 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating SOAP Notes from Doctor-Patient Conversations
May 04, 2020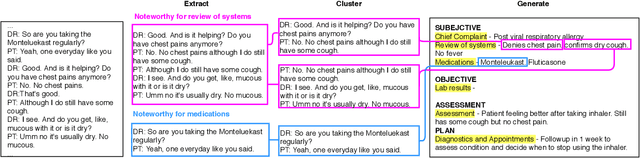
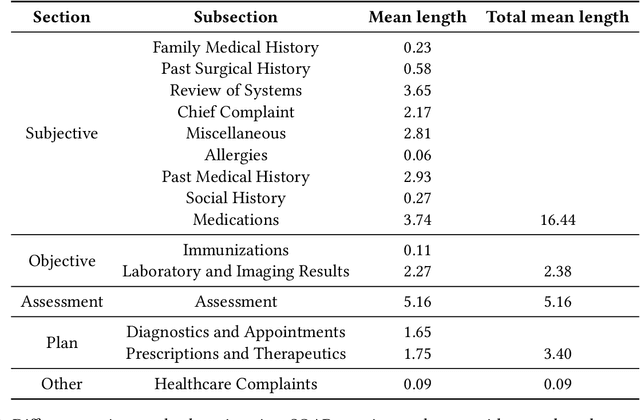
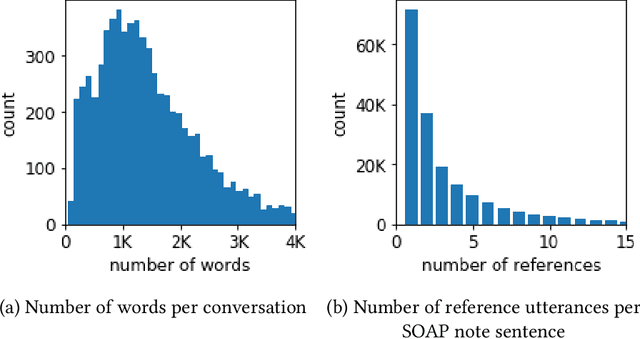
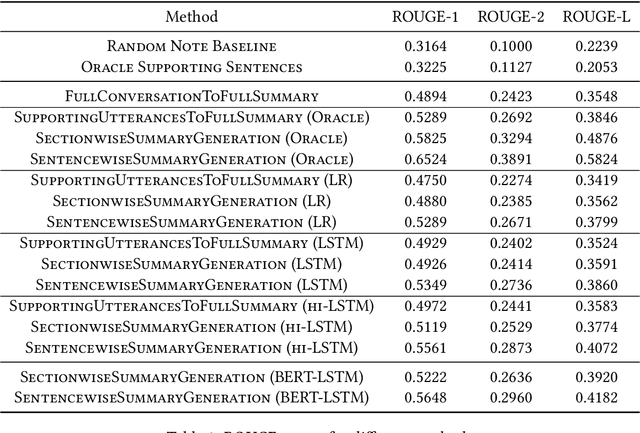
Following each patient visit, physicians must draft detailed clinical summaries called SOAP notes. Moreover, with electronic health records, these notes must be digitized. For all the benefits of this documentation the process remains onerous, contributing to increasing physician burnout. In a parallel development, patients increasingly record audio from their visits (with consent), often through dedicated apps. In this paper, we present the first study to evaluate complete pipelines for leveraging these transcripts to train machine learning model to generate these notes. We first describe a unique dataset of patient visit records, consisting of transcripts, paired SOAP notes, and annotations marking noteworthy utterances that support each summary sentence. We decompose the problem into extractive and abstractive subtasks, exploring a spectrum of approaches according to how much they demand from each component. Our best performing method first (i) extracts noteworthy utterances via multi-label classification assigns them to summary section(s); (ii) clusters noteworthy utterances on a per-section basis; and (iii) generates the summary sentences by conditioning on the corresponding cluster and the subsection of the SOAP sentence to be generated. Compared to an end-to-end approach that generates the full SOAP note from the full conversation, our approach improves by 7 ROUGE-1 points. Oracle experiments indicate that fixing our generative capabilities, improvements in extraction alone could provide (up to) a further 9 ROUGE point gain.
