 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdleSpec: Exploiting Idle Time via Speculative Planning for LLM Agents
May 21, 2026Large language model (LLM)-based agents solve complex tasks by leveraging multi-step reasoning with iterative tool calls and environment interactions, which incur idle time while waiting for observations. Despite the prevalence of idle time in most agentic scenarios, existing works treat it as an unavoidable overhead or propose restricted solutions that overlook varying computational budgets across different tool calls and future observation uncertainty, thereby leading to suboptimal utilization of idle time. In this paper, we introduce IdleSpec, a scalable and generic inference approach that leverages idle-time computation to improve agent performance while minimizing latency overhead. Specifically, IdleSpec iteratively generates plan candidates during idle periods and, once observations become available, aggregates them to guide the next reasoning step. For effective plan generation under observation uncertainty, IdleSpec samples between complementary drafting strategies (i.e., progressive and recovery) from a learned distribution that is updated via posterior feedback. Our experiments demonstrate that IdleSpec significantly improves agent performance in various agentic scenarios by effectively utilizing idle time. In particular, on the GAIA and FRAMES, IdleSpec achieves 55.6% average accuracy with Gemini-2.5-Flash, surpassing the vanilla baseline without idle-time usage by 5.1%. Furthermore, for MLE-Bench, which involves substantial delay from code executions, IdleSpec achieves performance gains of up to 9.1% on the Any Medal rate, highlighting its generalizability to long-horizon tasks.
ExComm: Exploration-Stage Communication for Error-Resilient Agentic Test-Time Scaling
May 21, 2026A common failure mode in long-horizon agentic test-time scaling is error propagation, where factual errors or invalid deductions introduced at intermediate steps persist in the agent's belief state and contaminate later reasoning. Existing test-time scaling methods provide limited control over this process, as they often rely on agents to detect their own mistakes, select among flawed trajectories, or refine solutions only after errors have already shaped the reasoning path. We propose ExComm, a communication protocol for exploration-stage agentic test-time scaling. ExComm is motivated by the empirical observation that the majority of intermediate errors in parallel agentic reasoning produce detectable cross-agent factual conflicts. Leveraging the iterative structure of agentic workflows, ExComm periodically audits agent belief states to detect such conflicts, resolves them through a dedicated tool-based verification loop, and returns concise, targeted feedback to the involved agents. Corrections are incorporated through soft belief updates, which append verified feedback rather than overwriting existing beliefs. Furthermore, to prevent collapsing trajectory diversity due to communication, ExComm further introduces a trajectory diversification module that redirects redundant trajectories toward orthogonal strategies. Experiments on AIME 2024, AIME 2025, and GAIA with Gemini-2.5-Flash-Lite and Qwen3.5-4B show that ExComm consistently outperforms strong test-time scaling baselines, achieving average performance gains of 5.7% and 5.0% over the best-performing baselines, respectively. Further analyses demonstrate improved error recovery, favorable scaling behavior, stronger diversity than adapted communication baselines, and the best performance-cost trade-off among the evaluated methods.
Accelerated Test-Time Scaling with Model-Free Speculative Sampling
Jun 05, 2025Language models have demonstrated remarkable capabilities in reasoning tasks through test-time scaling techniques like best-of-N sampling and tree search. However, these approaches often demand substantial computational resources, creating a critical trade-off between performance and efficiency. We introduce STAND (STochastic Adaptive N-gram Drafting), a novel model-free speculative decoding approach that leverages the inherent redundancy in reasoning trajectories to achieve significant acceleration without compromising accuracy. Our analysis reveals that reasoning paths frequently reuse similar reasoning patterns, enabling efficient model-free token prediction without requiring separate draft models. By introducing stochastic drafting and preserving probabilistic information through a memory-efficient logit-based N-gram module, combined with optimized Gumbel-Top-K sampling and data-driven tree construction, STAND significantly improves token acceptance rates. Extensive evaluations across multiple models and reasoning tasks (AIME-2024, GPQA-Diamond, and LiveCodeBench) demonstrate that STAND reduces inference latency by 60-65% compared to standard autoregressive decoding while maintaining accuracy. Furthermore, STAND outperforms state-of-the-art speculative decoding methods by 14-28% in throughput and shows strong performance even in single-trajectory scenarios, reducing inference latency by 48-58%. As a model-free approach, STAND can be applied to any existing language model without additional training, being a powerful plug-and-play solution for accelerating language model reasoning.
SpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
May 14, 2024



Integrated Speech and Large Language Models (SLMs) that can follow speech instructions and generate relevant text responses have gained popularity lately. However, the safety and robustness of these models remains largely unclear. In this work, we investigate the potential vulnerabilities of such instruction-following speech-language models to adversarial attacks and jailbreaking. Specifically, we design algorithms that can generate adversarial examples to jailbreak SLMs in both white-box and black-box attack settings without human involvement. Additionally, we propose countermeasures to thwart such jailbreaking attacks. Our models, trained on dialog data with speech instructions, achieve state-of-the-art performance on spoken question-answering task, scoring over 80% on both safety and helpfulness metrics. Despite safety guardrails, experiments on jailbreaking demonstrate the vulnerability of SLMs to adversarial perturbations and transfer attacks, with average attack success rates of 90% and 10% respectively when evaluated on a dataset of carefully designed harmful questions spanning 12 different toxic categories. However, we demonstrate that our proposed countermeasures reduce the attack success significantly.
Retrieve and Copy: Scaling ASR Personalization to Large Catalogs
Nov 14, 2023



Personalization of automatic speech recognition (ASR) models is a widely studied topic because of its many practical applications. Most recently, attention-based contextual biasing techniques are used to improve the recognition of rare words and domain specific entities. However, due to performance constraints, the biasing is often limited to a few thousand entities, restricting real-world usability. To address this, we first propose a "Retrieve and Copy" mechanism to improve latency while retaining the accuracy even when scaled to a large catalog. We also propose a training strategy to overcome the degradation in recall at such scale due to an increased number of confusing entities. Overall, our approach achieves up to 6% more Word Error Rate reduction (WERR) and 3.6% absolute improvement in F1 when compared to a strong baseline. Our method also allows for large catalog sizes of up to 20K without significantly affecting WER and F1-scores, while achieving at least 20% inference speedup per acoustic frame.
Evaluating Pretrained Transformer Models for Entity Linking in Task-Oriented Dialog
Dec 15, 2021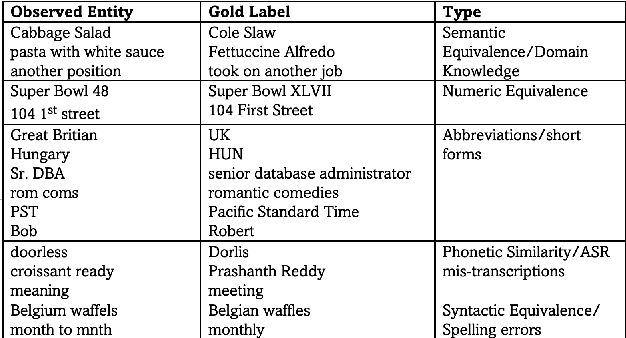
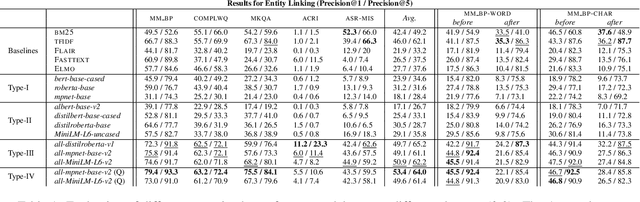
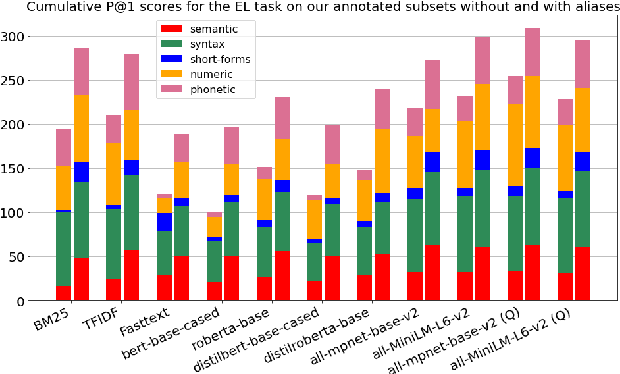
