 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearchGCN: Powering Embedding Retrieval by Graph Convolution Networks for E-Commerce Search
Jul 01, 2021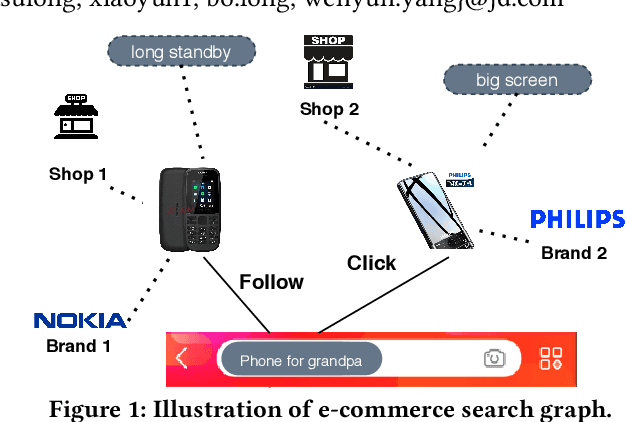
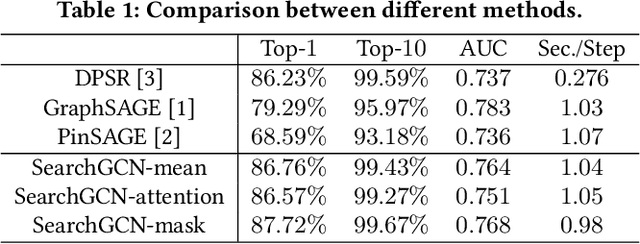
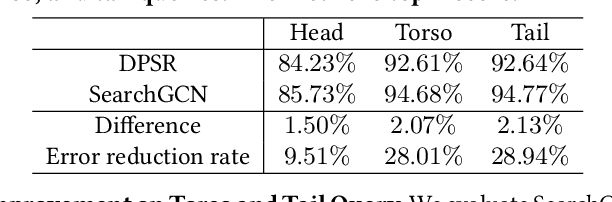
Graph convolution networks (GCN), which recently becomes new state-of-the-art method for graph node classification, recommendation and other applications, has not been successfully applied to industrial-scale search engine yet. In this proposal, we introduce our approach, namely SearchGCN, for embedding-based candidate retrieval in one of the largest e-commerce search engine in the world. Empirical studies demonstrate that SearchGCN learns better embedding representations than existing methods, especially for long tail queries and items. Thus, SearchGCN has been deployed into JD.com's search production since July 2020.
Joint Learning of Deep Retrieval Model and Product Quantization based Embedding Index
May 28, 2021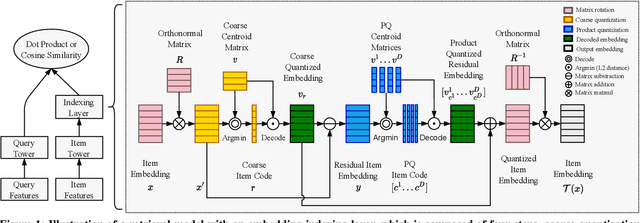
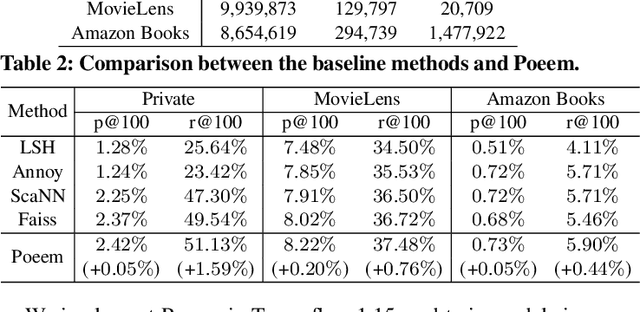
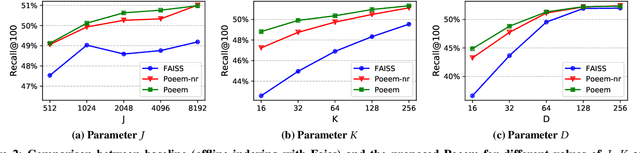
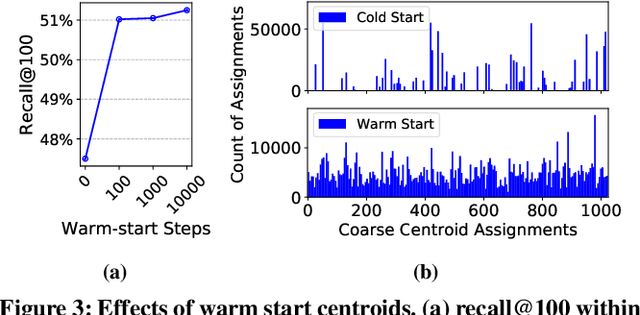
Embedding index that enables fast approximate nearest neighbor(ANN) search, serves as an indispensable component for state-of-the-art deep retrieval systems. Traditional approaches, often separating the two steps of embedding learning and index building, incur additional indexing time and decayed retrieval accuracy. In this paper, we propose a novel method called Poeem, which stands for product quantization based embedding index jointly trained with deep retrieval model, to unify the two separate steps within an end-to-end training, by utilizing a few techniques including the gradient straight-through estimator, warm start strategy, optimal space decomposition and Givens rotation. Extensive experimental results show that the proposed method not only improves retrieval accuracy significantly but also reduces the indexing time to almost none. We have open sourced our approach for the sake of comparison and reproducibility.
