 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV-VTON: Multi-View Virtual Try-On with Diffusion Models
Apr 29, 2024The goal of image-based virtual try-on is to generate an image of the target person naturally wearing the given clothing. However, most existing methods solely focus on the frontal try-on using the frontal clothing. When the views of the clothing and person are significantly inconsistent, particularly when the person's view is non-frontal, the results are unsatisfactory. To address this challenge, we introduce Multi-View Virtual Try-ON (MV-VTON), which aims to reconstruct the dressing results of a person from multiple views using the given clothes. On the one hand, given that single-view clothes provide insufficient information for MV-VTON, we instead employ two images, i.e., the frontal and back views of the clothing, to encompass the complete view as much as possible. On the other hand, the diffusion models that have demonstrated superior abilities are adopted to perform our MV-VTON. In particular, we propose a view-adaptive selection method where hard-selection and soft-selection are applied to the global and local clothing feature extraction, respectively. This ensures that the clothing features are roughly fit to the person's view. Subsequently, we suggest a joint attention block to align and fuse clothing features with person features. Additionally, we collect a MV-VTON dataset, i.e., Multi-View Garment (MVG), in which each person has multiple photos with diverse views and poses. Experiments show that the proposed method not only achieves state-of-the-art results on MV-VTON task using our MVG dataset, but also has superiority on frontal-view virtual try-on task using VITON-HD and DressCode datasets. Codes and datasets will be publicly released at https://github.com/hywang2002/MV-VTON .
NIR-Assisted Image Denoising: A Selective Fusion Approach and A Real-World Benchmark Datase
Apr 12, 2024Despite the significant progress in image denoising, it is still challenging to restore fine-scale details while removing noise, especially in extremely low-light environments. Leveraging near-infrared (NIR) images to assist visible RGB image denoising shows the potential to address this issue, becoming a promising technology. Nonetheless, existing works still struggle with taking advantage of NIR information effectively for real-world image denoising, due to the content inconsistency between NIR-RGB images and the scarcity of real-world paired datasets. To alleviate the problem, we propose an efficient Selective Fusion Module (SFM), which can be plug-and-played into the advanced denoising networks to merge the deep NIR-RGB features. Specifically, we sequentially perform the global and local modulation for NIR and RGB features, and then integrate the two modulated features. Furthermore, we present a Real-world NIR-Assisted Image Denoising (Real-NAID) dataset, which covers diverse scenarios as well as various noise levels. Extensive experiments on both synthetic and our real-world datasets demonstrate that the proposed method achieves better results than state-of-the-art ones. The dataset, codes, and pre-trained models will be publicly available at https://github.com/ronjonxu/NAID.
TBSN: Transformer-Based Blind-Spot Network for Self-Supervised Image Denoising
Apr 11, 2024



