 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Domain Targeted Sentiment Analysis via Span-Based Extraction and Classification
Jun 10, 2019

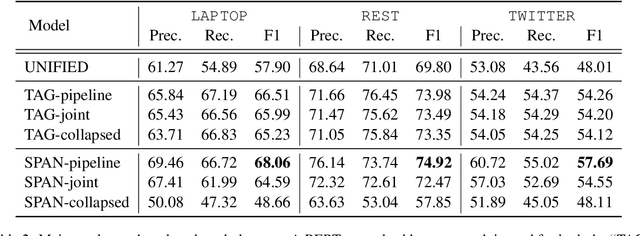
Open-domain targeted sentiment analysis aims to detect opinion targets along with their sentiment polarities from a sentence. Prior work typically formulates this task as a sequence tagging problem. However, such formulation suffers from problems such as huge search space and sentiment inconsistency. To address these problems, we propose a span-based extract-then-classify framework, where multiple opinion targets are directly extracted from the sentence under the supervision of target span boundaries, and corresponding polarities are then classified using their span representations. We further investigate three approaches under this framework, namely the pipeline, joint, and collapsed models. Experiments on three benchmark datasets show that our approach consistently outperforms the sequence tagging baseline. Moreover, we find that the pipeline model achieves the best performance compared with the other two models.
ThunderNet: Towards Real-time Generic Object Detection
Mar 28, 2019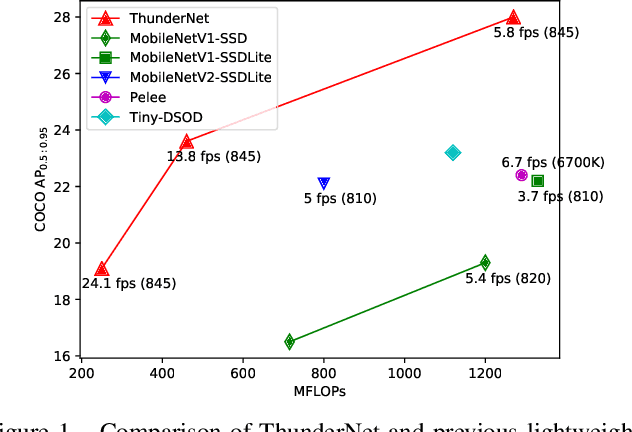
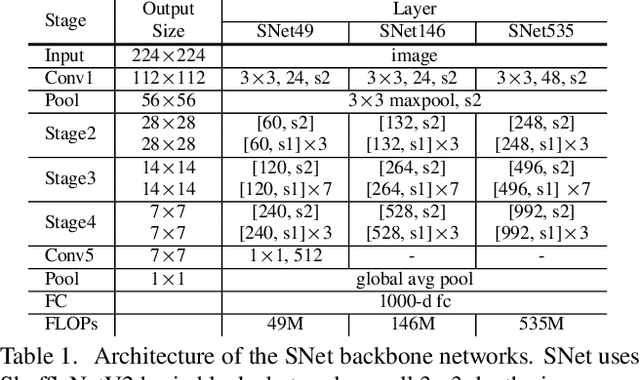
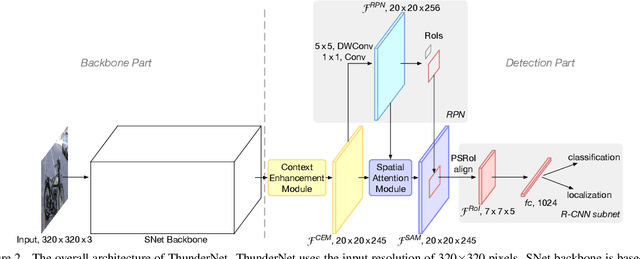
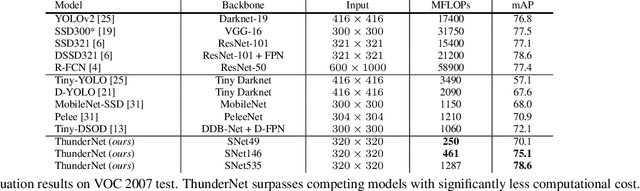
Real-time generic object detection on mobile platforms is a crucial but challenging computer vision task. However, previous CNN-based detectors suffer from enormous computational cost, which hinders them from real-time inference in computation-constrained scenarios. In this paper, we investigate the effectiveness of two-stage detectors in real-time generic detection and propose a lightweight two-stage detector named ThunderNet. In the backbone part, we analyze the drawbacks in previous lightweight backbones and present a lightweight backbone designed for object detection. In the detection part, we exploit an extremely efficient RPN and detection head design. To generate more discriminative feature representation, we design two efficient architecture blocks, Context Enhancement Module and Spatial Attention Module. At last, we investigate the balance between the input resolution, the backbone, and the detection head. Compared with lightweight one-stage detectors, ThunderNet achieves superior performance with only 40% of the computational cost on PASCAL VOC and COCO benchmarks. Without bells and whistles, our model runs at 24.1 fps on an ARM-based device. To the best of our knowledge, this is the first real-time detector reported on ARM platforms. Code will be released for paper reproduction.
