 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentGym: A Testbed For Cross-Task Experiential Learning With Controllable Latent Structure
Jun 13, 2026We envision continually learning agentic systems that become more useful over time: as they encounter sequences of related tasks, they should infer the hidden structure shared across those tasks and use it to improve future decisions. This cross-task experiential learning capability is pivotal in domains such as personalization and interactive assistance, but existing training/evaluation frameworks do not provide shared, controllable latent structures and cannot measure whether or why agents improve. We introduce LatentGym: a controllable suite in which each environment is organized around a ground-truth latent variable governing the structure across tasks. Our construction yields metrics that separate exploration (whether the agent's actions gather information about the latent) from exploitation (whether the agent uses what it has gathered). We demonstrate our suite on empirical studies addressing three questions: how and why frontier models fail to adapt across related tasks; whether post-training on related task sequences improves general cross-task adaptation, and where those gains come from; and how design choices such as inter-task feedback shape training dynamics and generalization. Together, these results establish a controlled foundation for studying how LLM agents learn from experience across tasks, and for designing agents that adapt more reliably in sequential, personalized, and interactive settings.
Can a Single Model Master Both Multi-turn Conversations and Tool Use? CALM: A Unified Conversational Agentic Language Model
Feb 12, 2025

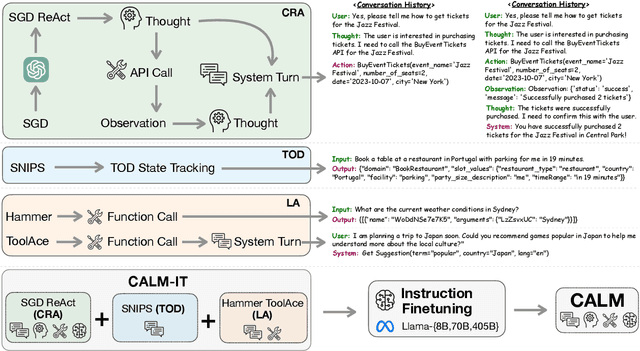
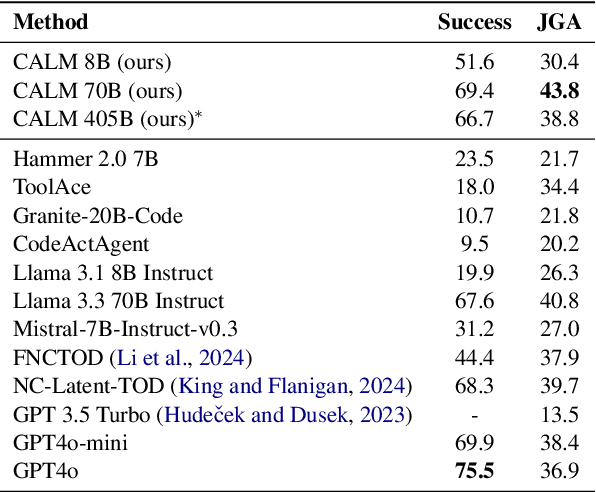
Large Language Models (LLMs) with API-calling capabilities enabled building effective Language Agents (LA), while also revolutionizing the conventional task-oriented dialogue (TOD) paradigm. However, current approaches face a critical dilemma: TOD systems are often trained on a limited set of target APIs, requiring new data to maintain their quality when interfacing with new services, while LAs are not trained to maintain user intent over multi-turn conversations. Because both robust multi-turn management and advanced function calling are crucial for effective conversational agents, we evaluate these skills on three popular benchmarks: MultiWOZ 2.4 (TOD), BFCL V3 (LA), and API-Bank (LA), and our analyses reveal that specialized approaches excel in one domain but underperform in the other. To bridge this chasm, we introduce CALM (Conversational Agentic Language Model), a unified approach that integrates both conversational and agentic capabilities. We created CALM-IT, a carefully constructed multi-task dataset that interleave multi-turn ReAct reasoning with complex API usage. Using CALM-IT, we train three models CALM 8B, CALM 70B, and CALM 405B, which outperform top domain-specific models, including GPT-4o, across all three benchmarks.
Quantum Algorithms for Compositional Natural Language Processing
Aug 04, 2016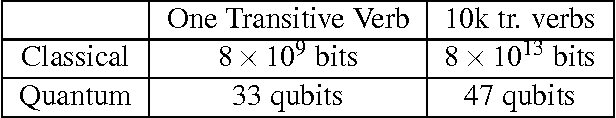
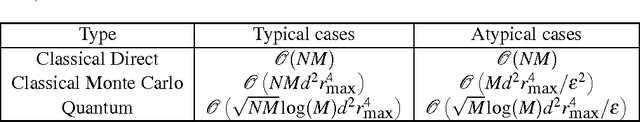
We propose a new application of quantum computing to the field of natural language processing. Ongoing work in this field attempts to incorporate grammatical structure into algorithms that compute meaning. In (Coecke, Sadrzadeh and Clark, 2010), the authors introduce such a model (the CSC model) based on tensor product composition. While this algorithm has many advantages, its implementation is hampered by the large classical computational resources that it requires. In this work we show how computational shortcomings of the CSC approach could be resolved using quantum computation (possibly in addition to existing techniques for dimension reduction). We address the value of quantum RAM (Giovannetti,2008) for this model and extend an algorithm from Wiebe, Braun and Lloyd (2012) into a quantum algorithm to categorize sentences in CSC. Our new algorithm demonstrates a quadratic speedup over classical methods under certain conditions.
* In Proceedings SLPCS 2016, arXiv:1608.01018