 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Online Estimation of Causal Effects by Deciding What to Observe
Aug 20, 2021

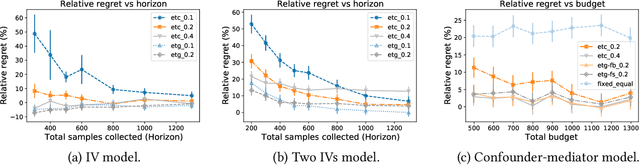
Researchers often face data fusion problems, where multiple data sources are available, each capturing a distinct subset of variables. While problem formulations typically take the data as given, in practice, data acquisition can be an ongoing process. In this paper, we aim to estimate any functional of a probabilistic model (e.g., a causal effect) as efficiently as possible, by deciding, at each time, which data source to query. We propose online moment selection (OMS), a framework in which structural assumptions are encoded as moment conditions. The optimal action at each step depends, in part, on the very moments that identify the functional of interest. Our algorithms balance exploration with choosing the best action as suggested by current estimates of the moments. We propose two selection strategies: (1) explore-then-commit (OMS-ETC) and (2) explore-then-greedy (OMS-ETG), proving that both achieve zero asymptotic regret as assessed by MSE. We instantiate our setup for average treatment effect estimation, where structural assumptions are given by a causal graph and data sources may include subsets of mediators, confounders, and instrumental variables.
Dive into Deep Learning
Jun 21, 2021
This open-source book represents our attempt to make deep learning approachable, teaching readers the concepts, the context, and the code. The entire book is drafted in Jupyter notebooks, seamlessly integrating exposition figures, math, and interactive examples with self-contained code. Our goal is to offer a resource that could (i) be freely available for everyone; (ii) offer sufficient technical depth to provide a starting point on the path to actually becoming an applied machine learning scientist; (iii) include runnable code, showing readers how to solve problems in practice; (iv) allow for rapid updates, both by us and also by the community at large; (v) be complemented by a forum for interactive discussion of technical details and to answer questions.
Correcting Exposure Bias for Link Recommendation
Jun 13, 2021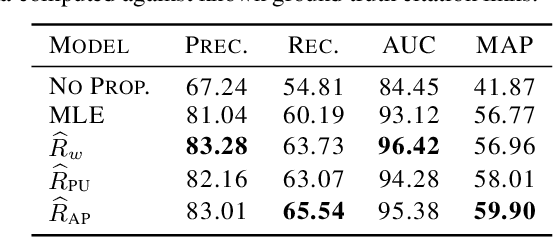
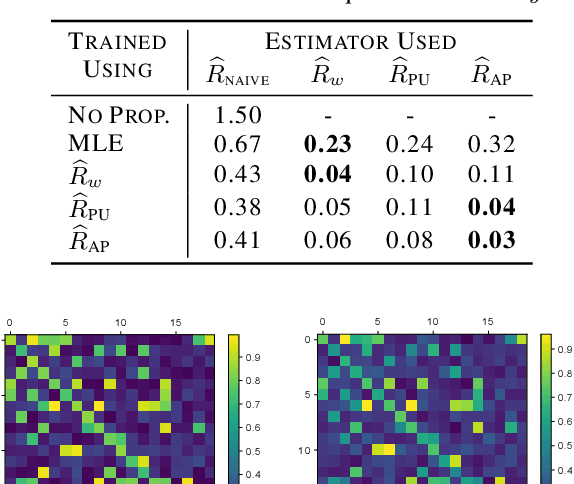
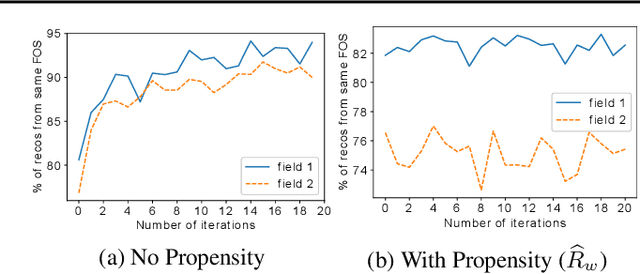
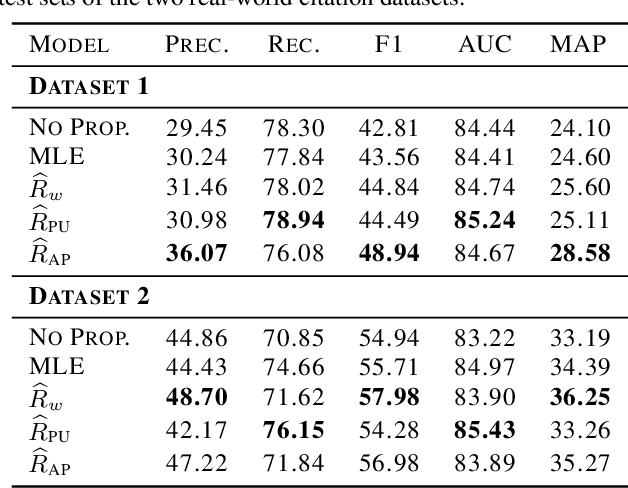