Blind-spot networks (BSN) have been prevalent network architectures in self-supervised image denoising (SSID). Existing BSNs are mostly conducted with convolution layers. Although transformers offer potential solutions to the limitations of convolutions and have demonstrated success in various image restoration tasks, their attention mechanisms may violate the blind-spot requirement, thus restricting their applicability in SSID. In this paper, we present a transformer-based blind-spot network (TBSN) by analyzing and redesigning the transformer operators that meet the blind-spot requirement. Specifically, TBSN follows the architectural principles of dilated BSNs, and incorporates spatial as well as channel self-attention layers to enhance the network capability. For spatial self-attention, an elaborate mask is applied to the attention matrix to restrict its receptive field, thus mimicking the dilated convolution. For channel self-attention, we observe that it may leak the blind-spot information when the channel number is greater than spatial size in the deep layers of multi-scale architectures. To eliminate this effect, we divide the channel into several groups and perform channel attention separately. Furthermore, we introduce a knowledge distillation strategy that distills TBSN into smaller denoisers to improve computational efficiency while maintaining performance. Extensive experiments on real-world image denoising datasets show that TBSN largely extends the receptive field and exhibits favorable performance against state-of-the-art SSID methods. The code and pre-trained models will be publicly available at https://github.com/nagejacob/TBSN.
Dual-Camera Smooth Zoom on Mobile Phones
Apr 07, 2024When zooming between dual cameras on a mobile, noticeable jumps in geometric content and image color occur in the preview, inevitably affecting the user's zoom experience. In this work, we introduce a new task, ie, dual-camera smooth zoom (DCSZ) to achieve a smooth zoom preview. The frame interpolation (FI) technique is a potential solution but struggles with ground-truth collection. To address the issue, we suggest a data factory solution where continuous virtual cameras are assembled to generate DCSZ data by rendering reconstructed 3D models of the scene. In particular, we propose a novel dual-camera smooth zoom Gaussian Splatting (ZoomGS), where a camera-specific encoding is introduced to construct a specific 3D model for each virtual camera. With the proposed data factory, we construct a synthetic dataset for DCSZ, and we utilize it to fine-tune FI models. In addition, we collect real-world dual-zoom images without ground-truth for evaluation. Extensive experiments are conducted with multiple FI methods. The results show that the fine-tuned FI models achieve a significant performance improvement over the original ones on DCSZ task. The datasets, codes, and pre-trained models will be publicly available.
Self-Supervised Video Desmoking for Laparoscopic Surgery
Mar 17, 2024Due to the difficulty of collecting real paired data, most existing desmoking methods train the models by synthesizing smoke, generalizing poorly to real surgical scenarios. Although a few works have explored single-image real-world desmoking in unpaired learning manners, they still encounter challenges in handling dense smoke. In this work, we address these issues together by introducing the self-supervised surgery video desmoking (SelfSVD). On the one hand, we observe that the frame captured before the activation of high-energy devices is generally clear (named pre-smoke frame, PS frame), thus it can serve as supervision for other smoky frames, making real-world self-supervised video desmoking practically feasible. On the other hand, in order to enhance the desmoking performance, we further feed the valuable information from PS frame into models, where a masking strategy and a regularization term are presented to avoid trivial solutions. In addition, we construct a real surgery video dataset for desmoking, which covers a variety of smoky scenes. Extensive experiments on the dataset show that our SelfSVD can remove smoke more effectively and efficiently while recovering more photo-realistic details than the state-of-the-art methods. The dataset, codes, and pre-trained models are available at \url{https://github.com/ZcsrenlongZ/SelfSVD}.
Bracketing is All You Need: Unifying Image Restoration and Enhancement Tasks with Multi-Exposure Images
Jan 01, 2024



It is challenging but highly desired to acquire high-quality photos with clear content in low-light environments. Although multi-image processing methods (using burst, dual-exposure, or multi-exposure images) have made significant progress in addressing this issue, they typically focus exclusively on specific restoration or enhancement tasks, being insufficient in exploiting multi-image. Motivated by that multi-exposure images are complementary in denoising, deblurring, high dynamic range imaging, and super-resolution, we propose to utilize bracketing photography to unify restoration and enhancement tasks in this work. Due to the difficulty in collecting real-world pairs, we suggest a solution that first pre-trains the model with synthetic paired data and then adapts it to real-world unlabeled images. In particular, a temporally modulated recurrent network (TMRNet) and self-supervised adaptation method are proposed. Moreover, we construct a data simulation pipeline to synthesize pairs and collect real-world images from 200 nighttime scenarios. Experiments on both datasets show that our method performs favorably against the state-of-the-art multi-image processing ones. The dataset, code, and pre-trained models are available at https://github.com/cszhilu1998/BracketIRE.
Improving Image Restoration through Removing Degradations in Textual Representations
Dec 28, 2023



In this paper, we introduce a new perspective for improving image restoration by removing degradation in the textual representations of a given degraded image. Intuitively, restoration is much easier on text modality than image one. For example, it can be easily conducted by removing degradation-related words while keeping the content-aware words. Hence, we combine the advantages of images in detail description and ones of text in degradation removal to perform restoration. To address the cross-modal assistance, we propose to map the degraded images into textual representations for removing the degradations, and then convert the restored textual representations into a guidance image for assisting image restoration. In particular, We ingeniously embed an image-to-text mapper and text restoration module into CLIP-equipped text-to-image models to generate the guidance. Then, we adopt a simple coarse-to-fine approach to dynamically inject multi-scale information from guidance to image restoration networks. Extensive experiments are conducted on various image restoration tasks, including deblurring, dehazing, deraining, and denoising, and all-in-one image restoration. The results showcase that our method outperforms state-of-the-art ones across all these tasks. The codes and models are available at \url{https://github.com/mrluin/TextualDegRemoval}.
DreamControl: Control-Based Text-to-3D Generation with 3D Self-Prior
Dec 11, 20233D generation has raised great attention in recent years. With the success of text-to-image diffusion models, the 2D-lifting technique becomes a promising route to controllable 3D generation. However, these methods tend to present inconsistent geometry, which is also known as the Janus problem. We observe that the problem is caused mainly by two aspects, i.e., viewpoint bias in 2D diffusion models and overfitting of the optimization objective. To address it, we propose a two-stage 2D-lifting framework, namely DreamControl, which optimizes coarse NeRF scenes as 3D self-prior and then generates fine-grained objects with control-based score distillation. Specifically, adaptive viewpoint sampling and boundary integrity metric are proposed to ensure the consistency of generated priors. The priors are then regarded as input conditions to maintain reasonable geometries, in which conditional LoRA and weighted score are further proposed to optimize detailed textures. DreamControl can generate high-quality 3D content in terms of both geometry consistency and texture fidelity. Moreover, our control-based optimization guidance is applicable to more downstream tasks, including user-guided generation and 3D animation. The project page is available at https://github.com/tyhuang0428/DreamControl.
Learning Real-World Image De-Weathering with Imperfect Supervision
Oct 23, 2023



