 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Anti-Spoofing by Learning Polarization Cues in a Real-World Scenario
Mar 19, 2020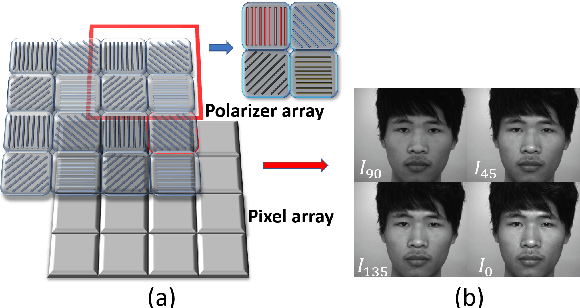
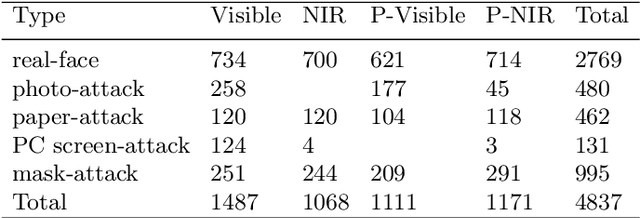
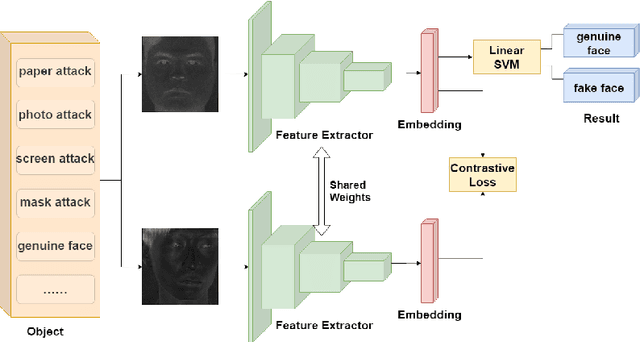
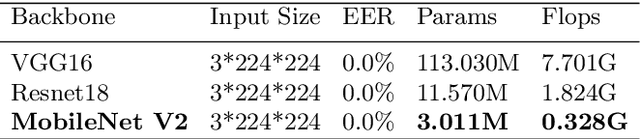
Face anti-spoofing is the key to preventing security breaches in biometric recognition applications. Existing software-based and hardware-based face liveness detection methods are effective in constrained environments or designated datasets only. Deep learning method using RGB and infrared images demands a large amount of training data for new attacks. In this paper, we present a face anti-spoofing method in a real-world scenario by automatic learning the physical characteristics in polarization images of a real face compared to a deceptive attack. A computational framework is developed to extract and classify the unique face features using convolutional neural networks and SVM together. Our real-time polarized face anti-spoofing (PAAS) detection method uses a on-chip integrated polarization imaging sensor with optimized processing algorithms. Extensive experiments demonstrate the advantages of the PAAS technique to counter diverse face spoofing attacks (print, replay, mask) in uncontrolled indoor and outdoor conditions by learning polarized face images of 33 people. A four-directional polarized face image dataset is released to inspire future applications within biometric anti-spoofing field.
