 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhanghui Kuang
RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition
Jul 15, 2020
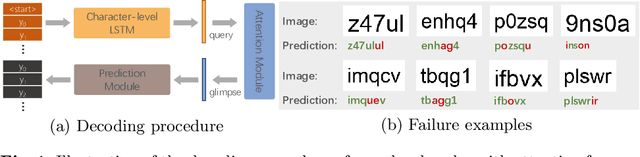
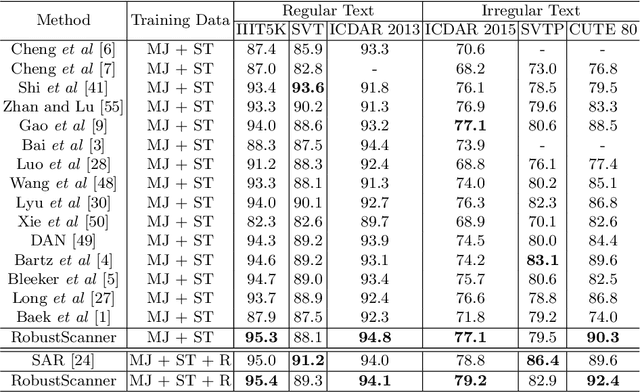
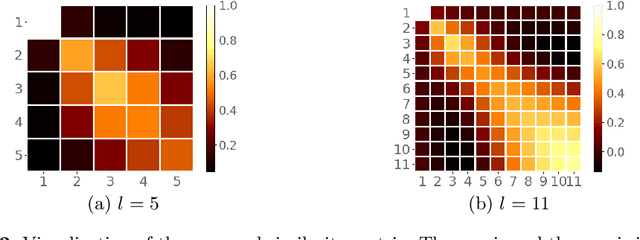

The attention-based encoder-decoder framework has recently achieved impressive results for scene text recognition, and many variants have emerged with improvements in recognition quality. However, it performs poorly on contextless texts (e.g., random character sequences) which is unacceptable in most of real application scenarios. In this paper, we first deeply investigate the decoding process of the decoder. We empirically find that a representative character-level sequence decoder utilizes not only context information but also positional information. The existing approaches heavily relying on contextual information causes the problem of attention drift. To suppress the side-effect of the attention drift, we propose one novel position enhancement branch, and dynamically fuse its outputs with those of the decoder attention module for scene text recognition. Specifically, it contains a position aware module to make the encoder output feature vectors encoding their own spatial positions, and an attention module to estimate glimpses using the positional clue (i.e., the current decoding time step) only. The dynamic fusion is conducted for more robust feature via an element-wise gate mechanism. Theoretically, our proposed method, dubbed RobustScanner, decodes individual characters with dynamic ratio between context and positional clues, and utilizes more positional ones when the decoding sequences with scarce context, and thus is robust and practical. Empirically, it has achieved new state-of-the-art results on popular regular and irregular text recognition benchmarks while without much performance drop on contextless benchmarks, validating its robustness in both context and contextless application scenarios.
