 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Be A Doctor: Searching for Effective Medical Agent Architectures
Apr 15, 2025Large Language Model (LLM)-based agents have demonstrated strong capabilities across a wide range of tasks, and their application in the medical domain holds particular promise due to the demand for high generalizability and reliance on interdisciplinary knowledge. However, existing medical agent systems often rely on static, manually crafted workflows that lack the flexibility to accommodate diverse diagnostic requirements and adapt to emerging clinical scenarios. Motivated by the success of automated machine learning (AutoML), this paper introduces a novel framework for the automated design of medical agent architectures. Specifically, we define a hierarchical and expressive agent search space that enables dynamic workflow adaptation through structured modifications at the node, structural, and framework levels. Our framework conceptualizes medical agents as graph-based architectures composed of diverse, functional node types and supports iterative self-improvement guided by diagnostic feedback. Experimental results on skin disease diagnosis tasks demonstrate that the proposed method effectively evolves workflow structures and significantly enhances diagnostic accuracy over time. This work represents the first fully automated framework for medical agent architecture design and offers a scalable, adaptable foundation for deploying intelligent agents in real-world clinical environments.
NeRF-Based defect detection
Mar 31, 2025The rapid growth of industrial automation has highlighted the need for precise and efficient defect detection in large-scale machinery. Traditional inspection techniques, involving manual procedures such as scaling tall structures for visual evaluation, are labor-intensive, subjective, and often hazardous. To overcome these challenges, this paper introduces an automated defect detection framework built on Neural Radiance Fields (NeRF) and the concept of digital twins. The system utilizes UAVs to capture images and reconstruct 3D models of machinery, producing both a standard reference model and a current-state model for comparison. Alignment of the models is achieved through the Iterative Closest Point (ICP) algorithm, enabling precise point cloud analysis to detect deviations that signify potential defects. By eliminating manual inspection, this method improves accuracy, enhances operational safety, and offers a scalable solution for defect detection. The proposed approach demonstrates great promise for reliable and efficient industrial applications.
Research on Large Language Model Cross-Cloud Privacy Protection and Collaborative Training based on Federated Learning
Mar 15, 2025The fast development of large language models (LLMs) and popularization of cloud computing have led to increasing concerns on privacy safeguarding and data security of cross-cloud model deployment and training as the key challenges. We present a new framework for addressing these issues along with enabling privacy preserving collaboration on training between distributed clouds based on federated learning. Our mechanism encompasses cutting-edge cryptographic primitives, dynamic model aggregation techniques, and cross-cloud data harmonization solutions to enhance security, efficiency, and scalability to the traditional federated learning paradigm. Furthermore, we proposed a hybrid aggregation scheme to mitigate the threat of Data Leakage and to optimize the aggregation of model updates, thus achieving substantial enhancement on the model effectiveness and stability. Experimental results demonstrate that the training efficiency, privacy protection, and model accuracy of the proposed model compare favorably to those of the traditional federated learning method.
Adaptive Fault Tolerance Mechanisms of Large Language Models in Cloud Computing Environments
Mar 15, 2025With the rapid evolution of Large Language Models (LLMs) and their large-scale experimentation in cloud-computing spaces, the challenge of guaranteeing their security and efficiency in a failure scenario has become a main issue. To ensure the reliability and availability of large-scale language models in cloud computing scenarios, such as frequent resource failures, network problems, and computational overheads, this study proposes a novel adaptive fault tolerance mechanism. It builds upon known fault-tolerant mechanisms, such as checkpointing, redundancy, and state transposition, introducing dynamic resource allocation and prediction of failure based on real-time performance metrics. The hybrid model integrates data driven deep learning-based anomaly detection technique underlining the contribution of cloud orchestration middleware for predictive prevention of system failures. Additionally, the model integrates adaptive checkpointing and recovery strategies that dynamically adapt according to load and system state to minimize the influence on the performance of the model and minimize downtime. The experimental results demonstrate that the designed model considerably enhances the fault tolerance in large-scale cloud surroundings, and decreases the system downtime by $\mathbf{30\%}$, and has a better modeling availability than the classical fault tolerance mechanism.
