 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Learning and Intervention in Games
Oct 26, 2020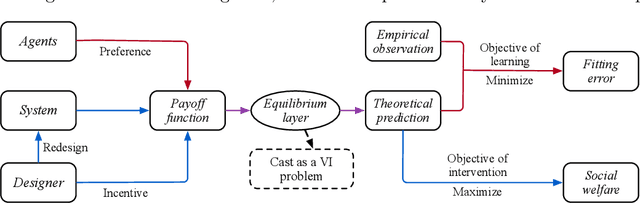
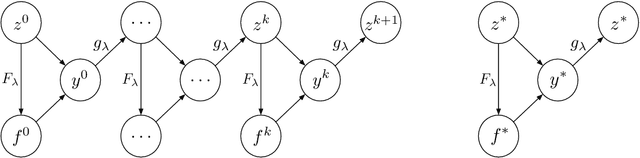
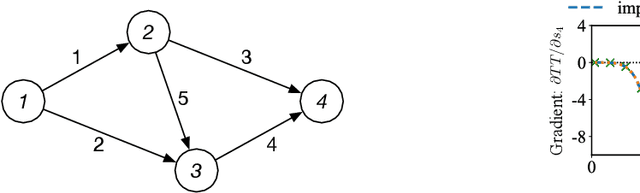
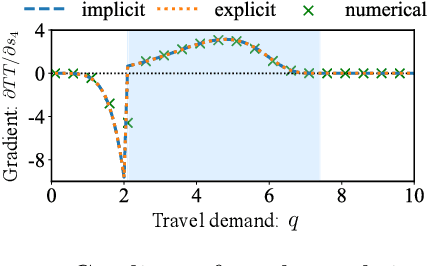
In a social system, the self-interest of agents can be detrimental to the collective good, sometimes leading to social dilemmas. To resolve such a conflict, a central designer may intervene by either redesigning the system or incentivizing the agents to change their behaviors. To be effective, the designer must anticipate how the agents react to the intervention, which is dictated by their often unknown payoff functions. Therefore, learning about the agents is a prerequisite for intervention. In this paper, we provide a unified framework for learning and intervention in games. We cast the equilibria of games as individual layers and integrate them into an end-to-end optimization framework. To enable the backward propagation through the equilibria of games, we propose two approaches, respectively based on explicit and implicit differentiation. Specifically, we cast the equilibria as the solutions to variational inequalities (VIs). The explicit approach unrolls the projection method for solving VIs, while the implicit approach exploits the sensitivity of the solutions to VIs. At the core of both approaches is the differentiation through a projection operator. Moreover, we establish the correctness of both approaches and identify the conditions under which one approach is more desirable than the other. The analytical results are validated using several real-world problems.
Variational Dynamic for Self-Supervised Exploration in Deep Reinforcement Learning
Oct 17, 2020
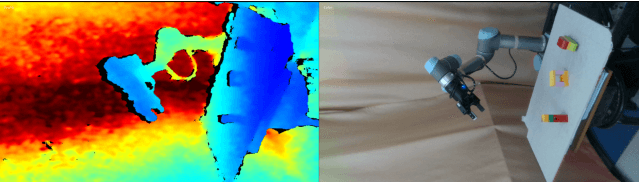
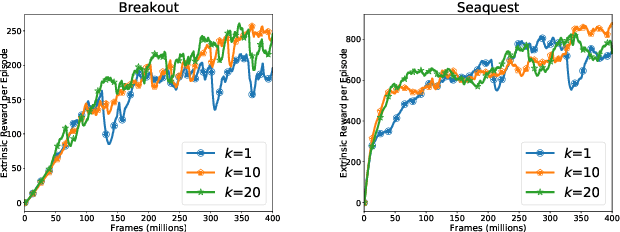
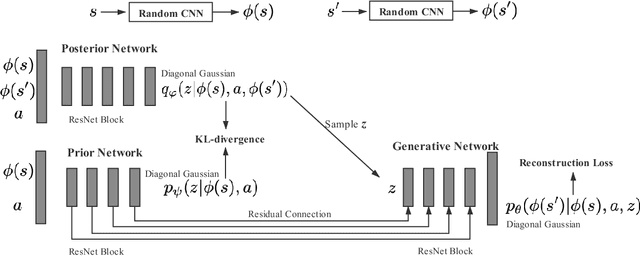
Efficient exploration remains a challenging problem in reinforcement learning, especially for tasks where extrinsic rewards from environments are sparse or even totally disregarded. Significant advances based on intrinsic motivation show promising results in simple environments but often get stuck in environments with multimodal and stochastic dynamics. In this work, we propose a variational dynamic model based on the conditional variational inference to model the multimodality and stochasticity. We consider the environmental state-action transition as a conditional generative process by generating the next-state prediction under the condition of the current state, action, and latent variable. We derive an upper bound of the negative log-likelihood of the environmental transition and use such an upper bound as the intrinsic reward for exploration, which allows the agent to learn skills by self-supervised exploration without observing extrinsic rewards. We evaluate the proposed method on several image-based simulation tasks and a real robotic manipulating task. Our method outperforms several state-of-the-art environment model-based exploration approaches.
