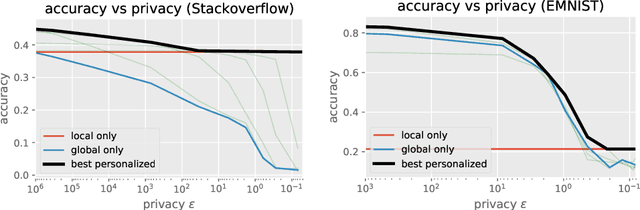
Large-scale machine learning systems often involve data distributed across a collection of users. Federated optimization algorithms leverage this structure by communicating model updates to a central server, rather than entire datasets. In this paper, we study stochastic optimization algorithms for a personalized federated learning setting involving local and global models subject to user-level (joint) differential privacy. While learning a private global model induces a cost of privacy, local learning is perfectly private. We show that coordinating local learning with private centralized learning yields a generically useful and improved tradeoff between accuracy and privacy. We illustrate our theoretical results with experiments on synthetic and real-world datasets.
Causal Imitation Learning under Temporally Correlated Noise
Feb 02, 2022


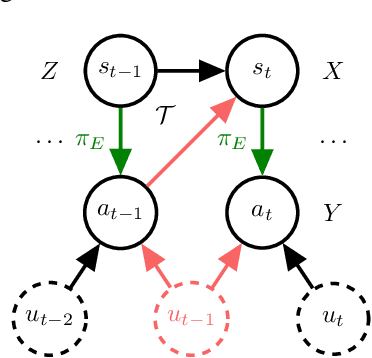
We develop algorithms for imitation learning from policy data that was corrupted by temporally correlated noise in expert actions. When noise affects multiple timesteps of recorded data, it can manifest as spurious correlations between states and actions that a learner might latch on to, leading to poor policy performance. To break up these spurious correlations, we apply modern variants of the instrumental variable regression (IVR) technique of econometrics, enabling us to recover the underlying policy without requiring access to an interactive expert. In particular, we present two techniques, one of a generative-modeling flavor (DoubIL) that can utilize access to a simulator, and one of a game-theoretic flavor (ResiduIL) that can be run entirely offline. We find both of our algorithms compare favorably to behavioral cloning on simulated control tasks.
Improved Regret for Differentially Private Exploration in Linear MDP
Feb 02, 2022We study privacy-preserving exploration in sequential decision-making for environments that rely on sensitive data such as medical records. In particular, we focus on solving the problem of reinforcement learning (RL) subject to the constraint of (joint) differential privacy in the linear MDP setting, where both dynamics and rewards are given by linear functions. Prior work on this problem due to Luyo et al. (2021) achieves a regret rate that has a dependence of $O(K^{3/5})$ on the number of episodes $K$. We provide a private algorithm with an improved regret rate with an optimal dependence of $O(\sqrt{K})$ on the number of episodes. The key recipe for our stronger regret guarantee is the adaptivity in the policy update schedule, in which an update only occurs when sufficient changes in the data are detected. As a result, our algorithm benefits from low switching cost and only performs $O(\log(K))$ updates, which greatly reduces the amount of privacy noise. Finally, in the most prevalent privacy regimes where the privacy parameter $\epsilon$ is a constant, our algorithm incurs negligible privacy cost -- in comparison with the existing non-private regret bounds, the additional regret due to privacy appears in lower-order terms.
Constrained Variational Policy Optimization for Safe Reinforcement Learning
Jan 28, 2022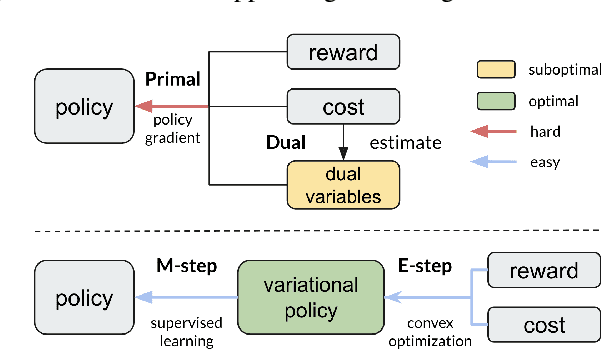
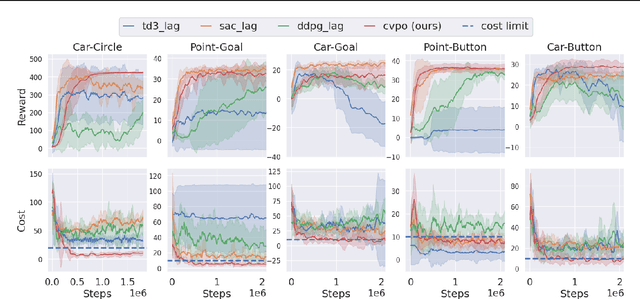
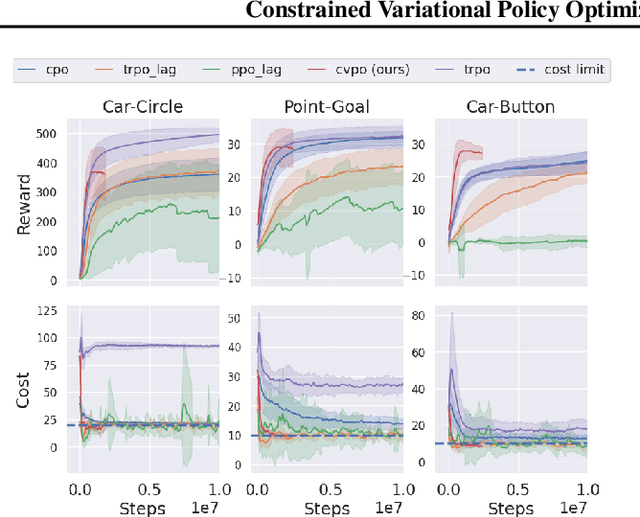
Safe reinforcement learning (RL) aims to learn policies that satisfy certain constraints before deploying to safety-critical applications. Primal-dual as a prevalent constrained optimization framework suffers from instability issues and lacks optimality guarantees. This paper overcomes the issues from a novel probabilistic inference perspective and proposes an Expectation-Maximization style approach to learn safe policy. We show that the safe RL problem can be decomposed to 1) a convex optimization phase with a non-parametric variational distribution and 2) a supervised learning phase. We show the unique advantages of constrained variational policy optimization by proving its optimality and policy improvement stability. A wide range of experiments on continuous robotic tasks show that the proposed method achieves significantly better performance in terms of constraint satisfaction and sample efficiency than primal-dual baselines.