 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of FPGA-Based Robotic Computing
Sep 13, 2020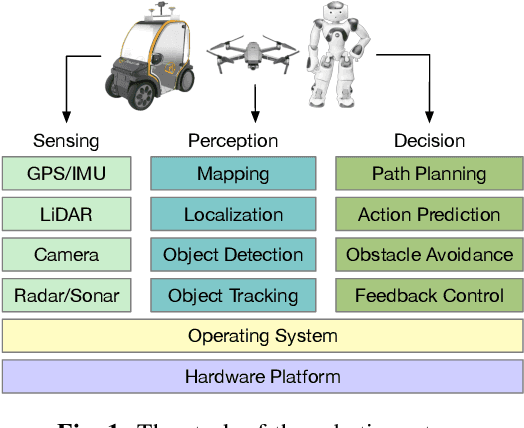
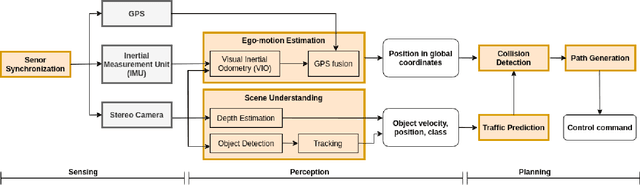
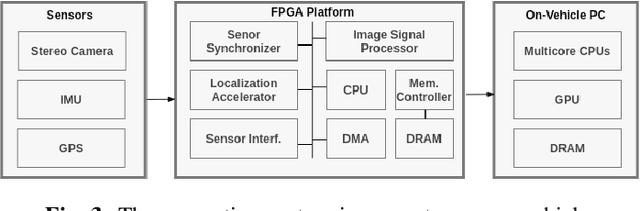
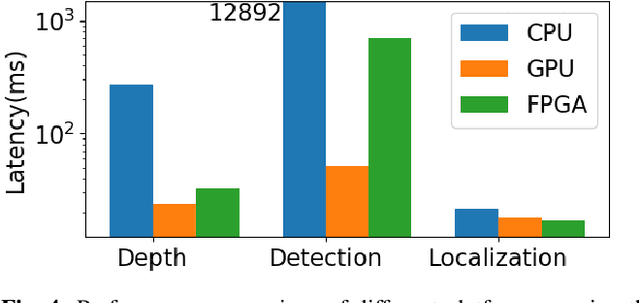
Recent researches on robotics have shown significant improvement, spanning from algorithms, mechanics to hardware architectures. Robotics, including manipulators, legged robots, drones, and autonomous vehicles, are now widely applied in diverse scenarios. However, the high computation and data complexity of robotic algorithms pose great challenges to its applications. On the one hand, CPU platform is flexible to handle multiple robotic tasks. GPU platform has higher computational capacities and easy-touse development frameworks, so they have been widely adopted in several applications. On the other hand, FPGA-based robotic accelerators are becoming increasingly competitive alternatives, especially in latency-critical and power-limited scenarios. With specialized designed hardware logic and algorithm kernels, FPGA-based accelerators can surpass CPU and GPU in performance and energy efficiency. In this paper, we give an overview of previous work on FPGA-based robotic accelerators covering different stages of the robotic system pipeline. An analysis of software and hardware optimization techniques and main technical issues is presented, along with some commercial and space applications, to serve as a guide for future work.
