 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiftVideo: A Unified Framework for Few-Step Video Generation through Trajectory-Distribution Alignment
Aug 08, 2025Diffusion-based or flow-based models have achieved significant progress in video synthesis but require multiple iterative sampling steps, which incurs substantial computational overhead. While many distillation methods that are solely based on trajectory-preserving or distribution-matching have been developed to accelerate video generation models, these approaches often suffer from performance breakdown or increased artifacts under few-step settings. To address these limitations, we propose \textbf{\emph{SwiftVideo}}, a unified and stable distillation framework that combines the advantages of trajectory-preserving and distribution-matching strategies. Our approach introduces continuous-time consistency distillation to ensure precise preservation of ODE trajectories. Subsequently, we propose a dual-perspective alignment that includes distribution alignment between synthetic and real data along with trajectory alignment across different inference steps. Our method maintains high-quality video generation while substantially reducing the number of inference steps. Quantitative evaluations on the OpenVid-1M benchmark demonstrate that our method significantly outperforms existing approaches in few-step video generation.
MoCHA: Advanced Vision-Language Reasoning with MoE Connector and Hierarchical Group Attention
Jul 30, 2025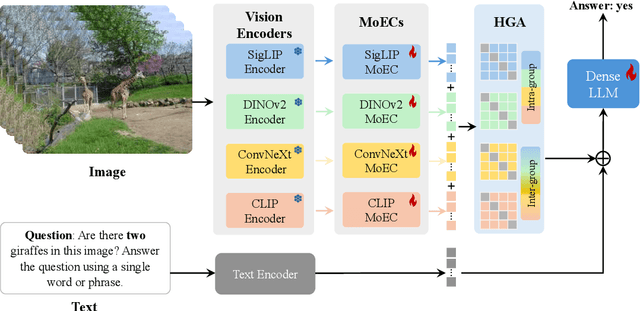
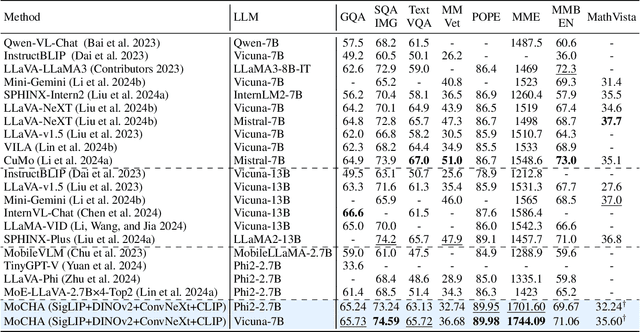
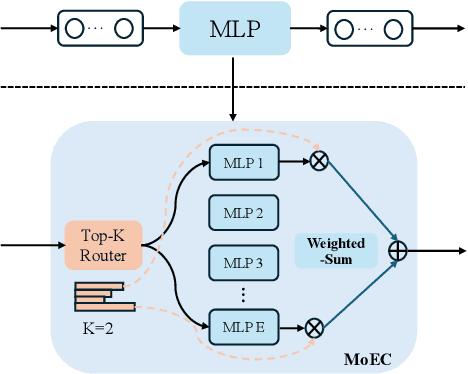
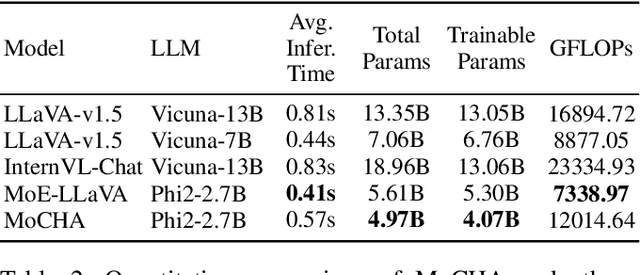
Vision large language models (VLLMs) are focusing primarily on handling complex and fine-grained visual information by incorporating advanced vision encoders and scaling up visual models. However, these approaches face high training and inference costs, as well as challenges in extracting visual details, effectively bridging across modalities. In this work, we propose a novel visual framework, MoCHA, to address these issues. Our framework integrates four vision backbones (i.e., CLIP, SigLIP, DINOv2 and ConvNeXt) to extract complementary visual features and is equipped with a sparse Mixture of Experts Connectors (MoECs) module to dynamically select experts tailored to different visual dimensions. To mitigate redundant or insufficient use of the visual information encoded by the MoECs module, we further design a Hierarchical Group Attention (HGA) with intra- and inter-group operations and an adaptive gating strategy for encoded visual features. We train MoCHA on two mainstream LLMs (e.g., Phi2-2.7B and Vicuna-7B) and evaluate their performance across various benchmarks. Notably, MoCHA outperforms state-of-the-art open-weight models on various tasks. For example, compared to CuMo (Mistral-7B), our MoCHA (Phi2-2.7B) presents outstanding abilities to mitigate hallucination by showing improvements of 3.25% in POPE and to follow visual instructions by raising 153 points on MME. Finally, ablation studies further confirm the effectiveness and robustness of the proposed MoECs and HGA in improving the overall performance of MoCHA.
