 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAVEN: A Regime-Aware Variable-context Expert Network for Financial Time Series Forecasting
Jun 23, 2026Financial time series forecasting presents structural challenges absent from standard benchmarks. Log-returns are non-stationary, exhibit exceptionally low signal-to-noise (SNR) ratios, and are governed by regime-dependent temporal dependencies. We identify a key limitation of state-of-the-art (SOTA) time series models in financial settings. A fixed context window is mismatched to the time-varying optimal look-back of non-stationary price processes. We propose the Regime-Aware Variable-context Expert Network (RAVEN), a Mixture-of-Experts framework designed to adaptively determine the temporal context for each input sample. Instead of relying on a fixed look-back horizon, RAVEN constructs a hierarchy of nested contiguous windows whose lengths are determined by the data itself. Specifically, RAVEN scores patches by learned importance in reverse chronological order and applies the Cumulative Importance Thresholding (CIT) mechanism to derive nested prefix windows, each routed to a scale-specialized expert. A Global Compressed Representation (GCR) branch runs in parallel over the full context, preserving global temporal coherence that local experts cannot guarantee. Because the nested routing induces structured overlap among expert inputs, we introduce a Correlation-Aware Weighting (CAW) to align variable-length expert outputs and penalize pairwise cosine similarity prior to aggregation. Experiments on cumulative log-return prediction (HS300, S&P500) and fund sales forecasting demonstrate that RAVEN achieves SOTA performances, improves Pearson correlation by 9.2% on HS300 and 20.2% on S&P500, and reduces MSE by 18.2% on fund sales forecasting, while achieving the best results in 14 of 16 metrics on four PEMS traffic benchmarks.
LASAR: Latent Adaptive Semantic Aligned Reasoning for Generative Recommendation
May 11, 2026Large Language Models (LLMs) have demonstrated powerful reasoning capabilities through Chain-of-Thought (CoT) in various tasks, yet the inefficiency of token-by-token generation hinders real-world deployment in latency-sensitive recommender systems. Latent reasoning has emerged as an effective paradigm in LLMs, performing multi-step inference in a continuous hidden-state space to achieve stronger reasoning at lower cost. However, this paradigm remains underexplored in mainstream generative recommendation. Adapting it reveals three unique challenges: (1) the gap between prior-less Semantic ID (SID) symbols and continuous latent reasoning - SIDs lack pre-trained semantics, hindering joint optimization; (2) representation drift due to a lack of reasoning chain supervision; and (3) the suboptimality of applying a globally fixed reasoning depth. To address these, we propose LASAR (Latent Adaptive Semantic Aligned Reasoning), an SFT-then-RL framework. First, we bridge this gap via two-stage training: Stage 1 grounds SID semantics before Stage 2 introduces latent reasoning, ensuring efficient convergence. Second, we mitigate representation drift through explicit CoT semantic alignment. Step-wise bidirectional KL divergence constrains the latent reasoning trajectory using hidden-state anchors extracted from CoT text, while a Policy Head predicts per-sample reasoning depth. Third, during the GRPO-based RL phase, terminal-only KL alignment accommodates variable-length reasoning, and REINFORCE optimizes the Policy Head to dynamically allocate steps. This nearly halves the average latent step count while simultaneously improving recommendation quality. Experiments on three real-world datasets demonstrate that LASAR outperforms all baselines. It adds marginal inference latency and is roughly 20 times faster than generating explicit CoT text.
Fusian: Multi-LoRA Fusion for Fine-Grained Continuous MBTI Personality Control in Large Language Models
Mar 16, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in simulating diverse human behaviors and personalities. However, existing methods for personality control, which include prompt engineering and standard Supervised Fine-Tuning (SFT), typically treat personality traits as discrete categories (e.g., "Extroverted" vs. "Introverted"), lacking the ability to precisely control the intensity of a trait on a continuous spectrum. In this paper, we introduce Fusian, a novel framework for fine-grained, continuous personality control in LLMs. Fusian operates in two stages: (1) Trajectory Collection, where we capture the dynamic evolution of personality adoption during SFT by saving a sequence of LoRA adapters, effectively mapping the continuous manifold of a trait; and (2) RL-based Dynamic Fusion, where we train a policy network using Reinforcement Learning to dynamically compute mixing weights for these frozen adapters. By sampling from a Dirichlet distribution parameterized by the policy network, Fusian fuses multiple adapters to align the model's output with a specific numerical target intensity. Experiments on the Qwen3-14B model demonstrate that Fusian achieves high precision in personality control, significantly outperforming baseline methods in aligning with user-specified trait intensities.