A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications
Jan 20, 2020
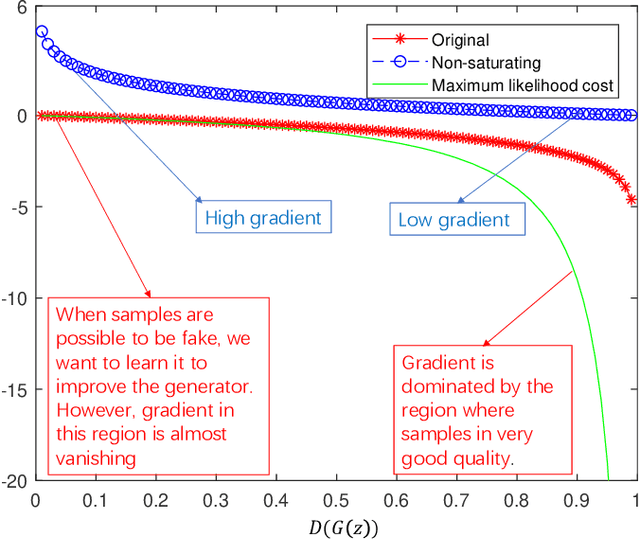

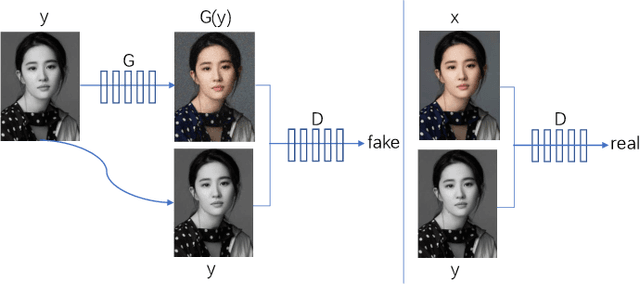
Generative adversarial networks (GANs) are a hot research topic recently. GANs have been widely studied since 2014, and a large number of algorithms have been proposed. However, there is few comprehensive study explaining the connections among different GANs variants, and how they have evolved. In this paper, we attempt to provide a review on various GANs methods from the perspectives of algorithms, theory, and applications. Firstly, the motivations, mathematical representations, and structure of most GANs algorithms are introduced in details. Furthermore, GANs have been combined with other machine learning algorithms for specific applications, such as semi-supervised learning, transfer learning, and reinforcement learning. This paper compares the commonalities and differences of these GANs methods. Secondly, theoretical issues related to GANs are investigated. Thirdly, typical applications of GANs in image processing and computer vision, natural language processing, music, speech and audio, medical field, and data science are illustrated. Finally, the future open research problems for GANs are pointed out.
Informative Sample Mining Network for Multi-Domain Image-to-Image Translation
Jan 05, 2020

The performance of multi-domain image-to-image translation has been significantly improved by recent progress in deep generative models. Existing approaches can use a unified model to achieve translations between all the visual domains. However, their outcomes are far from satisfying when there are large domain variations. In this paper, we reveal that improving the strategy of sample selection is an effective solution. To select informative samples, we dynamically estimate sample importance during the training of Generative Adversarial Networks, presenting Informative Sample Mining Network. We theoretically analyze the relationship between the sample importance and the prediction of the global optimal discriminator. Then a practical importance estimation function based on general discriminators is derived. In addition, we propose a novel multi-stage sample training scheme to reduce sample hardness while preserving sample informativeness. Extensive experiments on a wide range of specific image-to-image translation tasks are conducted, and the results demonstrate our superiority over current state-of-the-art methods.
Learning 3D Human Shape and Pose from Dense Body Parts
Dec 31, 2019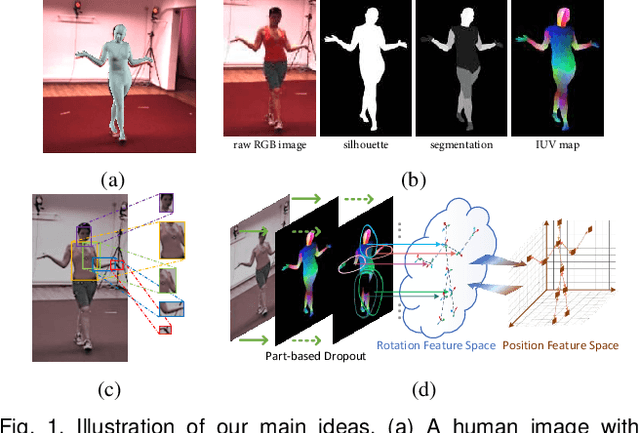