Swin DiT: Diffusion Transformer using Pseudo Shifted Windows
May 19, 2025Diffusion Transformers (DiTs) achieve remarkable performance within the domain of image generation through the incorporation of the transformer architecture. Conventionally, DiTs are constructed by stacking serial isotropic global information modeling transformers, which face significant computational cost when processing high-resolution images. We empirically analyze that latent space image generation does not exhibit a strong dependence on global information as traditionally assumed. Most of the layers in the model demonstrate redundancy in global computation. In addition, conventional attention mechanisms exhibit low-frequency inertia issues. To address these issues, we propose \textbf{P}seudo \textbf{S}hifted \textbf{W}indow \textbf{A}ttention (PSWA), which fundamentally mitigates global model redundancy. PSWA achieves intermediate global-local information interaction through window attention, while employing a high-frequency bridging branch to simulate shifted window operations, supplementing appropriate global and high-frequency information. Furthermore, we propose the Progressive Coverage Channel Allocation(PCCA) strategy that captures high-order attention similarity without additional computational cost. Building upon all of them, we propose a series of Pseudo \textbf{S}hifted \textbf{Win}dow DiTs (\textbf{Swin DiT}), accompanied by extensive experiments demonstrating their superior performance. For example, our proposed Swin-DiT-L achieves a 54%$\uparrow$ FID improvement over DiT-XL/2 while requiring less computational. https://github.com/wujiafu007/Swin-DiT
Can GPT tell us why these images are synthesized? Empowering Multimodal Large Language Models for Forensics
Apr 16, 2025The rapid development of generative AI facilitates content creation and makes image manipulation easier and more difficult to detect. While multimodal Large Language Models (LLMs) have encoded rich world knowledge, they are not inherently tailored for combating AI-generated Content (AIGC) and struggle to comprehend local forgery details. In this work, we investigate the application of multimodal LLMs in forgery detection. We propose a framework capable of evaluating image authenticity, localizing tampered regions, providing evidence, and tracing generation methods based on semantic tampering clues. Our method demonstrates that the potential of LLMs in forgery analysis can be effectively unlocked through meticulous prompt engineering and the application of few-shot learning techniques. We conduct qualitative and quantitative experiments and show that GPT4V can achieve an accuracy of 92.1% in Autosplice and 86.3% in LaMa, which is competitive with state-of-the-art AIGC detection methods. We further discuss the limitations of multimodal LLMs in such tasks and propose potential improvements.
DisentTalk: Cross-lingual Talking Face Generation via Semantic Disentangled Diffusion Model
Mar 24, 2025



Recent advances in talking face generation have significantly improved facial animation synthesis. However, existing approaches face fundamental limitations: 3DMM-based methods maintain temporal consistency but lack fine-grained regional control, while Stable Diffusion-based methods enable spatial manipulation but suffer from temporal inconsistencies. The integration of these approaches is hindered by incompatible control mechanisms and semantic entanglement of facial representations. This paper presents DisentTalk, introducing a data-driven semantic disentanglement framework that decomposes 3DMM expression parameters into meaningful subspaces for fine-grained facial control. Building upon this disentangled representation, we develop a hierarchical latent diffusion architecture that operates in 3DMM parameter space, integrating region-aware attention mechanisms to ensure both spatial precision and temporal coherence. To address the scarcity of high-quality Chinese training data, we introduce CHDTF, a Chinese high-definition talking face dataset. Extensive experiments show superior performance over existing methods across multiple metrics, including lip synchronization, expression quality, and temporal consistency. Project Page: https://kangweiiliu.github.io/DisentTalk.
PixelPonder: Dynamic Patch Adaptation for Enhanced Multi-Conditional Text-to-Image Generation
Mar 09, 2025Recent advances in diffusion-based text-to-image generation have demonstrated promising results through visual condition control. However, existing ControlNet-like methods struggle with compositional visual conditioning - simultaneously preserving semantic fidelity across multiple heterogeneous control signals while maintaining high visual quality, where they employ separate control branches that often introduce conflicting guidance during the denoising process, leading to structural distortions and artifacts in generated images. To address this issue, we present PixelPonder, a novel unified control framework, which allows for effective control of multiple visual conditions under a single control structure. Specifically, we design a patch-level adaptive condition selection mechanism that dynamically prioritizes spatially relevant control signals at the sub-region level, enabling precise local guidance without global interference. Additionally, a time-aware control injection scheme is deployed to modulate condition influence according to denoising timesteps, progressively transitioning from structural preservation to texture refinement and fully utilizing the control information from different categories to promote more harmonious image generation. Extensive experiments demonstrate that PixelPonder surpasses previous methods across different benchmark datasets, showing superior improvement in spatial alignment accuracy while maintaining high textual semantic consistency.