Attention-Guided Answer Distillation for Machine Reading Comprehension
Sep 17, 2018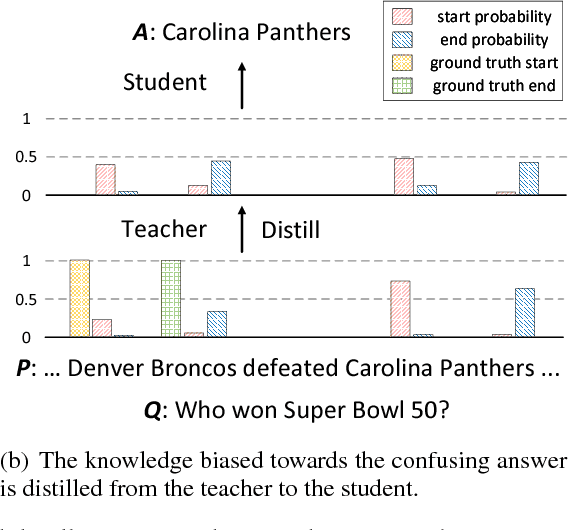
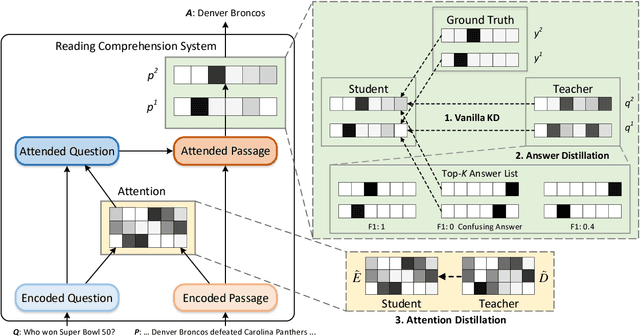
Despite that current reading comprehension systems have achieved significant advancements, their promising performances are often obtained at the cost of making an ensemble of numerous models. Besides, existing approaches are also vulnerable to adversarial attacks. This paper tackles these problems by leveraging knowledge distillation, which aims to transfer knowledge from an ensemble model to a single model. We first demonstrate that vanilla knowledge distillation applied to answer span prediction is effective for reading comprehension systems. We then propose two novel approaches that not only penalize the prediction on confusing answers but also guide the training with alignment information distilled from the ensemble. Experiments show that our best student model has only a slight drop of 0.4% F1 on the SQuAD test set compared to the ensemble teacher, while running 12x faster during inference. It even outperforms the teacher on adversarial SQuAD datasets and NarrativeQA benchmark.
