 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhipeng Luo
Efficient Architecture Search for Continual Learning
Jun 07, 2020
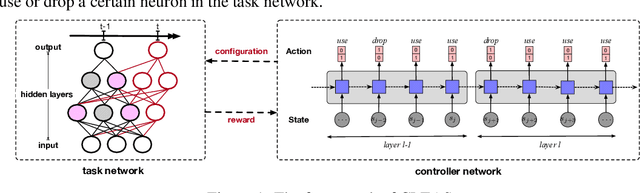
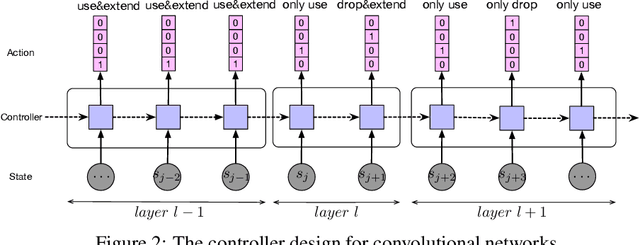
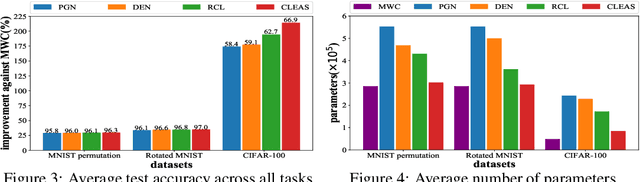

Continual learning with neural networks is an important learning framework in AI that aims to learn a sequence of tasks well. However, it is often confronted with three challenges: (1) overcome the catastrophic forgetting problem, (2) adapt the current network to new tasks, and meanwhile (3) control its model complexity. To reach these goals, we propose a novel approach named as Continual Learning with Efficient Architecture Search, or CLEAS in short. CLEAS works closely with neural architecture search (NAS) which leverages reinforcement learning techniques to search for the best neural architecture that fits a new task. In particular, we design a neuron-level NAS controller that decides which old neurons from previous tasks should be reused (knowledge transfer), and which new neurons should be added (to learn new knowledge). Such a fine-grained controller allows one to find a very concise architecture that can fit each new task well. Meanwhile, since we do not alter the weights of the reused neurons, we perfectly memorize the knowledge learned from previous tasks. We evaluate CLEAS on numerous sequential classification tasks, and the results demonstrate that CLEAS outperforms other state-of-the-art alternative methods, achieving higher classification accuracy while using simpler neural architectures.
Challenge report: Recognizing Families In the Wild Data Challenge
May 30, 2020
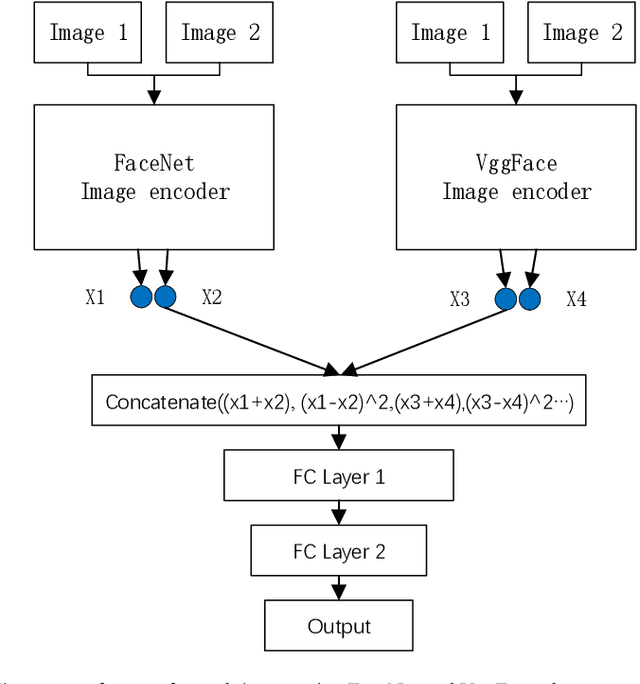
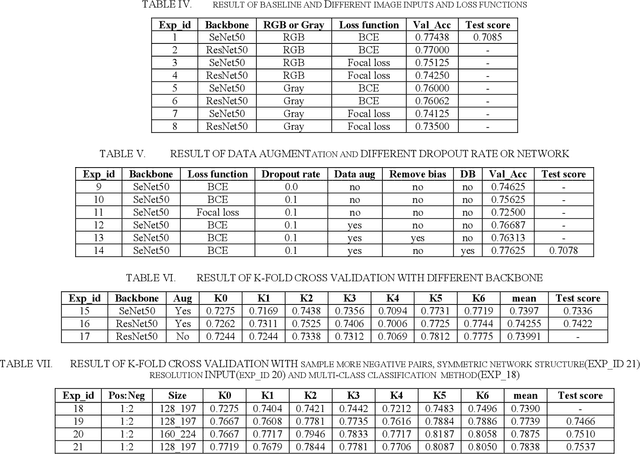
