 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaTr: Layout-Aware Transformer for Scene-Text VQA
Dec 24, 2021
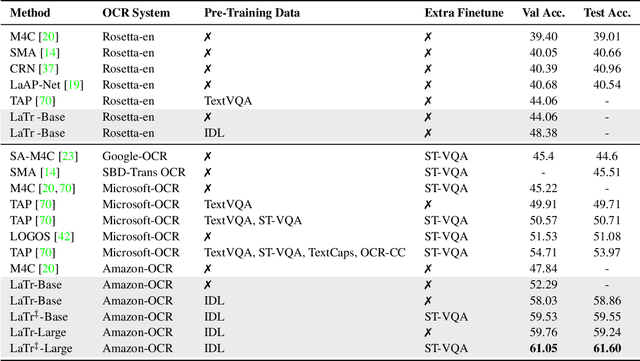
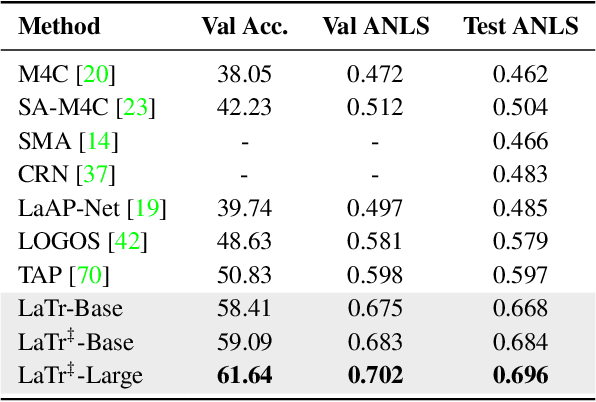
We propose a novel multimodal architecture for Scene Text Visual Question Answering (STVQA), named Layout-Aware Transformer (LaTr). The task of STVQA requires models to reason over different modalities. Thus, we first investigate the impact of each modality, and reveal the importance of the language module, especially when enriched with layout information. Accounting for this, we propose a single objective pre-training scheme that requires only text and spatial cues. We show that applying this pre-training scheme on scanned documents has certain advantages over using natural images, despite the domain gap. Scanned documents are easy to procure, text-dense and have a variety of layouts, helping the model learn various spatial cues (e.g. left-of, below etc.) by tying together language and layout information. Compared to existing approaches, our method performs vocabulary-free decoding and, as shown, generalizes well beyond the training vocabulary. We further demonstrate that LaTr improves robustness towards OCR errors, a common reason for failure cases in STVQA. In addition, by leveraging a vision transformer, we eliminate the need for an external object detector. LaTr outperforms state-of-the-art STVQA methods on multiple datasets. In particular, +7.6% on TextVQA, +10.8% on ST-VQA and +4.0% on OCR-VQA (all absolute accuracy numbers).
TransFusion: Cross-view Fusion with Transformer for 3D Human Pose Estimation
Oct 29, 2021
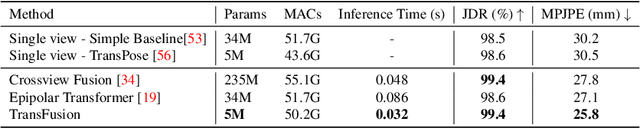
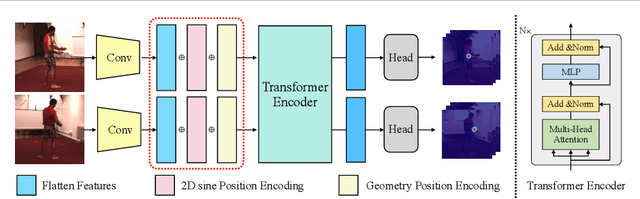

Estimating the 2D human poses in each view is typically the first step in calibrated multi-view 3D pose estimation. But the performance of 2D pose detectors suffers from challenging situations such as occlusions and oblique viewing angles. To address these challenges, previous works derive point-to-point correspondences between different views from epipolar geometry and utilize the correspondences to merge prediction heatmaps or feature representations. Instead of post-prediction merge/calibration, here we introduce a transformer framework for multi-view 3D pose estimation, aiming at directly improving individual 2D predictors by integrating information from different views. Inspired by previous multi-modal transformers, we design a unified transformer architecture, named TransFusion, to fuse cues from both current views and neighboring views. Moreover, we propose the concept of epipolar field to encode 3D positional information into the transformer model. The 3D position encoding guided by the epipolar field provides an efficient way of encoding correspondences between pixels of different views. Experiments on Human 3.6M and Ski-Pose show that our method is more efficient and has consistent improvements compared to other fusion methods. Specifically, we achieve 25.8 mm MPJPE on Human 3.6M with only 5M parameters on 256 x 256 resolution.