Accelerating Sparse DNN Models without Hardware-Support via Tile-Wise Sparsity
Aug 29, 2020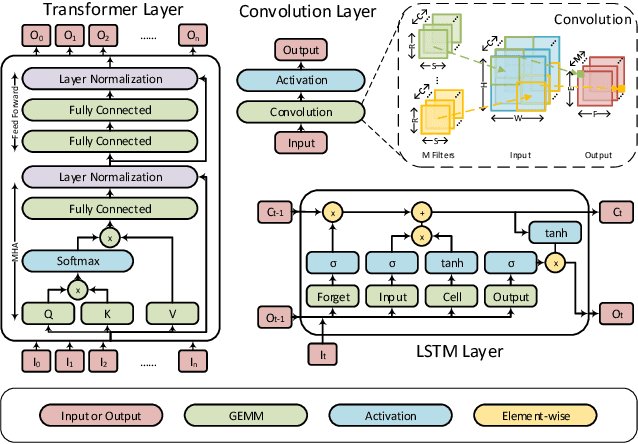
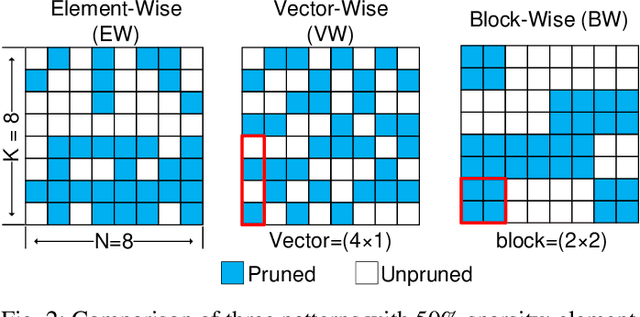
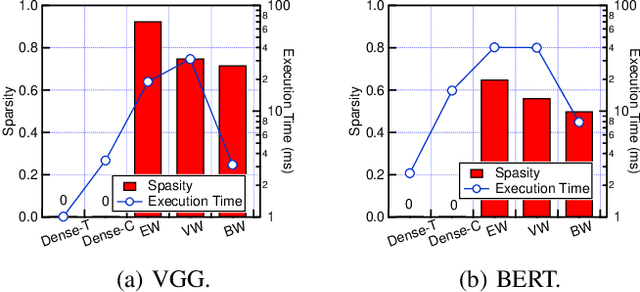
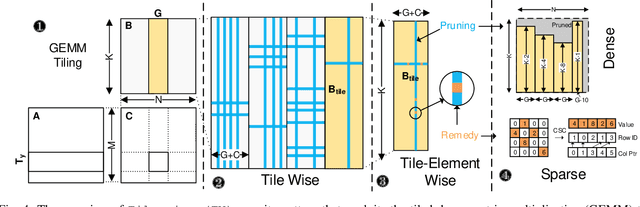
Network pruning can reduce the high computation cost of deep neural network (DNN) models. However, to maintain their accuracies, sparse models often carry randomly-distributed weights, leading to irregular computations. Consequently, sparse models cannot achieve meaningful speedup on commodity hardware (e.g., GPU) built for dense matrix computations. As such, prior works usually modify or design completely new sparsity-optimized architectures for exploiting sparsity. We propose an algorithm-software co-designed pruning method that achieves latency speedups on existing dense architectures. Our work builds upon the insight that the matrix multiplication generally breaks the large matrix into multiple smaller tiles for parallel execution. We propose a tiling-friendly "tile-wise" sparsity pattern, which maintains a regular pattern at the tile level for efficient execution but allows for irregular, arbitrary pruning at the global scale to maintain the high accuracy. We implement and evaluate the sparsity pattern on GPU tensor core, achieving a 1.95x speedup over the dense model.
Real-Time Spatio-Temporal LiDAR Point Cloud Compression
Aug 16, 2020

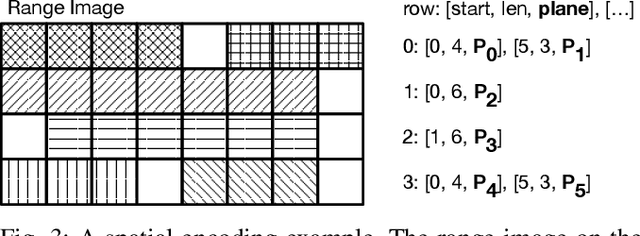

Compressing massive LiDAR point clouds in real-time is critical to autonomous machines such as drones and self-driving cars. While most of the recent prior work has focused on compressing individual point cloud frames, this paper proposes a novel system that effectively compresses a sequence of point clouds. The idea to exploit both the spatial and temporal redundancies in a sequence of point cloud frames. We first identify a key frame in a point cloud sequence and spatially encode the key frame by iterative plane fitting. We then exploit the fact that consecutive point clouds have large overlaps in the physical space, and thus spatially encoded data can be (re-)used to encode the temporal stream. Temporal encoding by reusing spatial encoding data not only improves the compression rate, but also avoids redundant computations, which significantly improves the compression speed. Experiments show that our compression system achieves 40x to 90x compression rate, significantly higher than the MPEG's LiDAR point cloud compression standard, while retaining high end-to-end application accuracies. Meanwhile, our compression system has a compression speed that matches the point cloud generation rate by today LiDARs and out-performs existing compression systems, enabling real-time point cloud transmission.