This paper is a brief report to our submission to the Recognizing Families In the Wild Data Challenge (4th Edition), in conjunction with FG 2020 Forum. Automatic kinship recognition has attracted many researchers' attention for its full application, but it is still a very challenging task because of the limited information that can be used to determine whether a pair of faces are blood relatives or not. In this paper, we studied previous methods and proposed our method. We try many methods, like deep metric learning-based, to extract deep embedding feature for every image, then determine if they are blood relatives by Euclidean distance or method based on classes. Finally, we find some tricks like sampling more negative samples and high resolution that can help get better performance. Moreover, we proposed a symmetric network with a binary classification based method to get our best score in all tasks.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
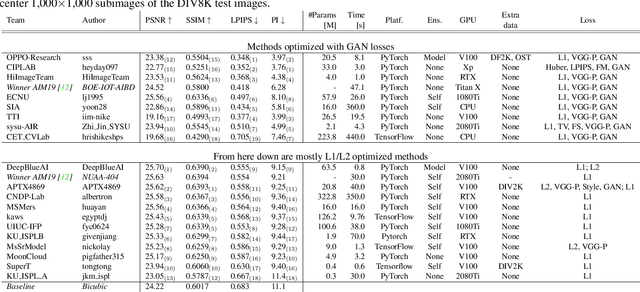

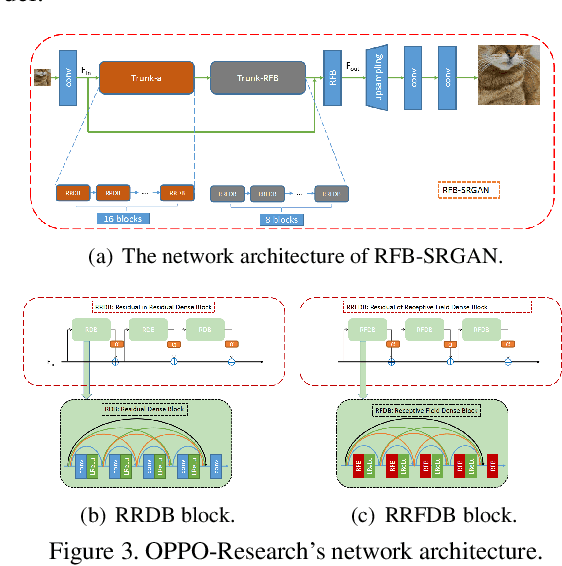
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
PointNLM: Point Nonlocal-Means for vegetation segmentation based on middle echo point clouds
Jun 20, 2019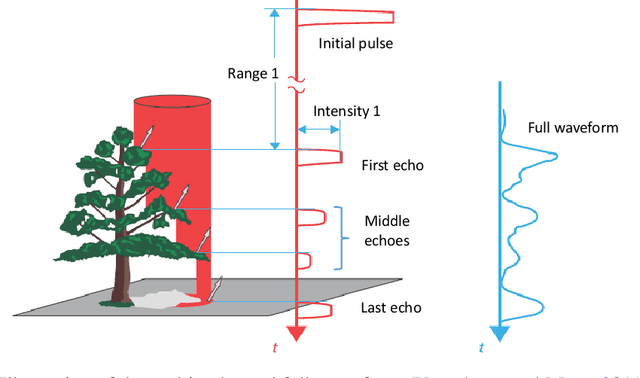
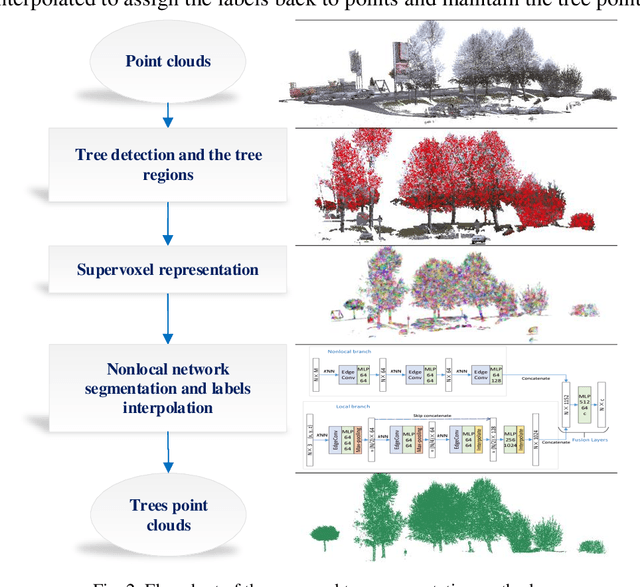

Middle-echo, which covers one or a few corresponding points, is a specific type of 3D point cloud acquired by a multi-echo laser scanner. In this paper, we propose a novel approach for automatic segmentation of trees that leverages middle-echo information from LiDAR point clouds. First, using a convolution classification method, the proposed type of point clouds reflected by the middle echoes are identified from all point clouds. The middle-echo point clouds are distinguished from the first and last echoes. Hence, the crown positions of the trees are quickly detected from the huge number of point clouds. Second, to accurately extract trees from all point clouds, we propose a 3D deep learning network, PointNLM, to semantically segment tree crowns. PointNLM captures the long-range relationship between the point clouds via a non-local branch and extracts high-level features via max-pooling applied to unordered points. The whole