 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Attention Networks with LSTM-based Path Reweighting
Jun 21, 2021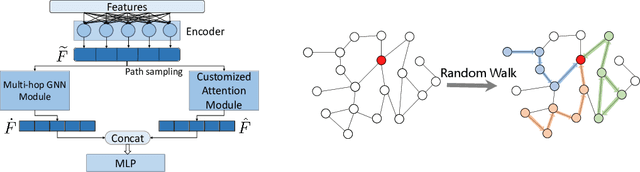


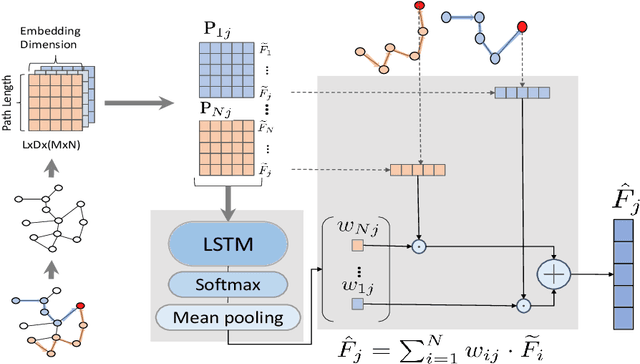
Graph Neural Networks (GNNs) have been extensively used for mining graph-structured data with impressive performance. However, traditional GNNs suffer from over-smoothing, non-robustness and over-fitting problems. To solve these weaknesses, we design a novel GNN solution, namely Graph Attention Network with LSTM-based Path Reweighting (PR-GAT). PR-GAT can automatically aggregate multi-hop information, highlight important paths and filter out noises. In addition, we utilize random path sampling in PR-GAT for data augmentation. The augmented data is used for predicting the distribution of corresponding labels. Finally, we demonstrate that PR-GAT can mitigate the issues of over-smoothing, non-robustness and overfitting. We achieve state-of-the-art accuracy on 5 out of 7 datasets and competitive accuracy for other 2 datasets. The average accuracy of 7 datasets have been improved by 0.5\% than the best SOTA from literature.
Learning Timestamp-Level Representations for Time Series with Hierarchical Contrastive Loss
Jun 19, 2021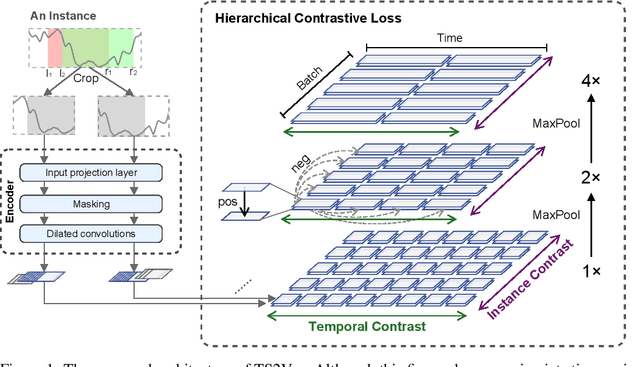
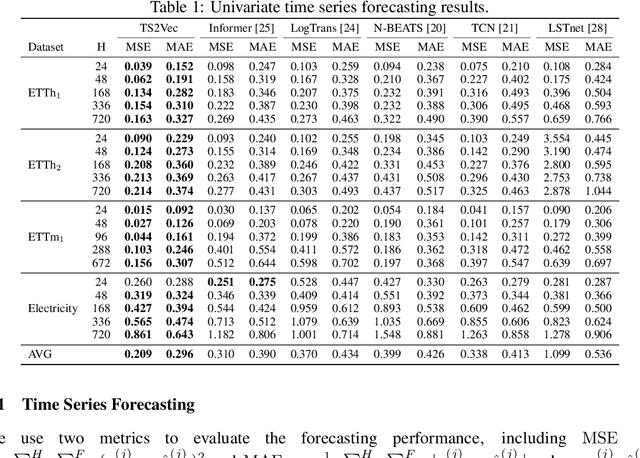
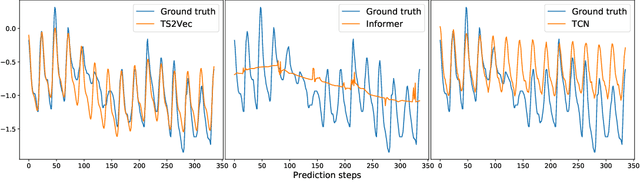
This paper presents TS2Vec, a universal framework for learning timestamp-level representations of time series. Unlike existing methods, TS2Vec performs timestamp-wise discrimination, which learns a contextual representation vector directly for each timestamp. We find that the learned representations have superior predictive ability. A linear regression trained on top of the learned representations outperforms previous SOTAs for supervised time series forecasting. Also, the instance-level representations can be simply obtained by applying a max pooling layer on top of learned representations of all timestamps. We conduct extensive experiments on time series classification tasks to evaluate the quality of instance-level representations. As a result, TS2Vec achieves significant improvement compared with existing SOTAs of unsupervised time series representation on 125 UCR datasets and 29 UEA datasets. The source code is publicly available at https://github.com/yuezhihan/ts2vec.