Person Search Challenges and Solutions: A Survey
May 01, 2021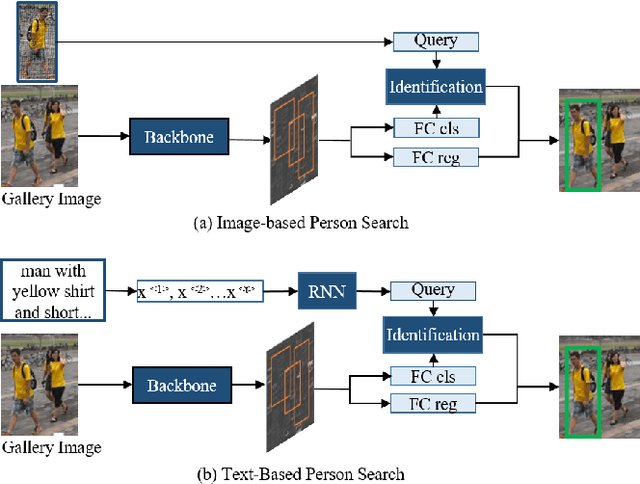
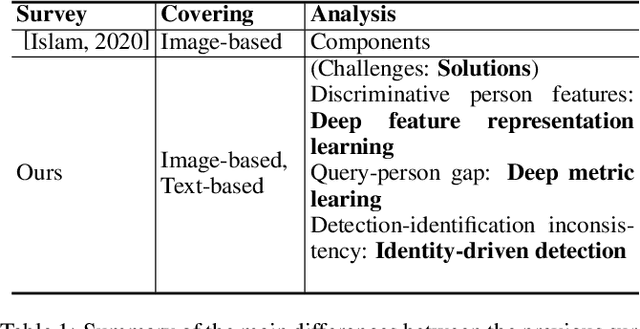


Person search has drawn increasing attention due to its real-world applications and research significance. Person search aims to find a probe person in a gallery of scene images with a wide range of applications, such as criminals search, multicamera tracking, missing person search, etc. Early person search works focused on image-based person search, which uses person image as the search query. Text-based person search is another major person search category that uses free-form natural language as the search query. Person search is challenging, and corresponding solutions are diverse and complex. Therefore, systematic surveys on this topic are essential. This paper surveyed the recent works on image-based and text-based person search from the perspective of challenges and solutions. Specifically, we provide a brief analysis of highly influential person search methods considering the three significant challenges: the discriminative person features, the query-person gap, and the detection-identification inconsistency. We summarise and compare evaluation results. Finally, we discuss open issues and some promising future research directions.
A unified Neural Network Approach to E-CommerceRelevance Learning
Apr 26, 2021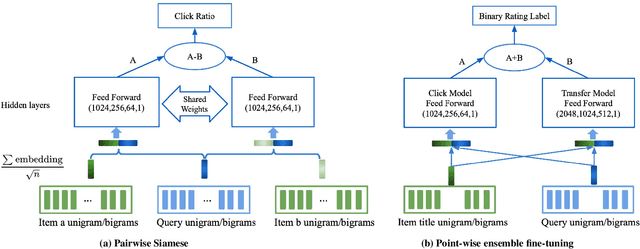



Result relevance scoring is critical to e-commerce search user experience. Traditional information retrieval methods focus on keyword matching and hand-crafted or counting-based numeric features, with limited understanding of item semantic relevance. We describe a highly-scalable feed-forward neural model to provide relevance score for (query, item) pairs, using only user query and item title as features, and both user click feedback as well as limited human ratings as labels. Several general enhancements were applied to further optimize eval/test metrics, including Siamese pairwise architecture, random batch negative co-training, and point-wise fine-tuning. We found significant improvement over GBDT baseline as well as several off-the-shelf deep-learning baselines on an independently constructed ratings dataset. The GBDT model relies on 10 times more features. We also present metrics for select subset combinations of techniques mentioned above.