Provable Fictitious Play for General Mean-Field Games
Oct 08, 2020We propose a reinforcement learning algorithm for stationary mean-field games, where the goal is to learn a pair of mean-field state and stationary policy that constitutes the Nash equilibrium. When viewing the mean-field state and the policy as two players, we propose a fictitious play algorithm which alternatively updates the mean-field state and the policy via gradient-descent and proximal policy optimization, respectively. Our algorithm is in stark contrast with previous literature which solves each single-agent reinforcement learning problem induced by the iterates mean-field states to the optimum. Furthermore, we prove that our fictitious play algorithm converges to the Nash equilibrium at a sublinear rate. To the best of our knowledge, this seems the first provably convergent single-loop reinforcement learning algorithm for mean-field games based on iterative updates of both mean-field state and policy.
Nearly Dimension-Independent Sparse Linear Bandit over Small Action Spaces via Best Subset Selection
Sep 04, 2020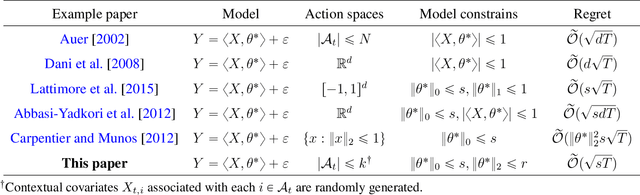
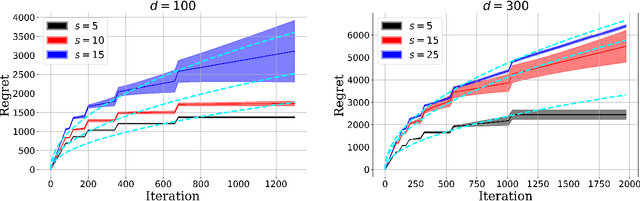
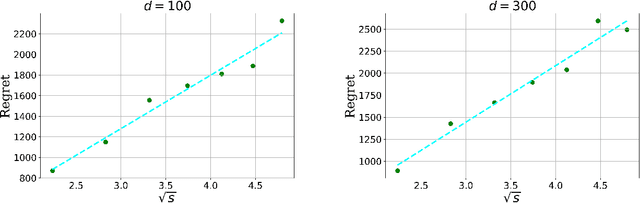
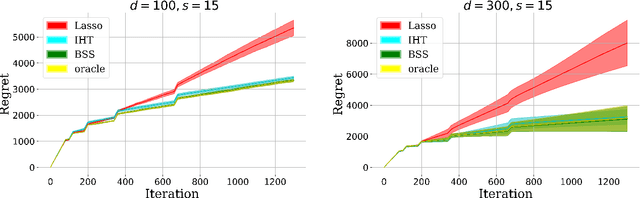
We consider the stochastic contextual bandit problem under the high dimensional linear model. We focus on the case where the action space is finite and random, with each action associated with a randomly generated contextual covariate. This setting finds essential applications such as personalized recommendation, online advertisement, and personalized medicine. However, it is very challenging as we need to balance exploration and exploitation. We propose doubly growing epochs and estimating the parameter using the best subset selection method, which is easy to implement in practice. This approach achieves $ \tilde{\mathcal{O}}(s\sqrt{T})$ regret with high probability, which is nearly independent in the ``ambient'' regression model dimension $d$. We further attain a sharper $\tilde{\mathcal{O}}(\sqrt{sT})$ regret by using the \textsc{SupLinUCB} framework and match the minimax lower bound of low-dimensional linear stochastic bandit problems. Finally, we conduct extensive numerical experiments to demonstrate the applicability and robustness of our algorithms empirically.
