 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Nonsmooth Convex Optimization with Heavy-Tailed Noises
Mar 25, 2023Recently, several studies consider the stochastic optimization problem but in a heavy-tailed noise regime, i.e., the difference between the stochastic gradient and the true gradient is assumed to have a finite $p$-th moment (say being upper bounded by $\sigma^{p}$ for some $\sigma\geq0$) where $p\in(1,2]$, which not only generalizes the traditional finite variance assumption ($p=2$) but also has been observed in practice for several different tasks. Under this challenging assumption, lots of new progress has been made for either convex or nonconvex problems, however, most of which only consider smooth objectives. In contrast, people have not fully explored and well understood this problem when functions are nonsmooth. This paper aims to fill this crucial gap by providing a comprehensive analysis of stochastic nonsmooth convex optimization with heavy-tailed noises. We revisit a simple clipping-based algorithm, whereas, which is only proved to converge in expectation but under the additional strong convexity assumption. Under appropriate choices of parameters, for both convex and strongly convex functions, we not only establish the first high-probability rates but also give refined in-expectation bounds compared with existing works. Remarkably, all of our results are optimal (or nearly optimal up to logarithmic factors) with respect to the time horizon $T$ even when $T$ is unknown in advance. Additionally, we show how to make the algorithm parameter-free with respect to $\sigma$, in other words, the algorithm can still guarantee convergence without any prior knowledge of $\sigma$.
A Finite Sample Complexity Bound for Distributionally Robust Q-learning
Mar 03, 2023We consider a reinforcement learning setting in which the deployment environment is different from the training environment. Applying a robust Markov decision processes formulation, we extend the distributionally robust $Q$-learning framework studied in Liu et al. [2022]. Further, we improve the design and analysis of their multi-level Monte Carlo estimator. Assuming access to a simulator, we prove that the worst-case expected sample complexity of our algorithm to learn the optimal robust $Q$-function within an $\epsilon$ error in the sup norm is upper bounded by $\tilde O(|S||A|(1-\gamma)^{-5}\epsilon^{-2}p_{\wedge}^{-6}\delta^{-4})$, where $\gamma$ is the discount rate, $p_{\wedge}$ is the non-zero minimal support probability of the transition kernels and $\delta$ is the uncertainty size. This is the first sample complexity result for the model-free robust RL problem. Simulation studies further validate our theoretical results.
Breaking the Lower Bound with (Little) Structure: Acceleration in Non-Convex Stochastic Optimization with Heavy-Tailed Noise
Feb 14, 2023We consider the stochastic optimization problem with smooth but not necessarily convex objectives in the heavy-tailed noise regime, where the stochastic gradient's noise is assumed to have bounded $p$th moment ($p\in(1,2]$). Zhang et al. (2020) is the first to prove the $\Omega(T^{\frac{1-p}{3p-2}})$ lower bound for convergence (in expectation) and provides a simple clipping algorithm that matches this optimal rate. Cutkosky and Mehta (2021) proposes another algorithm, which is shown to achieve the nearly optimal high-probability convergence guarantee $O(\log(T/\delta)T^{\frac{1-p}{3p-2}})$, where $\delta$ is the probability of failure. However, this desirable guarantee is only established under the additional assumption that the stochastic gradient itself is bounded in $p$th moment, which fails to hold even for quadratic objectives and centered Gaussian noise. In this work, we first improve the analysis of the algorithm in Cutkosky and Mehta (2021) to obtain the same nearly optimal high-probability convergence rate $O(\log(T/\delta)T^{\frac{1-p}{3p-2}})$, without the above-mentioned restrictive assumption. Next, and curiously, we show that one can achieve a faster rate than that dictated by the lower bound $\Omega(T^{\frac{1-p}{3p-2}})$ with only a tiny bit of structure, i.e., when the objective function $F(x)$ is assumed to be in the form of $\mathbb{E}_{\Xi\sim\mathcal{D}}[f(x,\Xi)]$, arguably the most widely applicable class of stochastic optimization problems. For this class of problems, we propose the first variance-reduced accelerated algorithm and establish that it guarantees a high-probability convergence rate of $O(\log(T/\delta)T^{\frac{1-p}{2p-1}})$ under a mild condition, which is faster than $\Omega(T^{\frac{1-p}{3p-2}})$. Notably, even when specialized to the finite-variance case, our result yields the (near-)optimal high-probability rate $O(\log(T/\delta)T^{-1/3})$.