The wide applicability of pretrained transformer models (PTMs) for natural language tasks is well demonstrated, but their ability to comprehend short phrases of text is less explored. To this end, we evaluate different PTMs from the lens of unsupervised Entity Linking in task-oriented dialog across 5 characteristics -- syntactic, semantic, short-forms, numeric and phonetic. Our results demonstrate that several of the PTMs produce sub-par results when compared to traditional techniques, albeit competitive to other neural baselines. We find that some of their shortcomings can be addressed by using PTMs fine-tuned for text-similarity tasks, which illustrate an improved ability in comprehending semantic and syntactic correspondences, as well as some improvements for short-forms, numeric and phonetic variations in entity mentions. We perform qualitative analysis to understand nuances in their predictions and discuss scope for further improvements. Code can be found at https://github.com/murali1996/el_tod
CodemixedNLP: An Extensible and Open NLP Toolkit for Code-Mixing
Jun 10, 2021
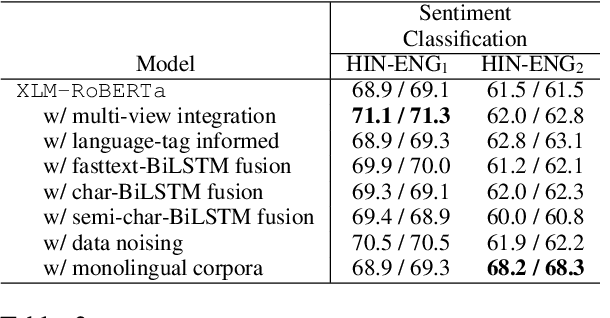

The NLP community has witnessed steep progress in a variety of tasks across the realms of monolingual and multilingual language processing recently. These successes, in conjunction with the proliferating mixed language interactions on social media have boosted interest in modeling code-mixed texts. In this work, we present CodemixedNLP, an open-source library with the goals of bringing together the advances in code-mixed NLP and opening it up to a wider machine learning community. The library consists of tools to develop and benchmark versatile model architectures that are tailored for mixed texts, methods to expand training sets, techniques to quantify mixing styles, and fine-tuned state-of-the-art models for 7 tasks in Hinglish. We believe this work has a potential to foster a distributed yet collaborative and sustainable ecosystem in an otherwise dispersed space of code-mixing research. The toolkit is designed to be simple, easily extensible, and resourceful to both researchers as well as practitioners.
SJ_AJ@DravidianLangTech-EACL2021: Task-Adaptive Pre-Training of Multilingual BERT models for Offensive Language Identification
Feb 01, 2021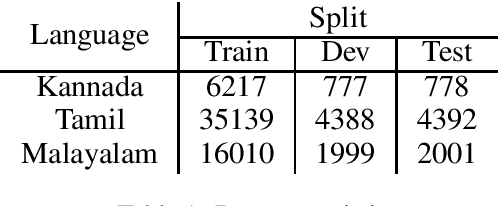
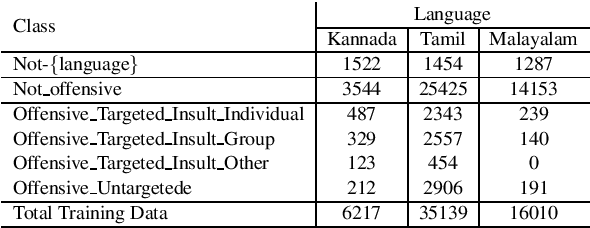
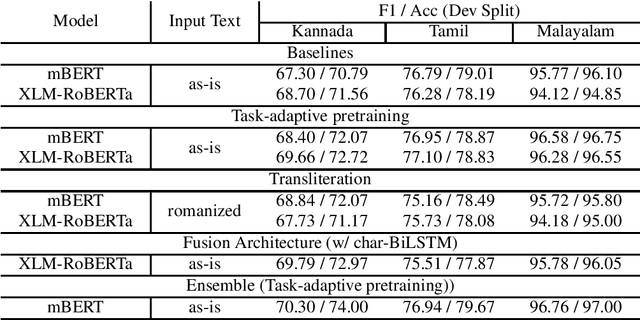

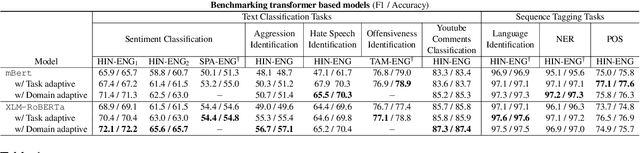
In this paper we present our submission for the EACL 2021-Shared Task on Offensive Language Identification in Dravidian languages. Our final system is an ensemble of mBERT and XLM-RoBERTa models which leverage task-adaptive pre-training of multilingual BERT models with a masked language modeling objective. Our system was ranked 1st for Kannada, 2nd for Malayalam and 3rd for Tamil.