Geometry Normalization Networks for Accurate Scene Text Detection
Sep 02, 2019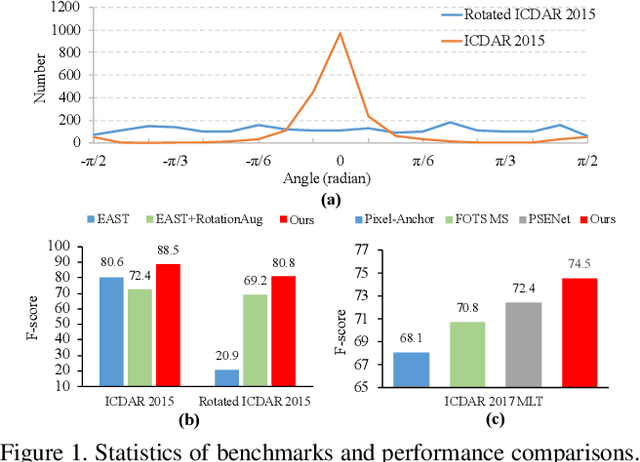
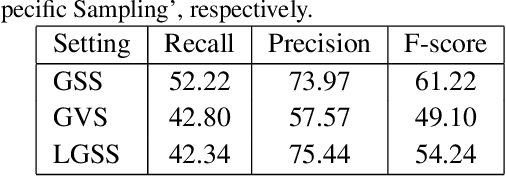
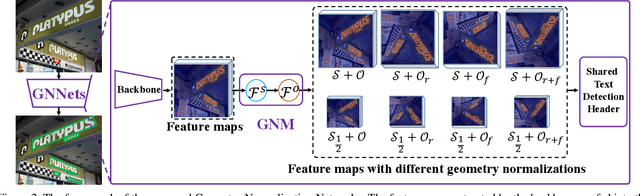
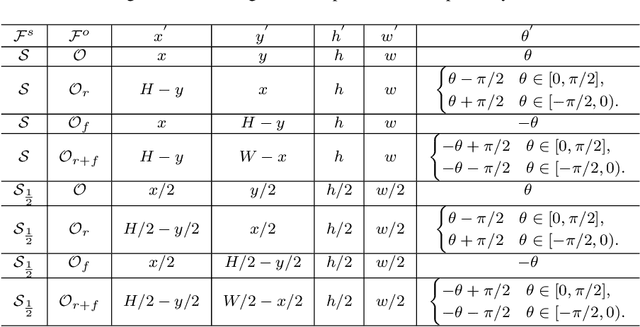
Large geometry (e.g., orientation) variances are the key challenges in the scene text detection. In this work, we first conduct experiments to investigate the capacity of networks for learning geometry variances on detecting scene texts, and find that networks can handle only limited text geometry variances. Then, we put forward a novel Geometry Normalization Module (GNM) with multiple branches, each of which is composed of one Scale Normalization Unit and one Orientation Normalization Unit, to normalize each text instance to one desired canonical geometry range through at least one branch. The GNM is general and readily plugged into existing convolutional neural network based text detectors to construct end-to-end Geometry Normalization Networks (GNNets). Moreover, we propose a geometry-aware training scheme to effectively train the GNNets by sampling and augmenting text instances from a uniform geometry variance distribution. Finally, experiments on popular benchmarks of ICDAR 2015 and ICDAR 2017 MLT validate that our method outperforms all the state-of-the-art approaches remarkably by obtaining one-forward test F-scores of 88.52 and 74.54 respectively.
Fashion Retrieval via Graph Reasoning Networks on a Similarity Pyramid
Aug 30, 2019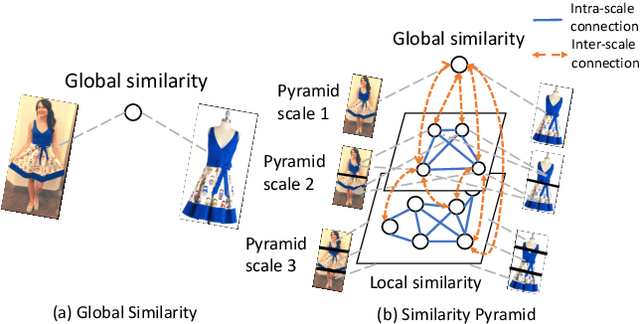
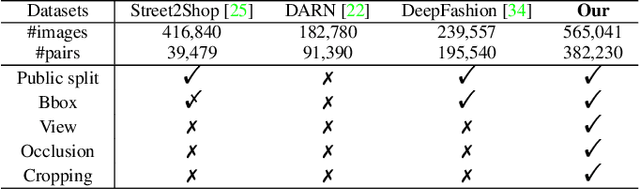
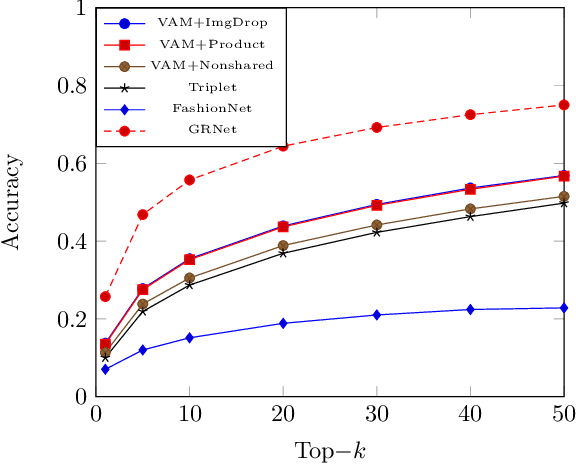
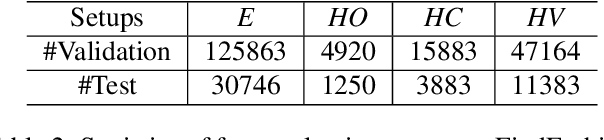
Matching clothing images from customers and online shopping stores has rich applications in E-commerce. Existing algorithms encoded an image as a global feature vector and performed retrieval with the global representation. However, discriminative local information on clothes are submerged in this global representation, resulting in sub-optimal performance. To address this issue, we propose a novel Graph Reasoning Network (GRNet) on a Similarity Pyramid, which learns similarities between a query and a gallery cloth by using both global and local representations in multiple scales. The similarity pyramid is