 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-Ranked Reconstruction of Census Microdata from Published Statistics
Nov 06, 2022A reconstruction attack on a private dataset $D$ takes as input some publicly accessible information about the dataset and produces a list of candidate elements of $D$. We introduce a new class of data reconstruction attacks based on randomized methods for non-convex optimization. We empirically demonstrate that our attacks can not only reconstruct full rows of $D$ from aggregate query statistics $Q(D)\in \mathbb{R}^m$, but can do so in a way that reliably ranks reconstructed rows by their odds of appearing in the private data, providing a signature that could be used for prioritizing reconstructed rows for further actions such as identify theft or hate crime. We also design a sequence of baselines for evaluating reconstruction attacks. Our attacks significantly outperform those that are based only on access to a public distribution or population from which the private dataset $D$ was sampled, demonstrating that they are exploiting information in the aggregate statistics $Q(D)$, and not simply the overall structure of the distribution. In other words, the queries $Q(D)$ are permitting reconstruction of elements of this dataset, not the distribution from which $D$ was drawn. These findings are established both on 2010 U.S. decennial Census data and queries and Census-derived American Community Survey datasets. Taken together, our methods and experiments illustrate the risks in releasing numerically precise aggregate statistics of a large dataset, and provide further motivation for the careful application of provably private techniques such as differential privacy.
Private Synthetic Data for Multitask Learning and Marginal Queries
Sep 15, 2022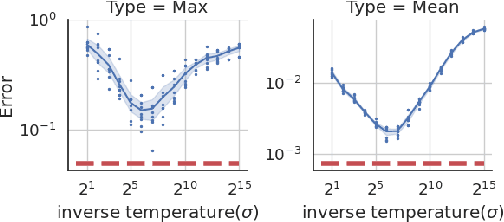


We provide a differentially private algorithm for producing synthetic data simultaneously useful for multiple tasks: marginal queries and multitask machine learning (ML). A key innovation in our algorithm is the ability to directly handle numerical features, in contrast to a number of related prior approaches which require numerical features to be first converted into {high cardinality} categorical features via {a binning strategy}. Higher binning granularity is required for better accuracy, but this negatively impacts scalability. Eliminating the need for binning allows us to produce synthetic data preserving large numbers of statistical queries such as marginals on numerical features, and class conditional linear threshold queries. Preserving the latter means that the fraction of points of each class label above a particular half-space is roughly the same in both the real and synthetic data. This is the property that is needed to train a linear classifier in a multitask setting. Our algorithm also allows us to produce high quality synthetic data for mixed marginal queries, that combine both categorical and numerical features. Our method consistently runs 2-5x faster than the best comparable techniques, and provides significant accuracy improvements in both marginal queries and linear prediction tasks for mixed-type datasets.
Game-Theoretic Algorithms for Conditional Moment Matching
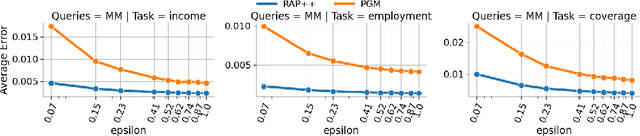
Aug 19, 2022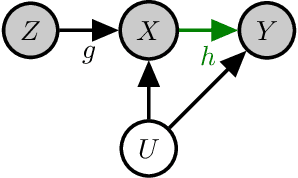
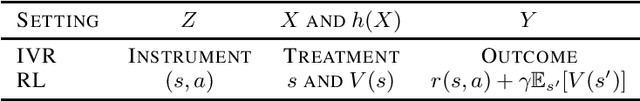
A variety of problems in econometrics and machine learning, including instrumental variable regression and Bellman residual minimization, can be formulated as satisfying a set of conditional moment restrictions (CMR). We derive a general, game-theoretic strategy for satisfying CMR that scales to nonlinear problems, is amenable to gradient-based optimization, and is able to account for finite sample uncertainty. We recover the approaches of Dikkala et al. and Dai et al. as special cases of our general framework before detailing various extensions and how to efficiently solve the game defined by CMR.
