 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Learning Prosodic-Enhanced Representation of Rap Lyrics
Mar 23, 2021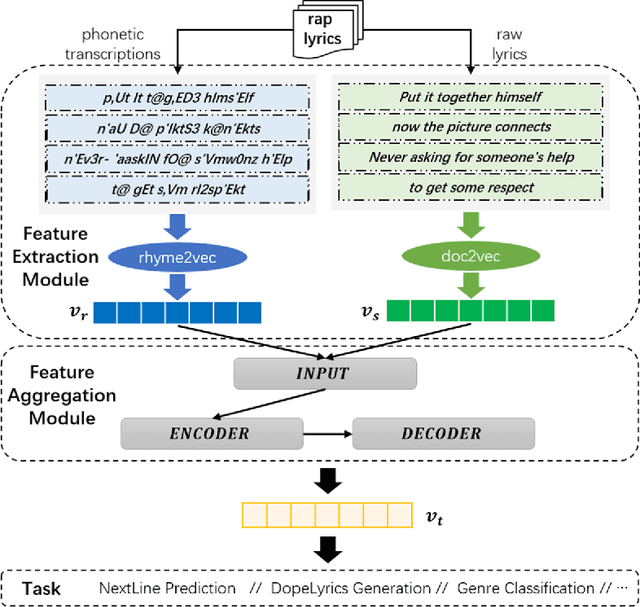


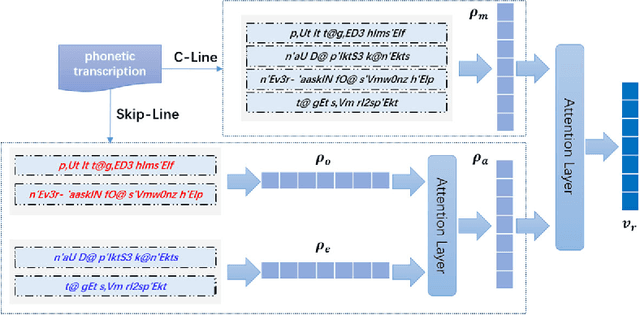
Learning and analyzing rap lyrics is a significant basis for many web applications, such as music recommendation, automatic music categorization, and music information retrieval, due to the abundant source of digital music in the World Wide Web. Although numerous studies have explored the topic, knowledge in this field is far from satisfactory, because critical issues, such as prosodic information and its effective representation, as well as appropriate integration of various features, are usually ignored. In this paper, we propose a hierarchical attention variational autoencoder framework (HAVAE), which simultaneously consider semantic and prosodic features for rap lyrics representation learning. Specifically, the representation of the prosodic features is encoded by phonetic transcriptions with a novel and effective strategy~(i.e., rhyme2vec). Moreover, a feature aggregation strategy is proposed to appropriately integrate various features and generate prosodic-enhanced representation. A comprehensive empirical evaluation demonstrates that the proposed framework outperforms the state-of-the-art approaches under various metrics in different rap lyrics learning tasks.
Generalized Relation Learning with Semantic Correlation Awareness for Link Prediction
Dec 22, 2020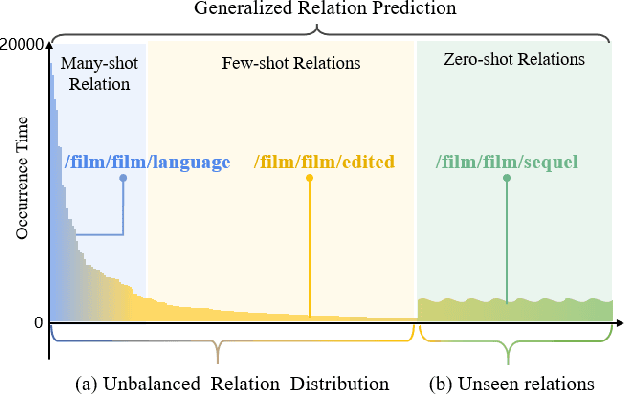
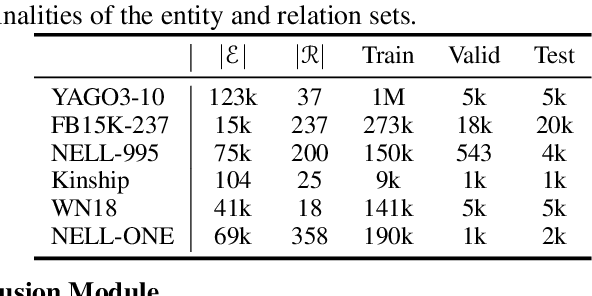
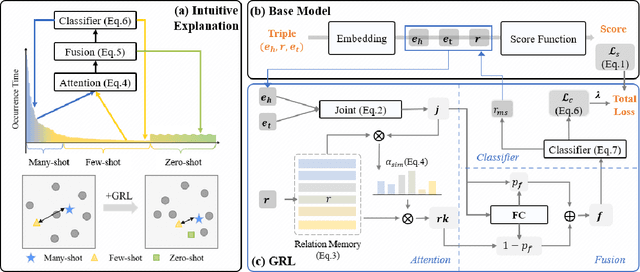
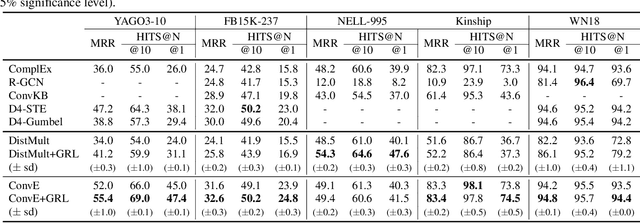
Developing link prediction models to automatically complete knowledge graphs has recently been the focus of significant research interest. The current methods for the link prediction taskhavetwonaturalproblems:1)the relation distributions in KGs are usually unbalanced, and 2) there are many unseen relations that occur in practical situations. These two problems limit the training effectiveness and practical applications of the existing link prediction models. We advocate a holistic understanding of KGs and we propose in this work a