* 6 pages
From Semantic Retrieval to Pairwise Ranking: Applying Deep Learning in E-commerce Search
Mar 24, 2021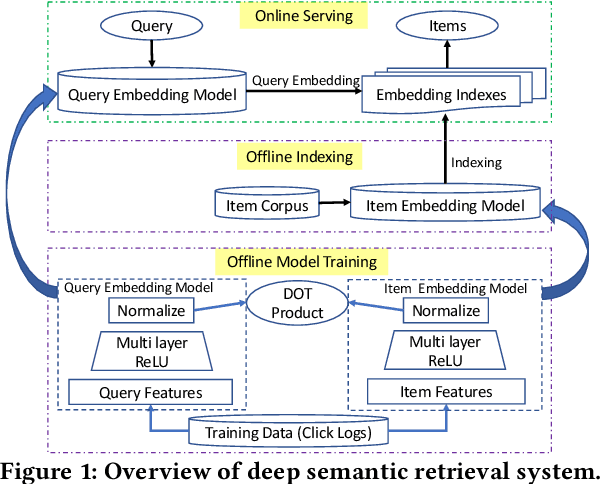
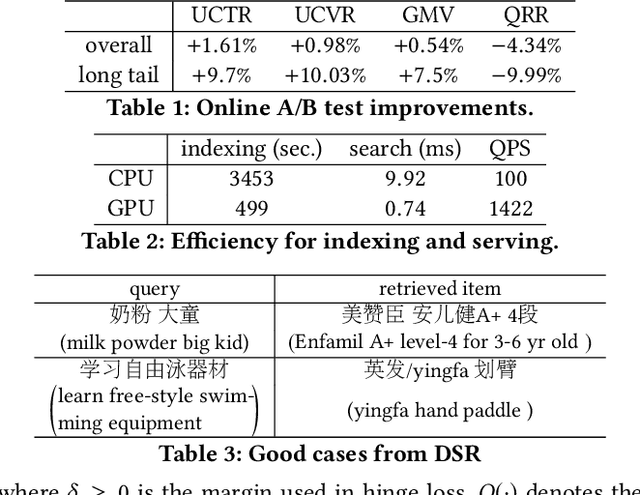
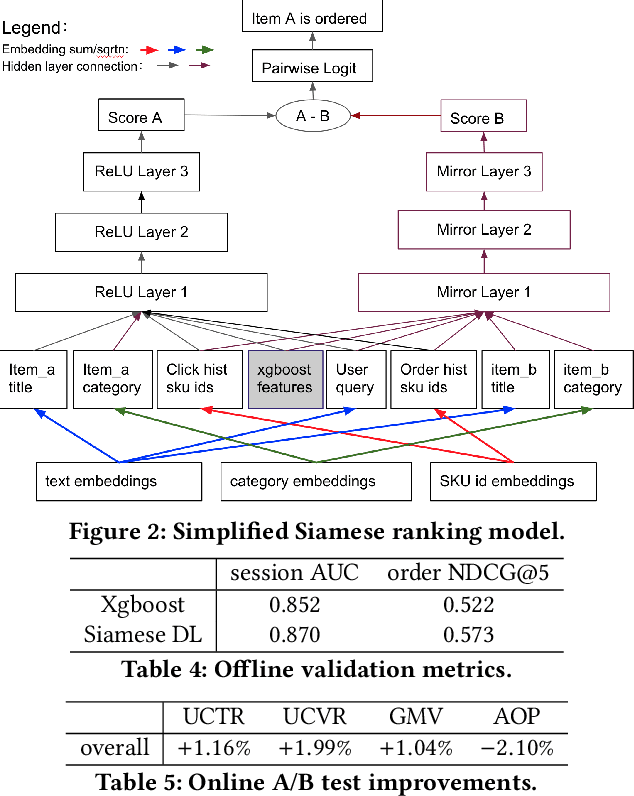
We introduce deep learning models to the two most important stages in product search at JD.com, one of the largest e-commerce platforms in the world. Specifically, we outline the design of a deep learning system that retrieves semantically relevant items to a query within milliseconds, and a pairwise deep re-ranking system, which learns subtle user preferences. Compared to traditional search systems, the proposed approaches are better at semantic retrieval and personalized ranking, achieving significant improvements.