Sequence Model Imitation Learning with Unobserved Contexts
Aug 03, 2022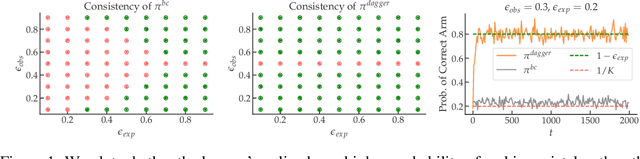
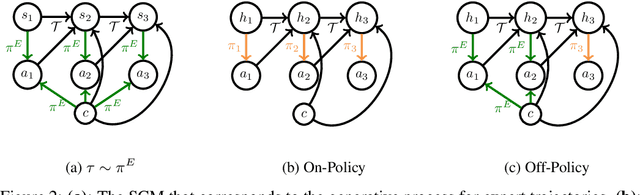
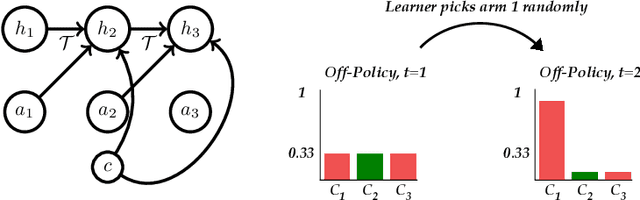

We consider imitation learning problems where the expert has access to a per-episode context that is hidden from the learner, both in the demonstrations and at test-time. While the learner might not be able to accurately reproduce expert behavior early on in an episode, by considering the entire history of states and actions, they might be able to eventually identify the context and act as the expert would. We prove that on-policy imitation learning algorithms (with or without access to a queryable expert) are better equipped to handle these sorts of asymptotically realizable problems than off-policy methods and are able to avoid the latching behavior (naive repetition of past actions) that plagues the latter. We conduct experiments in a toy bandit domain that show that there exist sharp phase transitions of whether off-policy approaches are able to match expert performance asymptotically, in contrast to the uniformly good performance of on-policy approaches. We demonstrate that on several continuous control tasks, on-policy approaches are able to use history to identify the context while off-policy approaches actually perform worse when given access to history.
On Privacy and Personalization in Cross-Silo Federated Learning
Jun 16, 2022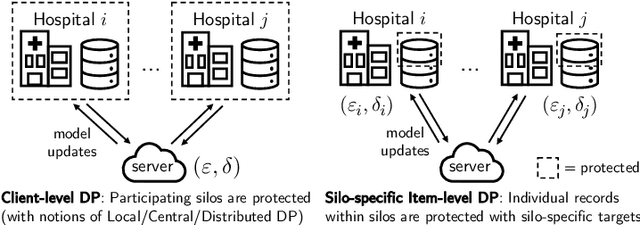
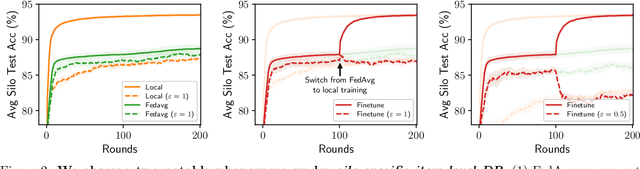
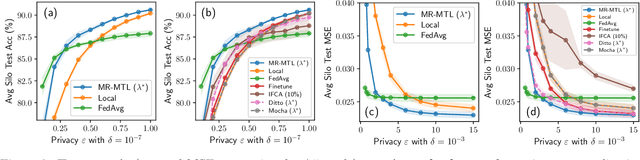
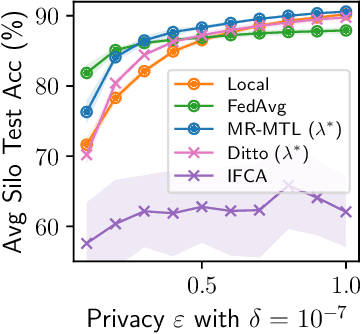
While the application of differential privacy (DP) has been well-studied in cross-device federated learning (FL), there is a lack of work considering DP for cross-silo FL, a setting characterized by a limited number of clients each containing many data subjects. In cross-silo FL, usual notions of client-level privacy are less suitable as real-world privacy regulations typically concern in-silo data subjects rather than the silos themselves. In this work, we instead consider the more realistic notion of silo-specific item-level privacy, where silos set their own privacy targets for their local examples. Under this setting, we reconsider the roles of personalization in federated learning. In particular, we show that mean-regularized multi-task learning (MR-MTL), a simple personalization framework, is a strong baseline for cross-silo FL: under stronger