Mesorasi: Architecture Support for Point Cloud Analytics via Delayed-Aggregation
Aug 16, 2020
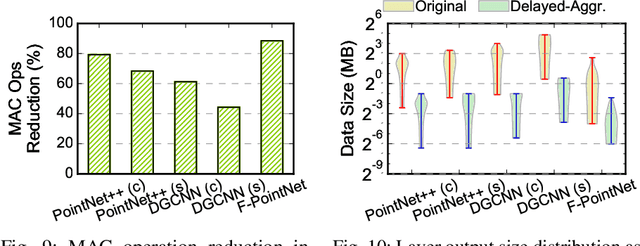
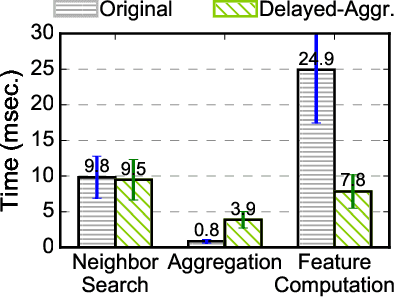
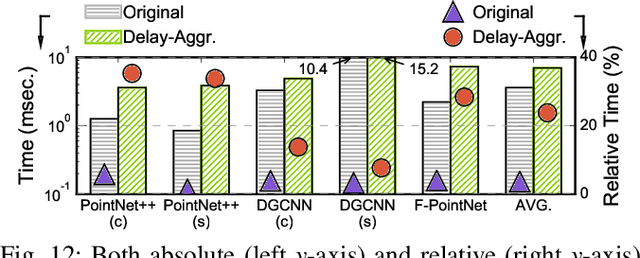
Point cloud analytics is poised to become a key workload on battery-powered embedded and mobile platforms in a wide range of emerging application domains, such as autonomous driving, robotics, and augmented reality, where efficiency is paramount. This paper proposes Mesorasi, an algorithm-architecture co-designed system that simultaneously improves the performance and energy efficiency of point cloud analytics while retaining its accuracy. Our extensive characterizations of state-of-the-art point cloud algorithms show that, while structurally reminiscent of convolutional neural networks (CNNs), point cloud algorithms exhibit inherent compute and memory inefficiencies due to the unique characteristics of point cloud data. We propose delayed-aggregation, a new algorithmic primitive for building efficient point cloud algorithms. Delayed-aggregation hides the performance bottlenecks and reduces the compute and memory redundancies by exploiting the approximately distributive property of key operations in point cloud algorithms. Delayed-aggregation let point cloud algorithms achieve 1.6x speedup and 51.1% energy reduction on a mobile GPU while retaining the accuracy (-0.9% loss to 1.2% gains). To maximize the algorithmic benefits, we propose minor extensions to contemporary CNN accelerators, which can be integrated into a mobile Systems-on-a-Chip (SoC) without modifying other SoC components. With additional hardware support, Mesorasi achieves up to 3.6x speedup.