NAS-TC: Neural Architecture Search on Temporal Convolutions for Complex Action Recognition
Mar 17, 2021
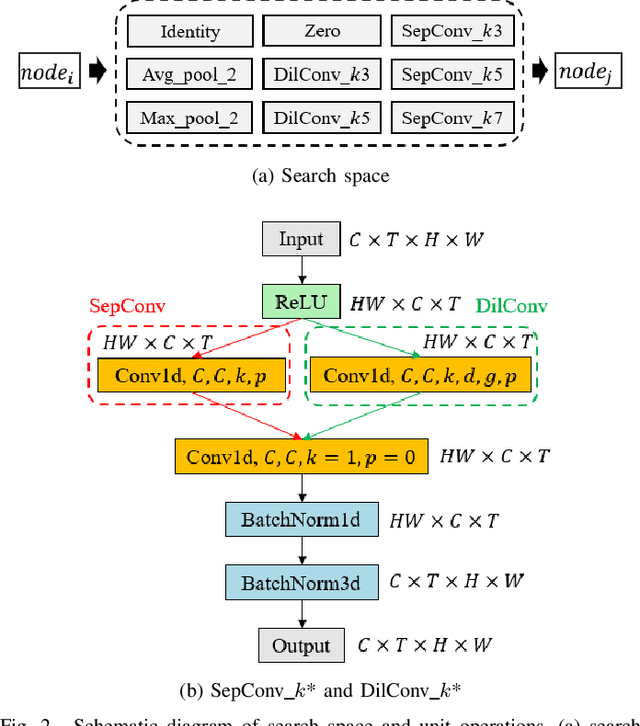
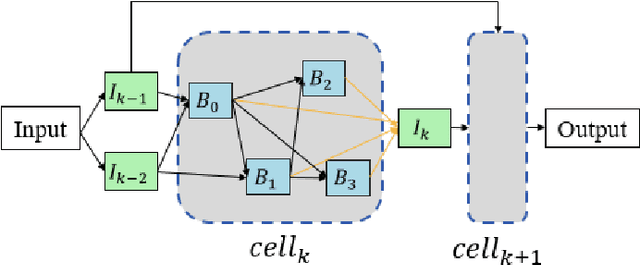
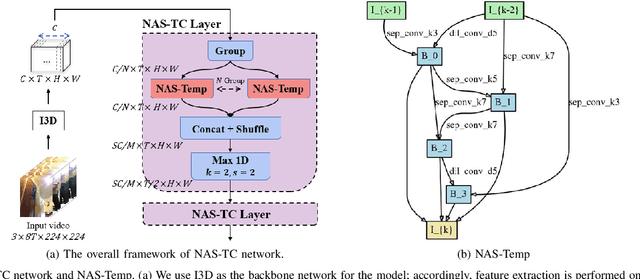
In the field of complex action recognition in videos, the quality of the designed model plays a crucial role in the final performance. However, artificially designed network structures often rely heavily on the researchers' knowledge and experience. Accordingly, because of the automated design of its network structure, Neural architecture search (NAS) has achieved great success in the image processing field and attracted substantial research attention in recent years. Although some NAS methods have reduced the number of GPU search days required to single digits in the image field, directly using 3D convolution to extend NAS to the video field is still likely to produce a surge in computing volume. To address this challenge, we propose a new processing framework called Neural Architecture Search- Temporal Convolutional (NAS-TC). Our proposed framework is divided into two phases. In the first phase, the classical CNN network is used as the backbone network to complete the computationally intensive feature extraction task. In the second stage, a simple stitching search to the cell is used to complete the relatively lightweight long-range temporal-dependent information extraction. This ensures our method will have more reasonable parameter assignments and can handle minute-level videos. Finally, we conduct sufficient experiments on multiple benchmark datasets and obtain competitive recognition accuracy.