NeuSpell: A Neural Spelling Correction Toolkit
Oct 21, 2020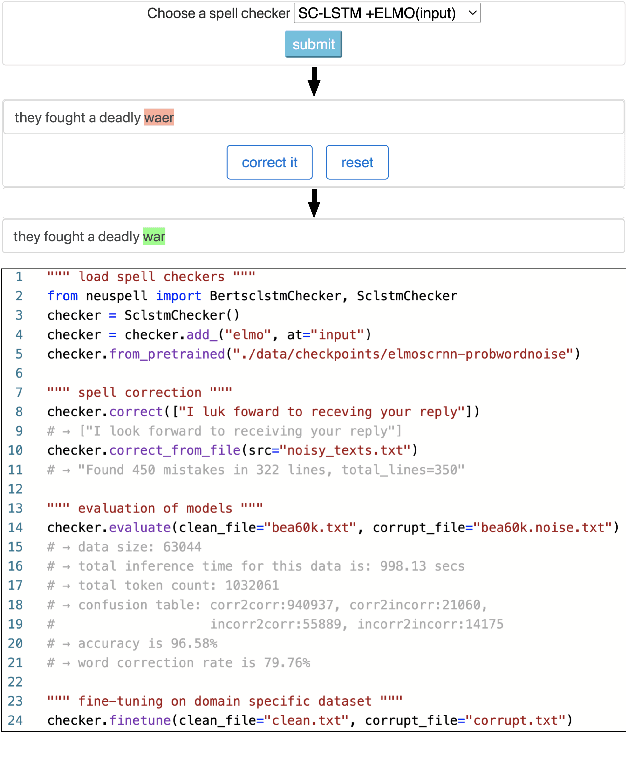
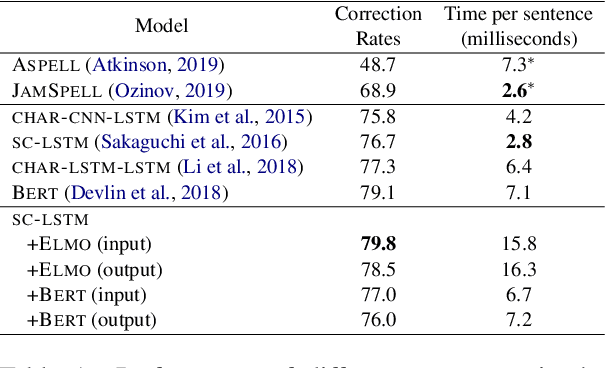
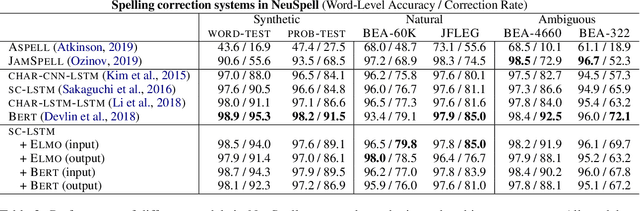
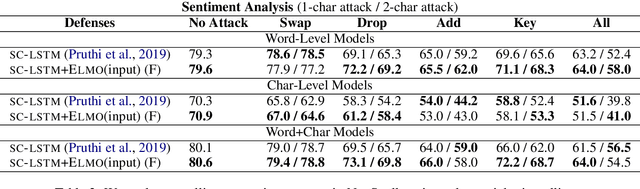
We introduce NeuSpell, an open-source toolkit for spelling correction in English. Our toolkit comprises ten different models, and benchmarks them on naturally occurring misspellings from multiple sources. We find that many systems do not adequately leverage the context around the misspelt token. To remedy this, (i) we train neural models using spelling errors in context, synthetically constructed by reverse engineering isolated misspellings; and (ii) use contextual representations. By training on our synthetic examples, correction rates improve by 9% (absolute) compared to the case when models are trained on randomly sampled character perturbations. Using richer contextual representations boosts the correction rate by another 3%. Our toolkit enables practitioners to use our proposed and existing spelling correction systems, both via a unified command line, as well as a web interface. Among many potential applications, we demonstrate the utility of our spell-checkers in combating adversarial misspellings. The toolkit can be accessed at neuspell.github.io. Code and pretrained models are available at http://github.com/neuspell/neuspell.