Single-Timescale Stochastic Nonconvex-Concave Optimization for Smooth Nonlinear TD Learning
Aug 23, 2020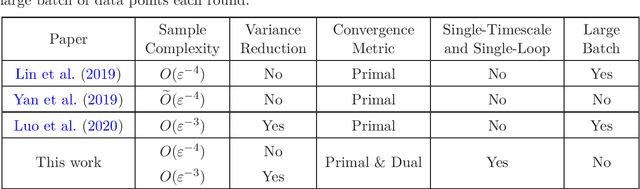
Temporal-Difference (TD) learning with nonlinear smooth function approximation for policy evaluation has achieved great success in modern reinforcement learning. It is shown that such a problem can be reformulated as a stochastic nonconvex-strongly-concave optimization problem, which is challenging as naive stochastic gradient descent-ascent algorithm suffers from slow convergence. Existing approaches for this problem are based on two-timescale or double-loop stochastic gradient algorithms, which may also require sampling large-batch data. However, in practice, a single-timescale single-loop stochastic algorithm is preferred due to its simplicity and also because its step-size is easier to tune. In this paper, we propose two single-timescale single-loop algorithms which require only one data point each step. Our first algorithm implements momentum updates on both primal and dual variables achieving an $O(\varepsilon^{-4})$ sample complexity, which shows the important role of momentum in obtaining a single-timescale algorithm. Our second algorithm improves upon the first one by applying variance reduction on top of momentum, which matches the best known $O(\varepsilon^{-3})$ sample complexity in existing works. Furthermore, our variance-reduction algorithm does not require a large-batch checkpoint. Moreover, our theoretical results for both algorithms are expressed in a tighter form of simultaneous primal and dual side convergence.
Global Convergence of Policy Gradient for Linear-Quadratic Mean-Field Control/Game in Continuous Time
Aug 16, 2020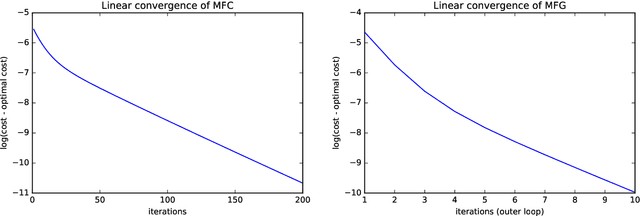
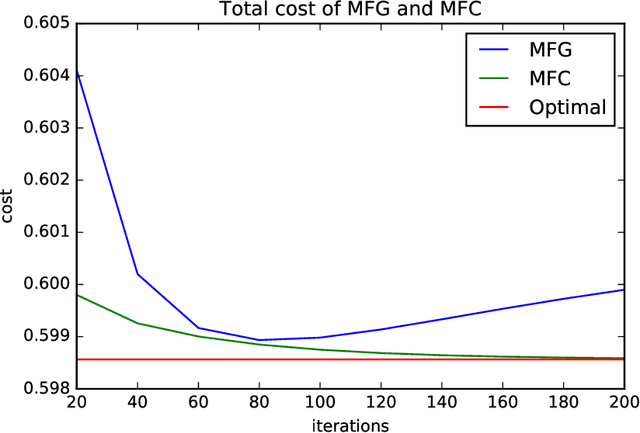
Reinforcement learning is a powerful tool to learn the optimal policy of possibly multiple agents by interacting with the environment. As the number of agents grow to be very large, the system can be approximated by a mean-field problem. Therefore, it has motivated new research directions for mean-field control (MFC) and mean-field game (MFG). In this paper, we study the policy gradient method for the linear-quadratic mean-field control and game, where we assume each agent has identical linear state transitions and quadratic cost functions. While most of the recent works on policy gradient for MFC and MFG are based on discrete-time models, we focus on the continuous-time models where some analyzing techniques can be interesting to the readers. For both MFC and MFG, we provide policy gradient update and show that it converges to the optimal solution at a linear rate, which is verified by a synthetic simulation. For MFG, we also provide sufficient conditions for the existence and uniqueness of the Nash equilibrium.