Weak-Driven Learning: How Weak Agents make Strong Agents Stronger
Feb 09, 2026As post-training optimization becomes central to improving large language models, we observe a persistent saturation bottleneck: once models grow highly confident, further training yields diminishing returns. While existing methods continue to reinforce target predictions, we find that informative supervision signals remain latent in models' own historical weak states. Motivated by this observation, we propose WMSS (Weak Agents Can Make Strong Agents Stronger), a post-training paradigm that leverages weak checkpoints to guide continued optimization. By identifying recoverable learning gaps via entropy dynamics and reinforcing them through compensatory learning, WMSS enables strong agents to improve beyond conventional post-training saturation. Experiments on mathematical reasoning and code generation datasets show that agents trained with our approach achieve effective performance improvements, while incurring zero additional inference cost.
Does Your Reasoning Model Implicitly Know When to Stop Thinking?
Feb 09, 2026Recent advancements in large reasoning models (LRMs) have greatly improved their capabilities on complex reasoning tasks through Long Chains of Thought (CoTs). However, this approach often results in substantial redundancy, impairing computational efficiency and causing significant delays in real-time applications. Recent studies show that longer reasoning chains are frequently uncorrelated with correctness and can even be detrimental to accuracy. In a further in-depth analysis of this phenomenon, we surprisingly uncover and empirically verify that LRMs implicitly know the appropriate time to stop thinking, while this capability is obscured by current sampling paradigms. Motivated by this, we introduce SAGE (Self-Aware Guided Efficient Reasoning), a novel sampling paradigm that unleashes this efficient reasoning potential. Furthermore, integrating SAGE as mixed sampling into group-based reinforcement learning (SAGE-RL) enables SAGE-RL to effectively incorporate SAGE-discovered efficient reasoning patterns into standard pass@1 inference, markedly enhancing both the reasoning accuracy and efficiency of LRMs across multiple challenging mathematical benchmarks.
LLMBoost: Make Large Language Models Stronger with Boosting
Dec 26, 2025Ensemble learning of LLMs has emerged as a promising alternative to enhance performance, but existing approaches typically treat models as black boxes, combining the inputs or final outputs while overlooking the rich internal representations and interactions across models.In this work, we introduce LLMBoost, a novel ensemble fine-tuning framework that breaks this barrier by explicitly leveraging intermediate states of LLMs. Inspired by the boosting paradigm, LLMBoost incorporates three key innovations. First, a cross-model attention mechanism enables successor models to access and fuse hidden states from predecessors, facilitating hierarchical error correction and knowledge transfer. Second, a chain training paradigm progressively fine-tunes connected models with an error-suppression objective, ensuring that each model rectifies the mispredictions of its predecessor with minimal additional computation. Third, a near-parallel inference paradigm design pipelines hidden states across models layer by layer, achieving inference efficiency approaching single-model decoding. We further establish the theoretical foundations of LLMBoost, proving that sequential integration guarantees monotonic improvements under bounded correction assumptions. Extensive experiments on commonsense reasoning and arithmetic reasoning tasks demonstrate that LLMBoost consistently boosts accuracy while reducing inference latency.
SVGBuilder: Component-Based Colored SVG Generation with Text-Guided Autoregressive Transformers
Dec 17, 2024



Scalable Vector Graphics (SVG) are essential XML-based formats for versatile graphics, offering resolution independence and scalability. Unlike raster images, SVGs use geometric shapes and support interactivity, animation, and manipulation via CSS and JavaScript. Current SVG generation methods face challenges related to high computational costs and complexity. In contrast, human designers use component-based tools for efficient SVG creation. Inspired by this, SVGBuilder introduces a component-based, autoregressive model for generating high-quality colored SVGs from textual input. It significantly reduces computational overhead and improves efficiency compared to traditional methods. Our model generates SVGs up to 604 times faster than optimization-based approaches. To address the limitations of existing SVG datasets and support our research, we introduce ColorSVG-100K, the first large-scale dataset of colored SVGs, comprising 100,000 graphics. This dataset fills the gap in color information for SVG generation models and enhances diversity in model training. Evaluation against state-of-the-art models demonstrates SVGBuilder's superior performance in practical applications, highlighting its efficiency and quality in generating complex SVG graphics.
