 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaTeaming: Supporting Persona-Driven Red-Teaming for Generative AI
May 07, 2026Recent developments in AI safety research have called for red-teaming methods that effectively surface potential risks posed by generative AI models, with growing emphasis on how red-teamers' backgrounds and perspectives shape their strategies and the risks they uncover. While automated red-teaming approaches promise to complement human red-teaming through larger-scale exploration, existing automated approaches do not account for human identities and rarely incorporate human inputs. In this work, we explore persona-driven red-teaming to advance both automated red-teaming and human-AI collaboration. We first develop PersonaTeaming Workflow, which incorporates personas into the adversarial prompt generation process to explore a wider spectrum of adversarial strategies. Compared to RainbowPlus, a state-of-the-art automated red-teaming method, PersonaTeaming Workflow achieves higher attack success rates while maintaining prompt diversity. However, since automated personas only approximate real human perspectives, we further instantiate PersonaTeaming Workflow as PersonaTeaming Playground, a user-facing interface that enables red-teamers to author their own personas and collaborate with AI to mutate and refine prompts. In a user study with 11 industry practitioners, we found that PersonaTeaming Playground enabled diverse red-teaming strategies and outputs that practitioners perceived as useful, and that AI-generated suggestions in the PersonaTeaming Playground encouraged out-of-the-box thinking even when practitioners did not follow them strictly. Together, our work advances both automated and human-in-the-loop approaches to red-teaming, while shedding light on interaction patterns and design insights for supporting human-AI collaboration in generative AI red-teaming.
MM-SCALE: Grounded Multimodal Moral Reasoning via Scalar Judgment and Listwise Alignment
Feb 03, 2026Vision-Language Models (VLMs) continue to struggle to make morally salient judgments in multimodal and socially ambiguous contexts. Prior works typically rely on binary or pairwise supervision, which often fail to capture the continuous and pluralistic nature of human moral reasoning. We present MM-SCALE (Multimodal Moral Scale), a large-scale dataset for aligning VLMs with human moral preferences through 5-point scalar ratings and explicit modality grounding. Each image-scenario pair is annotated with moral acceptability scores and grounded reasoning labels by humans using an interface we tailored for data collection, enabling listwise preference optimization over ranked scenario sets. By moving from discrete to scalar supervision, our framework provides richer alignment signals and finer calibration of multimodal moral reasoning. Experiments show that VLMs fine-tuned on MM-SCALE achieve higher ranking fidelity and more stable safety calibration than those trained with binary signals.
Critical or Compliant? The Double-Edged Sword of Reasoning in Chain-of-Thought Explanations
Nov 19, 2025Explanations are often promoted as tools for transparency, but they can also foster confirmation bias; users may assume reasoning is correct whenever outputs appear acceptable. We study this double-edged role of Chain-of-Thought (CoT) explanations in multimodal moral scenarios by systematically perturbing reasoning chains and manipulating delivery tones. Specifically, we analyze reasoning errors in vision language models (VLMs) and how they impact user trust and the ability to detect errors. Our findings reveal two key effects: (1) users often equate trust with outcome agreement, sustaining reliance even when reasoning is flawed, and (2) the confident tone suppresses error detection while maintaining reliance, showing that delivery styles can override correctness. These results highlight how CoT explanations can simultaneously clarify and mislead, underscoring the need for NLP systems to provide explanations that encourage scrutiny and critical thinking rather than blind trust. All code will be released publicly.