Spectral Temporal Graph Neural Network for Multivariate Time-series Forecasting
Mar 13, 2021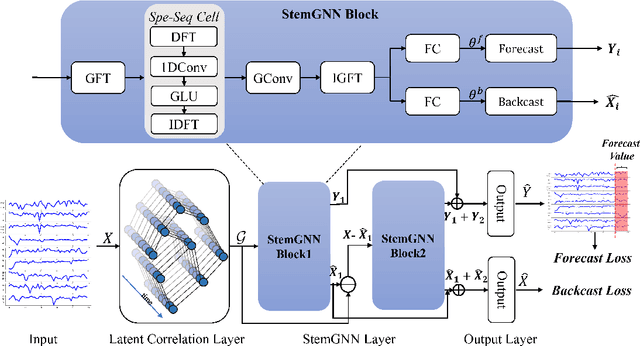

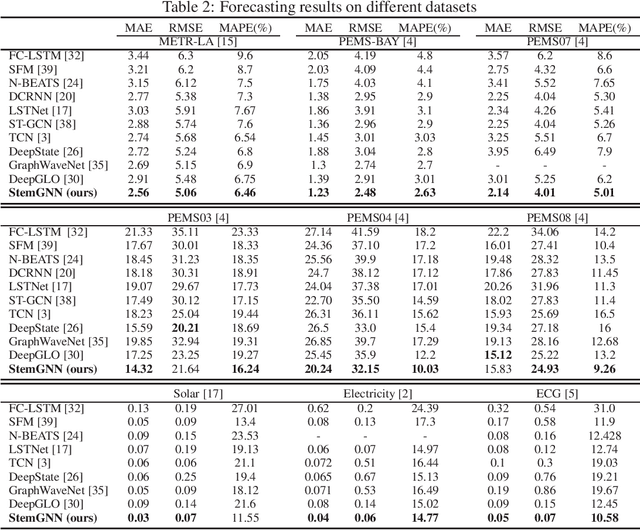
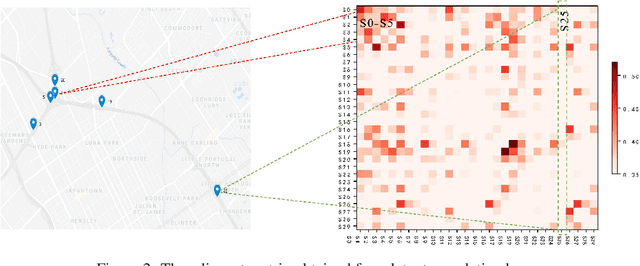
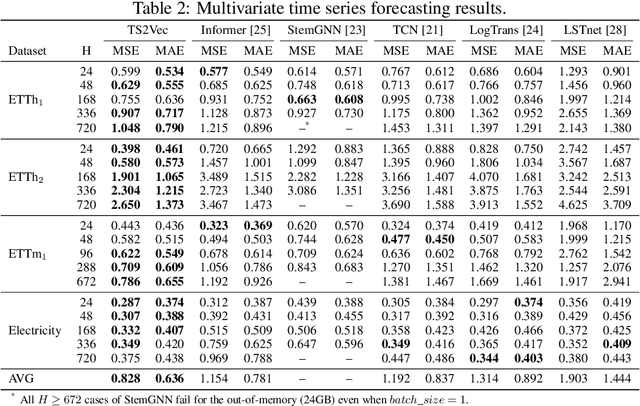
Multivariate time-series forecasting plays a crucial role in many real-world applications. It is a challenging problem as one needs to consider both intra-series temporal correlations and inter-series correlations simultaneously. Recently, there have been multiple works trying to capture both correlations, but most, if not all of them only capture temporal correlations in the time domain and resort to pre-defined priors as inter-series relationships. In this paper, we propose Spectral Temporal Graph Neural Network (StemGNN) to further improve the accuracy of multivariate time-series forecasting. StemGNN captures inter-series correlations and temporal dependencies \textit{jointly} in the \textit{spectral domain}. It combines Graph Fourier Transform (GFT) which models inter-series correlations and Discrete Fourier Transform (DFT) which models temporal dependencies in an end-to-end framework. After passing through GFT and DFT, the spectral representations hold clear patterns and can be predicted effectively by convolution and sequential learning modules. Moreover, StemGNN learns inter-series correlations automatically from the data without using pre-defined priors. We conduct extensive experiments on ten real-world datasets to demonstrate the effectiveness of StemGNN. Code is available at https://github.com/microsoft/StemGNN/
Syntax-BERT: Improving Pre-trained Transformers with Syntax Trees
Mar 07, 2021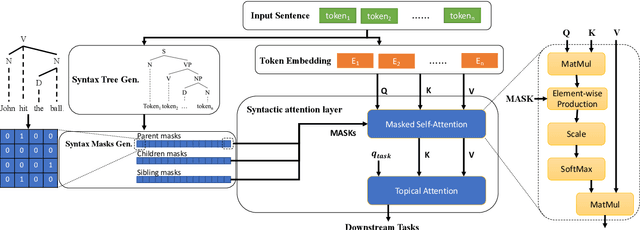

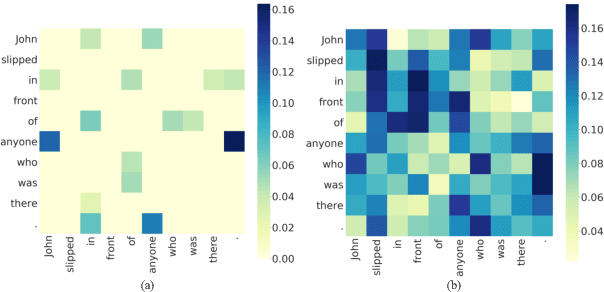