Real-world image de-weathering aims at removing various undesirable weather-related artifacts. Owing to the impossibility of capturing image pairs concurrently, existing real-world de-weathering datasets often exhibit inconsistent illumination, position, and textures between the ground-truth images and the input degraded images, resulting in imperfect supervision. Such non-ideal supervision negatively affects the training process of learning-based de-weathering methods. In this work, we attempt to address the problem with a unified solution for various inconsistencies. Specifically, inspired by information bottleneck theory, we first develop a Consistent Label Constructor (CLC) to generate a pseudo-label as consistent as possible with the input degraded image while removing most weather-related degradations. In particular, multiple adjacent frames of the current input are also fed into CLC to enhance the pseudo-label. Then we combine the original imperfect labels and pseudo-labels to jointly supervise the de-weathering model by the proposed Information Allocation Strategy (IAS). During testing, only the de-weathering model is used for inference. Experiments on two real-world de-weathering datasets show that our method helps existing de-weathering models achieve better performance. Codes are available at https://github.com/1180300419/imperfect-deweathering.
Self-Supervised High Dynamic Range Imaging with Multi-Exposure Images in Dynamic Scenes
Oct 03, 2023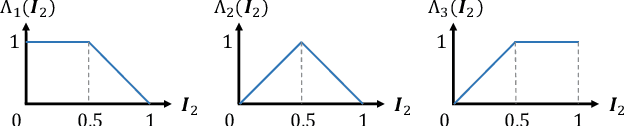
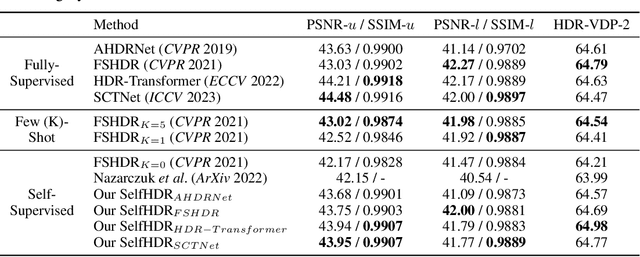
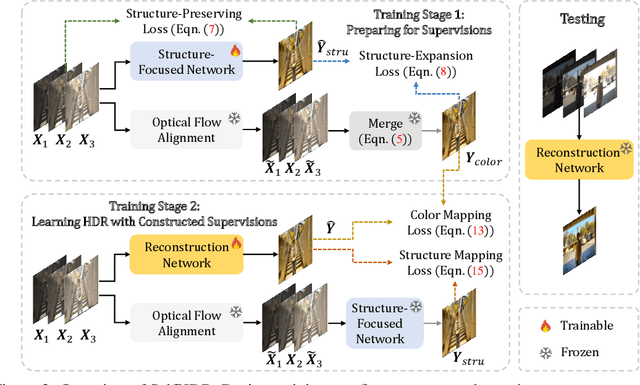

Merging multi-exposure images is a common approach for obtaining high dynamic range (HDR) images, with the primary challenge being the avoidance of ghosting artifacts in dynamic scenes. Recent methods have proposed using deep neural networks for deghosting. However, the methods typically rely on sufficient data with HDR ground-truths, which are difficult and costly to collect. In this work, to eliminate the need for labeled data, we propose SelfHDR, a self-supervised HDR reconstruction method that only requires dynamic multi-exposure images during training. Specifically, SelfHDR learns a reconstruction network under the supervision of two complementary components, which can be constructed from multi-exposure images and focus on HDR color as well as structure, respectively. The color component is estimated from aligned multi-exposure images, while the structure one is generated through a structure-focused network that is supervised by the color component and an input reference (\eg, medium-exposure) image. During testing, the learned reconstruction network is directly deployed to predict an HDR image. Experiments on real-world images demonstrate our SelfHDR achieves superior results against the state-of-the-art self-supervised methods, and comparable performance to supervised ones. Codes are available at https://github.com/cszhilu1998/SelfHDR