DocFormer: End-to-End Transformer for Document Understanding
Jun 22, 2021We present DocFormer -- a multi-modal transformer based architecture for the task of Visual Document Understanding (VDU). VDU is a challenging problem which aims to understand documents in their varied formats (forms, receipts etc.) and layouts. In addition, DocFormer is pre-trained in an unsupervised fashion using carefully designed tasks which encourage multi-modal interaction. DocFormer uses text, vision and spatial features and combines them using a novel multi-modal self-attention layer. DocFormer also shares learned spatial embeddings across modalities which makes it easy for the model to correlate text to visual tokens and vice versa. DocFormer is evaluated on 4 different datasets each with strong baselines. DocFormer achieves state-of-the-art results on all of them, sometimes beating models 4x its size (in no. of parameters).
MVHM: A Large-Scale Multi-View Hand Mesh Benchmark for Accurate 3D Hand Pose Estimation
Dec 06, 2020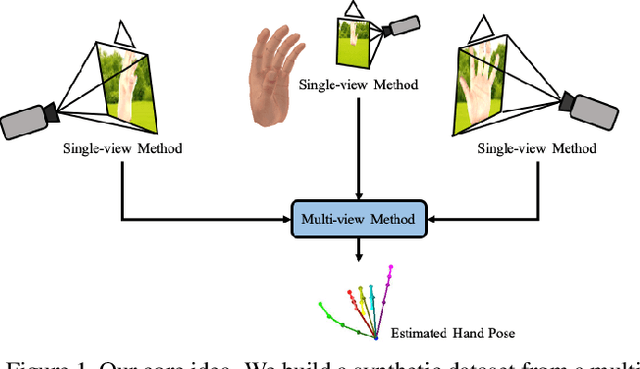
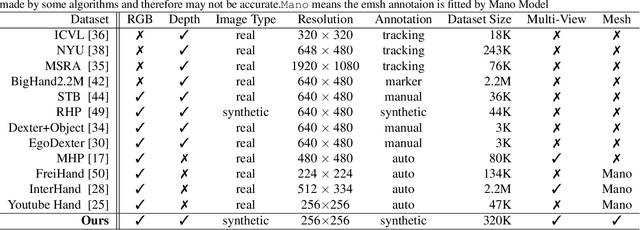
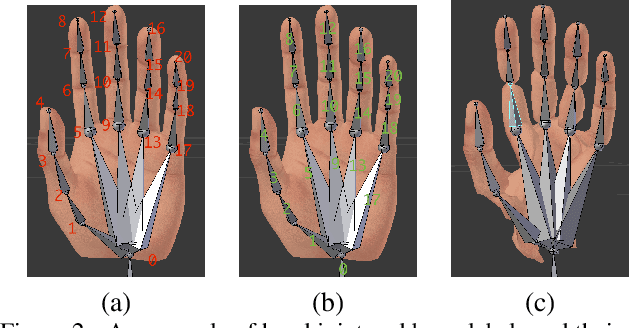
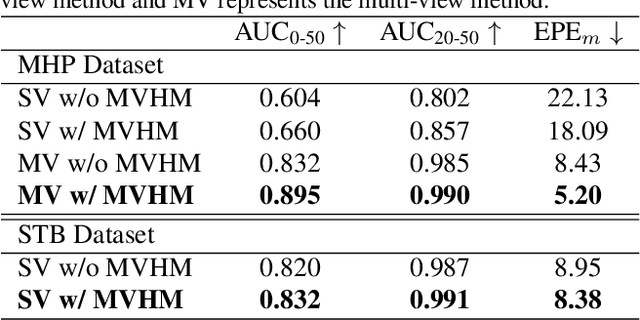
Estimating 3D hand poses from a single RGB image is challenging because depth ambiguity leads the problem ill-posed. Training hand pose estimators with 3D hand mesh annotations and multi-view images often results in significant performance gains. However, existing multi-view datasets are relatively small with hand joints annotated by off-the-shelf trackers or automated through model predictions, both of which may be