Pre-trained language models like BERT achieve superior performances in various NLP tasks without explicit consideration of syntactic information. Meanwhile, syntactic information has been proved to be crucial for the success of NLP applications. However, how to incorporate the syntax trees effectively and efficiently into pre-trained Transformers is still unsettled. In this paper, we address this problem by proposing a novel framework named Syntax-BERT. This framework works in a plug-and-play mode and is applicable to an arbitrary pre-trained checkpoint based on Transformer architecture. Experiments on various datasets of natural language understanding verify the effectiveness of syntax trees and achieve consistent improvement over multiple pre-trained models, including BERT, RoBERTa, and T5.
Evolving Attention with Residual Convolutions
Feb 20, 2021



Transformer is a ubiquitous model for natural language processing and has attracted wide attentions in computer vision. The attention maps are indispensable for a transformer model to encode the dependencies among input tokens. However, they are learned independently in each layer and sometimes fail to capture precise patterns. In this paper, we propose a novel and generic mechanism based on evolving attention to improve the performance of transformers. On one hand, the attention maps in different layers share common knowledge, thus the ones in preceding layers can instruct the attention in succeeding layers through residual connections. On the other hand, low-level and high-level attentions vary in the level of abstraction, so we adopt convolutional layers to model the evolutionary process of attention maps. The proposed evolving attention mechanism achieves significant performance improvement over various state-of-the-art models for multiple tasks, including image classification, natural language understanding and machine translation.