Viewpoint Consistency in 3D Generation via Attention and CLIP Guidance
Dec 03, 2024



Despite recent advances in text-to-3D generation techniques, current methods often suffer from geometric inconsistencies, commonly referred to as the Janus Problem. This paper identifies the root cause of the Janus Problem: viewpoint generation bias in diffusion models, which creates a significant gap between the actual generated viewpoint and the expected one required for optimizing the 3D model. To address this issue, we propose a tuning-free approach called the Attention and CLIP Guidance (ACG) mechanism. ACG enhances desired viewpoints by adaptively controlling cross-attention maps, employs CLIP-based view-text similarities to filter out erroneous viewpoints, and uses a coarse-to-fine optimization strategy with staged prompts to progressively refine 3D generation. Extensive experiments demonstrate that our method significantly reduces the Janus Problem without compromising generation speed, establishing ACG as an efficient, plug-and-play component for existing text-to-3D frameworks.
Manipulated Face Detector: Joint Spatial and Frequency Domain Attention Network
May 06, 2020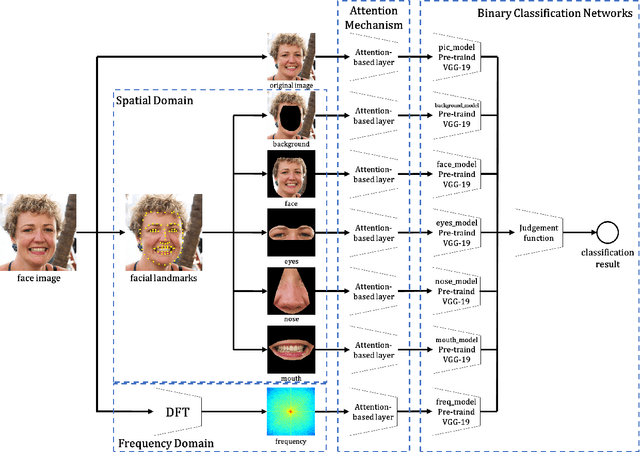
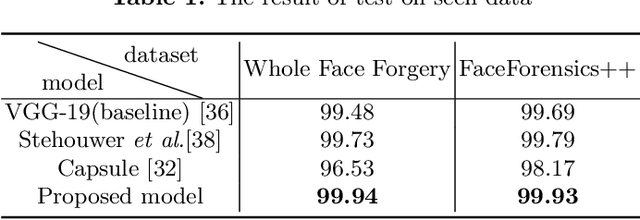

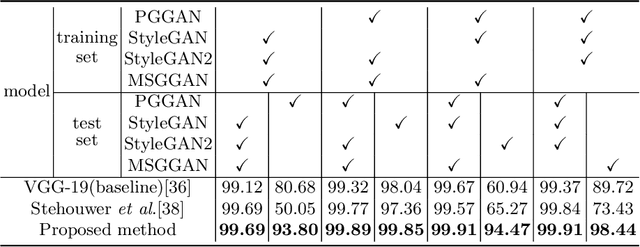
Face manipulation methods develop rapidly in recent years, which can generate high quality manipulated face images. However, detection methods perform not well on data produced by state-of-the-art manipulation methods, and they lack of generalization ability. In this paper, we propose a novel manipulated face detector, which is based on spatial and frequency domain combination and attention mechanism. Spatial domain features are extracted by facial semantic segmentation, and frequency domain features are extracted by Discrete Fourier Transform. We use features both in spatial domain and frequency domain as inputs in proposed model. And we add attention-based layers to backbone networks, in order to improve its generalization ability. We evaluate proposed model on several datasets and compare it with other state-of-the-art manipulated face detection methods. The results show our model performs best on both seen and unseen data.