Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJTAV: Jointly Learning Social Media Content Representation by Fusing Textual, Acoustic, and Visual Features
Paper and Code

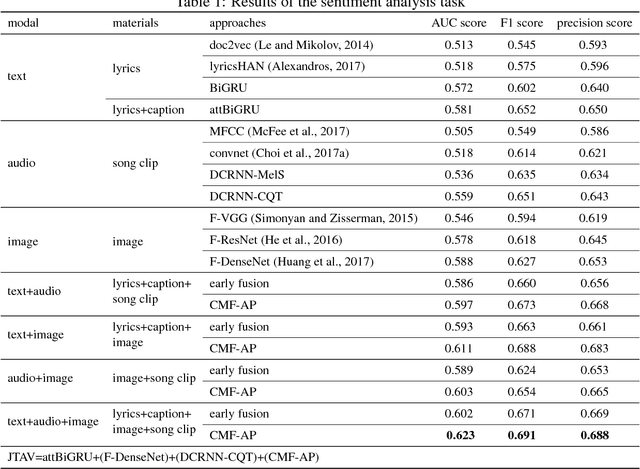
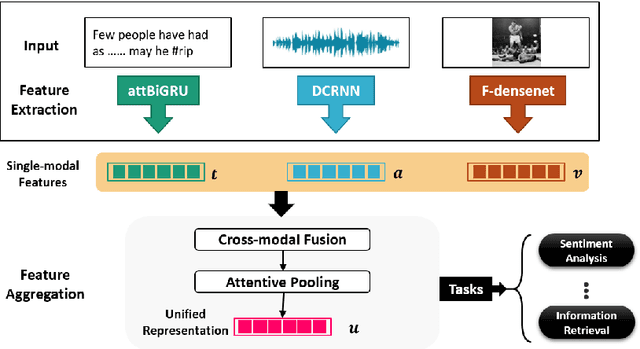
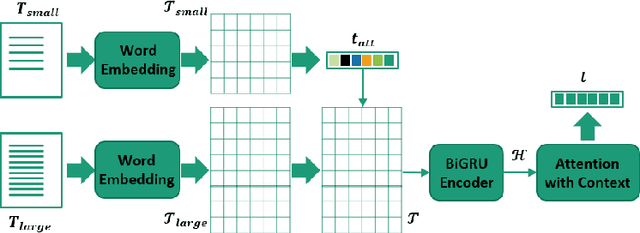
Learning social media content is the basis of many real-world applications, including information retrieval and recommendation systems, among others. In contrast with previous works that focus mainly on single modal or bi-modal learning, we propose to learn social media content by fusing jointly textual, acoustic, and visual information (JTAV). Effective strategies are proposed to extract fine-grained features of each modality, that is, attBiGRU and DCRNN. We also introduce cross-modal fusion and attentive pooling techniques to integrate multi-modal information comprehensively. Extensive experimental evaluation conducted on real-world datasets demonstrates our proposed model outperforms the state-of-the-art approaches by a large margin.
View paper on