Estimating Treatment Effects with Observed Confounders and Mediators
Mar 26, 2020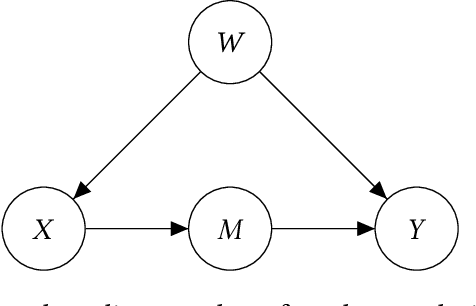
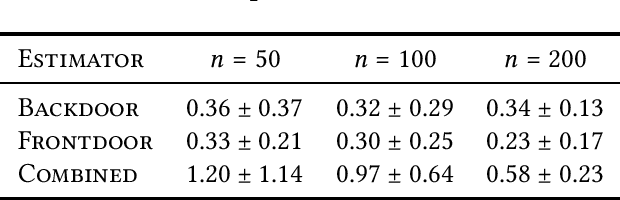
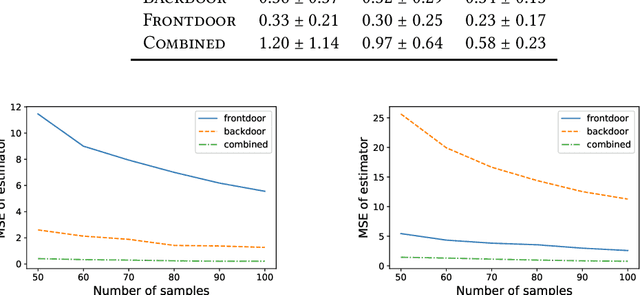
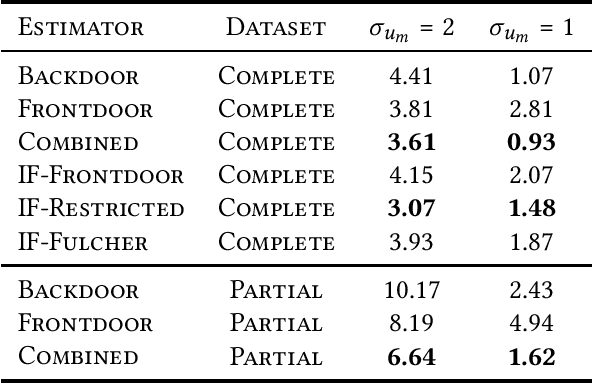
Given a causal graph, the do-calculus can express treatment effects as functionals of the observational joint distribution that can be estimated empirically. Sometimes the do-calculus identifies multiple valid formulae, prompting us to compare the statistical properties of the corresponding estimators. For example, the backdoor formula applies when all confounders are observed and the frontdoor formula applies when an observed mediator transmits the causal effect. In this paper, we investigate the over-identified scenario where both confounders and mediators are observed, rendering both estimators valid. Addressing the linear Gaussian causal model, we derive the finite-sample variance for both estimators and demonstrate that either estimator can dominate the other by an unbounded constant factor depending on the model parameters. Next, we derive an optimal estimator, which leverages all observed variables to strictly outperform the backdoor and frontdoor estimators. We also present a procedure for combining two datasets, with confounders observed in one and mediators in the other. Finally, we evaluate our methods on both simulated data and the IHDP and JTPA datasets.