Link prediction methods are frequently applied in recommender systems, e.g., to suggest citations for academic papers or friends in social networks. However, exposure bias can arise when users are systematically underexposed to certain relevant items. For example, in citation networks, authors might be more likely to encounter papers from their own field and thus cite them preferentially. This bias can propagate through naively trained link predictors, leading to both biased evaluation and high generalization error (as assessed by true relevance). Moreover, this bias can be exacerbated by feedback loops. We propose estimators that leverage known exposure probabilities to mitigate this bias and consequent feedback loops. Next, we provide a loss function for learning the exposure probabilities from data. Finally, experiments on semi-synthetic data based on real-world citation networks, show that our methods reliably identify (truly) relevant citations. Additionally, our methods lead to greater diversity in the recommended papers' fields of study. The code is available at https://github.com/shantanu95/exposure-bias-link-rec.
On the Efficacy of Adversarial Data Collection for Question Answering: Results from a Large-Scale Randomized Study
Jun 02, 2021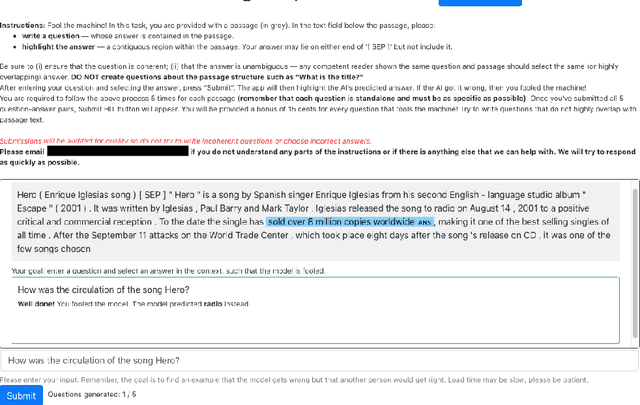

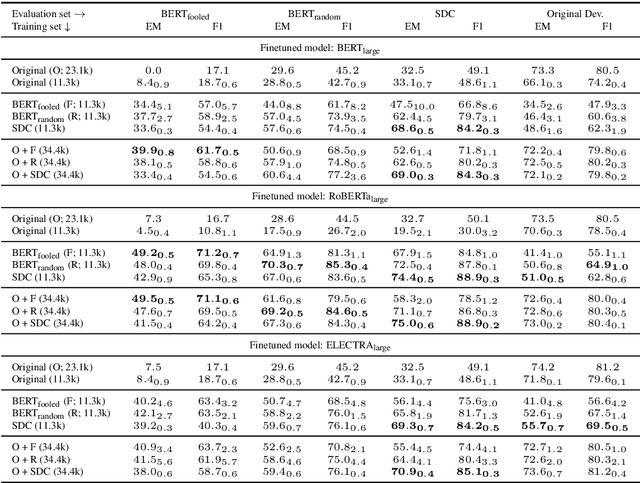

In adversarial data collection (ADC), a human workforce interacts with a model in real time, attempting to produce examples that elicit incorrect predictions. Researchers hope that models trained on these more challenging datasets will rely less on superficial patterns, and thus be less brittle. However, despite ADC's intuitive appeal, it remains unclear when training on adversarial datasets produces more robust models. In this paper, we conduct a large-scale controlled study focused on question answering, assigning workers at random to compose questions either (i) adversarially (with a model in the loop); or (ii) in the standard fashion (without a model). Across a variety of models and datasets, we find that models trained on adversarial data usually perform better on other adversarial datasets but worse on a diverse collection of out-of-domain evaluation sets. Finally, we provide a qualitative analysis of adversarial (vs standard) data, identifying key differences and offering guidance for future research.