Near-Optimal High-Probability Convergence for Non-Convex Stochastic Optimization with Variance Reduction
Feb 13, 2023Traditional analyses for non-convex stochastic optimization problems characterize convergence bounds in expectation, which is inadequate as it does not supply a useful performance guarantee on a single run. Motivated by its importance, an emerging line of literature has recently studied the high-probability convergence behavior of several algorithms, including the classic stochastic gradient descent (SGD). However, no high-probability results are established for optimization algorithms with variance reduction, which is known to accelerate the convergence process and has been the de facto algorithmic technique for stochastic optimization at large. To close this important gap, we introduce a new variance-reduced algorithm for non-convex stochastic optimization, which we call Generalized SignSTORM. We show that with probability at least $1-\delta$, our algorithm converges at the rate of $O(\log(dT/\delta)/T^{1/3})$ after $T$ iterations where $d$ is the problem dimension. This convergence guarantee matches the existing lower bound up to a log factor, and to our best knowledge, is the first high-probability minimax (near-)optimal result. Finally, we demonstrate the effectiveness of our algorithm through numerical experiments.
Single-Trajectory Distributionally Robust Reinforcement Learning
Jan 27, 2023



As a framework for sequential decision-making, Reinforcement Learning (RL) has been regarded as an essential component leading to Artificial General Intelligence (AGI). However, RL is often criticized for having the same training environment as the test one, which also hinders its application in the real world. To mitigate this problem, Distributionally Robust RL (DRRL) is proposed to improve the worst performance in a set of environments that may contain the unknown test environment. Due to the nonlinearity of the robustness goal, most of the previous work resort to the model-based approach, learning with either an empirical distribution learned from the data or a simulator that can be sampled infinitely, which limits their applications in simple dynamics environments. In contrast, we attempt to design a DRRL algorithm that can be trained along a single trajectory, i.e., no repeated sampling from a state. Based on the standard Q-learning, we propose distributionally robust Q-learning with the single trajectory (DRQ) and its average-reward variant named differential DRQ. We provide asymptotic convergence guarantees and experiments for both settings, demonstrating their superiority in the perturbed environments against the non-robust ones.
Leveraging the Hints: Adaptive Bidding in Repeated First-Price Auctions
Nov 05, 2022



With the advent and increasing consolidation of e-commerce, digital advertising has very recently replaced traditional advertising as the main marketing force in the economy. In the past four years, a particularly important development in the digital advertising industry is the shift from second-price auctions to first-price auctions for online display ads. This shift immediately motivated the intellectually challenging question of how to bid in first-price auctions, because unlike in second-price auctions, bidding one's private value truthfully is no longer optimal. Following a series of recent works in this area, we consider a differentiated setup: we do not make any assumption about other bidders' maximum bid (i.e. it can be adversarial over time), and instead assume that we have access to a hint that serves as a prediction of other bidders' maximum bid, where the prediction is learned through some blackbox machine learning model. We consider two types of hints: one where a single point-prediction is available, and the other where a hint interval (representing a type of confidence region into which others' maximum bid falls) is available. We establish minimax optimal regret bounds for both cases and highlight the quantitatively different behavior between the two settings. We also provide improved regret bounds when the others' maximum bid exhibits the further structure of sparsity. Finally, we complement the theoretical results with demonstrations using real bidding data.