Read + Verify: Machine Reading Comprehension with Unanswerable Questions
Sep 05, 2018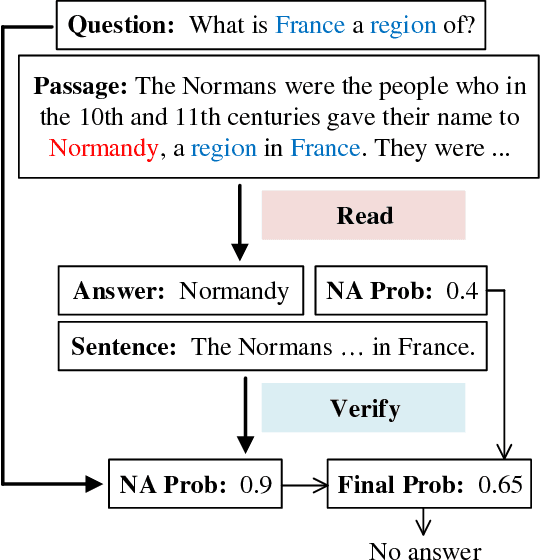
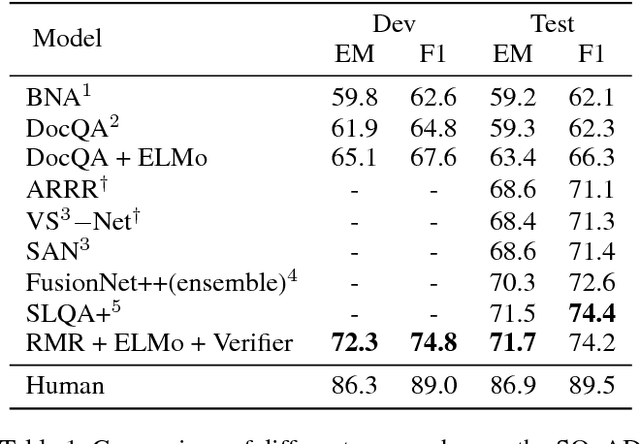
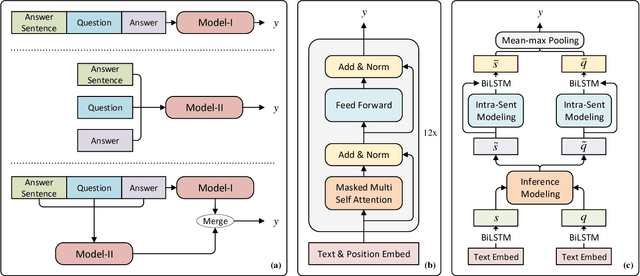
Machine reading comprehension with unanswerable questions aims to abstain from answering when no answer can be inferred. In addition to extract answers, previous works usually predict an additional "no-answer" probability to detect unanswerable cases. However, they fail to validate the answerability of the question by verifying the legitimacy of the predicted answer. To address this problem, we propose a novel read-then-verify system, which not only utilizes a neural reader to extract candidate answers and produce no-answer probabilities, but also leverages an answer verifier to decide whether the predicted answer is entailed by the input snippets. Moreover, we introduce two auxiliary losses to help the reader better handle answer extraction as well as no-answer detection, and investigate three different architectures for the answer verifier. Our experiments on the SQuAD 2.0 dataset show that our system achieves a score of 74.2 F1 on the test set, outperforming all previous approaches at the time of submission (Aug. 23th, 2018).
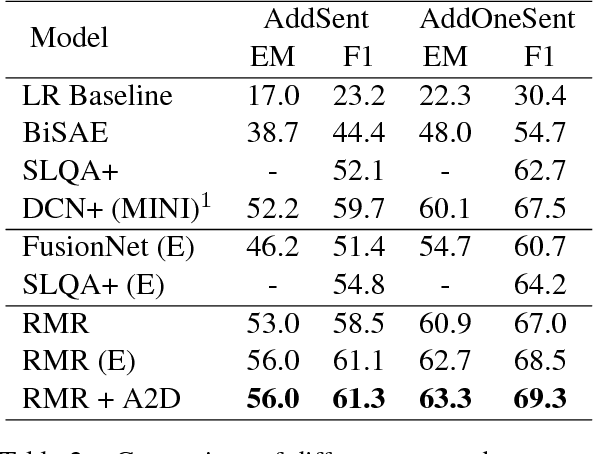