AutoADR: Automatic Model Design for Ad Relevance
Oct 14, 2020

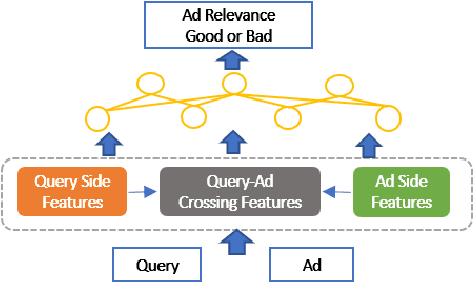
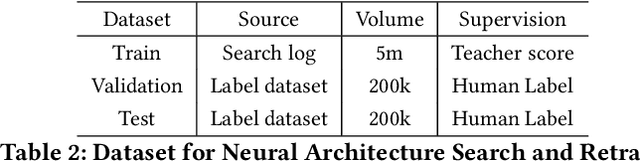
Large-scale pre-trained models have attracted extensive attention in the research community and shown promising results on various tasks of natural language processing. However, these pre-trained models are memory and computation intensive, hindering their deployment into industrial online systems like Ad Relevance. Meanwhile, how to design an effective yet efficient model architecture is another challenging problem in online Ad Relevance. Recently, AutoML shed new lights on architecture design, but how to integrate it with pre-trained language models remains unsettled. In this paper, we propose AutoADR (Automatic model design for AD Relevance) -- a novel end-to-end framework to address this challenge, and share our experience to ship these cutting-edge techniques into online Ad Relevance system at Microsoft Bing. Specifically, AutoADR leverages a one-shot neural architecture search algorithm to find a tailored network architecture for Ad Relevance. The search process is simultaneously guided by knowledge distillation from a large pre-trained teacher model (e.g. BERT), while taking the online serving constraints (e.g. memory and latency) into consideration. We add the model designed by AutoADR as a sub-model into the production Ad Relevance model. This additional sub-model improves the Precision-Recall AUC (PR AUC) on top of the original Ad Relevance model by 2.65X of the normalized shipping bar. More importantly, adding this automatically designed sub-model leads to a statistically significant 4.6% Bad-Ad ratio reduction in online A/B testing. This model has been shipped into Microsoft Bing Ad Relevance Production model.