Balancing Efficiency and Flexibility for DNN Acceleration via Temporal GPU-Systolic Array Integration
Feb 18, 2020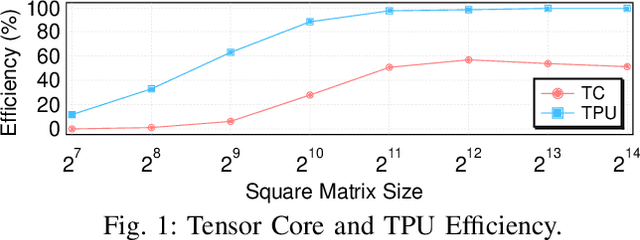
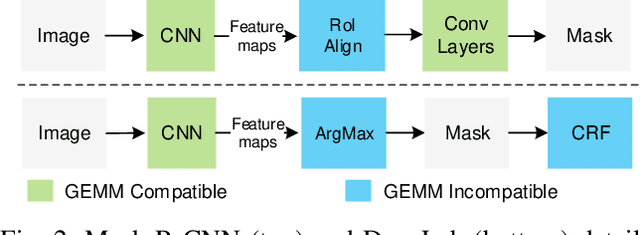

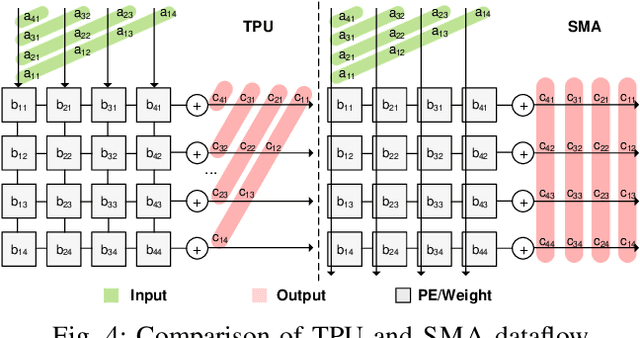
The research interest in specialized hardware accelerators for deep neural networks (DNN) spiked recently owing to their superior performance and efficiency. However, today's DNN accelerators primarily focus on accelerating specific "kernels" such as convolution and matrix multiplication, which are vital but only part of an end-to-end DNN-enabled application. Meaningful speedups over the entire application often require supporting computations that are, while massively parallel, ill-suited to DNN accelerators. Integrating a general-purpose processor such as a CPU or a GPU incurs significant data movement overhead and leads to resource under-utilization on the DNN accelerators. We propose Simultaneous Multi-mode Architecture (SMA), a novel architecture design and execution model that offers general-purpose programmability on DNN accelerators in order to accelerate end-to-end applications. The key to SMA is the temporal integration of the systolic execution model with the GPU-like SIMD execution model. The SMA exploits the common components shared between the systolic-array accelerator and the GPU, and provides lightweight reconfiguration capability to switch between the two modes in-situ. The SMA achieves up to 63% performance improvement while consuming 23% less energy than the baseline Volta architecture with TensorCore.
Tigris: Architecture and Algorithms for 3D Perception in Point Clouds
Nov 21, 2019
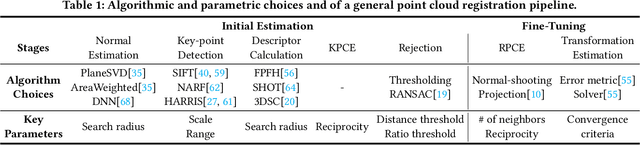

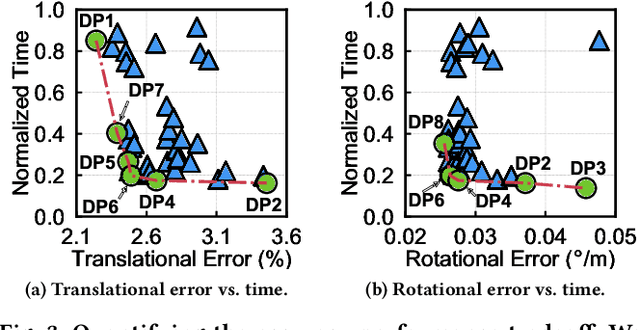
Machine perception applications are increasingly moving toward manipulating and processing 3D point cloud. This paper focuses on point cloud registration, a key primitive of 3D data processing widely used in high-level tasks such as odometry, simultaneous localization and mapping, and 3D reconstruction. As these applications are routinely deployed in energy-constrained environments, real-time and energy-efficient point cloud registration is critical. We present Tigris, an algorithm-architecture co-designed system specialized for point cloud registration. Through an extensive exploration of the registration pipeline design space, we find that, while different design points make vastly different trade-offs between accuracy and performance, KD-tree search is a common performance bottleneck, and thus is an ideal candidate for architectural specialization. While KD-tree search is inherently sequential, we propose an acceleration-amenable data structure and search algorithm that exposes different forms of parallelism of KD-tree search in the context of point cloud registration. The co-designed accelerator systematically exploits the parallelism while incorporating a set of architectural techniques that further improve the accelerator efficiency. Overall, Tigris achieves 77.2$\times$ speedup and 7.4$\times$ power reduction in KD-tree search over an RTX 2080 Ti GPU, which translates to a 41.7% registration performance improvements and 3.0$\times$ power reduction.