PersonaTeaming: Exploring How Introducing Personas Can Improve Automated AI Red-Teaming
Sep 03, 2025Recent developments in AI governance and safety research have called for red-teaming methods that can effectively surface potential risks posed by AI models. Many of these calls have emphasized how the identities and backgrounds of red-teamers can shape their red-teaming strategies, and thus the kinds of risks they are likely to uncover. While automated red-teaming approaches promise to complement human red-teaming by enabling larger-scale exploration of model behavior, current approaches do not consider the role of identity. As an initial step towards incorporating people's background and identities in automated red-teaming, we develop and evaluate a novel method, PersonaTeaming, that introduces personas in the adversarial prompt generation process to explore a wider spectrum of adversarial strategies. In particular, we first introduce a methodology for mutating prompts based on either "red-teaming expert" personas or "regular AI user" personas. We then develop a dynamic persona-generating algorithm that automatically generates various persona types adaptive to different seed prompts. In addition, we develop a set of new metrics to explicitly measure the "mutation distance" to complement existing diversity measurements of adversarial prompts. Our experiments show promising improvements (up to 144.1%) in the attack success rates of adversarial prompts through persona mutation, while maintaining prompt diversity, compared to RainbowPlus, a state-of-the-art automated red-teaming method. We discuss the strengths and limitations of different persona types and mutation methods, shedding light on future opportunities to explore complementarities between automated and human red-teaming approaches.
Cognitive Chain-of-Thought: Structured Multimodal Reasoning about Social Situations
Jul 27, 2025



Chain-of-Thought (CoT) prompting helps models think step by step. But what happens when they must see, understand, and judge-all at once? In visual tasks grounded in social context, where bridging perception with norm-grounded judgments is essential, flat CoT often breaks down. We introduce Cognitive Chain-of-Thought (CoCoT), a prompting strategy that scaffolds VLM reasoning through three cognitively inspired stages: perception, situation, and norm. Our experiments show that, across multiple multimodal benchmarks (including intent disambiguation, commonsense reasoning, and safety), CoCoT consistently outperforms CoT and direct prompting (+8\% on average). Our findings demonstrate that cognitively grounded reasoning stages enhance interpretability and social awareness in VLMs, paving the way for safer and more reliable multimodal systems.
Investigating Practices and Opportunities for Cross-functional Collaboration around AI Fairness in Industry Practice
Jun 10, 2023
An emerging body of research indicates that ineffective cross-functional collaboration -- the interdisciplinary work done by industry practitioners across roles -- represents a major barrier to addressing issues of fairness in AI design and development. In this research, we sought to better understand practitioners' current practices and tactics to enact cross-functional collaboration for AI fairness, in order to identify opportunities to support more effective collaboration. We conducted a series of interviews and design workshops with 23 industry practitioners spanning various roles from 17 companies. We found that practitioners engaged in bridging work to overcome frictions in understanding, contextualization, and evaluation around AI fairness across roles. In addition, in organizational contexts with a lack of resources and incentives for fairness work, practitioners often piggybacked on existing requirements (e.g., for privacy assessments) and AI development norms (e.g., the use of quantitative evaluation metrics), although they worry that these tactics may be fundamentally compromised. Finally, we draw attention to the invisible labor that practitioners take on as part of this bridging and piggybacking work to enact interdisciplinary collaboration for fairness. We close by discussing opportunities for both FAccT researchers and AI practitioners to better support cross-functional collaboration for fairness in the design and development of AI systems.