A Unified View of Label Shift Estimation
Mar 17, 2020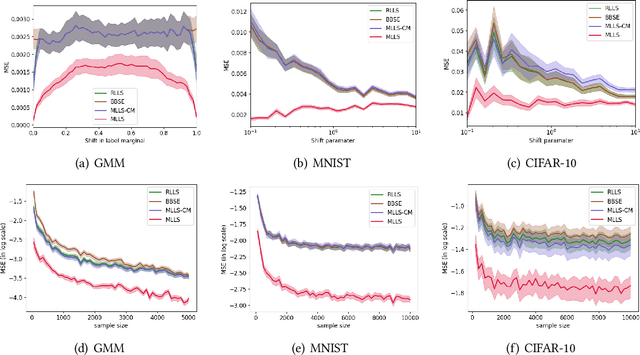
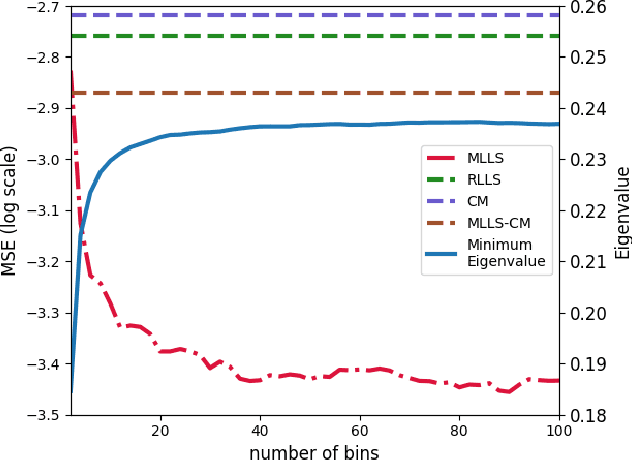
Label shift describes the setting where although the label distribution might change between the source and target domains, the class-conditional probabilities (of data given a label) do not. There are two dominant approaches for estimating the label marginal. BBSE, a moment-matching approach based on confusion matrices, is provably consistent and provides interpretable error bounds. However, a maximum likelihood estimation approach, which we call MLLS, dominates empirically. In this paper, we present a unified view of the two methods and the first theoretical characterization of the likelihood-based estimator. Our contributions include (i) conditions for consistency of MLLS, which include calibration of the classifier and a confusion matrix invertibility condition that BBSE also requires; (ii) a unified view of the methods, casting the confusion matrix as roughly equivalent to MLLS for a particular choice of calibration method; and (iii) a decomposition of MLLS's finite-sample error into terms reflecting the impacts of miscalibration and estimation error. Our analysis attributes BBSE's statistical inefficiency to a loss of information due to coarse calibration. We support our findings with experiments on both synthetic data and the MNIST and CIFAR10 image recognition datasets.
Causal Inference With Selectively-Deconfounded Data
Feb 25, 2020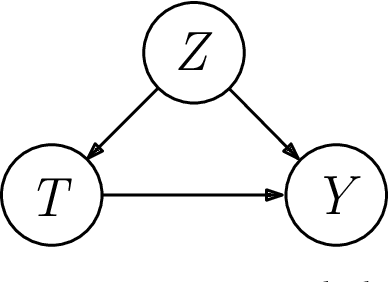
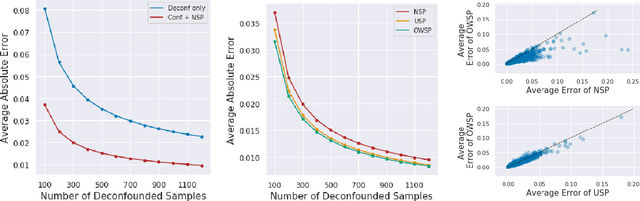
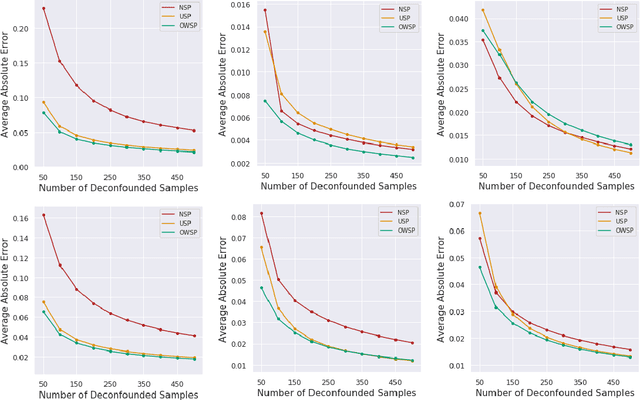
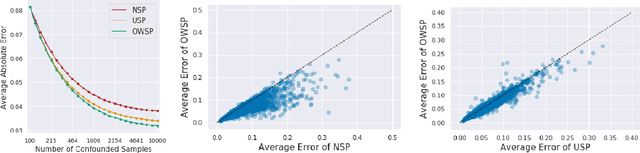
Given only data generated by a standard confounding graph with unobserved confounder, the Average Treatment Effect (ATE) is not identifiable. To estimate the ATE, a practitioner must then either (a) collect deconfounded data; (b) run a clinical trial; or (c) elucidate further properties of the causal graph that might render the ATE identifiable. In this paper, we consider the benefit of incorporating a (large) confounded observational dataset alongside a (small) deconfounded observational dataset when estimating the ATE. Our theoretical results show that the inclusion of confounded data can significantly reduce the quantity of deconfounded data required to estimate the ATE to within a desired accuracy level. Moreover, in some cases---say, genetics---we could imagine retrospectively selecting samples to deconfound. We