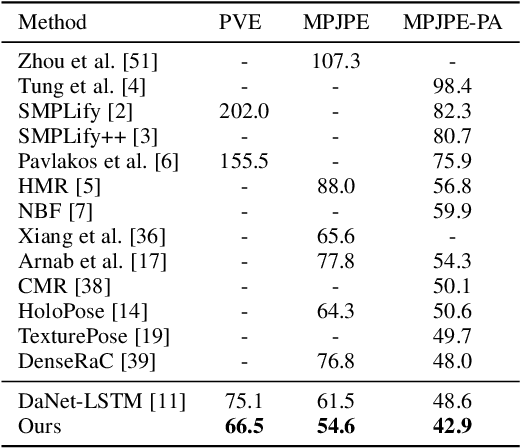
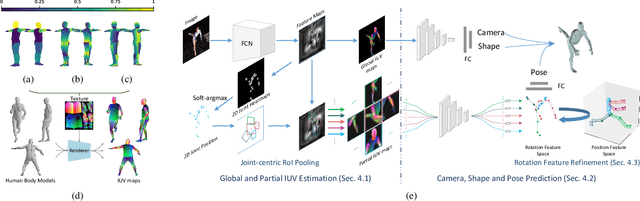
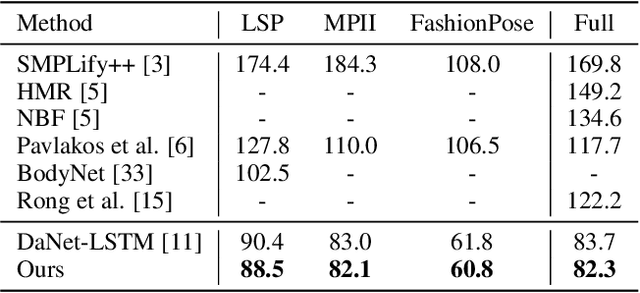
Reconstructing 3D human shape and pose from a monocular image is challenging despite the promising results achieved by the most recent learning-based methods. The commonly occurred misalignment comes from the facts that the mapping from images to the model space is highly non-linear and the rotation-based pose representation of the body model is prone to result in the drift of joint positions. In this work, we investigate learning 3D human shape and pose from dense correspondences of body parts and propose a Decompose-and-aggregate Network (DaNet) to address these issues. DaNet adopts the dense correspondence maps, which densely build a bridge between 2D pixels and 3D vertexes, as intermediate representations to facilitate the learning of 2D-to-3D mapping. The prediction modules of DaNet are decomposed into one global stream and multiple local streams to enable global and fine-grained perceptions for the shape and pose predictions, respectively. Messages from local streams are further aggregated to enhance the robust prediction of the rotation-based poses, where a position-aided rotation feature refinement strategy is proposed to exploit spatial relationships between body joints. Moreover, a Part-based Dropout (PartDrop) strategy is introduced to drop out dense information from intermediate representations during training, encouraging the network to focus on more complementary body parts as well as adjacent position features. The effectiveness of our method is validated on both in-door and real-world datasets including the Human3.6M, UP3D, and DensePose-COCO datasets. Experimental results show that the proposed method significantly improves the reconstruction performance in comparison with previous state-of-the-art methods. Our code will be made publicly available at https://hongwenzhang.github.io/dense2mesh .
Alignment Free and Distortion Robust Iris Recognition
Dec 01, 2019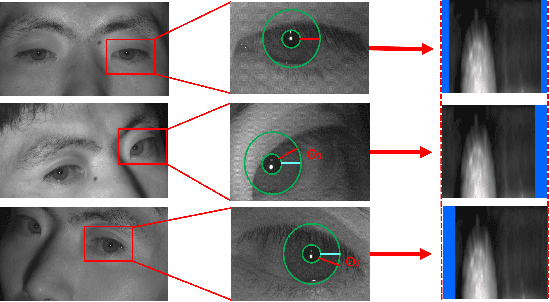
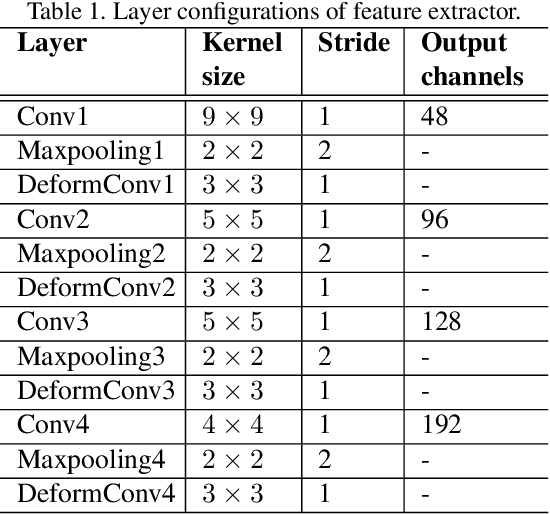
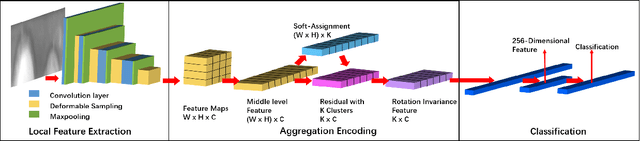
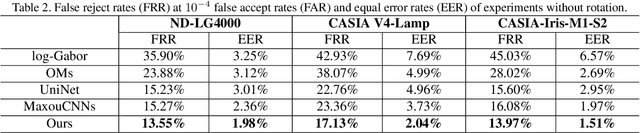
Iris recognition is a reliable personal identification method but there is still much room to improve its accuracy especially in less-constrained situations. For example, free movement of head pose may cause large rotation difference between iris images. And illumination variations may cause irregular distortion of iris texture. To match intra-class iris images with head rotation robustly, the existing solutions usually