represented by a Graph of similarity, where nodes represent similarities between clothing components at different scales, and the final matching score is obtained by message passing along edges. In GRNet, graph reasoning is solved by training a graph convolutional network, enabling to align salient clothing components to improve clothing retrieval. To facilitate future researches, we introduce a new benchmark FindFashion, containing rich annotations of bounding boxes, views, occlusions, and cropping. Extensive experiments show that GRNet obtains new state-of-the-art results on two challenging benchmarks, e.g., pushing the top-1, top-20, and top-50 accuracies on DeepFashion to 26%, 64%, and 75% (i.e., 4%, 10%, and 10% absolute improvements), outperforming competitors with large margins. On FindFashion, GRNet achieves considerable improvements on all empirical settings.
Data-Driven Neuron Allocation for Scale Aggregation Networks
Apr 20, 2019
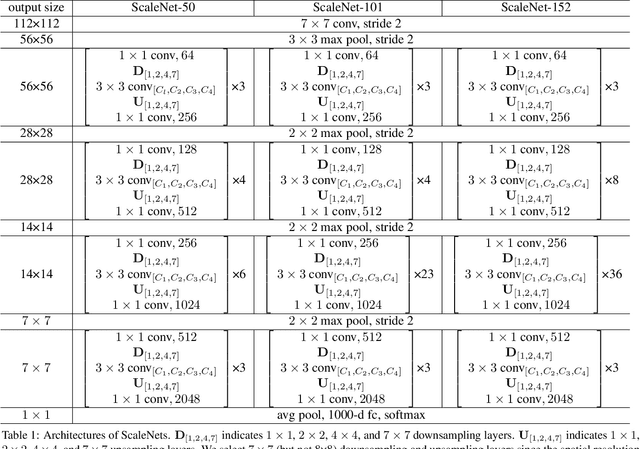
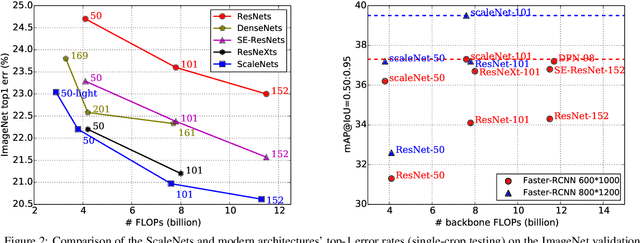
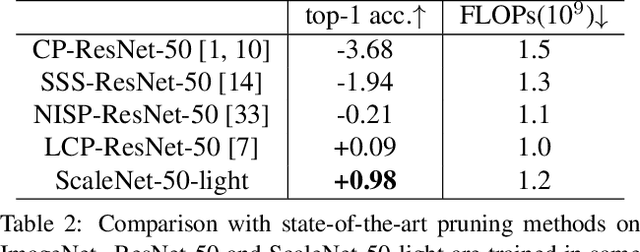
Successful visual recognition networks benefit from aggregating information spanning from a wide range of scales. Previous research has investigated information fusion of connected layers or multiple branches in a block, seeking to strengthen the power of multi-scale representations. Despite their great successes, existing practices often allocate the neurons for each scale manually, and keep the same ratio in all aggregation blocks of an entire network, rendering suboptimal performance. In this paper, we propose to learn the neuron allocation for aggregating multi-scale information in different building blocks of a deep network. The most informative output neurons in each block are preserved while others are discarded, and thus neurons for multiple scales are competitively and adaptively allocated. Our scale aggregation network (ScaleNet) is constructed by repeating a scale aggregation (SA) block that concatenates feature maps at a wide range of scales. Feature maps for each scale are generated by a stack of downsampling, convolution and upsampling operations. The data-driven neuron allocation and SA block achieve strong representational power at the cost of considerably low computational