inaccurate and can introduce biases. Collecting a large-scale multi-view 3D hand pose images with accurate mesh and joint annotations is valuable but strenuous. In this paper, we design a spin match algorithm that enables a rigid mesh model matching with any target mesh ground truth. Based on the match algorithm, we propose an efficient pipeline to generate a large-scale multi-view hand mesh (MVHM) dataset with accurate 3D hand mesh and joint labels. We further present a multi-view hand pose estimation approach to verify that training a hand pose estimator with our generated dataset greatly enhances the performance. Experimental results show that our approach achieves the performance of 0.990 in $\text{AUC}_{\text{20-50}}$ on the MHP dataset compared to the previous state-of-the-art of 0.939 on this dataset. Our datasset is public available. \footnote{\url{https://github.com/Kuzphi/MVHM}} Our datasset is available at~\href{https://github.com/Kuzphi/MVHM}{\color{blue}{https://github.com/Kuzphi/MVHM}}.
Temporal-Aware Self-Supervised Learning for 3D Hand Pose and Mesh Estimation in Videos
Dec 06, 2020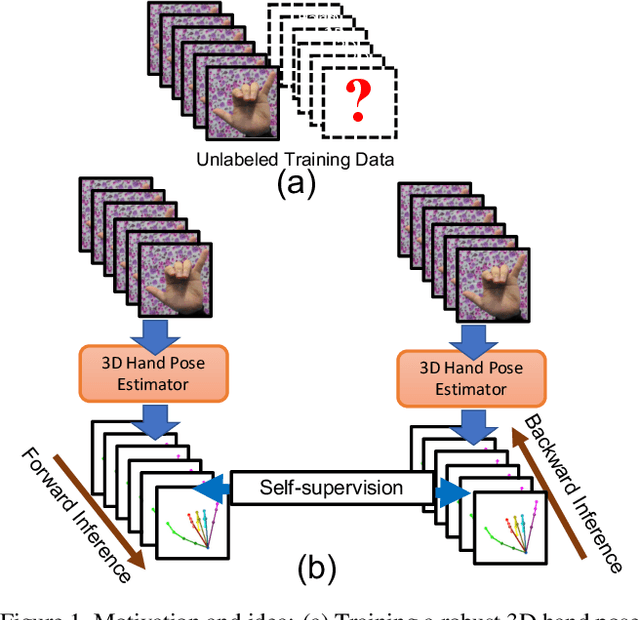
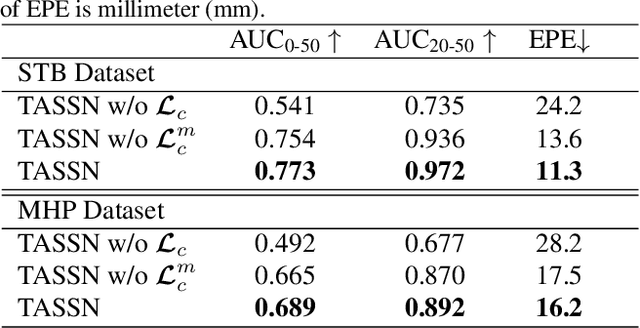
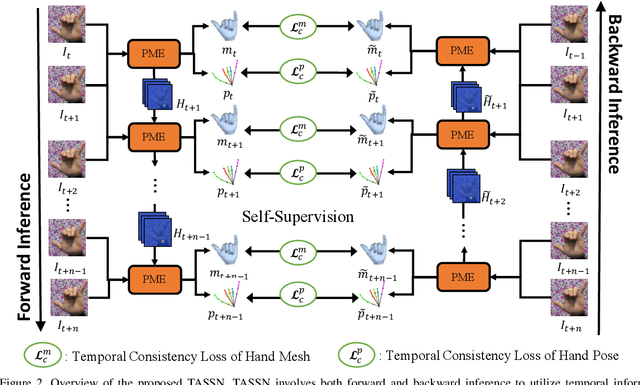
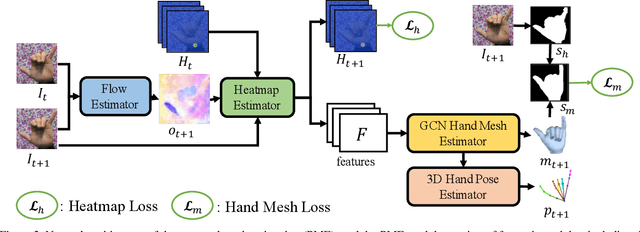
Estimating 3D hand pose directly from RGB imagesis challenging but has gained steady progress recently bytraining deep models with annotated 3D poses. Howeverannotating 3D poses is difficult and as such only a few 3Dhand pose datasets are available, all with limited samplesizes. In this study, we propose a new framework of