Query Rewriting via Cycle-Consistent Translation for E-Commerce Search
Mar 01, 2021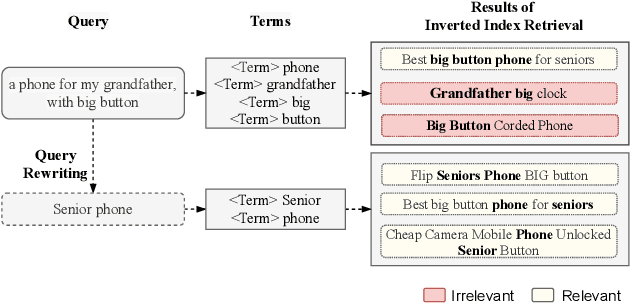
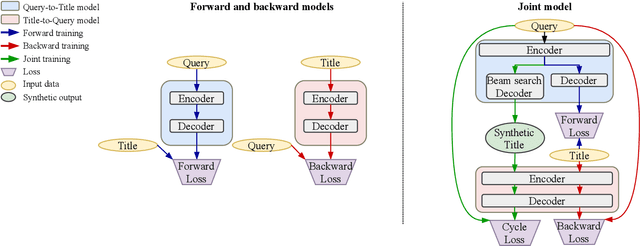

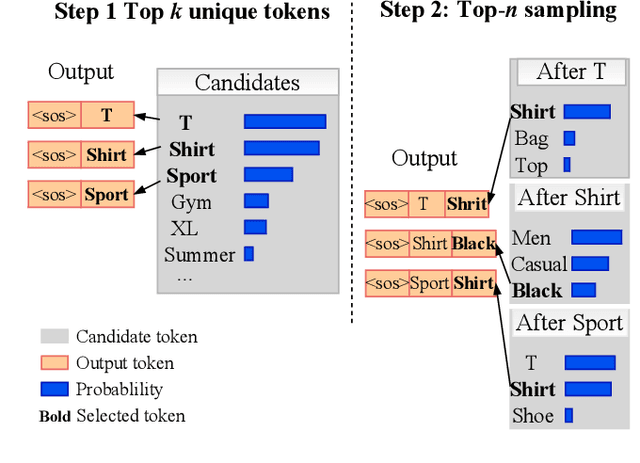
Nowadays e-commerce search has become an integral part of many people's shopping routines. One critical challenge in today's e-commerce search is the semantic matching problem where the relevant items may not contain the exact terms in the user query. In this paper, we propose a novel deep neural network based approach to query rewriting, in order to tackle this problem. Specifically, we formulate query rewriting into a cyclic machine translation problem to leverage abundant click log data. Then we introduce a novel cyclic consistent training algorithm in conjunction with state-of-the-art machine translation models to achieve the optimal performance in terms of query rewriting accuracy. In order to make it practical in industrial scenarios, we optimize the syntax tree construction to reduce computational cost and online serving latency. Offline experiments show that the proposed method is able to rewrite hard user queries into more standard queries that are more appropriate for the inverted index to retrieve. Comparing with human curated rule-based method, the proposed model significantly improves query rewriting diversity while maintaining good relevancy. Online A/B experiments show that it improves core e-commerce business metrics significantly. Since the summer of 2020, the proposed model has been launched into our search engine production, serving hundreds of millions of users.