need a precise alignment operation by exhaustive search within a determined range in iris image preprosessing or brute force searching the minimum Hamming distance in iris feature matching. In the wild, iris rotation is of much greater uncertainty than that in constrained situations and exhaustive search within a determined range is impracticable. This paper presents a unified feature-level solution to both alignment free and distortion robust iris recognition in the wild. A new deep learning based method named Alignment Free Iris Network (AFINet) is proposed, which uses a trainable VLAD (Vector of Locally Aggregated Descriptors) encoder called NetVLAD to decouple the correlations between local representations and their spatial positions. And deformable convolution is used to overcome iris texture distortion by dense adaptive sampling. The results of extensive experiments on three public iris image databases and the simulated degradation databases show that AFINet significantly outperforms state-of-art iris recognition methods.
Dynamic Graph Representation for Partially Occluded Biometrics
Dec 01, 2019
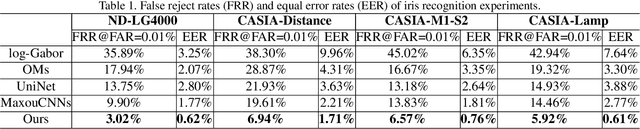
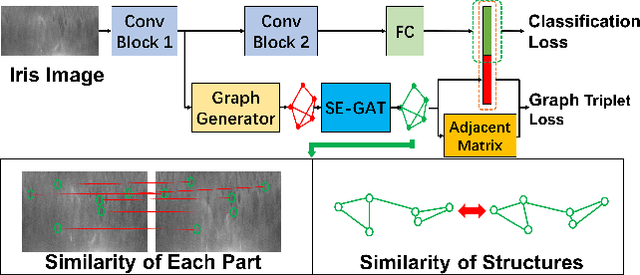
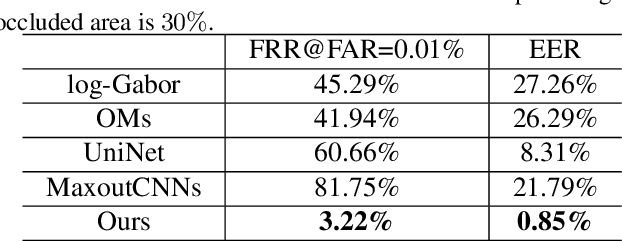
The generalization ability of Convolutional neural networks (CNNs) for biometrics drops greatly due to the adverse effects of various occlusions. To this end, we propose a novel unified framework integrated the merits of both CNNs and graphical models to learn dynamic graph representations for occlusion problems in biometrics, called Dynamic Graph Representation (DGR). Convolutional features onto certain regions are re-crafted by a graph generator to establish the connections among the spatial parts of biometrics and build Feature Graphs based on these node representations. Each node of Feature Graphs corresponds to a specific part of the input image and the edges express the spatial relationships between parts. By analyzing the similarities between the nodes, the framework is able to adaptively remove the nodes representing the occluded parts. During dynamic graph matching, we propose a novel strategy to measure the distances of both nodes and adjacent matrixes. In this way, the proposed method is more convincing than CNNs-based methods because the dynamic graph method implies a more illustrative and reasonable inference of the biometrics decision. Experiments conducted on iris and face demonstrate the superiority of the proposed framework, which boosts the accuracy of occluded biometrics recognition by a large margin comparing with baseline methods.