unified Generalized Relation Learning framework GRL to address the above two problems, which can be plugged into existing link prediction models. GRL conducts a generalized relation learning, which is aware of semantic correlations between relations that serve as a bridge to connect semantically similar relations. After training with GRL, the closeness of semantically similar relations in vector space and the discrimination of dissimilar relations are improved. We perform comprehensive experiments on six benchmarks to demonstrate the superior capability of GRL in the link prediction task. In particular, GRL is found to enhance the existing link prediction models making them insensitive to unbalanced relation distributions and capable of learning unseen relations.
GMH: A General Multi-hop Reasoning Model for KG Completion
Oct 16, 2020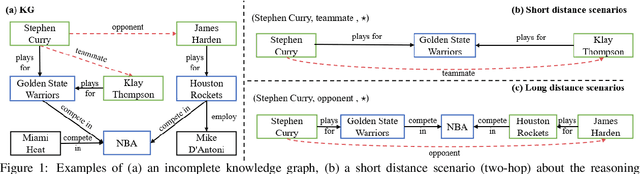
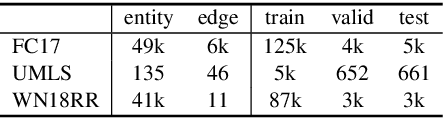
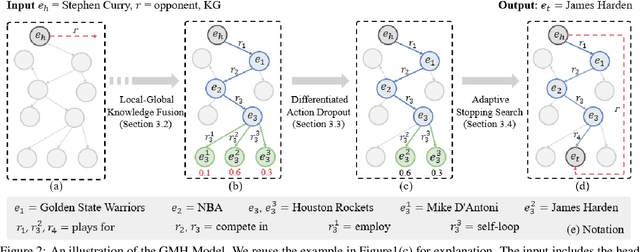
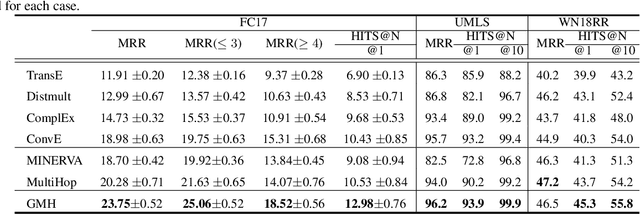
Knowledge graphs are essential for numerous downstream natural language processing applications, but are typically incomplete with many facts missing. This results in research efforts on multi-hop reasoning task, which can be formulated as a search process and current models typically perform short distance reasoning. However, the long-distance reasoning is also vital with the ability to connect the superficially unrelated entities. To the best of our knowledge, there lacks a general framework that approaches multi-hop reasoning in both short and long scenarios. We argue that there are two key issues for long distance reasoning: i) which edge to select, and ii) when to stop the search. In this work, we propose a general model which resolves the issues with three modules: 1) the local-global knowledge module to estimate the possible paths, 2) the differentiated action dropout module to explore a diverse set of paths, and 3) the adaptive stopping search module to avoid over searching. The comprehensive results on three datasets demonstrate the superiority of our model with significant improvements against baselines in both short and long distance reasoning scenarios.