Distributionally Robust Offline Reinforcement Learning with Linear Function Approximation
Sep 29, 2022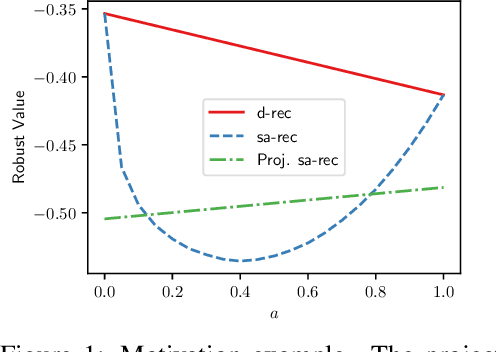
Among the reasons hindering reinforcement learning (RL) applications to real-world problems, two factors are critical: limited data and the mismatch between the testing environment (real environment in which the policy is deployed) and the training environment (e.g., a simulator). This paper attempts to address these issues simultaneously with distributionally robust offline RL, where we learn a distributionally robust policy using historical data obtained from the source environment by optimizing against a worst-case perturbation thereof. In particular, we move beyond tabular settings and consider linear function approximation. More specifically, we consider two settings, one where the dataset is well-explored and the other where the dataset has sufficient coverage. We propose two algorithms -- one for each of the two settings -- that achieve error bounds $\tilde{O}(d^{1/2}/N^{1/2})$ and $\tilde{O}(d^{3/2}/N^{1/2})$ respectively, where $d$ is the dimension in the linear function approximation and $N$ is the number of trajectories in the dataset. To the best of our knowledge, they provide the first non-asymptotic results of the sample complexity in this setting. Diverse experiments are conducted to demonstrate our theoretical findings, showing the superiority of our algorithm against the non-robust one.
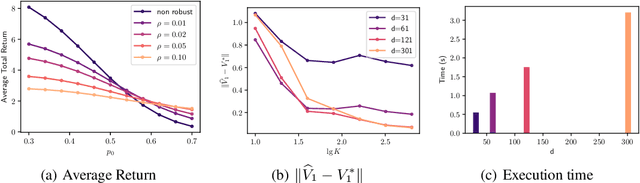
Optimal Diagonal Preconditioning: Theory and Practice
Sep 02, 2022
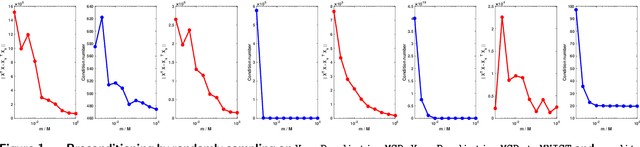

Preconditioning has been a staple technique in optimization and machine learning. It often reduces the condition number of the matrix it is applied to, thereby speeding up convergence of optimization algorithms. Although there are many popular preconditioning techniques in practice, most lack theoretical guarantees for reductions in condition number. In this paper, we study the problem of optimal diagonal preconditioning to achieve maximal reduction in the condition number of any full-rank matrix by scaling its rows or columns separately or simultaneously. We first reformulate the problem as a quasi-convex problem and provide a baseline bisection algorithm that is easy to implement in practice, where each iteration consists of an SDP feasibility problem. Then we propose a polynomial time potential reduction algorithm with $O(\log(\frac{1}{\epsilon}))$ iteration complexity, where each iteration consists of a Newton update based on the Nesterov-Todd direction. Our algorithm is based on a formulation of the problem which is a generalized version of the Von Neumann optimal growth problem. Next, we specialize to one-sided optimal diagonal preconditioning problems, and demonstrate that they can be formulated as standard dual SDP problems, to which we apply efficient customized solvers and study the empirical performance of our optimal diagonal preconditioners. Our extensive experiments on large matrices demonstrate the practical appeal of optimal diagonal preconditioners at reducing condition numbers compared to heuristics-based preconditioners.