Multivariate Time-series Anomaly Detection via Graph Attention Network
Sep 04, 2020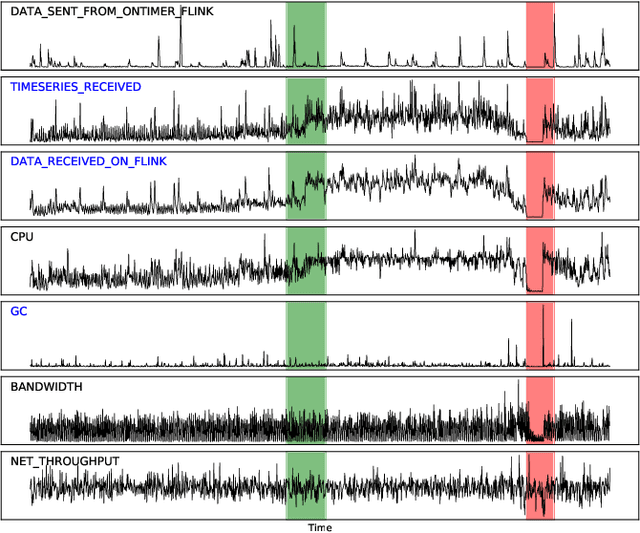
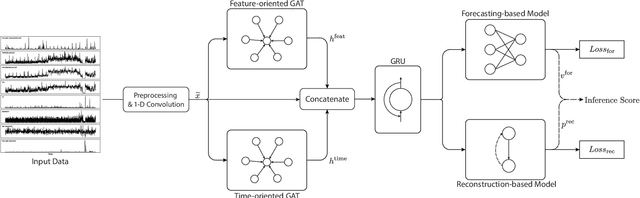
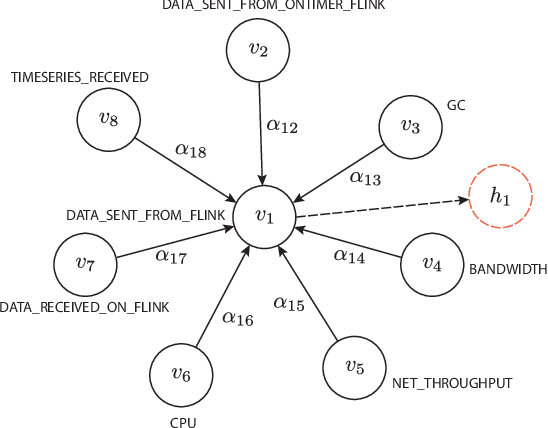
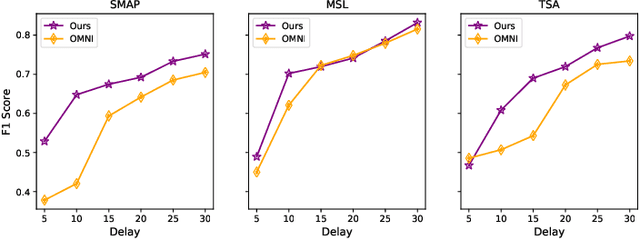
Anomaly detection on multivariate time-series is of great importance in both data mining research and industrial applications. Recent approaches have achieved significant progress in this topic, but there is remaining limitations. One major limitation is that they do not capture the relationships between different time-series explicitly, resulting in inevitable false alarms. In this paper, we propose a novel self-supervised framework for multivariate time-series anomaly detection to address this issue. Our framework considers each univariate time-series as an individual feature and includes two graph attention layers in parallel to learn the complex dependencies of multivariate time-series in both temporal and feature dimensions. In addition, our approach jointly optimizes a forecasting-based model and are construction-based model, obtaining better time-series representations through a combination of single-timestamp prediction and reconstruction of the entire time-series. We demonstrate the efficacy of our model through extensive experiments. The proposed method outperforms other state-of-the-art models on three real-world datasets. Further analysis shows that our method has good interpretability and is useful for anomaly diagnosis.