demonstrate that by strategically selecting these examples based upon the (already observed) treatment and outcome, we can reduce our data dependence further. Our theoretical and empirical results establish that the worst-case relative performance of our approach (vs. a natural benchmark) is bounded while our best-case gains are unbounded. Next, we demonstrate the benefits of selective deconfounding using a large real-world dataset related to genetic mutation in cancer. Finally, we introduce an online version of the problem, proposing two adaptive heuristics.
Algorithmic Fairness from a Non-ideal Perspective
Jan 08, 2020Inspired by recent breakthroughs in predictive modeling, practitioners in both industry and government have turned to machine learning with hopes of operationalizing predictions to drive automated decisions. Unfortunately, many social desiderata concerning consequential decisions, such as justice or fairness, have no natural formulation within a purely predictive framework. In efforts to mitigate these problems, researchers have proposed a variety of metrics for quantifying deviations from various statistical parities that we might expect to observe in a fair world and offered a variety of algorithms in attempts to satisfy subsets of these parities or to trade off the degree to which they are satisfied against utility. In this paper, we connect this approach to \emph{fair machine learning} to the literature on ideal and non-ideal methodological approaches in political philosophy. The ideal approach requires positing the principles according to which a just world would operate. In the most straightforward application of ideal theory, one supports a proposed policy by arguing that it closes a discrepancy between the real and the perfectly just world. However, by failing to account for the mechanisms by which our non-ideal world arose, the responsibilities of various decision-makers, and the impacts of proposed policies, naive applications of ideal thinking can lead to misguided interventions. In this paper, we demonstrate a connection between the fair machine learning literature and the ideal approach in political philosophy, and argue that the increasingly apparent shortcomings of proposed fair machine learning algorithms reflect broader troubles faced by the ideal approach. We conclude with a critical discussion of the harms of misguided solutions, a reinterpretation of impossibility results, and directions for future research.