A3GAN: An Attribute-aware Attentive Generative Adversarial Network for Face Aging
Nov 15, 2019
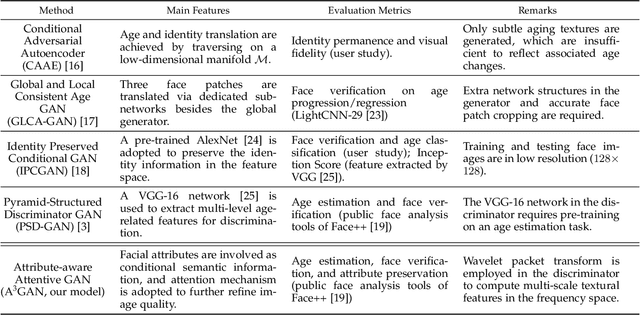
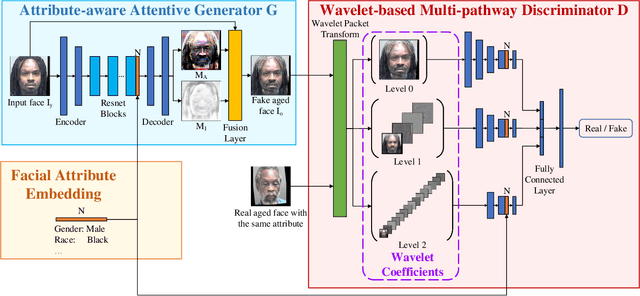
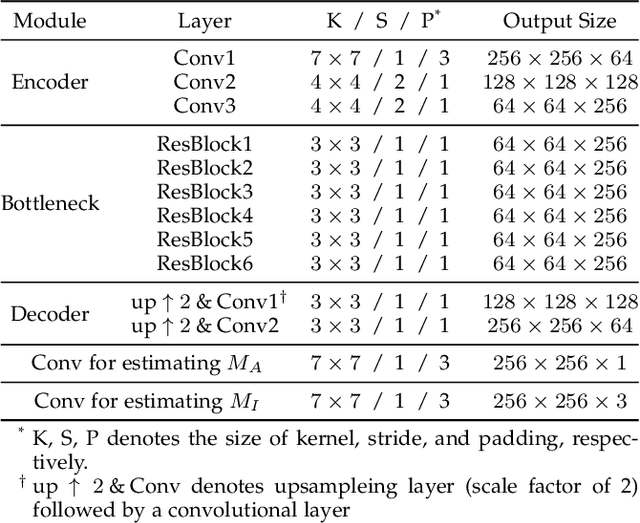
Face aging, which aims at aesthetically rendering a given face to predict its future appearance, has received significant research attention in recent years. Although great progress has been achieved with the success of Generative Adversarial Networks (GANs) in synthesizing realistic images, most existing GAN-based face aging methods have two main problems: 1) unnatural changes of high-level semantic information (e.g. facial attributes) due to the insufficient utilization of prior knowledge of input faces, and 2) distortions of low-level image content including ghosting artifacts and modifications in age-irrelevant regions. In this paper, we introduce A3GAN, an Attribute-Aware Attentive face aging model to address the above issues. Facial attribute vectors are regarded as the conditional information and embedded into both the generator and discriminator, encouraging synthesized faces to be faithful to attributes of corresponding inputs. To improve the visual fidelity of generation results, we leverage the attention mechanism to restrict modifications to age-related areas and preserve image details. Moreover, the wavelet packet transform is employed to capture textural features at multiple scales in the frequency space. Extensive experimental results demonstrate the effectiveness of our model in synthesizing photorealistic aged face images and achieving state-of-the-art performance on popular face aging datasets.