Cross-modal Knowledge Reasoning for Knowledge-based Visual Question Answering
Aug 31, 2020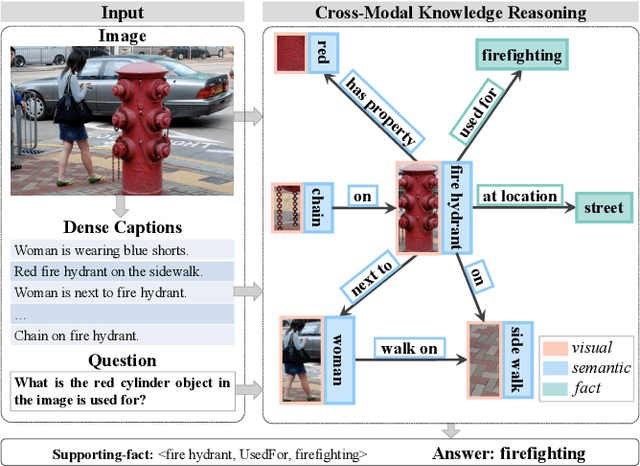
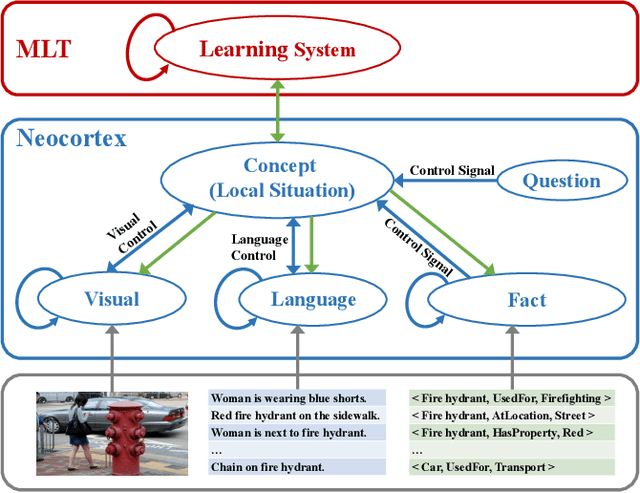
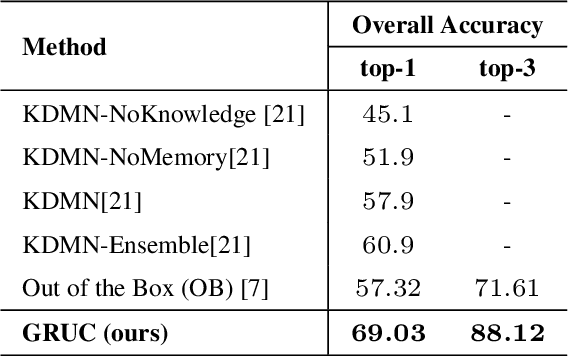
Knowledge-based Visual Question Answering (KVQA) requires external knowledge beyond the visible content to answer questions about an image. This ability is challenging but indispensable to achieve general VQA. One limitation of existing KVQA solutions is that they jointly embed all kinds of information without fine-grained selection, which introduces unexpected noises for reasoning the correct answer. How to capture the question-oriented and information-complementary evidence remains a key challenge to solve the problem. Inspired by the human cognition theory, in this paper, we depict an image by multiple knowledge graphs from the visual, semantic and factual views. Thereinto, the visual graph and semantic graph are regarded as image-conditioned instantiation of the factual graph. On top of these new representations, we re-formulate Knowledge-based Visual Question Answering as a recurrent reasoning process for obtaining complementary evidence from multimodal information. To this end, we decompose the model into a series of memory-based reasoning steps, each performed by a G raph-based R ead, U pdate, and C ontrol ( GRUC ) module that conducts parallel reasoning over both visual and semantic information. By stacking the modules multiple times, our model performs transitive reasoning and obtains question-oriented concept representations under the constrain of different modalities. Finally, we perform graph neural networks to infer the global-optimal