 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Mixture Of Experts with Category Hierarchy Soft Constraint
Paper and Code
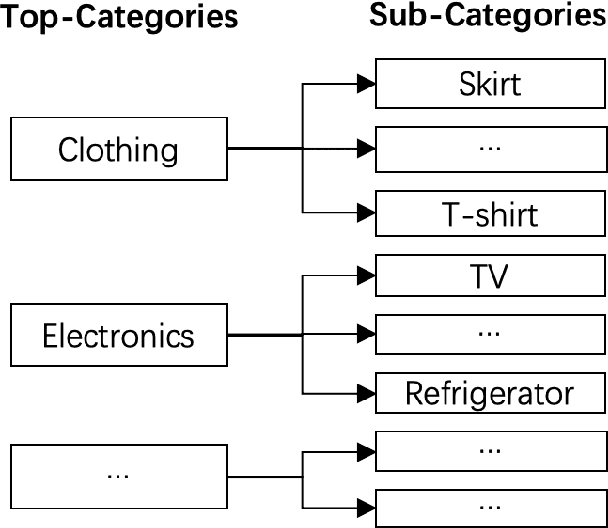
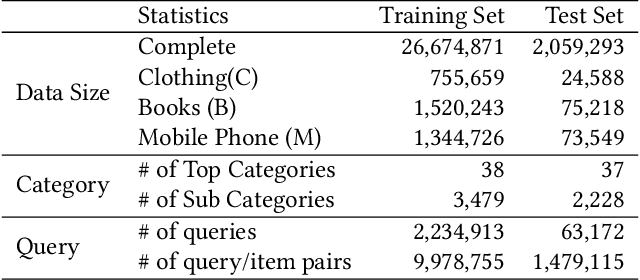
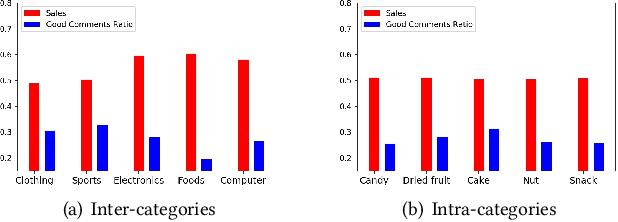
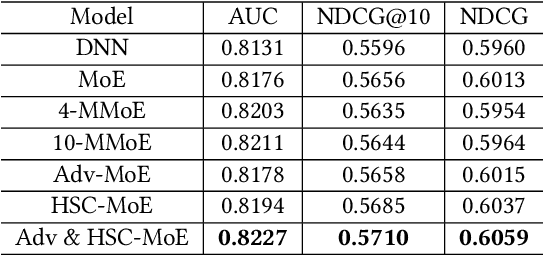
Product search is the most common way for people to satisfy their shopping needs on e-commerce websites. Products are typically annotated with one of several broad categorical tags, such as "Clothing" or "Electronics", as well as finer-grained categories like "Refrigerator" or "TV", both under "Electronics". These tags are used to construct a hierarchy of query categories. Feature distributions such as price and brand popularity vary wildly across query categories. In addition, feature importance for the purpose of CTR/CVR predictions differs from one category to another. In this work, we leverage the Mixture of Expert (MoE) framework to learn a ranking model that specializes for each query category. In particular, our gate network relies solely on the category ids extracted from the user query. While classical MoE's pick expert towers spontaneously for each input example, we explore two techniques to establish more explicit and transparent connections between the experts and query categories. To help differentiate experts on their domain specialties, we introduce a form of adversarial regularization among the expert outputs, forcing them to disagree with one another. As a result, they tend to approach each prediction problem from different angles, rather than copying one another. This is validated by a much stronger clustering effect of the gate output vectors under different categories. In addition, soft gating constraints based on the categorical hierarchy are imposed to help similar products choose similar gate values. and make them more likely to share similar experts. This allows aggregation of training data among smaller sibling categories to overcome data scarcity issues among the latter. Experiments on a learning-to-rank dataset gathered from a leading e-commerce search log demonstrate that MoE with our improvements consistently outperforms competing models.