training3D pose estimation models from RGB images without usingexplicit 3D annotations, i.e., trained with only 2D informa-tion. Our framework is motivated by two observations: 1)Videos provide richer information for estimating 3D posesas opposed to static images; 2) Estimated 3D poses oughtto be consistent whether the videos are viewed in the for-ward order or reverse order. We leverage these two obser-vations to develop a self-supervised learning model calledtemporal-aware self-supervised network (TASSN). By en-forcing temporal consistency constraints, TASSN learns 3Dhand poses and meshes from videos with only 2D keypointposition annotations. Experiments show that our modelachieves surprisingly good results, with 3D estimation ac-curacy on par with the state-of-the-art models trained with3D annotations, highlighting the benefit of the temporalconsistency in constraining 3D prediction models.
DGGAN: Depth-image Guided Generative Adversarial Networks for Disentangling RGB and Depth Images in 3D Hand Pose Estimation
Dec 06, 2020
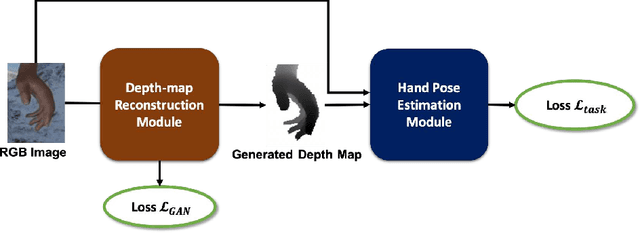
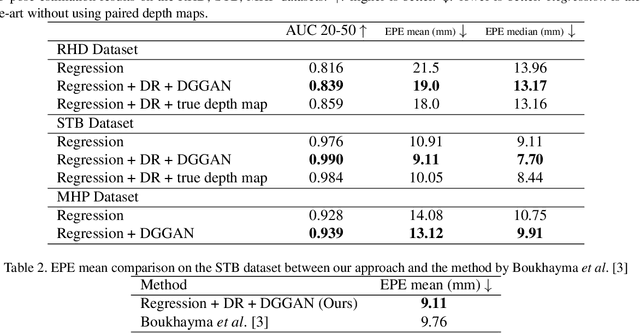
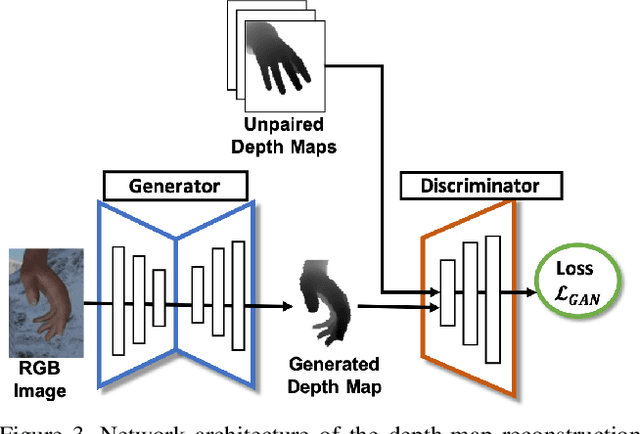
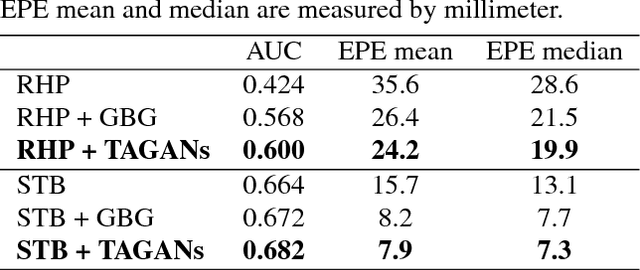
Estimating3D hand poses from RGB images is essentialto a wide range of potential applications, but is challengingowing to substantial ambiguity in the inference of depth in-formation from RGB images. State-of-the-art estimators ad-dress this problem by regularizing3D hand pose estimationmodels during training to enforce the consistency betweenthe predicted3D poses and the ground-truth depth