privacy, silos are further incentivized to "federate" with each other to mitigate DP noise, resulting in consistent improvements relative to standard baseline methods. We provide a thorough empirical study of competing methods as well as a theoretical characterization of MR-MTL for a mean estimation problem, highlighting the interplay between privacy and cross-silo data heterogeneity. Our work serves to establish baselines for private cross-silo FL as well as identify key directions of future work in this area.
Brownian Noise Reduction: Maximizing Privacy Subject to Accuracy Constraints
Jun 15, 2022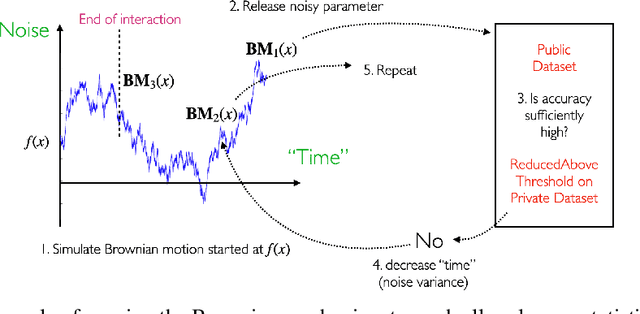
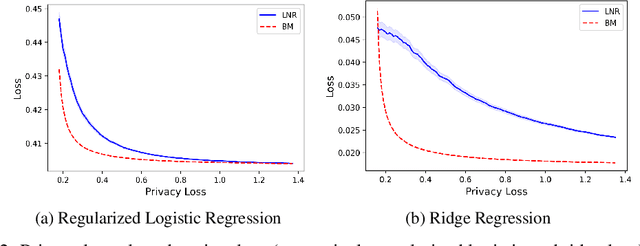
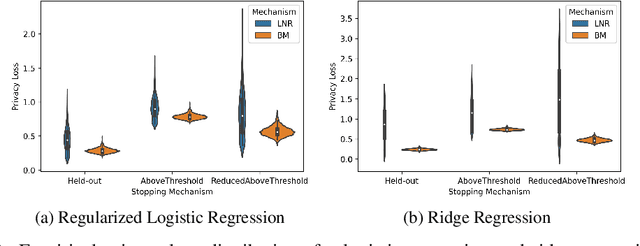
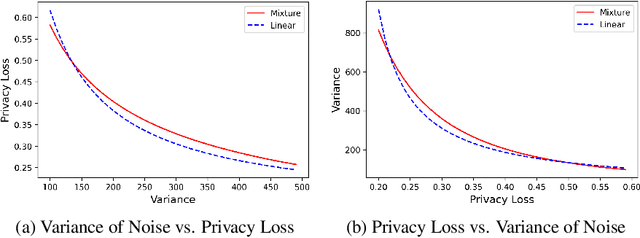
There is a disconnect between how researchers and practitioners handle privacy-utility tradeoffs. Researchers primarily operate from a privacy first perspective, setting strict privacy requirements and minimizing risk subject to these constraints. Practitioners often desire an accuracy first perspective, possibly satisfied with the greatest privacy they can get subject to obtaining sufficiently small error. Ligett et al. have introduced a "noise reduction" algorithm to address the latter perspective. The authors show that by adding correlated Laplace noise and progressively reducing it on demand, it is possible to produce a sequence of increasingly accurate estimates of a private parameter while only paying a privacy cost for the least noisy iterate released. In this work, we generalize noise reduction to the setting of Gaussian noise, introducing the Brownian mechanism. The Brownian mechanism works by first adding Gaussian noise of high variance corresponding to the final point of a simulated Brownian motion. Then, at the practitioner's discretion, noise is gradually decreased by tracing back along the Brownian path to an earlier time. Our mechanism is more naturally applicable to the common setting of bounded $\ell_2$-sensitivity, empirically outperforms existing work on common statistical tasks, and provides customizable control of privacy loss over the entire interaction with the practitioner. We complement our Brownian mechanism with ReducedAboveThreshold, a generalization of the classical AboveThreshold algorithm that provides adaptive privacy guarantees. Overall, our results demonstrate that one can meet utility constraints while still maintaining strong levels of privacy.