Reinforced Mnemonic Reader for Machine Reading Comprehension
Jun 06, 2018
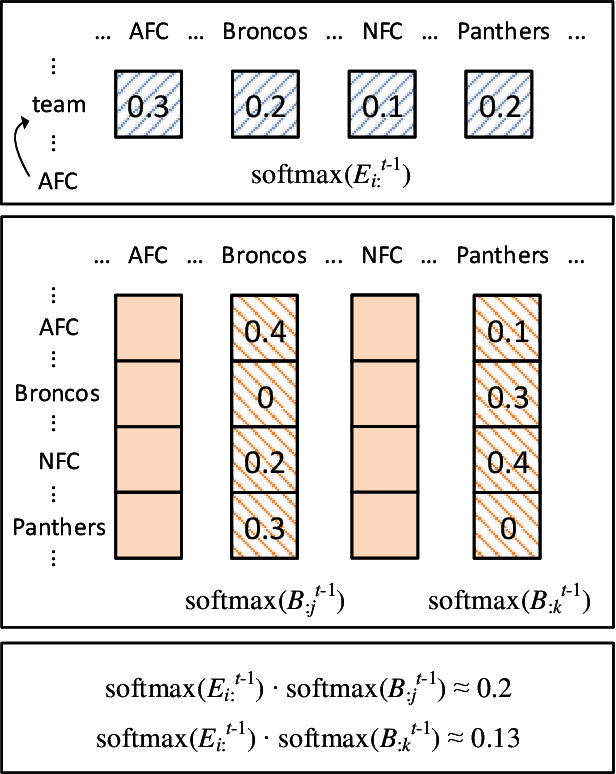
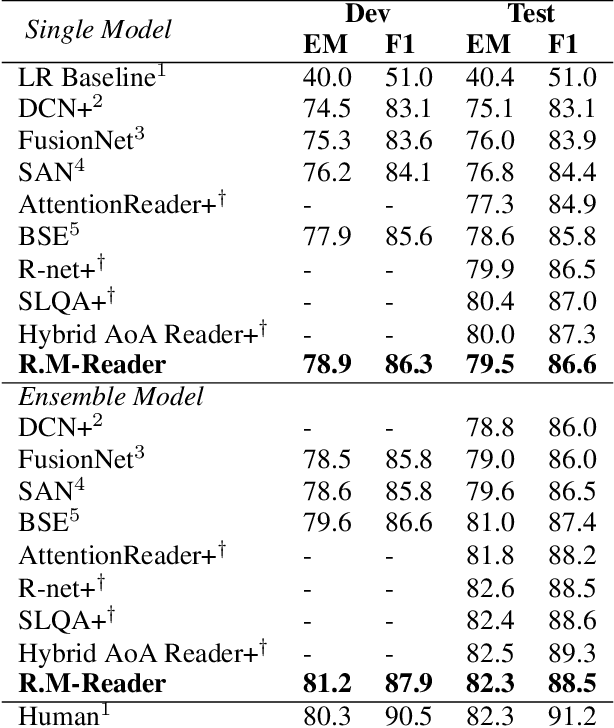
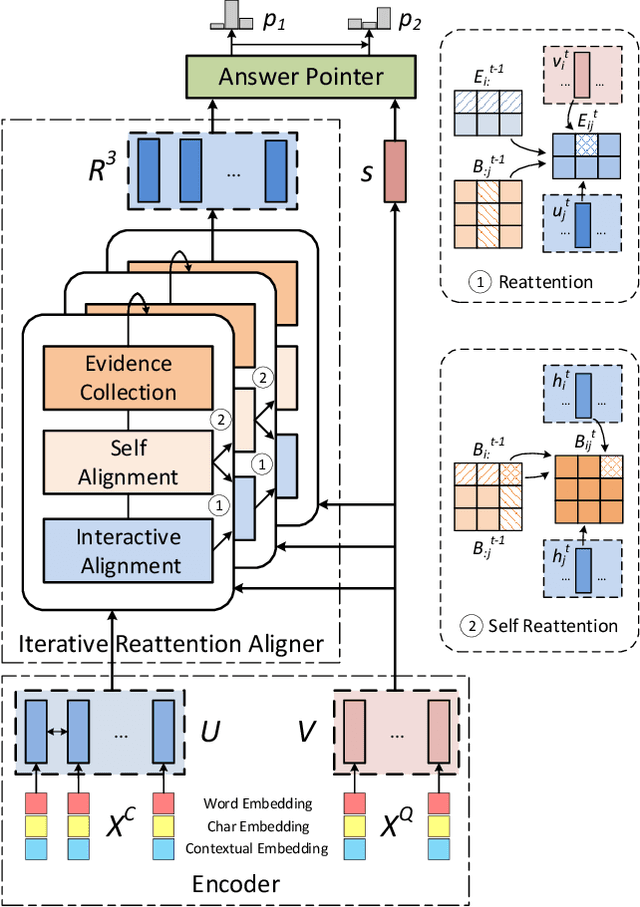
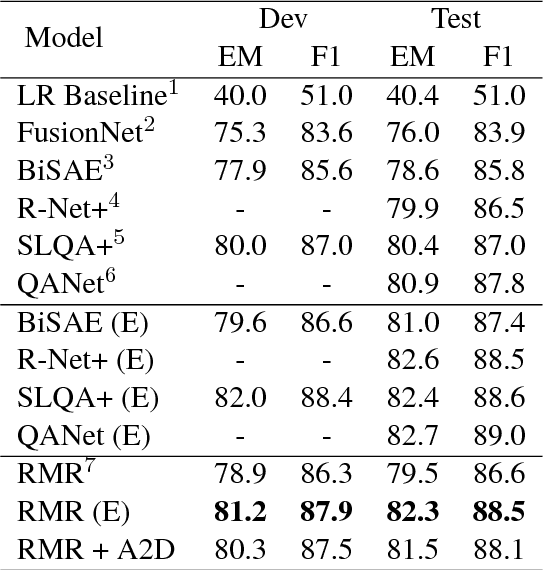
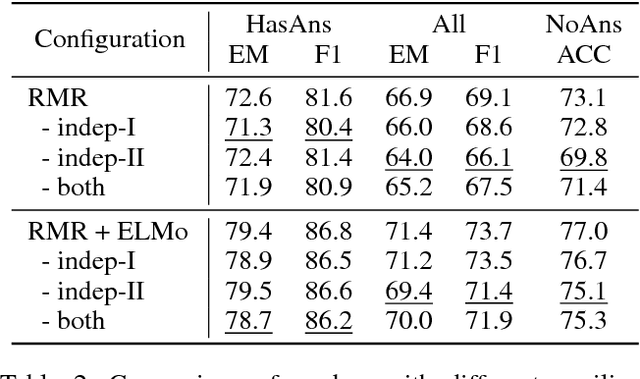
In this paper, we introduce the Reinforced Mnemonic Reader for machine reading comprehension tasks, which enhances previous attentive readers in two aspects. First, a reattention mechanism is proposed to refine current attentions by directly accessing to past attentions that are temporally memorized in a multi-round alignment architecture, so as to avoid the problems of attention redundancy and attention deficiency. Second, a new optimization approach, called dynamic-critical reinforcement learning, is introduced to extend the standard supervised method. It always encourages to predict a more acceptable answer so as to address the convergence suppression problem occurred in traditional reinforcement learning algorithms. Extensive experiments on the Stanford Question Answering Dataset (SQuAD) show that our model achieves state-of-the-art results. Meanwhile, our model outperforms previous systems by over 6% in terms of both Exact Match and F1 metrics on two adversarial SQuAD datasets.
Diagonalwise Refactorization: An Efficient Training Method for Depthwise Convolutions