answer by jointly considering all the concepts. We achieve a new state-of-the-art performance on three popular benchmark datasets, including FVQA, Visual7W-KB and OK-VQA, and demonstrate the effectiveness and interpretability of our model with extensive experiments.
Automated Model Selection for Time-Series Anomaly Detection
Aug 25, 2020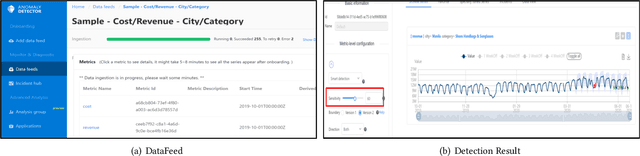
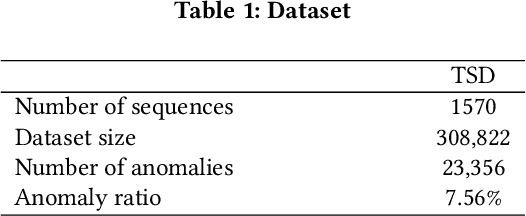
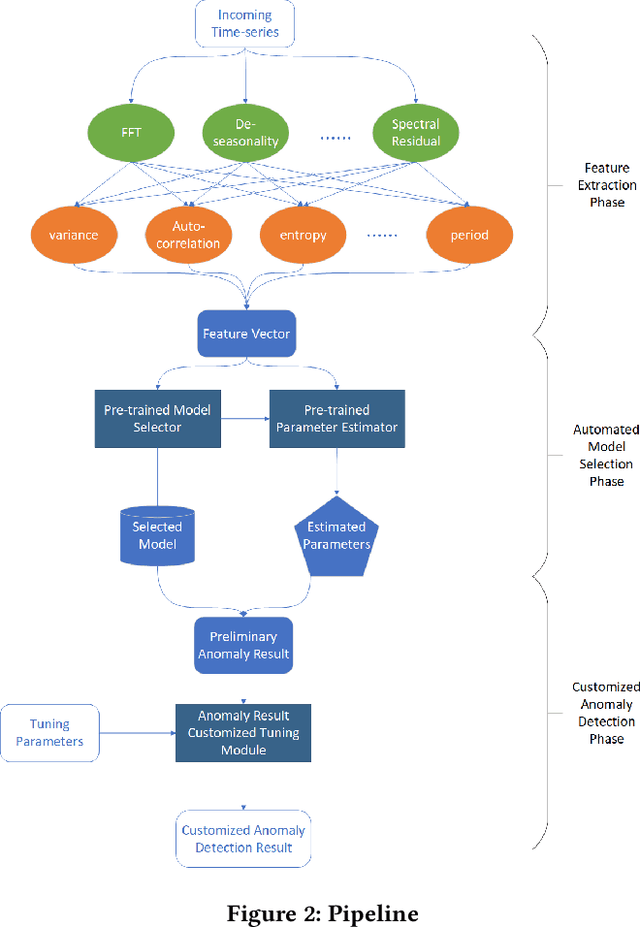
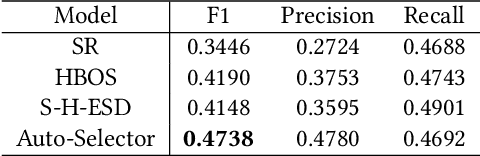
Time-series anomaly detection is a popular topic in both academia and industrial fields. Many companies need to monitor thousands of temporal signals for their applications and services and require instant feedback and alerts for potential incidents in time. The task is challenging because of the complex characteristics of time-series, which are messy, stochastic, and often without proper labels. This prohibits training supervised models because of lack of labels and a single model hardly fits different time series. In this paper, we propose a solution to address these issues. We present an automated model selection framework to automatically find the most suitable detection model with proper parameters for the incoming data. The model selection layer is extensible as it can be updated without too much effort when a new detector is available to the service. Finally, we incorporate a customized tuning algorithm to flexibly filter anomalies to meet customers' criteria. Experiments on real-world datasets show the effectiveness of our solution.
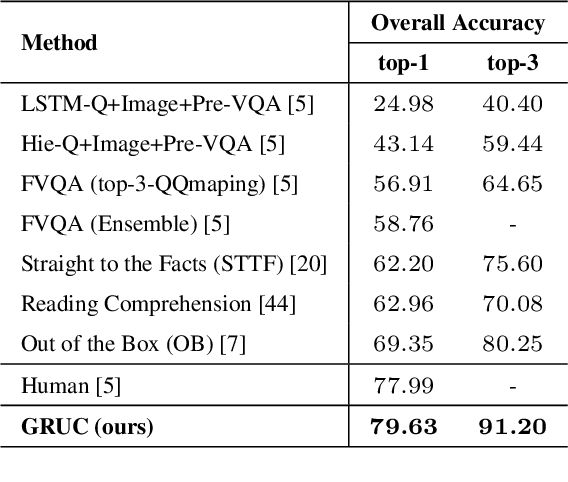
Mucko: Multi-Layer Cross-Modal Knowledge Reasoning for Fact-based Visual Question Answering