RATT: Leveraging Unlabeled Data to Guarantee Generalization
May 01, 2021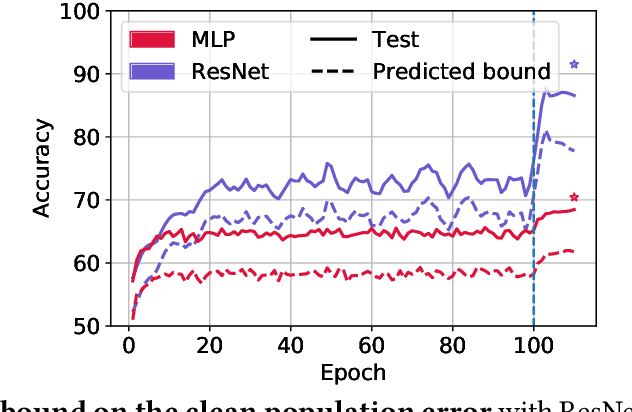
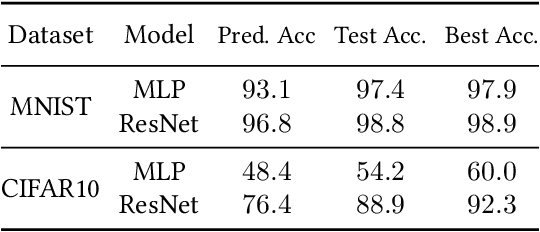
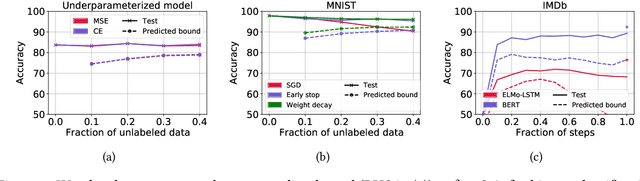
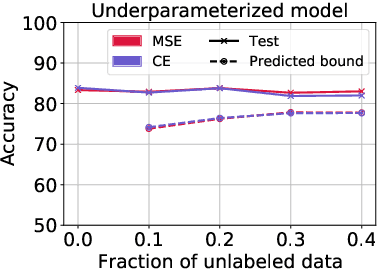
To assess generalization, machine learning scientists typically either (i) bound the generalization gap and then (after training) plug in the empirical risk to obtain a bound on the true risk; or (ii) validate empirically on holdout data. However, (i) typically yields vacuous guarantees for overparameterized models. Furthermore, (ii) shrinks the training set and its guarantee erodes with each re-use of the holdout set. In this paper, we introduce a method that leverages unlabeled data to produce generalization bounds. After augmenting our (labeled) training set with randomly labeled fresh examples, we train in the standard fashion. Whenever classifiers achieve low error on clean data and high error on noisy data, our bound provides a tight upper bound on the true risk. We prove that our bound is valid for 0-1 empirical risk minimization and with linear classifiers trained by gradient descent. Our approach is especially useful in conjunction with deep learning due to the early learning phenomenon whereby networks fit true labels before noisy labels but requires one intuitive assumption. Empirically, on canonical computer vision and NLP tasks, our bound provides non-vacuous generalization guarantees that track actual performance closely. This work provides practitioners with an option for certifying the generalization of deep nets even when unseen labeled data is unavailable and provides theoretical insights into the relationship between random label noise and generalization.
