 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou
Nov 18, 2024



In recent years, with the significant evolution of multi-modal large models, many recommender researchers realized the potential of multi-modal information for user interest modeling. In industry, a wide-used modeling architecture is a cascading paradigm: (1) first pre-training a multi-modal model to provide omnipotent representations for downstream services; (2) The downstream recommendation model takes the multi-modal representation as additional input to fit real user-item behaviours. Although such paradigm achieves remarkable improvements, however, there still exist two problems that limit model performance: (1) Representation Unmatching: The pre-trained multi-modal model is always supervised by the classic NLP/CV tasks, while the recommendation models are supervised by real user-item interaction. As a result, the two fundamentally different tasks' goals were relatively separate, and there was a lack of consistent objective on their representations; (2) Representation Unlearning: The generated multi-modal representations are always stored in cache store and serve as extra fixed input of recommendation model, thus could not be updated by recommendation model gradient, further unfriendly for downstream training. Inspired by the two difficulties challenges in downstream tasks usage, we introduce a quantitative multi-modal framework to customize the specialized and trainable multi-modal information for different downstream models.
A Partition Filter Network for Joint Entity and Relation Extraction
Sep 09, 2021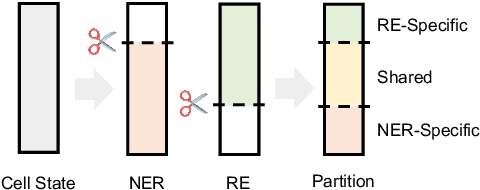
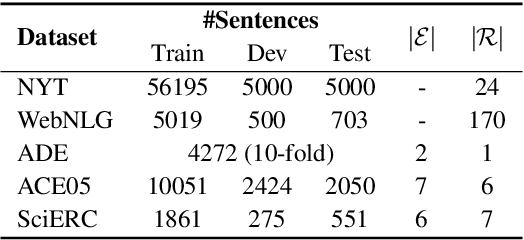
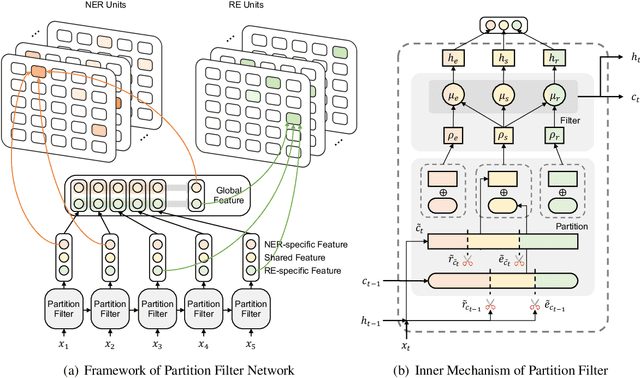
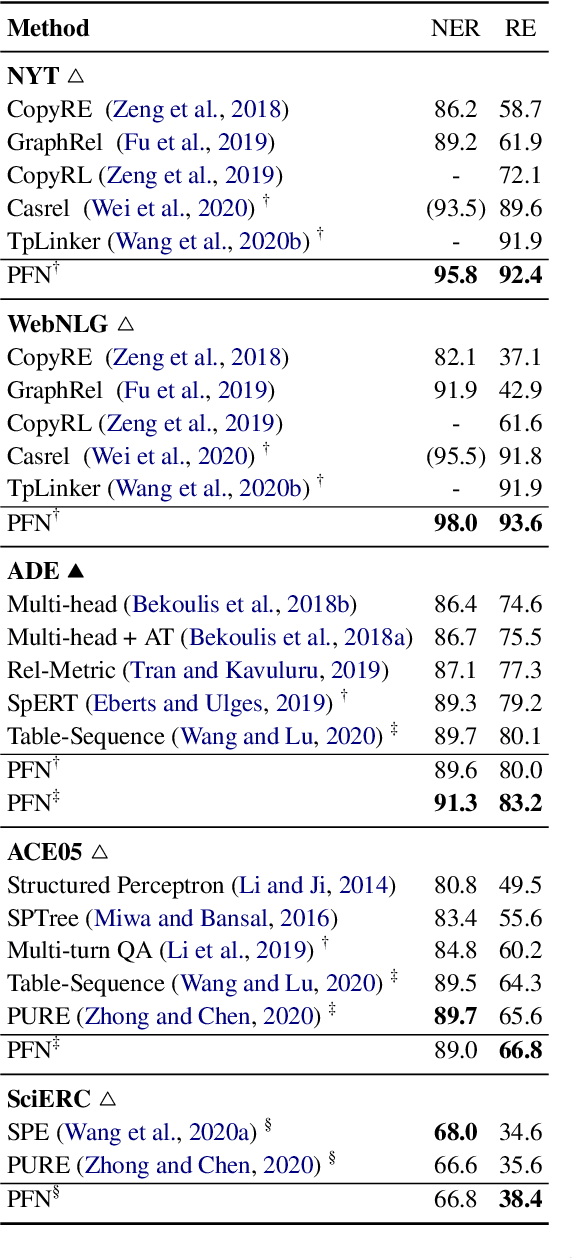
In joint entity and relation extraction, existing work either sequentially encode task-specific features, leading to an imbalance in inter-task feature interaction where features extracted later have no direct contact with those that come first. Or they encode entity features and relation features in a parallel manner, meaning that feature representation learning for each task is largely independent of each other except for input sharing. We propose a partition filter network to model two-way interaction between tasks properly, where feature encoding is decomposed into two steps: partition and filter. In our encoder, we leverage two gates: entity and relation gate, to segment neurons into two task partitions and one shared partition. The shared partition represents inter-task information valuable to both tasks and is evenly shared across two tasks to ensure proper two-way interaction. The task partitions represent intra-task information and are formed through concerted efforts of both gates, making sure that encoding of task-specific features is dependent upon each other. Experiment results on six public datasets show that our model performs significantly better than previous approaches. In addition, contrary to what previous work has claimed, our auxiliary experiments suggest that relation prediction is contributory to named entity prediction in a non-negligible way. The source code can be found at https://github.com/Coopercoppers/PFN.
TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing
Apr 06, 2021



Various robustness evaluation methodologies from different perspectives have been proposed for different natural language processing (NLP) tasks. These methods have often focused on either universal or task-specific generalization capabilities. In this work, we propose a multilingual robustness evaluation platform for NLP tasks (TextFlint) that incorporates universal text transformation, task-specific transformation, adversarial attack, subpopulation, and their combinations to provide comprehensive robustness analysis. TextFlint enables practitioners to automatically evaluate their models from all aspects or to customize their evaluations as desired with just a few lines of code. To guarantee user acceptability, all the text transformations are linguistically based, and we provide a human evaluation for each one. TextFlint generates complete analytical reports as well as targeted augmented data to address the shortcomings of the model's robustness. To validate TextFlint's utility, we performed large-scale empirical evaluations (over 67,000 evaluations) on state-of-the-art deep learning models, classic supervised methods, and real-world systems. Almost all models showed significant performance degradation, including a decline of more than 50% of BERT's prediction accuracy on tasks such as aspect-level sentiment classification, named entity recognition, and natural language inference. Therefore, we call for the robustness to be included in the model evaluation, so as to promote the healthy development of NLP technology.