complexity. The proposed ScaleNet, by replacing all 3x3 convolutions in ResNet with our SA blocks, achieves better performance than ResNet and its outstanding variants like ResNeXt and SE-ResNet, in the same computational complexity. On ImageNet classification, ScaleNets absolutely reduce the top-1 error rate of ResNets by 1.12 (101 layers) and 1.82 (50 layers). On COCO object detection, ScaleNets absolutely improve the mmAP with backbone of ResNets by 3.6 (101 layers) and 4.6 (50 layers) on Faster RCNN, respectively. Code and models are released at https://github.com/Eli-YiLi/ScaleNet.
* 11 pages,
Learning Efficient Detector with Semi-supervised Adaptive Distillation
Jan 14, 2019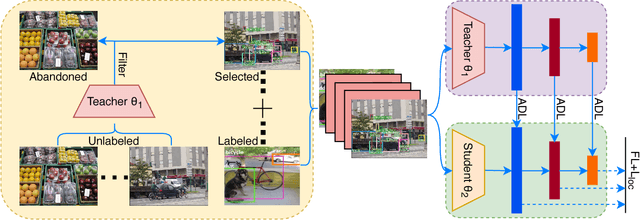
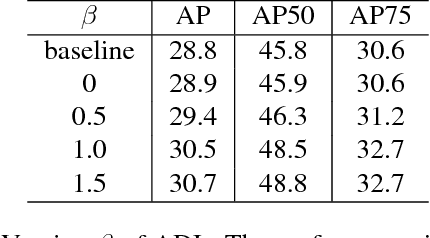
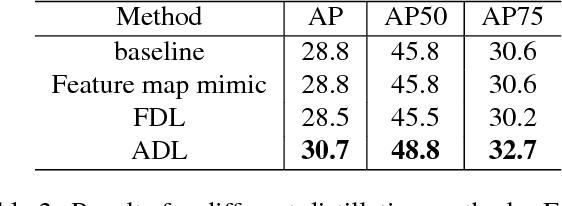
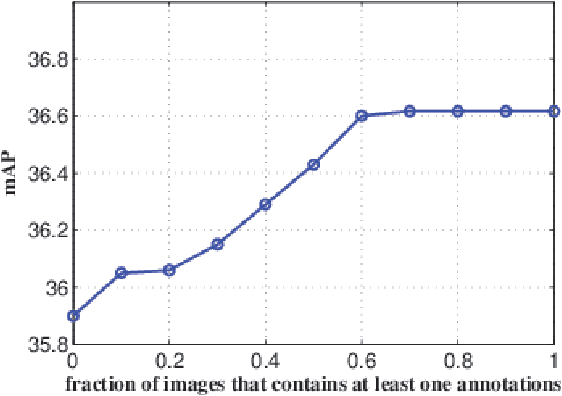
Knowledge Distillation (KD) has been used in image classification for model compression. However, rare studies apply this technology on single-stage object detectors. Focal loss shows that the accumulated errors of easily-classified samples dominate the overall loss in the training process. This problem is also encountered when applying KD in the detection task. For KD, the teacher-defined hard samples are far more important than any others. We propose ADL to address this issue by adaptively mimicking the teacher's logits, with more attention paid on two types of hard samples: hard-to-learn samples predicted by teacher with low certainty and hard-to-mimic samples with a large gap between the teacher's and the student's prediction. ADL enlarges the distillation loss for hard-to-learn and hard-to-mimic samples and reduces distillation loss for the dominant easy samples, enabling distillation to work on the single-stage detector first time, even if the student and the teacher are identical. Besides, ADL is effective in both the supervised setting and the semi-supervised setting, even when the labeled data and unlabeled data are from different distributions. For distillation on unlabeled data, ADL achieves better performance than existing data distillation which simply utilizes hard targets, making the student detector surpass its teacher. On the COCO database, semi-supervised adaptive distillation (SAD) makes a student detector with a backbone of ResNet-50 surpasses its teacher with a backbone of ResNet-101, while the student has half of the teacher's computation complexity. The code is avaiable at https://github.com/Tangshitao/Semi-supervised-Adaptive-Distillation