Game Design for Eliciting Distinguishable Behavior
Dec 12, 2019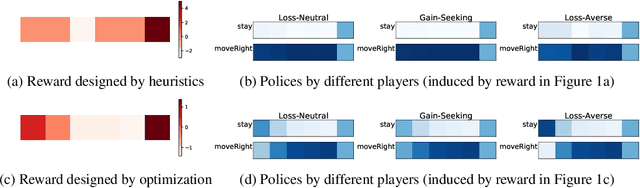
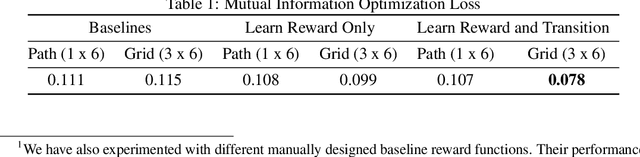
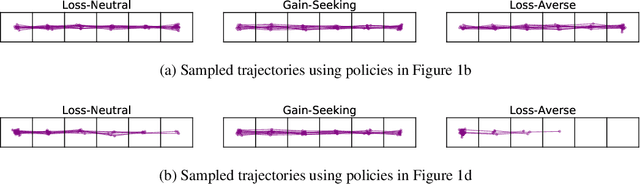

The ability to inferring latent psychological traits from human behavior is key to developing personalized human-interacting machine learning systems. Approaches to infer such traits range from surveys to manually-constructed experiments and games. However, these traditional games are limited because they are typically designed based on heuristics. In this paper, we formulate the task of designing \emph{behavior diagnostic games} that elicit distinguishable behavior as a mutual information maximization problem, which can be solved by optimizing a variational lower bound. Our framework is instantiated by using prospect theory to model varying player traits, and Markov Decision Processes to parameterize the games. We validate our approach empirically, showing that our designed games can successfully distinguish among players with different traits, outperforming manually-designed ones by a large margin.
Are Perceptually-Aligned Gradients a General Property of Robust Classifiers?
Oct 23, 2019



For a standard convolutional neural network, optimizing over the input pixels to maximize the score of some target class will generally produce a grainy-looking version of the original image. However, Santurkar et al. (2019) demonstrated that for adversarially-trained neural networks, this optimization produces images that uncannily resemble the target class. In this paper, we show that these "perceptually-aligned gradients" also occur under randomized smoothing, an alternative means of constructing adversarially-robust classifiers. Our finding supports the hypothesis that perceptually-aligned gradients may be a general property of robust classifiers. We hope that our results will inspire research aimed at explaining this link between perceptually-aligned gradients and adversarial robustness.
Accelerating Deep Learning by Focusing on the Biggest Losers
Oct 02, 2019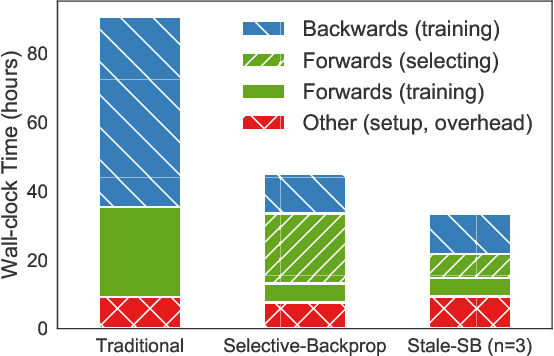
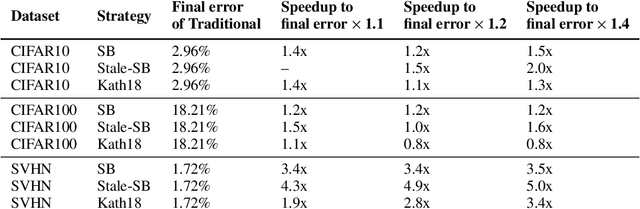


This paper introduces Selective-Backprop, a technique that accelerates the training of deep neural networks (DNNs) by prioritizing examples with high loss at each iteration. Selective-Backprop uses the output of a training example's forward pass to decide whether to use that example to compute gradients and update parameters, or to skip immediately to the next example. By reducing the number of computationally-expensive backpropagation steps performed, Selective-Backprop accelerates training. Evaluation on CIFAR10, CIFAR100, and SVHN, across a variety of modern image models, shows that Selective-Backprop converges to target error rates up to 3.5x faster than with standard SGD and between 1.02--1.8x faster than a state-of-the-art importance sampling approach. Further acceleration of 26% can be achieved by using stale forward pass results for selection, thus also skipping forward passes of low priority examples.