Off-Policy Risk Assessment in Contextual Bandits
Apr 18, 2021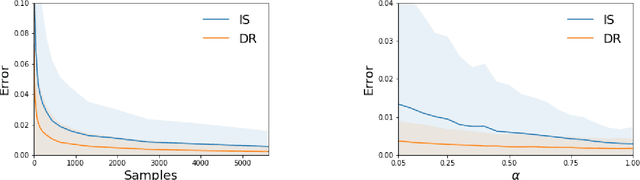
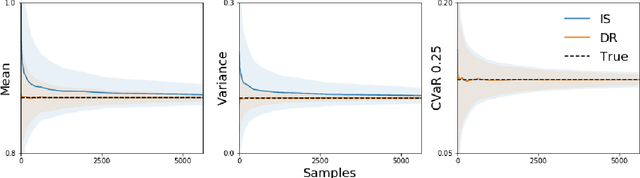
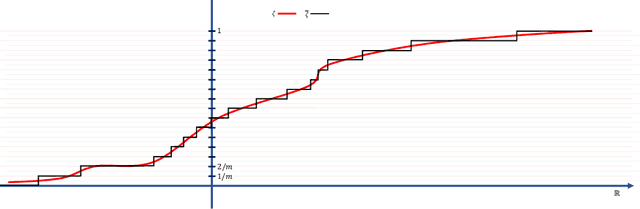
To evaluate prospective contextual bandit policies when experimentation is not possible, practitioners often rely on off-policy evaluation, using data collected under a behavioral policy. While off-policy evaluation studies typically focus on the expected return, practitioners often care about other functionals of the reward distribution (e.g., to express aversion to risk). In this paper, we first introduce the class of Lipschitz risk functionals, which subsumes many common functionals, including variance, mean-variance, and conditional value-at-risk (CVaR). For Lipschitz risk functionals, the error in off-policy risk estimation is bounded by the error in off-policy estimation of the cumulative distribution function (CDF) of rewards. Second, we propose Off-Policy Risk Assessment (OPRA), an algorithm that (i) estimates the target policy's CDF of rewards; and (ii) generates a plug-in estimate of the risk. Given a collection of Lipschitz risk functionals, OPRA provides estimates for each with corresponding error bounds that hold simultaneously. We analyze both importance sampling and variance-reduced doubly robust estimators of the CDF. Our primary theoretical contributions are (i) the first concentration inequalities for both types of CDF estimators and (ii) guarantees on our Lipschitz risk functional estimates, which converge at a rate of O(1/\sqrt{n}). For practitioners, OPRA offers a practical solution for providing high-confidence assessments of policies using a collection of relevant metrics.
On the Convergence and Optimality of Policy Gradient for Markov Coherent Risk
Mar 05, 2021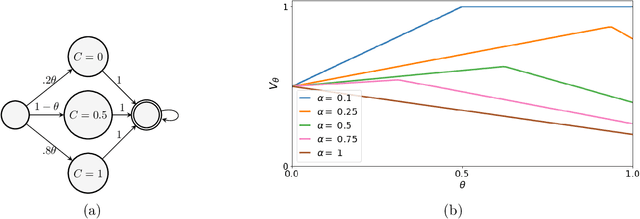

In order to model risk aversion in reinforcement learning, an emerging line of research adapts familiar algorithms to optimize coherent risk functionals, a class that includes conditional value-at-risk (CVaR). Because optimizing the coherent risk is difficult in Markov decision processes, recent work tends to focus on the Markov coherent risk (MCR), a time-consistent surrogate. While, policy gradient (PG) updates have been derived for this objective, it remains unclear (i) whether PG finds a global optimum for MCR; (ii) how to estimate the gradient in a tractable manner. In this paper, we demonstrate that, in general, MCR objectives (unlike the expected return) are not gradient dominated and that stationary points are not, in general, guaranteed to be globally optimal. Moreover, we present a tight upper bound on the suboptimality of the learned policy, characterizing its dependence on the nonlinearity of the objective and the degree of risk aversion. Addressing (ii), we propose a practical implementation of PG that uses state distribution reweighting to overcome previous limitations. Through experiments, we demonstrate that when the optimality gap is small, PG can learn risk-sensitive policies. However, we find that instances with large suboptimality gaps are abundant and easy to construct, outlining an important challenge for future research.