Biphasic Learning of GANs for High-Resolution Image-to-Image Translation
Apr 14, 2019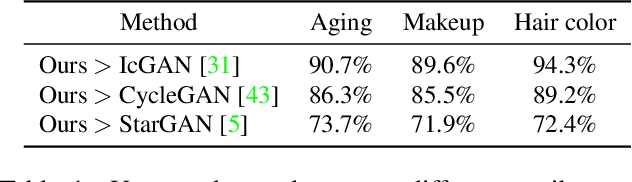
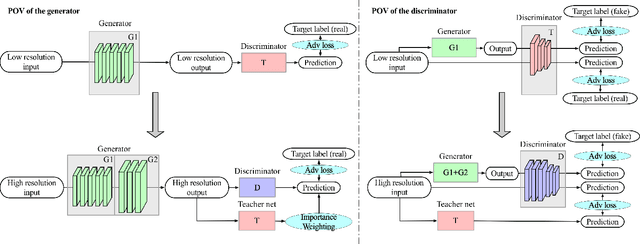
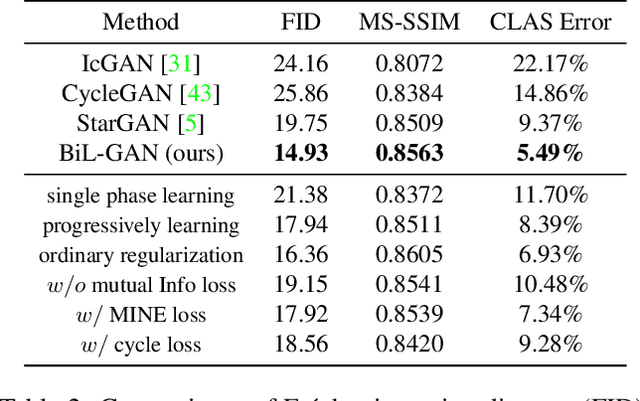

Despite that the performance of image-to-image translation has been significantly improved by recent progress in generative models, current methods still suffer from severe degradation in training stability and sample quality when applied to the high-resolution situation. In this work, we present a novel training framework for GANs, namely biphasic learning, to achieve image-to-image translation in multiple visual domains at $1024^2$ resolution. Our core idea is to design an adjustable objective function that varies across training phases. Within the biphasic learning framework, we propose a novel inherited adversarial loss to achieve the enhancement of model capacity and stabilize the training phase transition. Furthermore, we introduce a perceptual-level consistency loss through mutual information estimation and maximization. To verify the superiority of the proposed method, we apply it to a wide range of face-related synthesis tasks and conduct experiments on multiple large-scale datasets. Through comprehensive quantitative analyses, we demonstrate that our method significantly outperforms existing methods.
Foreground-aware Pyramid Reconstruction for Alignment-free Occluded Person Re-identification
Apr 11, 2019
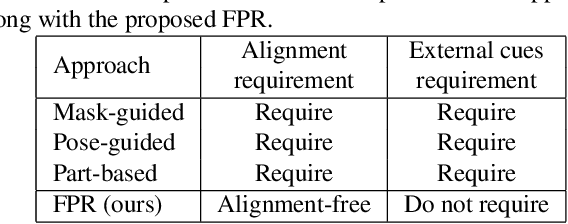
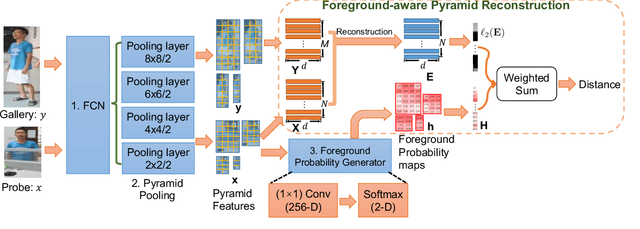

Re-identifying a person across multiple disjoint camera views is important for intelligent video surveillance, smart retailing and many other applications. However, existing person re-identification (ReID) methods are challenged by the ubiquitous occlusion over persons and suffer from performance degradation. This paper proposes a novel occlusion-robust and alignment-free model for occluded person ReID and extends its application to realistic and crowded scenarios. The proposed model first leverages the full convolution network (FCN) and pyramid pooling to extract spatial pyramid features. Then an alignment-free matching approach, namely Foreground-aware Pyramid Reconstruction (FPR), is developed to accurately compute matching scores between occluded persons, despite their different scales and sizes. FPR uses the error from robust reconstruction over spatial pyramid features to measure