Private Synthetic Data with Hierarchical Structure
Jun 13, 2022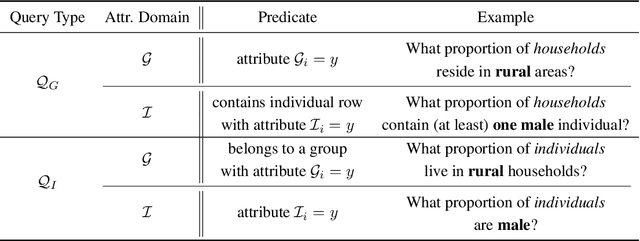
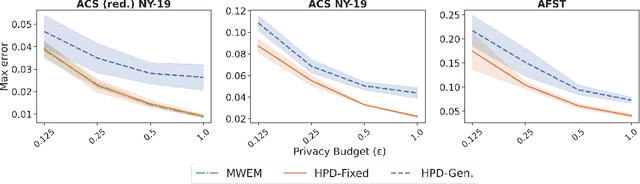

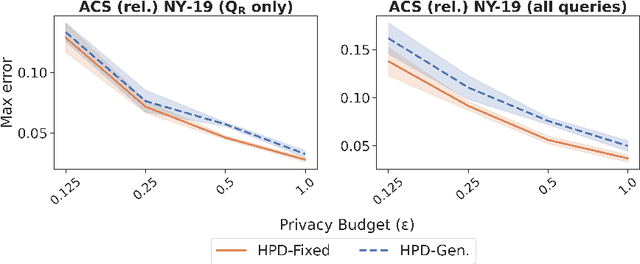
We study the problem of differentially private synthetic data generation for hierarchical datasets in which individual data points are grouped together (e.g., people within households). In particular, to measure the similarity between the synthetic dataset and the underlying private one, we frame our objective under the problem of private query release, generating a synthetic dataset that preserves answers for some collection of queries (i.e., statistics like mean aggregate counts). However, while the application of private synthetic data to the problem of query release has been well studied, such research is restricted to non-hierarchical data domains, raising the initial question -- what queries are important when considering data of this form? Moreover, it has not yet been established how one can generate synthetic data at both the group and individual-level while capturing such statistics. In light of these challenges, we first formalize the problem of hierarchical query release, in which the goal is to release a collection of statistics for some hierarchical dataset. Specifically, we provide a general set of statistical queries that captures relationships between attributes at both the group and individual-level. Subsequently, we introduce private synthetic data algorithms for hierarchical query release and evaluate them on hierarchical datasets derived from the American Community Survey and Allegheny Family Screening Tool data. Finally, we look to the American Community Survey, whose inherent hierarchical structure gives rise to another set of domain-specific queries that we run experiments with.