maps.However, these estimators rely on both RGB images and thepaired depth maps during training. In this study, we proposea conditional generative adversarial network (GAN) model,called Depth-image Guided GAN (DGGAN), to generate re-alistic depth maps conditioned on the input RGB image, anduse the synthesized depth maps to regularize the3D handpose estimation model, therefore eliminating the need forground-truth depth maps. Experimental results on multiplebenchmark datasets show that the synthesized depth mapsproduced by DGGAN are quite effective in regularizing thepose estimation model, yielding new state-of-the-art resultsin estimation accuracy, notably reducing the mean3D end-point errors (EPE) by4.7%,16.5%, and6.8%on the RHD,STB and MHP datasets, respectively.
Towards Good Practices in Self-supervised Representation Learning
Dec 01, 2020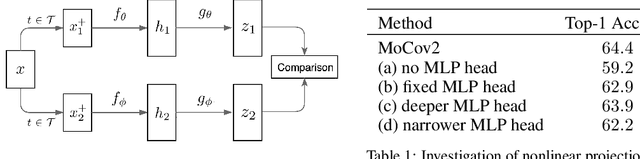

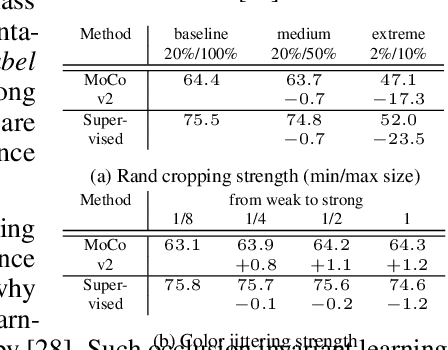

Self-supervised representation learning has seen remarkable progress in the last few years. More recently, contrastive instance learning has shown impressive results compared to its supervised learning counterparts. However, even with the ever increased interest in contrastive instance learning, it is still largely unclear why these methods work so well. In this paper, we aim to unravel some of the mysteries behind their success, which are the good practices. Through an extensive empirical analysis, we hope to not only provide insights but also lay out a set of best practices that led to the success of recent work in self-supervised representation learning.