Temporal Sequence Distillation: Towards Few-Frame Action Recognition in Videos
Aug 15, 2018
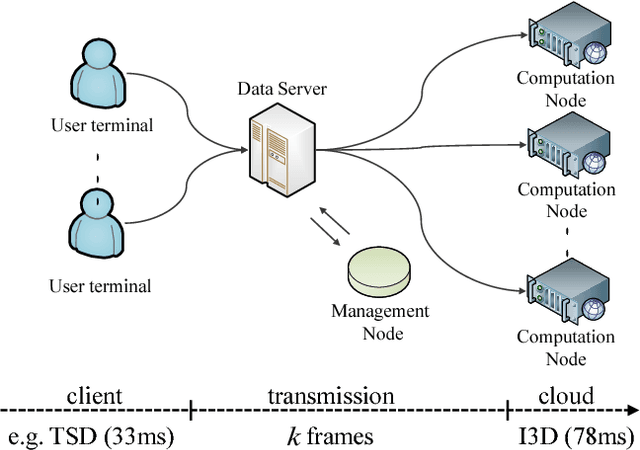

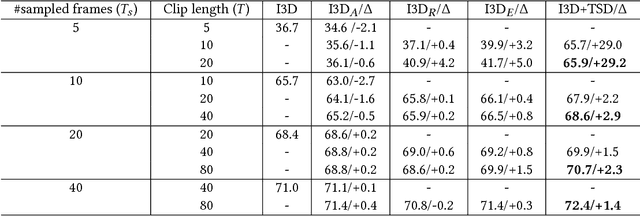
Video Analytics Software as a Service (VA SaaS) has been rapidly growing in recent years. VA SaaS is typically accessed by users using a lightweight client. Because the transmission bandwidth between the client and cloud is usually limited and expensive, it brings great benefits to design cloud video analysis algorithms with a limited data transmission requirement. Although considerable research has been devoted to video analysis, to our best knowledge, little of them has paid attention to the transmission bandwidth limitation in SaaS. As the first attempt in this direction, this work introduces a problem of few-frame action recognition, which aims at maintaining high recognition accuracy, when accessing only a few frames during both training and test. Unlike previous work that processed dense frames, we present Temporal Sequence Distillation (TSD), which distills a long video sequence into a very short one for transmission. By end-to-end training with 3D CNNs for video action recognition, TSD learns a compact and discriminative temporal and spatial representation of video frames. On Kinetics dataset, TSD+I3D typically requires only 50\% of the number of frames compared to I3D, a state-of-the-art video action recognition algorithm, to achieve almost the same accuracies. The proposed TSD has three appealing advantages. Firstly, TSD has a lightweight architecture and can be deployed in the client, eg. mobile devices, to produce compressed representative frames to save transmission bandwidth. Secondly, TSD significantly reduces the computations to run video action recognition with compressed frames on the cloud, while maintaining high recognition accuracies. Thirdly, TSD can be plugged in as a preprocessing module of any existing 3D CNNs. Extensive experiments show the effectiveness and characteristics of TSD.
Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition
Jul 07, 2018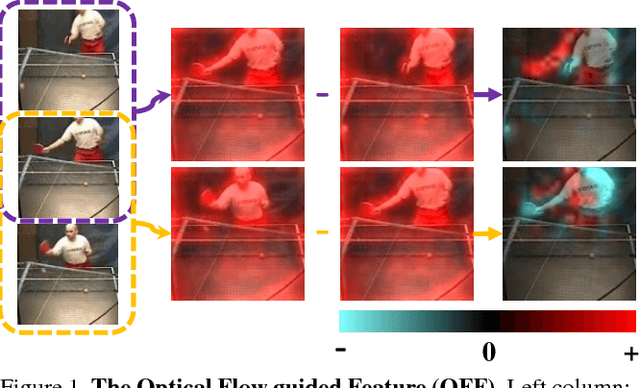
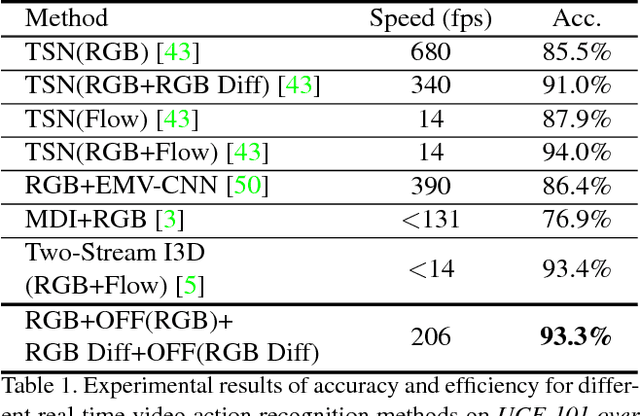
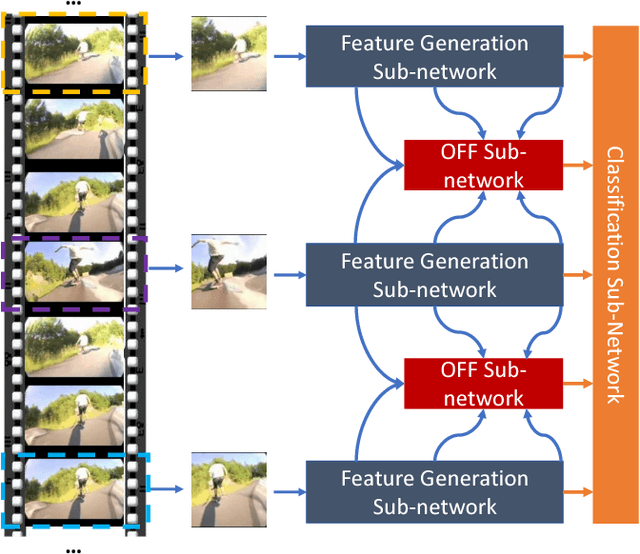
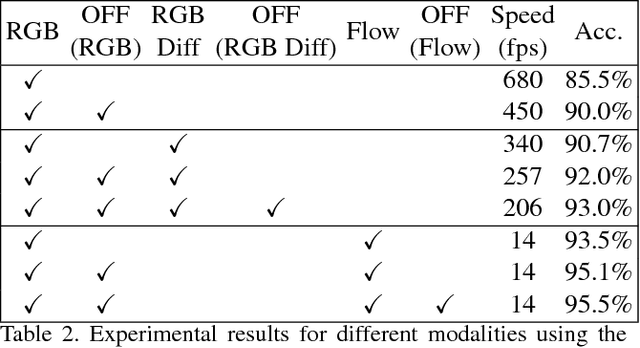
Motion representation plays a vital role in human action recognition in videos. In this study, we introduce a novel compact motion representation for video action recognition, named Optical Flow guided Feature (OFF), which enables the network to distill temporal information through a fast and robust approach. The OFF is derived from the definition of optical flow and is orthogonal to the optical flow. The derivation also provides theoretical support for using the difference between two frames. By directly calculating pixel-wise spatiotemporal gradients of the deep feature maps, the OFF could be embedded in any existing CNN based video action recognition framework with only a slight additional cost. It enables the CNN to extract spatiotemporal information, especially the temporal information between frames simultaneously. This simple but powerful idea is validated by experimental results. The network with OFF fed only by RGB inputs achieves a competitive accuracy of 93.3% on UCF-101, which is comparable with the result obtained by two streams (RGB and optical flow), but is 15 times faster in speed. Experimental results also show that OFF is complementary to other motion modalities such as optical flow. When the proposed method is plugged into the state-of-the-art video action recognition framework, it has 96:0% and 74:2% accuracy on UCF-101 and HMDB-51 respectively. The code for this project is available at https://github.com/kevin-ssy/Optical-Flow-Guided-Feature.