Can a Single Model Master Both Multi-turn Conversations and Tool Use? CALM: A Unified Conversational Agentic Language Model
Feb 12, 2025

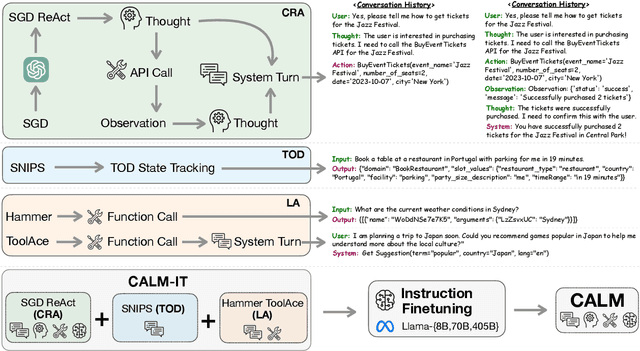
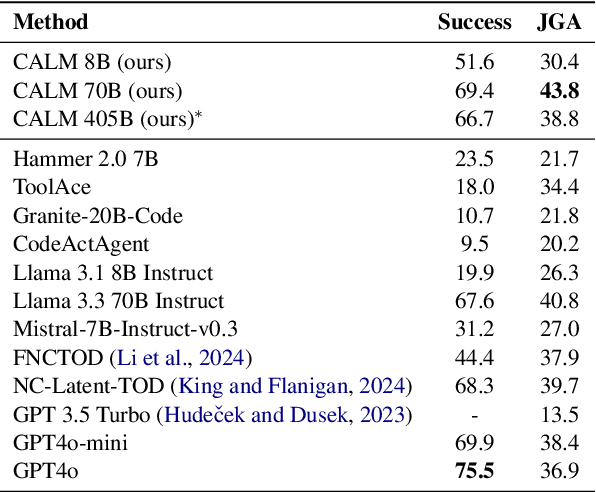
Large Language Models (LLMs) with API-calling capabilities enabled building effective Language Agents (LA), while also revolutionizing the conventional task-oriented dialogue (TOD) paradigm. However, current approaches face a critical dilemma: TOD systems are often trained on a limited set of target APIs, requiring new data to maintain their quality when interfacing with new services, while LAs are not trained to maintain user intent over multi-turn conversations. Because both robust multi-turn management and advanced function calling are crucial for effective conversational agents, we evaluate these skills on three popular benchmarks: MultiWOZ 2.4 (TOD), BFCL V3 (LA), and API-Bank (LA), and our analyses reveal that specialized approaches excel in one domain but underperform in the other. To bridge this chasm, we introduce CALM (Conversational Agentic Language Model), a unified approach that integrates both conversational and agentic capabilities. We created CALM-IT, a carefully constructed multi-task dataset that interleave multi-turn ReAct reasoning with complex API usage. Using CALM-IT, we train three models CALM 8B, CALM 70B, and CALM 405B, which outperform top domain-specific models, including GPT-4o, across all three benchmarks.
HADES: Hardware Accelerated Decoding for Efficient Speculation in Large Language Models
Dec 27, 2024Large Language Models (LLMs) have revolutionized natural language processing by understanding and generating human-like text. However, the increasing demand for more sophisticated LLMs presents significant computational challenges due to their scale and complexity. This paper introduces Hardware Accelerated Decoding (HADES), a novel approach to enhance the performance and energy efficiency of LLMs. We address the design of an LLM accelerator with hardware-level speculative decoding support, a concept not previously explored in existing literature. Our work demonstrates how speculative decoding can significantly improve the efficiency of LLM operations, paving the way for more advanced and practical applications of these models.