MM-Hand: 3D-Aware Multi-Modal Guided Hand Generative Network for 3D Hand Pose Synthesis
Oct 02, 2020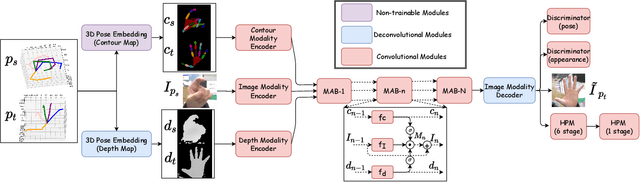
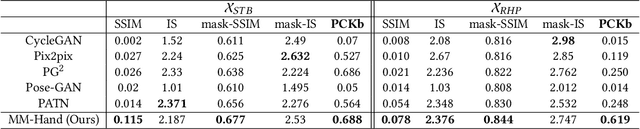
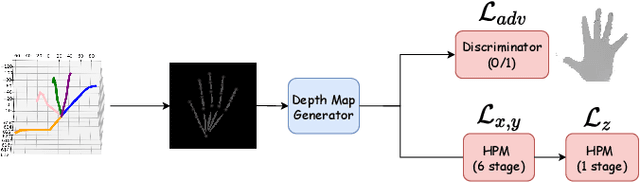
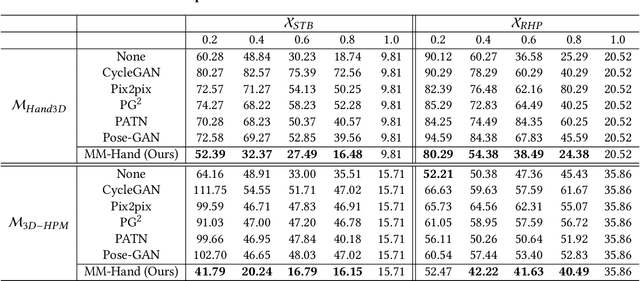
Estimating the 3D hand pose from a monocular RGB image is important but challenging. A solution is training on large-scale RGB hand images with accurate 3D hand keypoint annotations. However, it is too expensive in practice. Instead, we have developed a learning-based approach to synthesize realistic, diverse, and 3D pose-preserving hand images under the guidance of 3D pose information. We propose a 3D-aware multi-modal guided hand generative network (MM-Hand), together with a novel geometry-based curriculum learning strategy. Our extensive experimental results demonstrate that the 3D-annotated images generated by MM-Hand qualitatively and quantitatively outperform existing options. Moreover, the augmented data can consistently improve the quantitative performance of the state-of-the-art 3D hand pose estimators on two benchmark datasets. The code will be available at https://github.com/ScottHoang/mm-hand.
Generating Realistic Training Images Based on Tonality-Alignment Generative Adversarial Networks for Hand Pose Estimation
Nov 27, 2018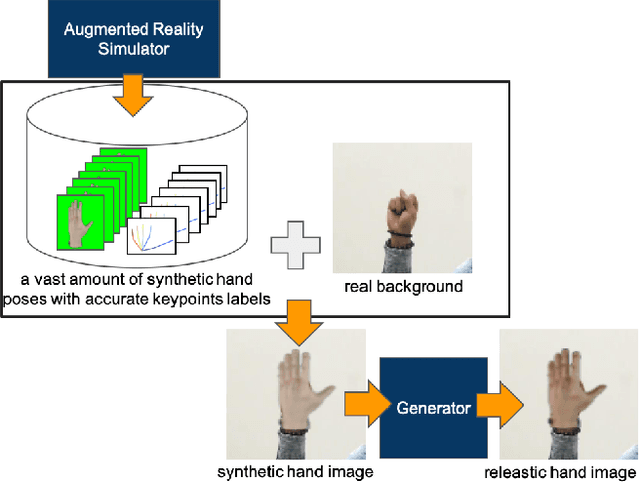
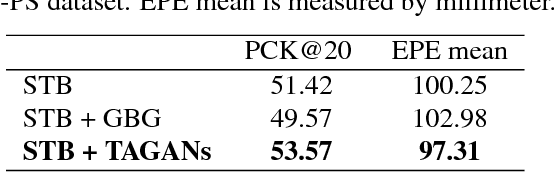

Hand pose estimation from a monocular RGB image is an important but challenging task. The main factor affecting its performance is the lack of a sufficiently large training dataset with accurate hand-keypoint annotations. In this work, we circumvent this problem by proposing an effective method for generating realistic hand poses and show that state-of-the-art algorithms for hand pose estimation can be greatly improved by utilizing the generated hand poses as training data. Specifically, we first adopt an augmented reality (AR) simulator to synthesize hand poses with accurate hand-keypoint labels. Although the synthetic hand poses come with precise joint labels, eliminating the