ASV: Accelerated Stereo Vision System
Nov 15, 2019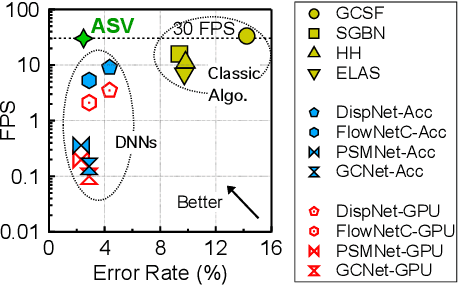
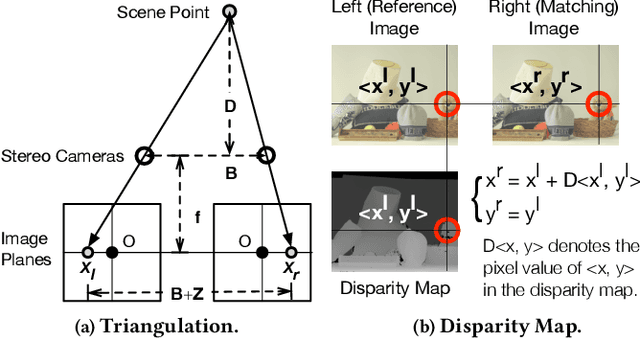
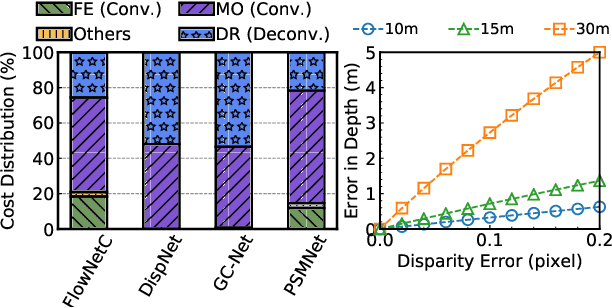
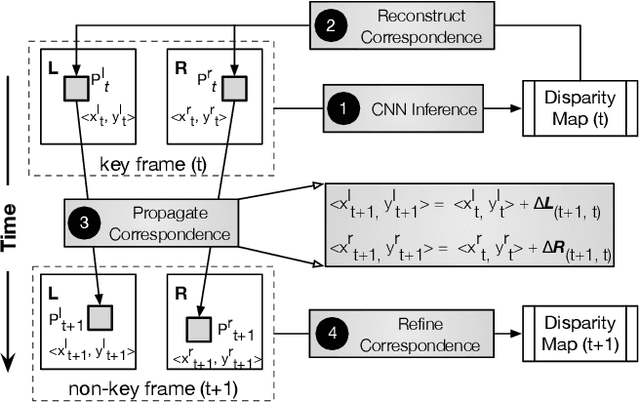
Estimating depth from stereo vision cameras, i.e., "depth from stereo", is critical to emerging intelligent applications deployed in energy- and performance-constrained devices, such as augmented reality headsets and mobile autonomous robots. While existing stereo vision systems make trade-offs between accuracy, performance and energy-efficiency, we describe ASV, an accelerated stereo vision system that simultaneously improves both performance and energy-efficiency while achieving high accuracy. The key to ASV is to exploit unique characteristics inherent to stereo vision, and apply stereo-specific optimizations, both algorithmically and computationally. We make two contributions. Firstly, we propose a new stereo algorithm, invariant-based stereo matching (ISM), that achieves significant speedup while retaining high accuracy. The algorithm combines classic "hand-crafted" stereo algorithms with recent developments in Deep Neural Networks (DNNs), by leveraging the correspondence invariant unique to stereo vision systems. Secondly, we observe that the bottleneck of the ISM algorithm is the DNN inference, and in particular the deconvolution operations that introduce massive compute-inefficiencies. We propose a set of software optimizations that mitigate these inefficiencies. We show that with less than 0.5% hardware area overhead, these algorithmic and computational optimizations can be effectively integrated within a conventional DNN accelerator. Overall, ASV achieves 5x speedup and 85% energy saving with 0.02% accuracy loss compared to today DNN-based stereo vision systems.