Learning the Difference that Makes a Difference with Counterfactually-Augmented Data
Sep 26, 2019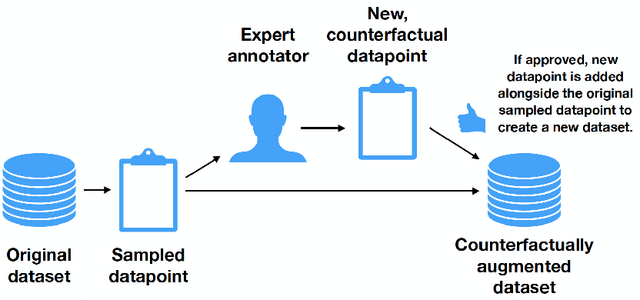
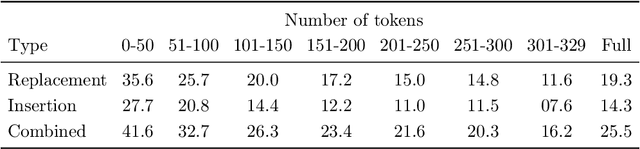

Despite alarm over the reliance of machine learning systems on so-called spurious patterns in training data, the term lacks coherent meaning in standard statistical frameworks. However, the language of causality offers clarity: spurious associations are those due to a common cause (confounding) vs direct or indirect effects. In this paper, we focus on NLP, introducing methods and resources for training models insensitive to spurious patterns. Given documents and their initial labels, we task humans with revise each document to accord with a counterfactual target label, asking that the revised documents be internally coherent while avoiding any gratuitous changes. Interestingly, on sentiment analysis and natural language inference tasks, classifiers trained on original data fail on their counterfactually-revised counterparts and vice versa. Classifiers trained on combined datasets perform remarkably well, just shy of those specialized to either domain. While classifiers trained on either original or manipulated data alone are sensitive to spurious features (e.g., mentions of genre), models trained on the combined data are insensitive to this signal. We will publicly release both datasets.
Learning to Deceive with Attention-Based Explanations
Sep 17, 2019
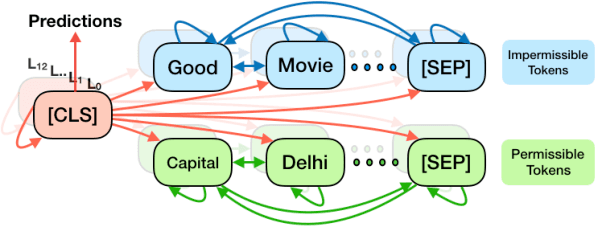

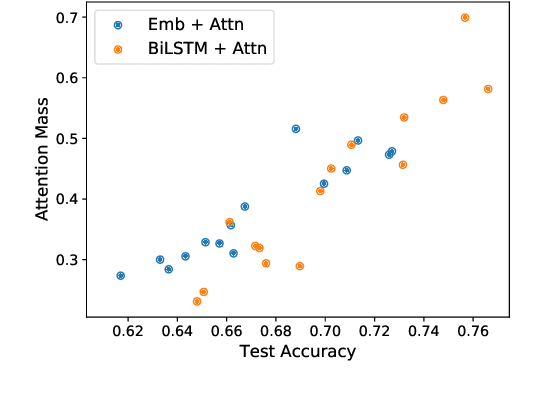
Attention mechanisms are ubiquitous components in neural architectures applied in natural language processing. In addition to yielding gains in predictive accuracy, researchers often claim that attention weights confer interpretability, purportedly useful both for providing insights to practitioners and for explaining why a model makes its decisions to stakeholders. We call the latter use of attention mechanisms into question, demonstrating a simple method for training models to produce deceptive attention masks, diminishing the total weight assigned to designated impermissible tokens, even as the models are shown to nevertheless rely on these features to drive predictions. Across multiple models and datasets, our approach manipulates attention weights while paying surprisingly little cost in accuracy. Although our results do not rule out potential insights due to organically-trained attention, they cast doubt on attention's reliability as a tool for auditing algorithms, as in the context of fairness and accountability.