Multi-modal Summarization for Video-containing Documents
Sep 17, 2020
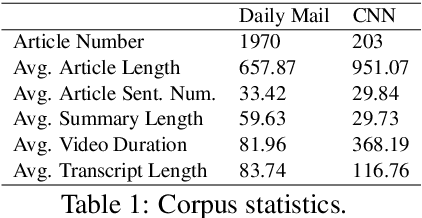
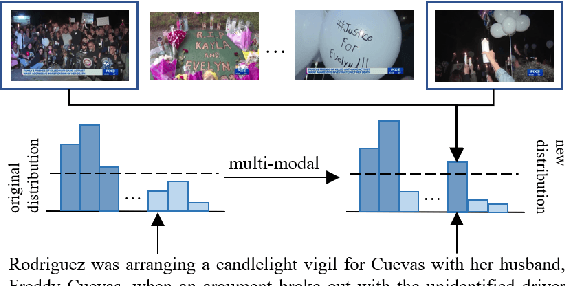
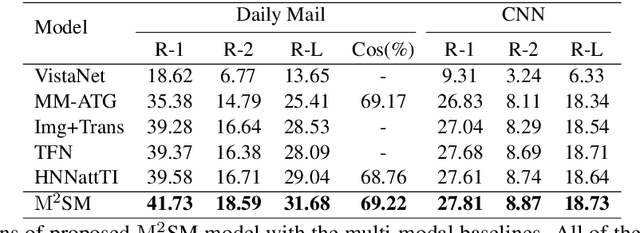
Summarization of multimedia data becomes increasingly significant as it is the basis for many real-world applications, such as question answering, Web search, and so forth. Most existing multi-modal summarization works however have used visual complementary features extracted from images rather than videos, thereby losing abundant information. Hence, we propose a novel multi-modal summarization task to summarize from a document and its associated video. In this work, we also build a baseline general model with effective strategies, i.e., bi-hop attention and improved late fusion mechanisms to bridge the gap between different modalities, and a bi-stream summarization strategy to employ text and video summarization simultaneously. Comprehensive experiments show that the proposed model is beneficial for multi-modal summarization and superior to existing methods. Moreover, we collect a novel dataset and it provides a new resource for future study that results from documents and videos.
Curriculum Pre-training for End-to-End Speech Translation
Apr 21, 2020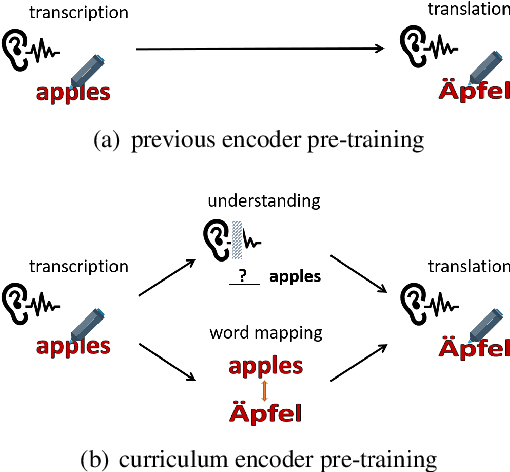
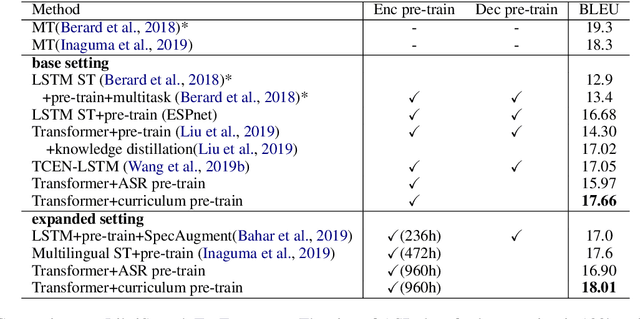
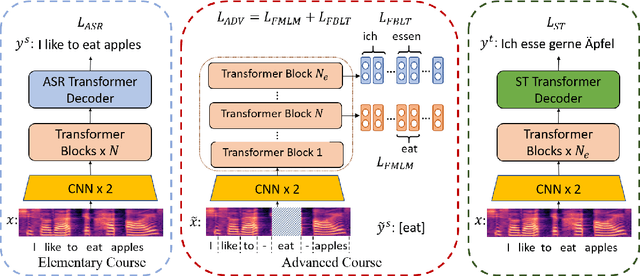
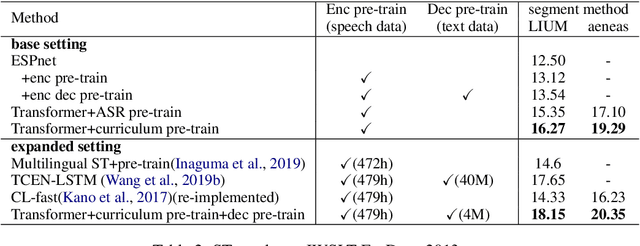
End-to-end speech translation poses a heavy burden on the encoder, because it has to transcribe, understand, and learn cross-lingual semantics simultaneously. To obtain a powerful encoder, traditional methods pre-train it on ASR data to capture speech features. However, we argue that pre-training the encoder only through simple speech recognition is not enough and high-level linguistic knowledge should be considered. Inspired by this, we propose a curriculum pre-training method that includes an elementary course for transcription learning and two advanced courses for understanding the utterance and mapping words in two languages. The difficulty of these courses is gradually increasing. Experiments show that our curriculum pre-training method leads to significant improvements on En-De and En-Fr speech translation benchmarks.