BERT2DNN: BERT Distillation with Massive Unlabeled Data for Online E-Commerce Search
Oct 20, 2020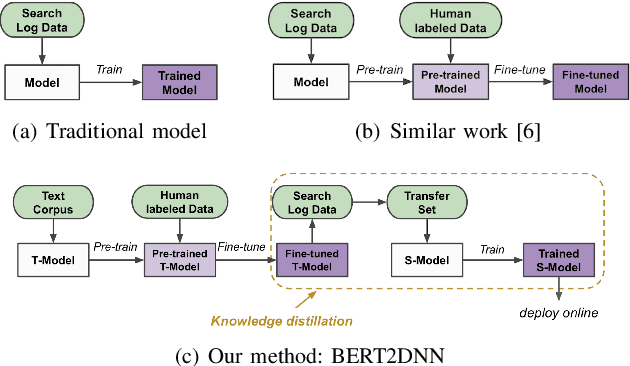

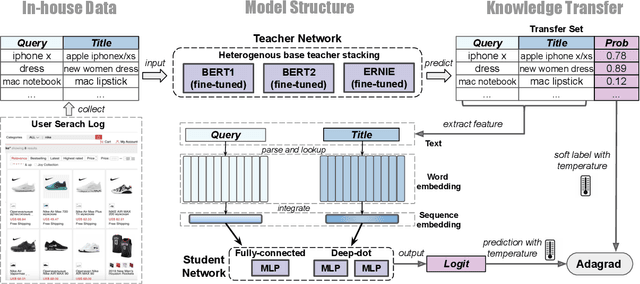
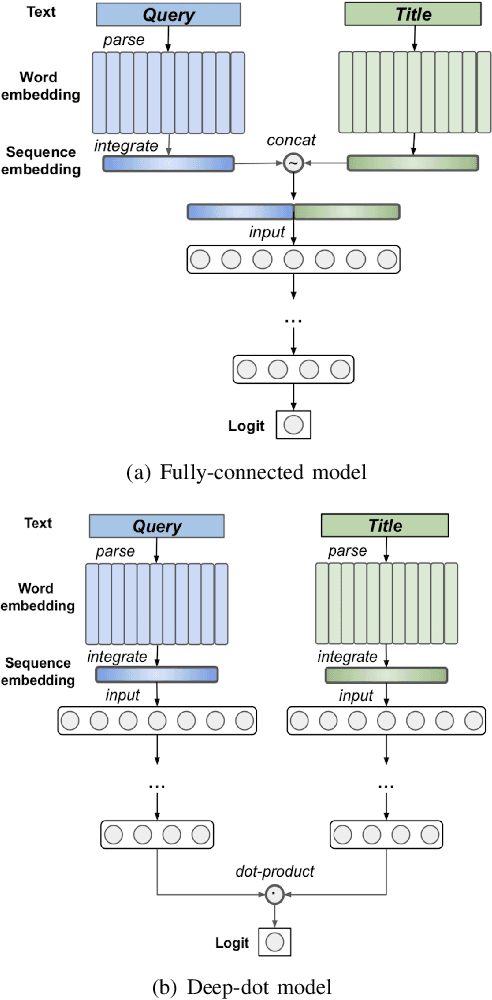
Relevance has significant impact on user experience and business profit for e-commerce search platform. In this work, we propose a data-driven framework for search relevance prediction, by distilling knowledge from BERT and related multi-layer Transformer teacher models into simple feed-forward networks with large amount of unlabeled data. The distillation process produces a student model that recovers more than 97\% test accuracy of teacher models on new queries, at a serving cost that's several magnitude lower (latency 150x lower than BERT-Base and 15x lower than the most efficient BERT variant, TinyBERT). The applications of temperature rescaling and teacher model stacking further boost model accuracy, without increasing the student model complexity. We present experimental results on both in-house e-commerce search relevance data as well as a public data set on sentiment analysis from the GLUE benchmark. The latter takes advantage of another related public data set of much larger scale, while disregarding its potentially noisy labels. Embedding analysis and case study on the in-house data further highlight the strength of the resulting model. By making the data processing and model training source code public, we hope the techniques presented here can help reduce energy consumption of the state of the art Transformer models and also level the playing field for small organizations lacking access to cutting edge machine learning hardwares.