Mar 27, 2018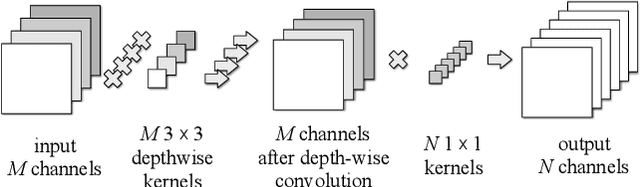
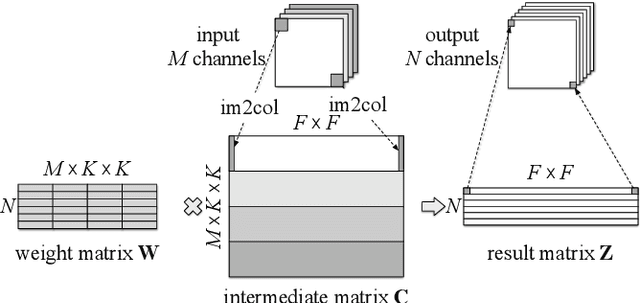
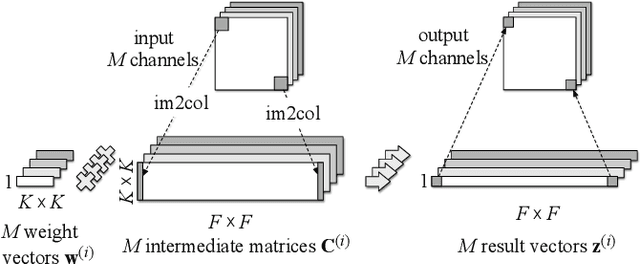
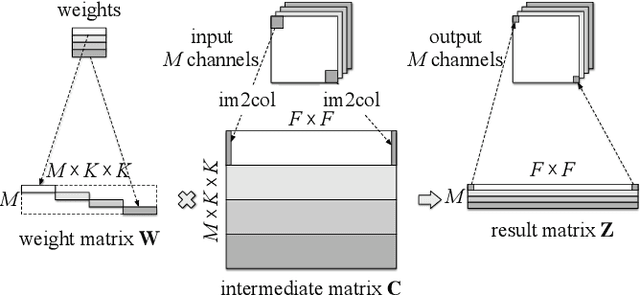
Depthwise convolutions provide significant performance benefits owing to the reduction in both parameters and mult-adds. However, training depthwise convolution layers with GPUs is slow in current deep learning frameworks because their implementations cannot fully utilize the GPU capacity. To address this problem, in this paper we present an efficient method (called diagonalwise refactorization) for accelerating the training of depthwise convolution layers. Our key idea is to rearrange the weight vectors of a depthwise convolution into a large diagonal weight matrix so as to convert the depthwise convolution into one single standard convolution, which is well supported by the cuDNN library that is highly-optimized for GPU computations. We have implemented our training method in five popular deep learning frameworks. Evaluation results show that our proposed method gains $15.4\times$ training speedup on Darknet, $8.4\times$ on Caffe, $5.4\times$ on PyTorch, $3.5\times$ on MXNet, and $1.4\times$ on TensorFlow, compared to their original implementations of depthwise convolutions.