Jun 17, 2020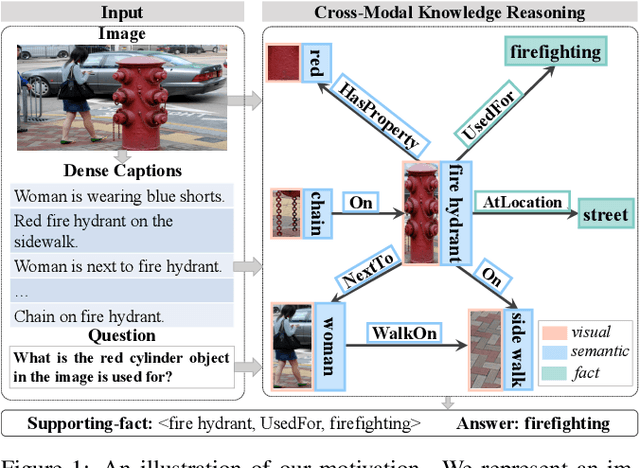
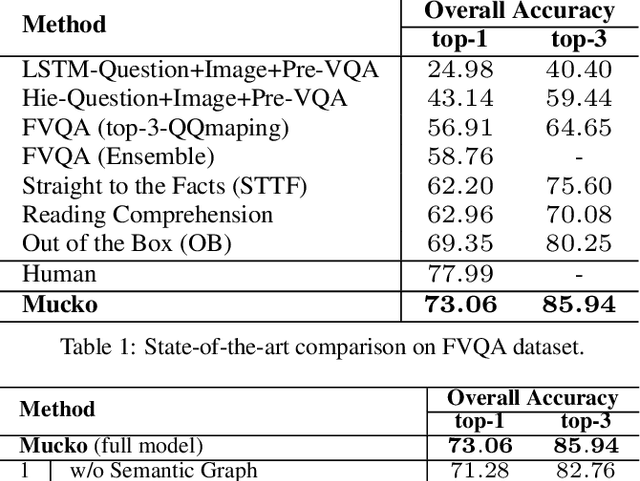
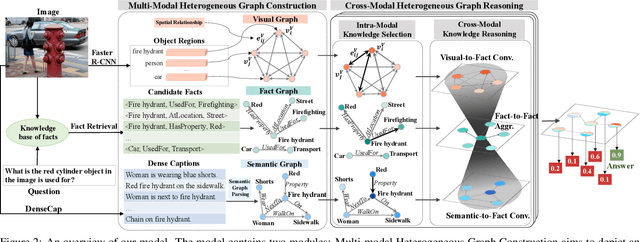
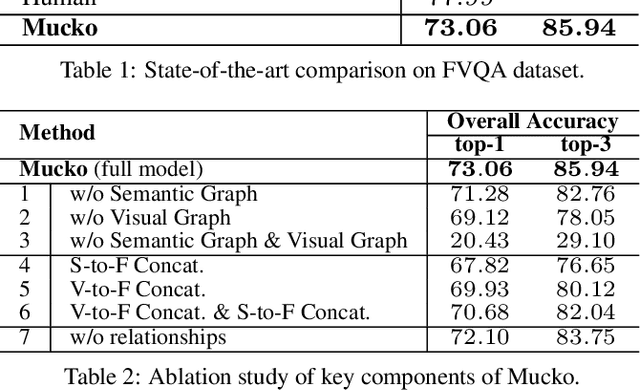
Fact-based Visual Question Answering (FVQA) requires external knowledge beyond visible content to answer questions about an image, which is challenging but indispensable to achieve general VQA. One limitation of existing FVQA solutions is that they jointly embed all kinds of information without fine-grained selection, which introduces unexpected noises for reasoning the final answer. How to capture the question-oriented and information-complementary evidence remains a key challenge to solve the problem. In this paper, we depict an image by a multi-modal heterogeneous graph, which contains multiple layers of information corresponding to the visual, semantic and factual features. On top of the multi-layer graph representations, we propose a modality-aware heterogeneous graph convolutional network to capture evidence from different layers that is most relevant to the given question. Specifically, the intra-modal graph convolution selects evidence from each modality and cross-modal graph convolution aggregates relevant information across different modalities. By stacking this process multiple times, our model performs iterative reasoning and predicts the optimal answer by analyzing all question-oriented evidence. We achieve a new state-of-the-art performance on the FVQA task and demonstrate the effectiveness and interpretability of our model with extensive experiments. The code is available at https://github.com/astro-zihao/mucko.