Minimax Optimal Online Imitation Learning via Replay Estimation
Jun 02, 2022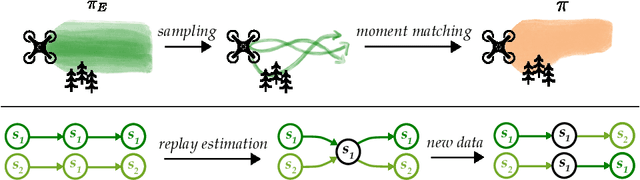
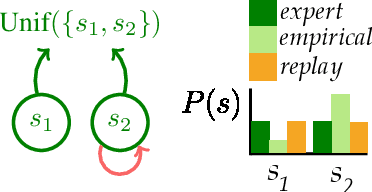

Online imitation learning is the problem of how best to mimic expert demonstrations, given access to the environment or an accurate simulator. Prior work has shown that in the infinite sample regime, exact moment matching achieves value equivalence to the expert policy. However, in the finite sample regime, even if one has no optimization error, empirical variance can lead to a performance gap that scales with $H^2 / N$ for behavioral cloning and $H / \sqrt{N}$ for online moment matching, where $H$ is the horizon and $N$ is the size of the expert dataset. We introduce the technique of replay estimation to reduce this empirical variance: by repeatedly executing cached expert actions in a stochastic simulator, we compute a smoother expert visitation distribution estimate to match. In the presence of general function approximation, we prove a meta theorem reducing the performance gap of our approach to the parameter estimation error for offline classification (i.e. learning the expert policy). In the tabular setting or with linear function approximation, our meta theorem shows that the performance gap incurred by our approach achieves the optimal $\widetilde{O} \left( \min({H^{3/2}} / {N}, {H} / {\sqrt{N}} \right)$ dependency, under significantly weaker assumptions compared to prior work. We implement multiple instantiations of our approach on several continuous control tasks and find that we are able to significantly improve policy performance across a variety of dataset sizes.
Incentivizing Combinatorial Bandit Exploration
Jun 01, 2022Consider a bandit algorithm that recommends actions to self-interested users in a recommendation system. The users are free to choose other actions and need to be incentivized to follow the algorithm's recommendations. While the users prefer to exploit, the algorithm can incentivize them to explore by leveraging the information collected from the previous users. All published work on this problem, known as incentivized exploration, focuses on small, unstructured action sets and mainly targets the case when the users' beliefs are independent across actions. However, realistic exploration problems often feature large, structured action sets and highly correlated beliefs. We focus on a paradigmatic exploration problem with structure: combinatorial semi-bandits. We prove that Thompson Sampling, when applied to combinatorial semi-bandits, is incentive-compatible when initialized with a sufficient number of samples of each arm (where this number is determined in advance by the Bayesian prior). Moreover, we design incentive-compatible algorithms for collecting the initial samples.
Meta-Learning Adversarial Bandits
May 27, 2022We study online learning with bandit feedback across multiple tasks, with the goal of improving average performance across tasks if they are similar according to some natural task-similarity measure. As the first to target the adversarial setting, we design a unified meta-algorithm that yields setting-specific guarantees for two important cases: multi-armed bandits (MAB) and bandit linear optimization (BLO). For MAB, the meta-algorithm tunes the initialization, step-size, and entropy parameter of the Tsallis-entropy generalization of the well-known Exp3 method, with the task-averaged regret provably improving if the entropy of the distribution over estimated optima-in-hindsight is small. For BLO, we learn the initialization, step-size, and boundary-offset of online mirror descent (OMD) with self-concordant barrier regularizers, showing that task-averaged regret varies directly with a measure induced by these functions on the interior of the action space. Our adaptive guarantees rely on proving that unregularized follow-the-leader combined with multiplicative weights is enough to online learn a non-smooth and non-convex sequence of affine functions of Bregman divergences that upper-bound the regret of OMD.