Understanding Practices, Challenges, and Opportunities for User-Driven Algorithm Auditing in Industry Practice
Oct 10, 2022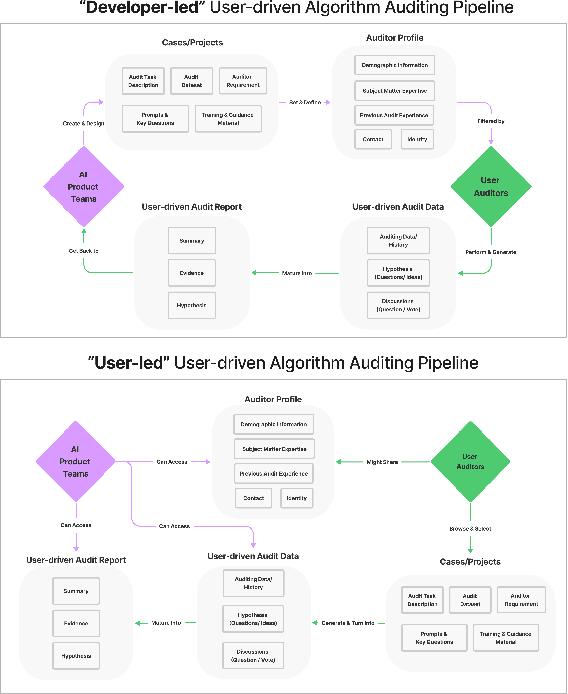
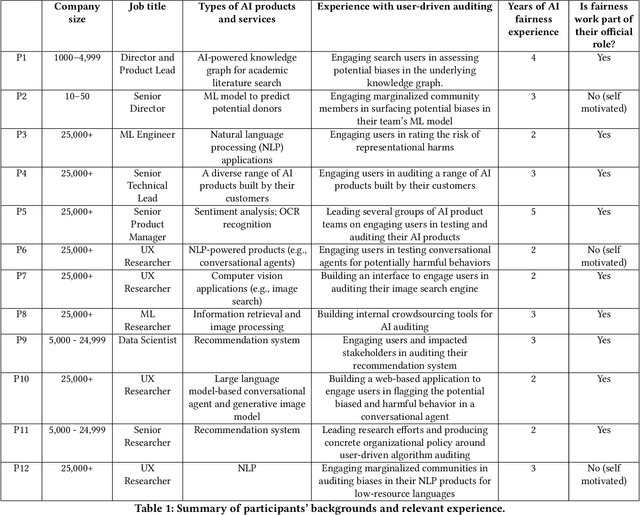
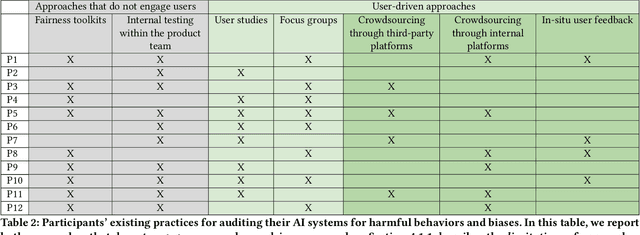

Recent years have seen growing interest among both researchers and practitioners in user-driven approaches to algorithm auditing, which directly engage users in detecting problematic behaviors in algorithmic systems. However, we know little about industry practitioners' current practices and challenges around user-driven auditing, nor what opportunities exist for them to better leverage such approaches in practice. To investigate, we conducted a series of interviews and iterative co-design activities with practitioners who employ user-driven auditing approaches in their work. Our findings reveal several challenges practitioners face in appropriately recruiting and incentivizing user auditors, scaffolding user audits, and deriving actionable insights from user-driven audit reports. Furthermore, practitioners shared organizational obstacles to user-driven auditing, surfacing a complex relationship between practitioners and user auditors. Based on these findings, we discuss opportunities for future HCI research to help realize the potential (and mitigate risks) of user-driven auditing in industry practice.
Exploring How Machine Learning Practitioners (Try To) Use Fairness Toolkits
May 13, 2022
Recent years have seen the development of many open-source ML fairness toolkits aimed at helping ML practitioners assess and address unfairness in their systems. However, there has been little research investigating how ML practitioners actually use these toolkits in practice. In this paper, we conducted the first in-depth empirical exploration of how industry practitioners (try to) work with existing fairness toolkits. In particular, we conducted think-aloud interviews to understand how participants learn about and use fairness toolkits, and explored the generality of our findings through an anonymous online survey. We identified several opportunities for fairness toolkits to better address practitioner needs and scaffold them in using toolkits effectively and responsibly. Based on these findings, we highlight implications for the design of future open-source fairness toolkits that can support practitioners in better contextualizing, communicating, and collaborating around ML fairness efforts.
Beyond General Purpose Machine Translation: The Need for Context-specific Empirical Research to Design for Appropriate User Trust
May 13, 2022Machine Translation (MT) has the potential to help people overcome language barriers and is widely used in high-stakes scenarios, such as in hospitals. However, in order to use MT reliably and safely, users need to understand when to trust MT outputs and how to assess the quality of often imperfect translation results. In this paper, we discuss research directions to support users to calibrate trust in MT systems. We share findings from an empirical study in which we conducted semi-structured interviews with 20 clinicians to understand how they communicate with patients across language barriers, and if and how they use MT systems. Based on our findings, we advocate for empirical research on how MT systems are used in practice as an important first step to addressing the challenges in building appropriate trust between users and MT tools.