need of manual annotations, they look unnatural and are not the ideal training data. To produce more realistic hand poses, we propose to blend a synthetic hand pose with a real background, such as arms and sleeves. To this end, we develop tonality-alignment generative adversarial networks (TAGANs), which align the tonality and color distributions between synthetic hand poses and real backgrounds, and can generate high quality hand poses. We evaluate TAGAN on three benchmarks, including the RHP, STB, and CMU-PS hand pose datasets. With the aid of the synthesized poses, our method performs favorably against the state-of-the-arts in both $2$D and $3$D hand pose estimations.
On the Generation of Medical Question-Answer Pairs
Nov 01, 2018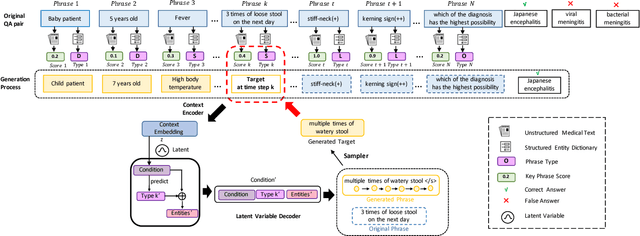
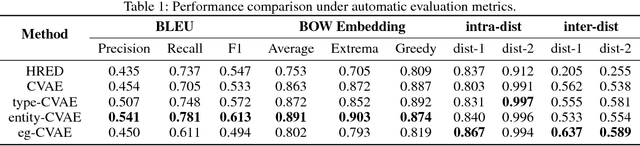
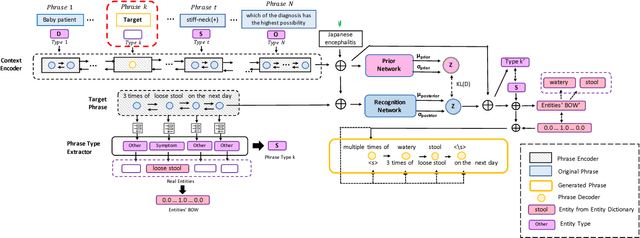
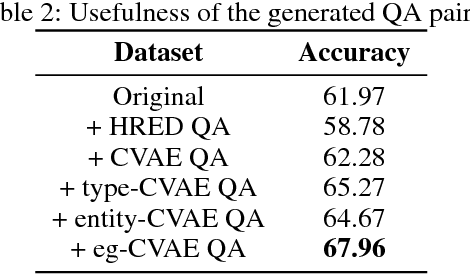
Question answering (QA) has achieved promising progress recently. However, answering a question in real-world scenarios like the medical domain is still challenging, due to the requirement of external knowledge and the insufficient of high-quality training data. In the light of these challenges, we study the task of generating medical QA pairs in this paper. With the insight that each medical question can be considered as a sample from the latent distribution conditioned on the corresponding answer, we propose an automated medical QA pair generation framework, consisting of an unsupervised key phrase detector that explores unstructured material for validity, and a generator that involves multi-pass decoder to integrate with structural knowledge for diversity. Series of experiments have been conducted on a real-world dataset collected from the National Medical Licensing Examination of China. Both automatic evaluation and human annotation demonstrate the effectiveness of the proposed method. Further investigation shows that, by incorporating the generated QA pairs for training, significant improvement in terms of accuracy can be achieved for the examination QA system.