Attention Optimization for Abstractive Document Summarization
Oct 25, 2019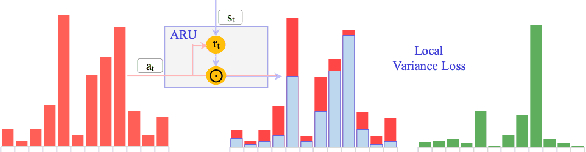
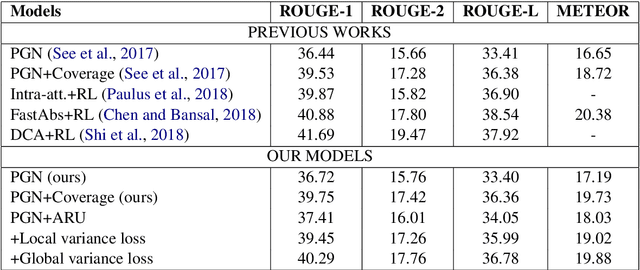
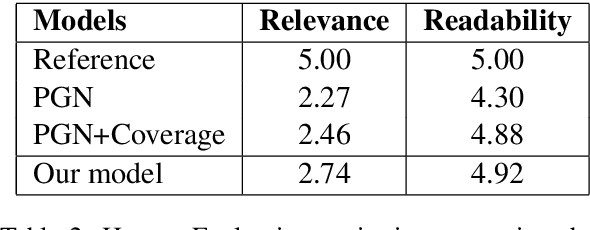
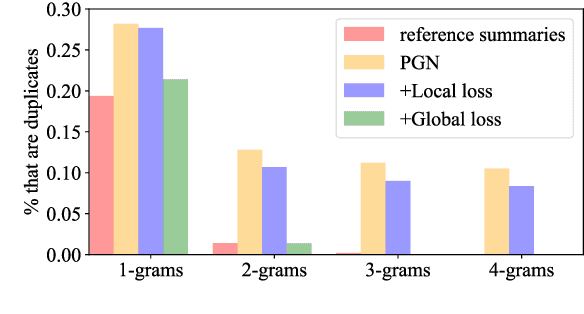
Attention plays a key role in the improvement of sequence-to-sequence-based document summarization models. To obtain a powerful attention helping with reproducing the most salient information and avoiding repetitions, we augment the vanilla attention model from both local and global aspects. We propose an attention refinement unit paired with local variance loss to impose supervision on the attention model at each decoding step, and a global variance loss to optimize the attention distributions of all decoding steps from the global perspective. The performances on the CNN/Daily Mail dataset verify the effectiveness of our methods.