Merging and Evolution: Improving Convolutional Neural Networks for Mobile Applications
Mar 24, 2018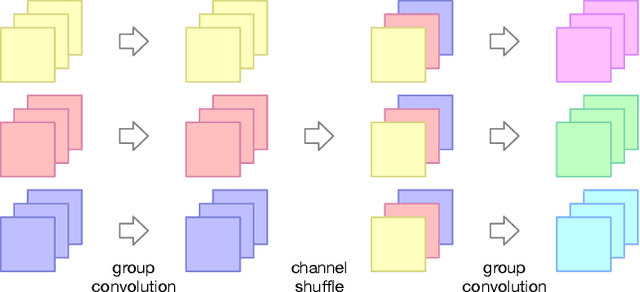
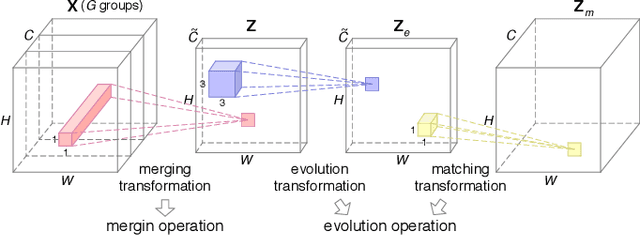
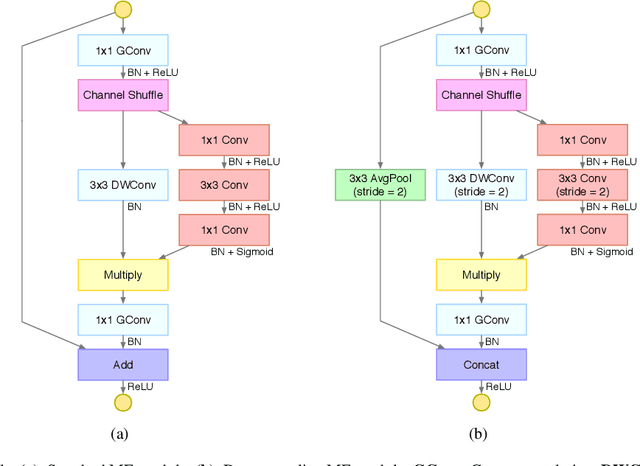
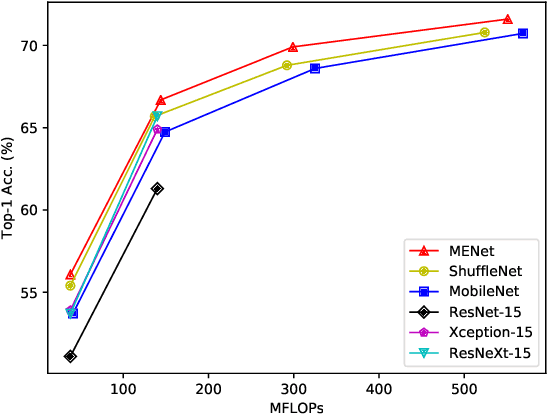
Compact neural networks are inclined to exploit "sparsely-connected" convolutions such as depthwise convolution and group convolution for employment in mobile applications. Compared with standard "fully-connected" convolutions, these convolutions are more computationally economical. However, "sparsely-connected" convolutions block the inter-group information exchange, which induces severe performance degradation. To address this issue, we present two novel operations named merging and evolution to leverage the inter-group information. Our key idea is encoding the inter-group information with a narrow feature map, then combining the generated features with the original network for better representation. Taking advantage of the proposed operations, we then introduce the Merging-and-Evolution (ME) module, an architectural unit specifically designed for compact networks. Finally, we propose a family of compact neural networks called MENet based on ME modules. Extensive experiments on ILSVRC 2012 dataset and PASCAL VOC 2007 dataset demonstrate that MENet consistently outperforms other state-of-the-art compact networks under different computational budgets. For instance, under the computational budget of 140 MFLOPs, MENet surpasses ShuffleNet by 1% and MobileNet by 1.95% on ILSVRC 2012 top-1 accuracy, while by 2.3% and 4.1% on PASCAL VOC 2007 mAP, respectively.