Language Models Can See Better: Visual Contrastive Decoding For LLM Multimodal Reasoning
Feb 17, 2025Although Large Language Models (LLMs) excel in reasoning and generation for language tasks, they are not specifically designed for multimodal challenges. Training Multimodal Large Language Models (MLLMs), however, is resource-intensive and constrained by various training limitations. In this paper, we propose the Modular-based Visual Contrastive Decoding (MVCD) framework to move this obstacle. Our framework leverages LLMs' In-Context Learning (ICL) capability and the proposed visual contrastive-example decoding (CED), specifically tailored for this framework, without requiring any additional training. By converting visual signals into text and focusing on contrastive output distributions during decoding, we can highlight the new information introduced by contextual examples, explore their connections, and avoid over-reliance on prior encoded knowledge. MVCD enhances LLMs' visual perception to make it see and reason over the input visuals. To demonstrate MVCD's effectiveness, we conduct experiments with four LLMs across five question answering datasets. Our results not only show consistent improvement in model accuracy but well explain the effective components inside our decoding strategy. Our code will be available at https://github.com/Pbhgit/MVCD.
VI3DRM:Towards meticulous 3D Reconstruction from Sparse Views via Photo-Realistic Novel View Synthesis
Sep 12, 2024



Recently, methods like Zero-1-2-3 have focused on single-view based 3D reconstruction and have achieved remarkable success. However, their predictions for unseen areas heavily rely on the inductive bias of large-scale pretrained diffusion models. Although subsequent work, such as DreamComposer, attempts to make predictions more controllable by incorporating additional views, the results remain unrealistic due to feature entanglement in the vanilla latent space, including factors such as lighting, material, and structure. To address these issues, we introduce the Visual Isotropy 3D Reconstruction Model (VI3DRM), a diffusion-based sparse views 3D reconstruction model that operates within an ID consistent and perspective-disentangled 3D latent space. By facilitating the disentanglement of semantic information, color, material properties and lighting, VI3DRM is capable of generating highly realistic images that are indistinguishable from real photographs. By leveraging both real and synthesized images, our approach enables the accurate construction of pointmaps, ultimately producing finely textured meshes or point clouds. On the NVS task, tested on the GSO dataset, VI3DRM significantly outperforms state-of-the-art method DreamComposer, achieving a PSNR of 38.61, an SSIM of 0.929, and an LPIPS of 0.027. Code will be made available upon publication.
VividPose: Advancing Stable Video Diffusion for Realistic Human Image Animation
May 28, 2024



Human image animation involves generating a video from a static image by following a specified pose sequence. Current approaches typically adopt a multi-stage pipeline that separately learns appearance and motion, which often leads to appearance degradation and temporal inconsistencies. To address these issues, we propose VividPose, an innovative end-to-end pipeline based on Stable Video Diffusion (SVD) that ensures superior temporal stability. To enhance the retention of human identity, we propose an identity-aware appearance controller that integrates additional facial information without compromising other appearance details such as clothing texture and background. This approach ensures that the generated videos maintain high fidelity to the identity of human subject, preserving key facial features across various poses. To accommodate diverse human body shapes and hand movements, we introduce a geometry-aware pose controller that utilizes both dense rendering maps from SMPL-X and sparse skeleton maps. This enables accurate alignment of pose and shape in the generated videos, providing a robust framework capable of handling a wide range of body shapes and dynamic hand movements. Extensive qualitative and quantitative experiments on the UBCFashion and TikTok benchmarks demonstrate that our method achieves state-of-the-art performance. Furthermore, VividPose exhibits superior generalization capabilities on our proposed in-the-wild dataset. Codes and models will be available.
UVL: A Unified Framework for Video Tampering Localization
Sep 28, 2023



With the development of deep learning technology, various forgery methods emerge endlessly. Meanwhile, methods to detect these fake videos have also achieved excellent performance on some datasets. However, these methods suffer from poor generalization to unknown videos and are inefficient for new forgery methods. To address this challenging problem, we propose UVL, a novel unified video tampering localization framework for synthesizing forgeries. Specifically, UVL extracts common features of synthetic forgeries: boundary artifacts of synthetic edges, unnatural distribution of generated pixels, and noncorrelation between the forgery region and the original. These features are widely present in different types of synthetic forgeries and help improve generalization for detecting unknown videos. Extensive experiments on three types of synthetic forgery: video inpainting, video splicing and DeepFake show that the proposed UVL achieves state-of-the-art performance on various benchmarks and outperforms existing methods by a large margin on cross-dataset.