Parametric Complexity Bounds for Approximating PDEs with Neural Networks
Mar 03, 2021Recent empirical results show that deep networks can approximate solutions to high dimensional PDEs, seemingly escaping the curse of dimensionality. However many open questions remain regarding the theoretical basis for such approximations, including the number of parameters required. In this paper, we investigate the representational power of neural networks for approximating solutions to linear elliptic PDEs with Dirichlet Boundary conditions. We prove that when a PDE's coefficients are representable by small neural networks, the parameters required to approximate its solution scale polynomially with the input dimension $d$ and are proportional to the parameter counts of the coefficient neural networks. Our proof is based on constructing a neural network which simulates gradient descent in an appropriate Hilbert space which converges to the solution of the PDE. Moreover, we bound the size of the neural network needed to represent each iterate in terms of the neural network representing the previous iterate, resulting in a final network whose parameters depend polynomially on $d$ and does not depend on the volume of the domain.
On Proximal Policy Optimization's Heavy-tailed Gradients
Feb 20, 2021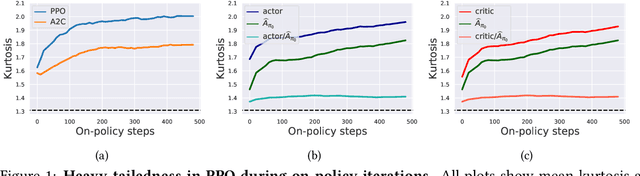
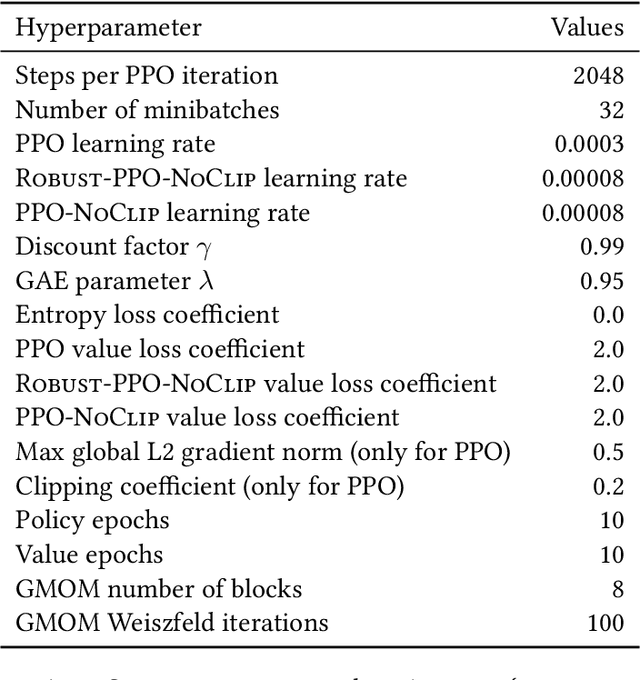
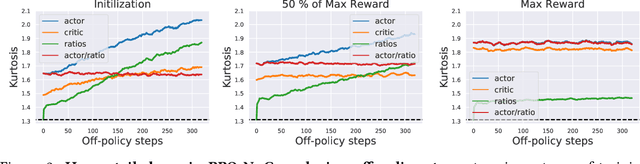
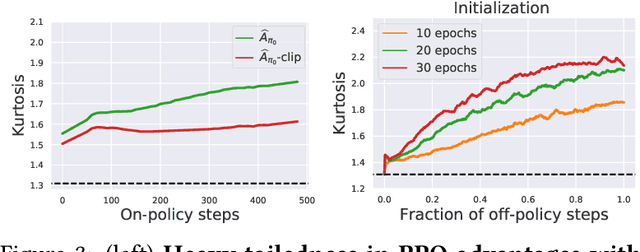
Modern policy gradient algorithms, notably Proximal Policy Optimization (PPO), rely on an arsenal of heuristics, including loss clipping and gradient clipping, to ensure successful learning. These heuristics are reminiscent of techniques from robust statistics, commonly used for estimation in outlier-rich ("heavy-tailed") regimes. In this paper, we present a detailed empirical study to characterize the heavy-tailed nature of the gradients of the PPO surrogate reward function. We demonstrate that the