FD-MobileNet: Improved MobileNet with a Fast Downsampling Strategy
Feb 11, 2018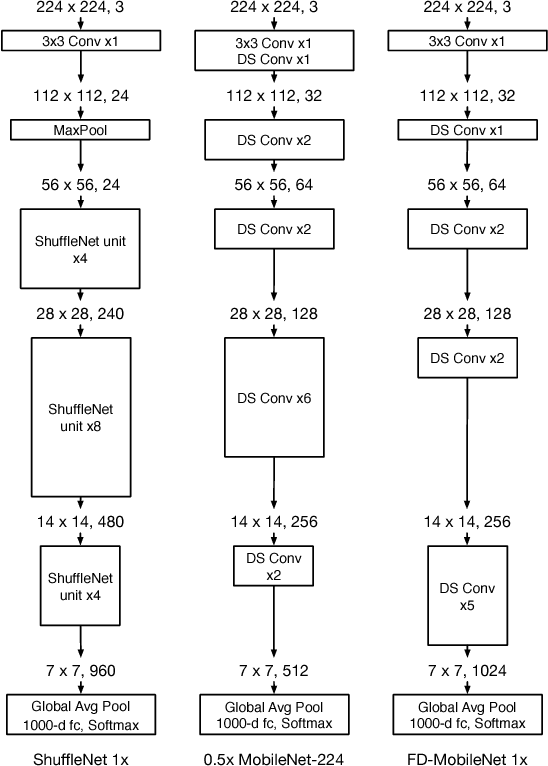
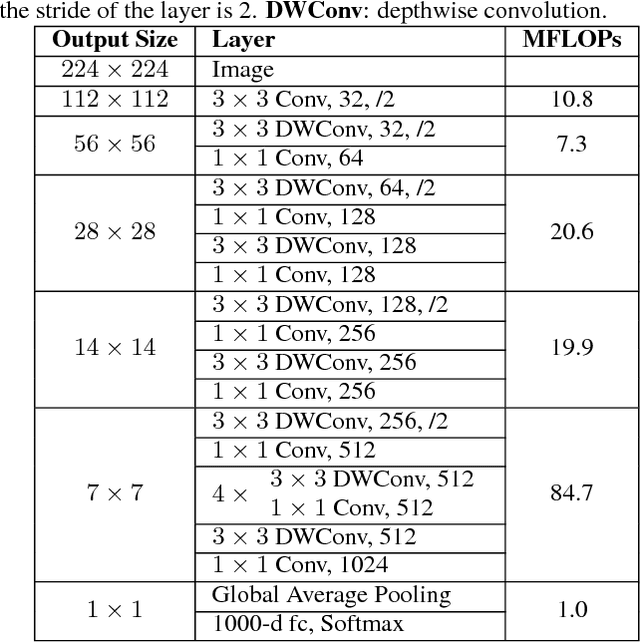
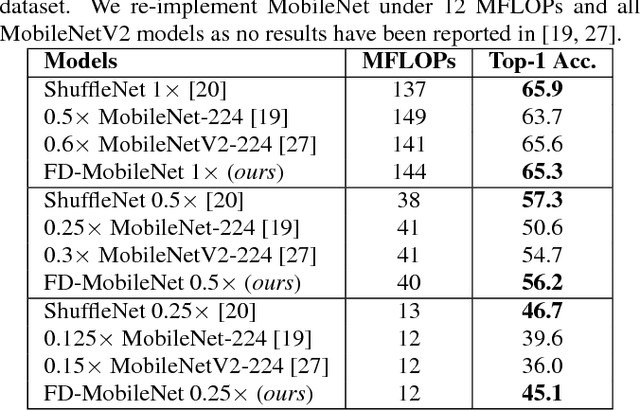
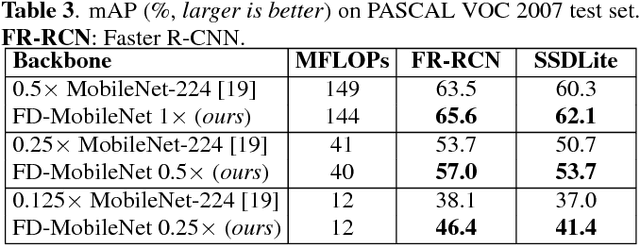
We present Fast-Downsampling MobileNet (FD-MobileNet), an efficient and accurate network for very limited computational budgets (e.g., 10-140 MFLOPs). Our key idea is applying an aggressive downsampling strategy to MobileNet framework. In FD-MobileNet, we perform 32$\times$ downsampling within 12 layers, only half the layers in the original MobileNet. This design brings three advantages: (i) It remarkably reduces the computational cost. (ii) It increases the information capacity and achieves significant performance improvements. (iii) It is engineering-friendly and provides fast actual inference speed. Experiments on ILSVRC 2012 and PASCAL VOC 2007 datasets demonstrate that FD-MobileNet consistently outperforms MobileNet and achieves comparable results with ShuffleNet under different computational budgets, for instance, surpassing MobileNet by 5.5% on the ILSVRC 2012 top-1 accuracy and 3.6% on the VOC 2007 mAP under a complexity of 12 MFLOPs. On an ARM-based device, FD-MobileNet achieves 1.11$\times$ inference speedup over MobileNet and 1.82$\times$ over ShuffleNet under the same complexity.