A Survey of Deep Active Learning
Aug 30, 2020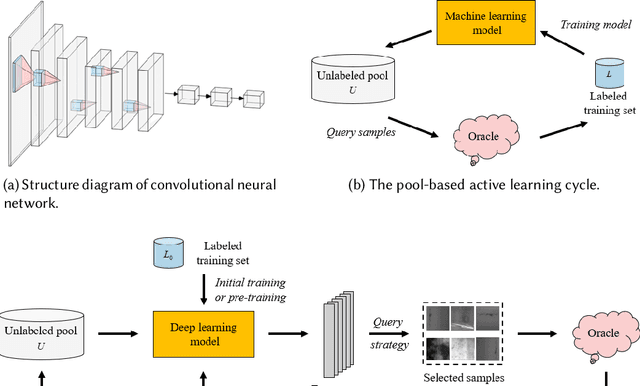
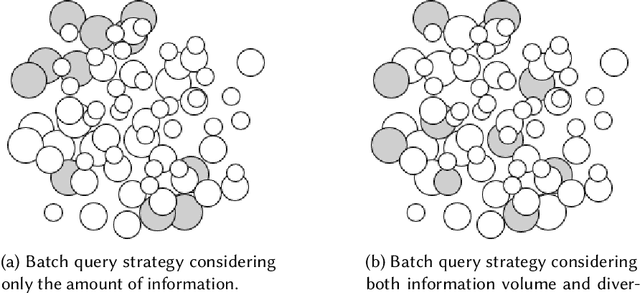
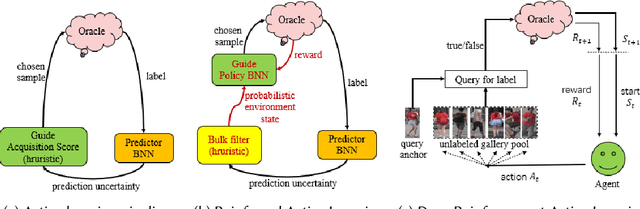
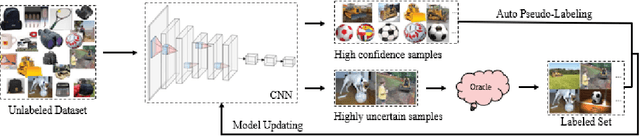
Active learning (AL) attempts to maximize the performance gain of the model by marking the fewest samples. Deep learning (DL) is greedy for data and requires a large amount of data supply to optimize massive parameters, so that the model learns how to extract high-quality features. In recent years, due to the rapid development of internet technology, we are in an era of information torrents and we have massive amounts of data. In this way, DL has aroused strong interest of researchers and has been rapidly developed. Compared with DL, researchers have relatively low interest in AL. This is mainly because before the rise of DL, traditional machine learning requires relatively few labeled samples. Therefore, early AL is difficult to reflect the value it deserves. Although DL has made breakthroughs in various fields, most of this success is due to the publicity of the large number of existing annotation datasets. However, the acquisition of a large number of high-quality annotated datasets consumes a lot of manpower, which is not allowed in some fields that require high expertise, especially in the fields of speech recognition, information extraction, medical images, etc. Therefore, AL has gradually received due attention. A natural idea is whether AL can be used to reduce the cost of sample annotations, while retaining the powerful learning capabilities of DL. Therefore, deep active learning (DAL) has emerged. Although the related research has been quite abundant, it lacks a comprehensive survey of DAL. This article is to fill this gap, we provide a formal classification method for the existing work, and a comprehensive and systematic overview. In addition, we also analyzed and summarized the development of DAL from the perspective of application. Finally, we discussed the confusion and problems in DAL, and gave some possible development directions for DAL.
Fine-tune BERT for E-commerce Non-Default Search Ranking
Aug 21, 2020
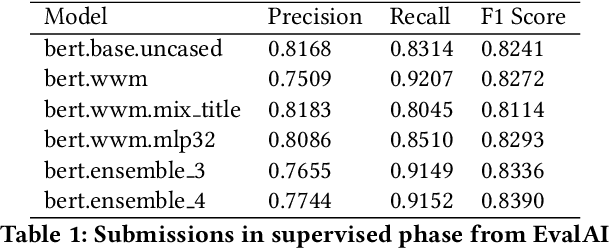
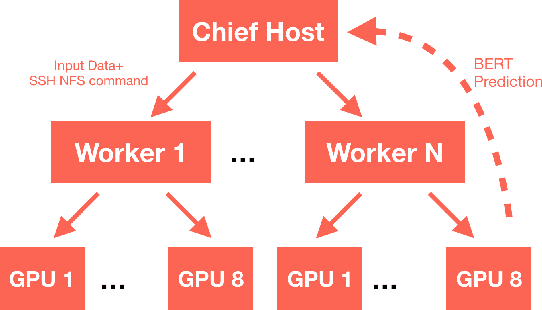
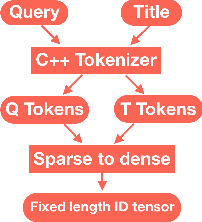
The quality of non-default ranking on e-commerce platforms, such as based on ascending item price or descending historical sales volume, often suffers from acute relevance problems, since the irrelevant items are much easier to be exposed at the top of the ranking results. In this work, we propose a two-stage ranking scheme, which first recalls wide range of candidate items through refined query/title keyword matching, and then classifies the recalled items using BERT-Large fine-tuned on human label data. We also implemented parallel prediction on multiple GPU hosts and a C++ tokenization custom op of Tensorflow. In this data challenge, our model won the 1st place in the supervised phase (based on overall F1 score) and 2nd place in the final phase (based on average per query F1 score).