Scam Detection for Ethereum Smart Contracts: Leveraging Graph Representation Learning for Secure Blockchain
Dec 16, 2024



The detection of scams within Ethereum smart contracts is a critical challenge due to their increasing exploitation for fraudulent activities, leading to significant financial and reputational damages. Existing detection methods often rely on contract code analysis or manually extracted features, which suffer from scalability and adaptability limitations. In this study, we introduce an innovative method that leverages graph representation learning to examine transaction patterns and identify fraudulent contracts. By transforming Ethereum transaction data into graph structures and employing advanced machine learning models, we achieve robust classification performance. Our method addresses label imbalance through SMOTE-ENN techniques and evaluates models like Multi-Layer Perceptron (MLP) and Graph Convolutional Networks (GCN). Experimental results indicate that the MLP model surpasses the GCN in this context, with real-world evaluations aligning closely with domain-specific analyses. This study provides a scalable and effective solution for enhancing trust and security in the Ethereum ecosystem.
Towards Lifelong Few-Shot Customization of Text-to-Image Diffusion
Nov 08, 2024



Lifelong few-shot customization for text-to-image diffusion aims to continually generalize existing models for new tasks with minimal data while preserving old knowledge. Current customization diffusion models excel in few-shot tasks but struggle with catastrophic forgetting problems in lifelong generations. In this study, we identify and categorize the catastrophic forgetting problems into two folds: relevant concepts forgetting and previous concepts forgetting. To address these challenges, we first devise a data-free knowledge distillation strategy to tackle relevant concepts forgetting. Unlike existing methods that rely on additional real data or offline replay of original concept data, our approach enables on-the-fly knowledge distillation to retain the previous concepts while learning new ones, without accessing any previous data. Second, we develop an In-Context Generation (ICGen) paradigm that allows the diffusion model to be conditioned upon the input vision context, which facilitates the few-shot generation and mitigates the issue of previous concepts forgetting. Extensive experiments show that the proposed Lifelong Few-Shot Diffusion (LFS-Diffusion) method can produce high-quality and accurate images while maintaining previously learned knowledge.
G3R: Gradient Guided Generalizable Reconstruction
Sep 28, 2024Large scale 3D scene reconstruction is important for applications such as virtual reality and simulation. Existing neural rendering approaches (e.g., NeRF, 3DGS) have achieved realistic reconstructions on large scenes, but optimize per scene, which is expensive and slow, and exhibit noticeable artifacts under large view changes due to overfitting. Generalizable approaches or large reconstruction models are fast, but primarily work for small scenes/objects and often produce lower quality rendering results. In this work, we introduce G3R, a generalizable reconstruction approach that can efficiently predict high-quality 3D scene representations for large scenes. We propose to learn a reconstruction network that takes the gradient feedback signals from differentiable rendering to iteratively update a 3D scene representation, combining the benefits of high photorealism from per-scene optimization with data-driven priors from fast feed-forward prediction methods. Experiments on urban-driving and drone datasets show that G3R generalizes across diverse large scenes and accelerates the reconstruction process by at least 10x while achieving comparable or better realism compared to 3DGS, and also being more robust to large view changes.
UniCal: Unified Neural Sensor Calibration
Sep 27, 2024



Self-driving vehicles (SDVs) require accurate calibration of LiDARs and cameras to fuse sensor data accurately for autonomy. Traditional calibration methods typically leverage fiducials captured in a controlled and structured scene and compute correspondences to optimize over. These approaches are costly and require substantial infrastructure and operations, making it challenging to scale for vehicle fleets. In this work, we propose UniCal, a unified framework for effortlessly calibrating SDVs equipped with multiple LiDARs and cameras. Our approach is built upon a differentiable scene representation capable of rendering multi-view geometrically and photometrically consistent sensor observations. We jointly learn the sensor calibration and the underlying scene representation through differentiable volume rendering, utilizing outdoor sensor data without the need for specific calibration fiducials. This "drive-and-calibrate" approach significantly reduces costs and operational overhead compared to existing calibration systems, enabling efficient calibration for large SDV fleets at scale. To ensure geometric consistency across observations from different sensors, we introduce a novel surface alignment loss that combines feature-based registration with neural rendering. Comprehensive evaluations on multiple datasets demonstrate that UniCal outperforms or matches the accuracy of existing calibration approaches while being more efficient, demonstrating the value of UniCal for scalable calibration.