framework is evaluated using the Semantic 3D reduced-test set. The IoU of tree point cloud segmentation reached 0.864. In addition, the semantic segmentation network was tested using the Paris-Lille-3D dataset. The average IoU outperformed several other popular methods. The experimental results indicate that the proposed algorithm provides an excellent solution for vegetation segmentation from LiDAR point clouds.
User-level Weibo Recommendation incorporating Social Influence based on Semi-Supervised Algorithm
Oct 26, 2012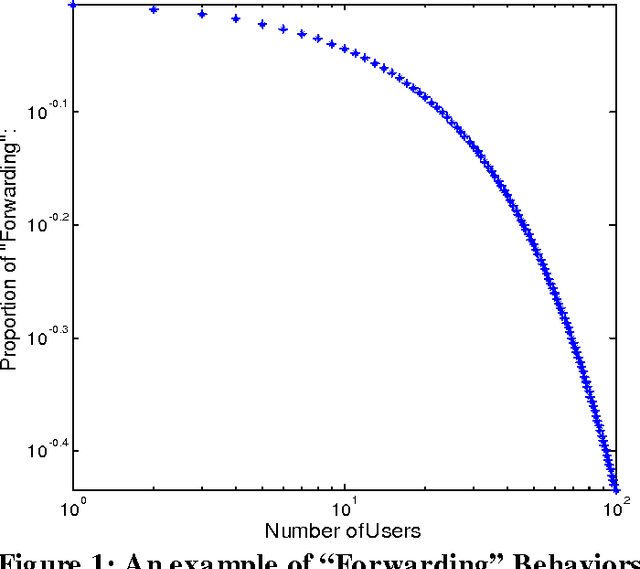

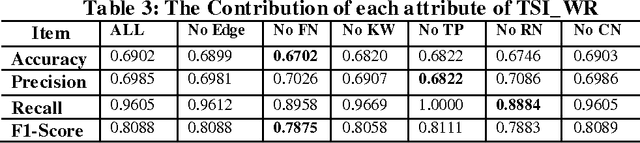
Tencent Weibo, as one of the most popular micro-blogging services in China, has attracted millions of users, producing 30-60 millions of weibo (similar as tweet in Twitter) daily. With the overload problem of user generate content, Tencent users find it is more and more hard to browse and find valuable information at the first time. In this paper, we propose a Factor Graph based weibo recommendation algorithm TSI-WR (Topic-Level Social Influence based Weibo Recommendation), which could help Tencent users to find most suitable information. The main innovation is that we consider both direct and indirect social influence from topic level based on social balance theory. The main advantages of adopting this strategy are that it could first build a more accurate description of latent relationship between two users with weak connections, which could help to solve the data sparsity problem; second provide a more accurate recommendation for a certain user from a wider range. Other meaningful contextual information is also combined into our model, which include: Users profile, Users influence, Content of weibos, Topic information of weibos and etc. We also design a semi-supervised algorithm to further reduce the influence of data sparisty. The experiments show that all the selected variables are important and the proposed model outperforms several baseline methods.