Single-Timescale Actor-Critic Provably Finds Globally Optimal Policy
Aug 02, 2020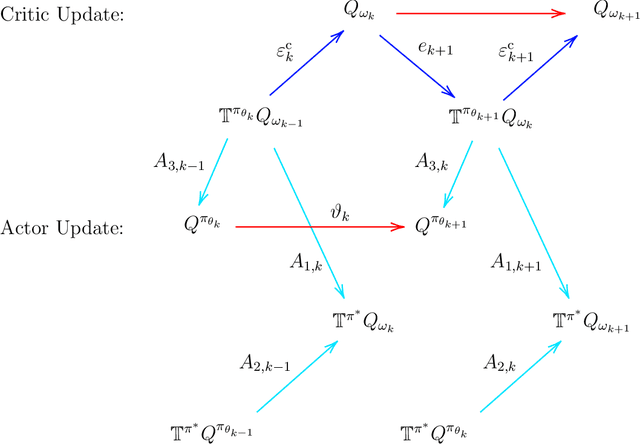
We study the global convergence and global optimality of actor-critic, one of the most popular families of reinforcement learning algorithms. While most existing works on actor-critic employ bi-level or two-timescale updates, we focus on the more practical single-timescale setting, where the actor and critic are updated simultaneously. Specifically, in each iteration, the critic update is obtained by applying the Bellman evaluation operator only once while the actor is updated in the policy gradient direction computed using the critic. Moreover, we consider two function approximation settings where both the actor and critic are represented by linear or deep neural networks. For both cases, we prove that the actor sequence converges to a globally optimal policy at a sublinear $O(K^{-1/2})$ rate, where $K$ is the number of iterations. To the best of our knowledge, we establish the rate of convergence and global optimality of single-timescale actor-critic with linear function approximation for the first time. Moreover, under the broader scope of policy optimization with nonlinear function approximation, we prove that actor-critic with deep neural network finds the globally optimal policy at a sublinear rate for the first time.
A Two-Timescale Framework for Bilevel Optimization: Complexity Analysis and Application to Actor-Critic
Jul 10, 2020
This paper analyzes a two-timescale stochastic algorithm for a class of bilevel optimization problems with applications such as policy optimization in reinforcement learning, hyperparameter optimization, among others. We consider a case when the inner problem is unconstrained and strongly convex, and the outer problem is either strongly convex, convex or weakly convex. We propose a nonlinear two-timescale stochastic approximation (TTSA) algorithm for tackling the bilevel optimization. In the algorithm, a stochastic (semi)gradient update with a larger step size (faster timescale) is used for the inner problem, while a stochastic mirror descent update with a smaller step size (slower timescale) is used for the outer problem. When the outer problem is strongly convex (resp. weakly convex), the TTSA algorithm finds an $\mathcal{O}(K^{-1/2})$-optimal (resp. $\mathcal{O}(K^{-2/5})$-stationary) solution, where $K$ is the iteration number. To our best knowledge, these are the first convergence rate results for using nonlinear TTSA algorithms on the concerned class of bilevel optimization problems. Lastly, specific to the application of policy optimization, we show that a two-timescale actor-critic proximal policy optimization algorithm can be viewed as a special case of our framework. The actor-critic algorithm converges at $\mathcal{O}(K^{-1/4})$ in terms of the gap in objective value to a globally optimal policy.