gradients, especially for the actor network, exhibit pronounced heavy-tailedness and that it increases as the agent's policy diverges from the behavioral policy (i.e., as the agent goes further off policy). Further examination implicates the likelihood ratios and advantages in the surrogate reward as the main sources of the observed heavy-tailedness. We then highlight issues arising due to the heavy-tailed nature of the gradients. In this light, we study the effects of the standard PPO clipping heuristics, demonstrating that these tricks primarily serve to offset heavy-tailedness in gradients. Thus motivated, we propose incorporating GMOM, a high-dimensional robust estimator, into PPO as a substitute for three clipping tricks. Despite requiring less hyperparameter tuning, our method matches the performance of PPO (with all heuristics enabled) on a battery of MuJoCo continuous control tasks.
Evaluating Explanations: How much do explanations from the teacher aid students?
Dec 01, 2020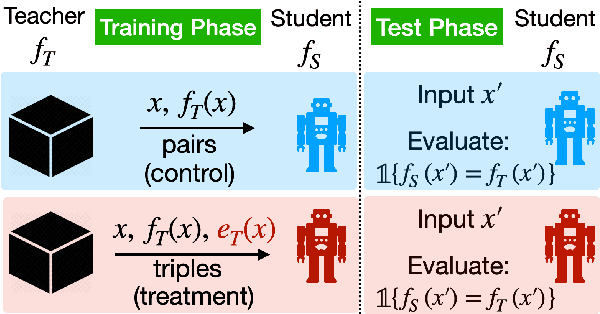
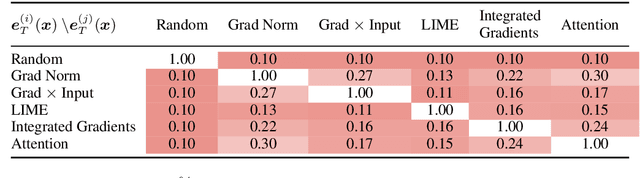

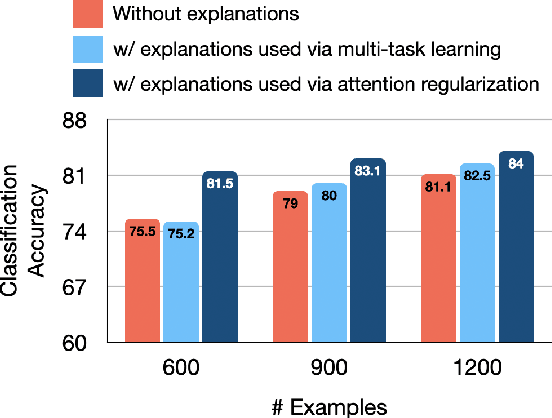
While many methods purport to explain predictions by highlighting salient features, what precise aims these explanations serve and how to evaluate their utility are often unstated. In this work, we formalize the value of explanations using a student-teacher paradigm that measures the extent to which explanations improve student models in learning to simulate the teacher model on unseen examples for which explanations are unavailable. Student models incorporate explanations in training (but not prediction) procedures. Unlike many prior proposals to evaluate explanations, our approach cannot be easily gamed, enabling principled, scalable, and automatic evaluation of attributions. Using our framework, we compare multiple attribution methods and observe consistent and quantitative differences amongst them across multiple learning strategies.