Learning to Order for Inventory Systems with Lost Sales and Uncertain Supplies
Jul 10, 2022We consider a stochastic lost-sales inventory control system with a lead time $L$ over a planning horizon $T$. Supply is uncertain, and is a function of the order quantity (due to random yield/capacity, etc). We aim to minimize the $T$-period cost, a problem that is known to be computationally intractable even under known distributions of demand and supply. In this paper, we assume that both the demand and supply distributions are unknown and develop a computationally efficient online learning algorithm. We show that our algorithm achieves a regret (i.e. the performance gap between the cost of our algorithm and that of an optimal policy over $T$ periods) of $O(L+\sqrt{T})$ when $L\geq\log(T)$. We do so by 1) showing our algorithm cost is higher by at most $O(L+\sqrt{T})$ for any $L\geq 0$ compared to an optimal constant-order policy under complete information (a well-known and widely-used algorithm) and 2) leveraging its known performance guarantee from the existing literature. To the best of our knowledge, a finite-sample $O(\sqrt{T})$ (and polynomial in $L$) regret bound when benchmarked against an optimal policy is not known before in the online inventory control literature. A key challenge in this learning problem is that both demand and supply data can be censored; hence only truncated values are observable. We circumvent this challenge by showing that the data generated under an order quantity $q^2$ allows us to simulate the performance of not only $q^2$ but also $q^1$ for all $q^1<q^2$, a key observation to obtain sufficient information even under data censoring. By establishing a high probability coupling argument, we are able to evaluate and compare the performance of different order policies at their steady state within a finite time horizon. Since the problem lacks convexity, we develop an active elimination method that adaptively rules out suboptimal solutions.
Doubly Robust Distributionally Robust Off-Policy Evaluation and Learning
Feb 19, 2022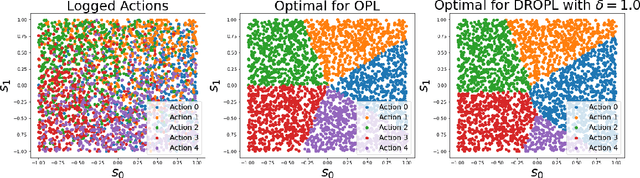
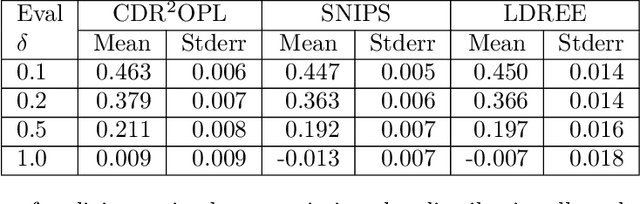
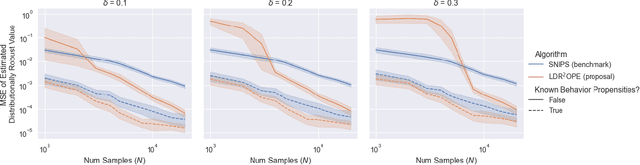
Off-policy evaluation and learning (OPE/L) use offline observational data to make better decisions, which is crucial in applications where experimentation is necessarily limited. OPE/L is nonetheless sensitive to discrepancies between the data-generating environment and that where policies are deployed. Recent work proposed distributionally robust OPE/L (DROPE/L) to remedy this, but the proposal relies on inverse-propensity weighting, whose regret rates may deteriorate if propensities are estimated and whose variance is suboptimal even if not. For vanilla OPE/L, this is solved by doubly robust (DR) methods, but they do not naturally extend to the more complex DROPE/L, which involves a worst-case expectation. In this paper, we propose the first DR algorithms for DROPE/L with KL-divergence uncertainty sets. For evaluation, we propose Localized Doubly Robust DROPE (LDR$^2$OPE) and prove its semiparametric efficiency under weak product rates conditions. Notably, thanks to a localization technique, LDR$^2$OPE only requires fitting a small number of regressions, just like DR methods for vanilla OPE. For learning, we propose Continuum Doubly Robust DROPL (CDR$^2$OPL) and show that, under a product rate condition involving a continuum of regressions, it enjoys a fast regret rate of $\mathcal{O}(N^{-1/2})$ even when unknown propensities are nonparametrically estimated. We further extend our results to general $f$-divergence uncertainty sets. We illustrate the advantage of our algorithms in simulations.