Boosting up Scene Text Detectors with Guided CNN
May 14, 2018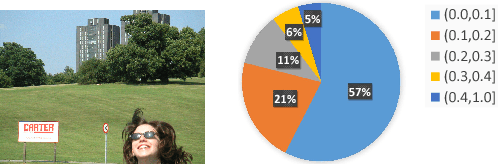
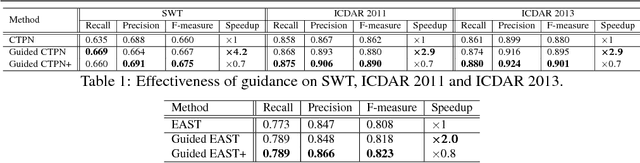
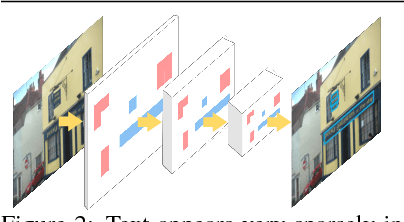
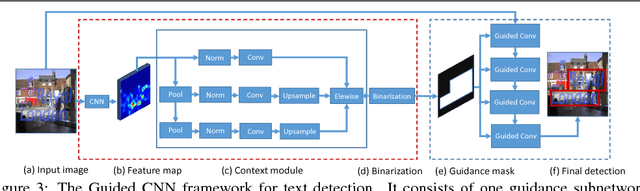
Deep CNNs have achieved great success in text detection. Most of existing methods attempt to improve accuracy with sophisticated network design, while paying less attention on speed. In this paper, we propose a general framework for text detection called Guided CNN to achieve the two goals simultaneously. The proposed model consists of one guidance subnetwork, where a guidance mask is learned from the input image itself, and one primary text detector, where every convolution and non-linear operation are conducted only in the guidance mask. On the one hand, the guidance subnetwork filters out non-text regions coarsely, greatly reduces the computation complexity. On the other hand, the primary text detector focuses on distinguishing between text and hard non-text regions and regressing text bounding boxes, achieves a better detection accuracy. A training strategy, called background-aware block-wise random synthesis, is proposed to further boost up the performance. We demonstrate that the proposed Guided CNN is not only effective but also efficient with two state-of-the-art methods, CTPN and EAST, as backbones. On the challenging benchmark ICDAR 2013, it speeds up CTPN by 2.9 times on average, while improving the F-measure by 1.5%. On ICDAR 2015, it speeds up EAST by 2.0 times while improving the F-measure by 1.0%.