hi-RF: Incremental Learning Random Forest for large-scale multi-class Data Classification
Oct 31, 2016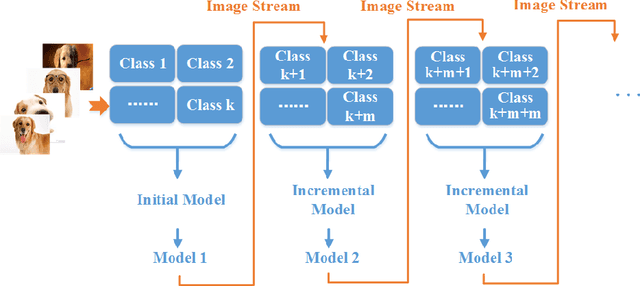

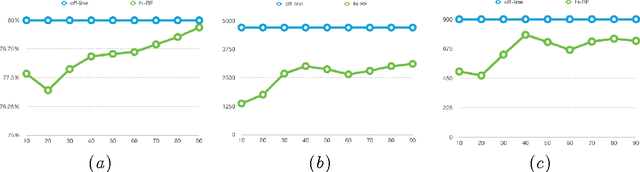
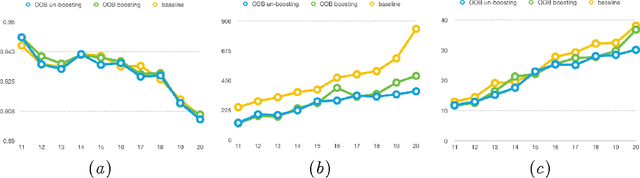
In recent years, dynamically growing data and incrementally growing number of classes pose new challenges to large-scale data classification research. Most traditional methods struggle to balance the precision and computational burden when data and its number of classes increased. However, some methods are with weak precision, and the others are time-consuming. In this paper, we propose an incremental learning method, namely, heterogeneous incremental Nearest Class Mean Random Forest (hi-RF), to handle this issue. It is a heterogeneous method that either replaces trees or updates trees leaves in the random forest adaptively, to reduce the computational time in comparable performance, when data of new classes arrive. Specifically, to keep the accuracy, one proportion of trees are replaced by new NCM decision trees; to reduce the computational load, the rest trees are updated their leaves probabilities only. Most of all, out-of-bag estimation and out-of-bag boosting are proposed to balance the accuracy and the computational efficiency. Fair experiments were conducted and demonstrated its comparable precision with much less computational time.