Topic-Level Opinion Influence Model(TOIM): An Investigation Using Tencent Micro-Blogging
Oct 24, 2012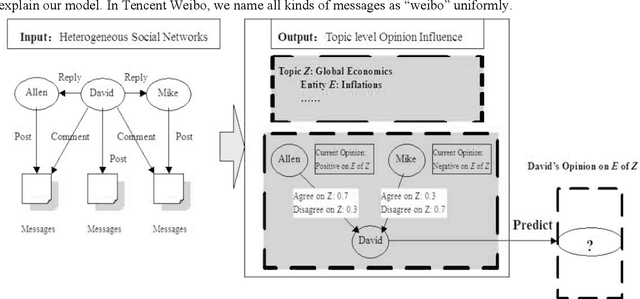
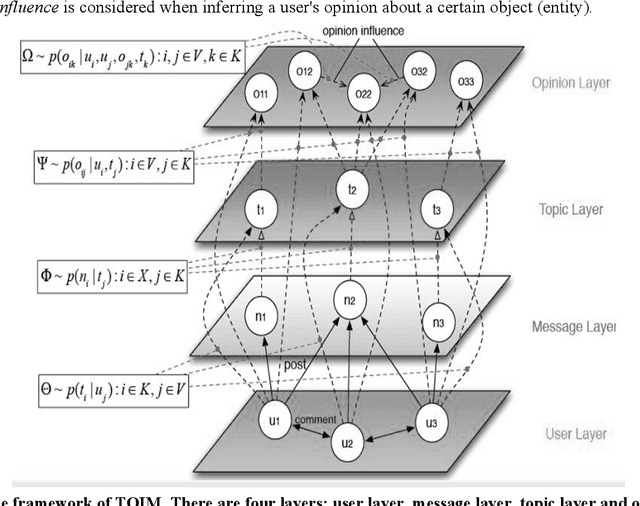
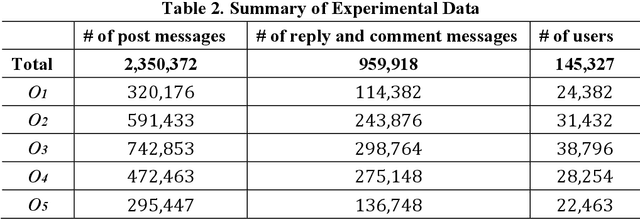
Mining user opinion from Micro-Blogging has been extensively studied on the most popular social networking sites such as Twitter and Facebook in the U.S., but few studies have been done on Micro-Blogging websites in other countries (e.g. China). In this paper, we analyze the social opinion influence on Tencent, one of the largest Micro-Blogging websites in China, endeavoring to unveil the behavior patterns of Chinese Micro-Blogging users. This paper proposes a Topic-Level Opinion Influence Model (TOIM) that simultaneously incorporates topic factor and social direct influence in a unified probabilistic framework. Based on TOIM, two topic level opinion influence propagation and aggregation algorithms are developed to consider the indirect influence: CP (Conservative Propagation) and NCP (None Conservative Propagation). Users' historical social interaction records are leveraged by TOIM to construct their progressive opinions and neighbors' opinion influence through a statistical learning process, which can be further utilized to predict users' future opinions on some specific topics. To evaluate and test this proposed model, an experiment was designed and a sub-dataset from Tencent Micro-Blogging was used. The experimental results show that TOIM outperforms baseline methods on predicting users' opinion. The applications of CP and NCP have no significant differences and could significantly improve recall and F1-measure of TOIM.