Bridging the Gap between Pre-Training and Fine-Tuning for End-to-End Speech Translation
Sep 19, 2019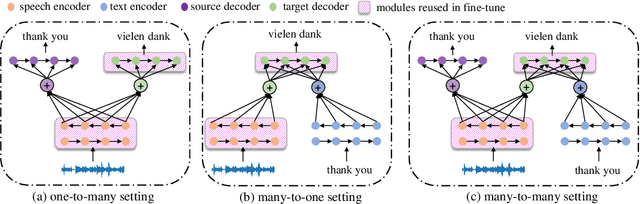

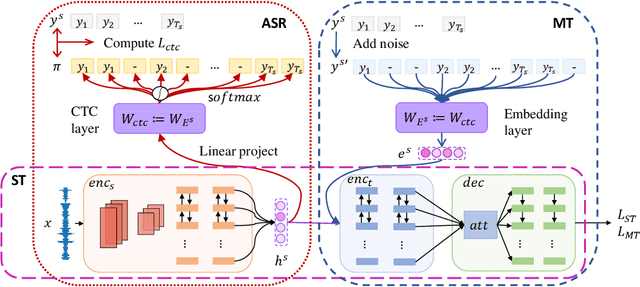

End-to-end speech translation, a hot topic in recent years, aims to translate a segment of audio into a specific language with an end-to-end model. Conventional approaches employ multi-task learning and pre-training methods for this task, but they suffer from the huge gap between pre-training and fine-tuning. To address these issues, we propose a Tandem Connectionist Encoding Network (TCEN) which bridges the gap by reusing all subnets in fine-tuning, keeping the roles of subnets consistent, and pre-training the attention module. Furthermore, we propose two simple but effective methods to guarantee the speech encoder outputs and the MT encoder inputs are consistent in terms of semantic representation and sequence length. Experimental results show that our model outperforms baselines 2.2 BLEU on a large benchmark dataset.
JTAV: Jointly Learning Social Media Content Representation by Fusing Textual, Acoustic, and Visual Features
Jun 05, 2018
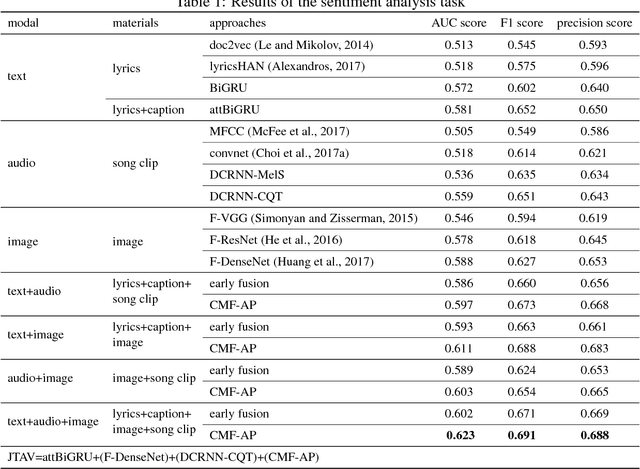
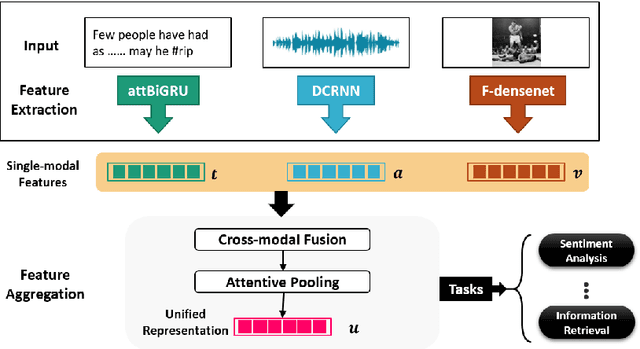
Learning social media content is the basis of many real-world applications, including information retrieval and recommendation systems, among others. In contrast with previous works that focus mainly on single modal or bi-modal learning, we propose to learn social media content by fusing jointly textual, acoustic, and visual information (JTAV). Effective strategies are proposed to extract fine-grained features of each modality, that is, attBiGRU and DCRNN. We also introduce cross-modal fusion and attentive pooling techniques to integrate multi-modal information comprehensively. Extensive experimental evaluation conducted on real-world datasets demonstrates our proposed model outperforms the state-of-the-art approaches by a large margin.
Automatic Generation of Grounded Visual Questions
May 29, 2017
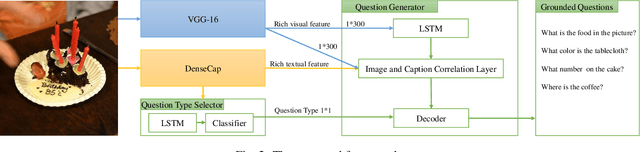


In this paper, we propose the first model to be able to generate visually grounded questions with diverse types for a single image. Visual question generation is an emerging topic which aims to ask questions in natural language based on visual input. To the best of our knowledge, it lacks automatic methods to generate meaningful questions with various types for the same visual input. To circumvent the problem, we propose a model that automatically generates visually grounded questions with varying types. Our model takes as input both images and the captions generated by a dense caption model, samples the most probable question types, and generates the questions in sequel. The experimental results on two real world datasets show that our model outperforms the strongest baseline in terms of both correctness and diversity with a wide margin.
* VQA