similarities between two persons. More importantly, we design an occlusion-sensitive foreground probability generator that focuses more on clean human body parts to refine the similarity computation with less contamination from occlusion. The FPR is easily embedded into any end-to-end person ReID models. The effectiveness of the proposed method is clearly demonstrated by the experimental results (Rank-1 accuracy) on three occluded person datasets: Partial REID (78.30\%), Partial iLIDS (68.08\%) and Occluded REID (81.00\%); and three benchmark person datasets: Market1501 (95.42\%), DukeMTMC (88.64\%) and CUHK03 (76.08\%)
Fast Supervised Discrete Hashing
Apr 07, 2019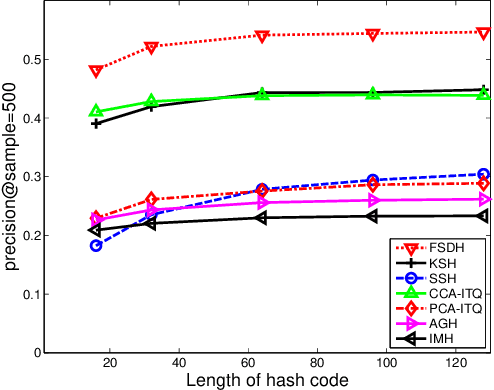
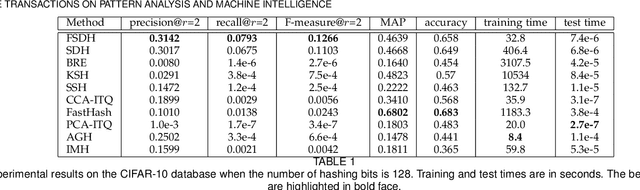
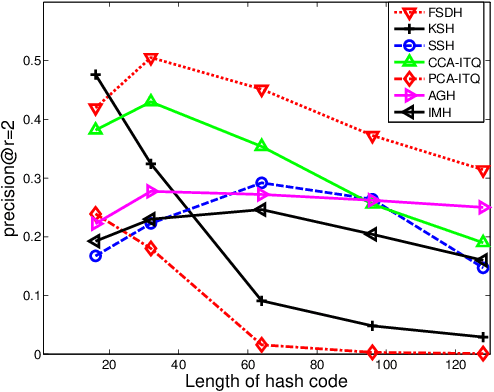
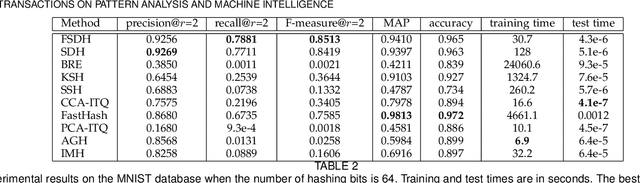
Learning-based hashing algorithms are ``hot topics" because they can greatly increase the scale at which existing methods operate. In this paper, we propose a new learning-based hashing method called ``fast supervised discrete hashing" (FSDH) based on ``supervised discrete hashing" (SDH). Regressing the training examples (or hash code) to the corresponding class labels is widely used in ordinary least squares regression. Rather than adopting this method, FSDH uses a very simple yet effective regression of the class labels of training examples to the corresponding hash code to accelerate the algorithm. To the best of our knowledge, this strategy has not previously been used for hashing. Traditional SDH decomposes the optimization into three sub-problems, with the most critical sub-problem - discrete optimization for binary hash codes - solved using iterative discrete cyclic coordinate descent (DCC), which is time-consuming. However, FSDH has a closed-form solution and only requires a single rather than iterative hash code-solving step, which is highly efficient. Furthermore, FSDH is usually faster than SDH for solving the projection matrix for least squares regression, making FSDH generally faster than SDH. For example, our results show that FSDH is about 12-times faster than SDH when the number of hashing bits is 128 on the CIFAR-10 data base, and FSDH is about 151-times faster than FastHash when the number of hashing bits is 64 on the MNIST data-base. Our experimental results show that FSDH is not only fast, but also outperforms other comparative methods.