Accelerating Nonconvex Learning via Replica Exchange Langevin Diffusion
Jul 04, 2020
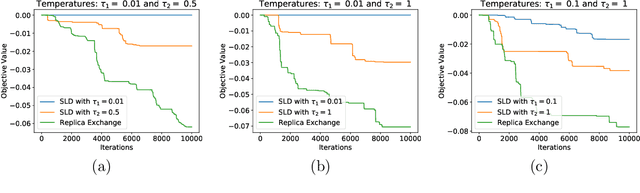
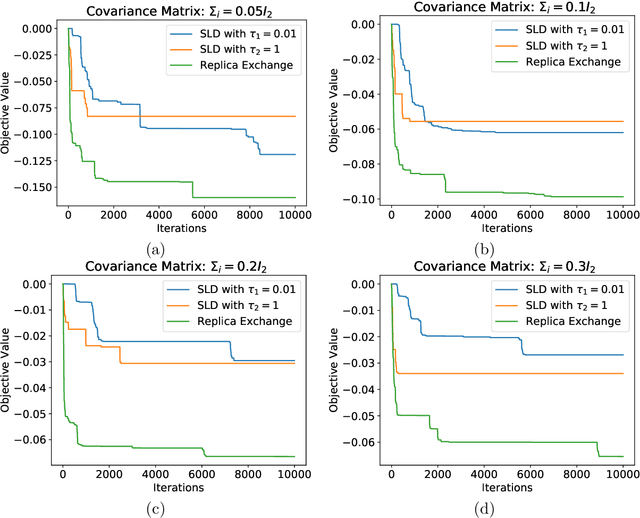
Langevin diffusion is a powerful method for nonconvex optimization, which enables the escape from local minima by injecting noise into the gradient. In particular, the temperature parameter controlling the noise level gives rise to a tradeoff between ``global exploration'' and ``local exploitation'', which correspond to high and low temperatures. To attain the advantages of both regimes, we propose to use replica exchange, which swaps between two Langevin diffusions with different temperatures. We theoretically analyze the acceleration effect of replica exchange from two perspectives: (i) the convergence in \chi^2-divergence, and (ii) the large deviation principle. Such an acceleration effect allows us to faster approach the global minima. Furthermore, by discretizing the replica exchange Langevin diffusion, we obtain a discrete-time algorithm. For such an algorithm, we quantify its discretization error in theory and demonstrate its acceleration effect in practice.
Provably Efficient Neural Estimation of Structural Equation Model: An Adversarial Approach
Jul 02, 2020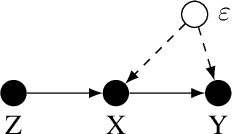
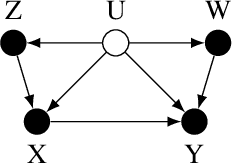
Structural equation models (SEMs) are widely used in sciences, ranging from economics to psychology, to uncover causal relationships underlying a complex system under consideration and estimate structural parameters of interest. We study estimation in a class of generalized SEMs where the object of interest is defined as the solution to a linear operator equation. We formulate the linear operator equation as a min-max game, where both players are parameterized by neural networks (NNs), and learn the parameters of these neural networks using the stochastic gradient descent. We consider both 2-layer and multi-layer NNs with ReLU activation functions and prove global convergence in an overparametrized regime, where the number of neurons is diverging. The results are established using techniques from online learning and local linearization of NNs, and improve in several aspects the current state-of-the-art. For the first time we provide a tractable estimation procedure for SEMs based on NNs with provable convergence and without the need for sample splitting.