* MICRO 2019
Learning Sparsity and Quantization Jointly and Automatically for Neural Network Compression via Constrained Optimization
Oct 17, 2019
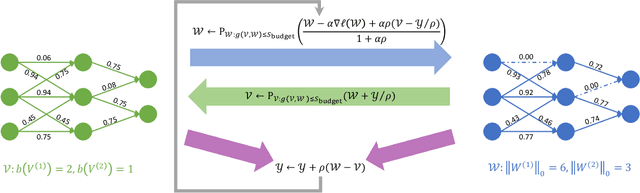
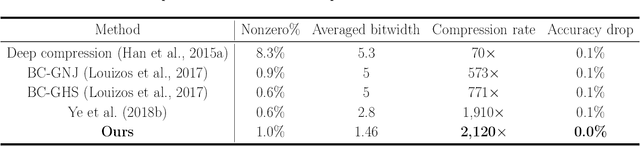
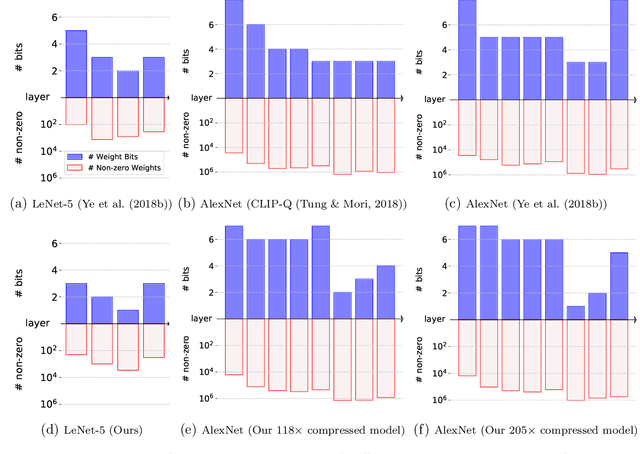
Deep Neural Networks (DNNs) are widely applied in a wide range of usecases. There is an increased demand for deploying DNNs on devices that do not have abundant resources such as memory and computation units. Recently, network compression through a variety of techniques such as pruning and quantization have been proposed to reduce the resource requirement. A key parameter that all existing compression techniques are sensitive to is the compression ratio (e.g., pruning sparsity, quantization bitwidth) of each layer. Traditional solutions treat the compression ratios of each layer as hyper-parameters, and tune them using human heuristic. Recent researchers start using black-box hyper-parameter optimizations, but they will introduce new hyper-parameters and have efficiency issue. In this paper, we propose a framework to jointly prune and quantize the DNNs automatically according to a target model size without using any hyper-parameters to manually set the compression ratio for each layer. In the experiments, we show that our framework can compress the weights data of ResNet-50 to be 836x smaller without accuracy loss on CIFAR-10, and compress AlexNet to be 205x smaller without accuracy loss on ImageNet classification.
Adversarial Defense Through Network Profiling Based Path Extraction
May 09, 2019



Recently, researchers have started decomposing deep neural network models according to their semantics or functions. Recent work has shown the effectiveness of decomposed functional blocks for defending adversarial attacks, which add small input perturbation to the input image to fool the DNN models. This work proposes a profiling-based method to decompose the DNN models to different functional blocks, which lead to the effective path as a new approach to exploring DNNs' internal organization. Specifically, the per-image effective path can be aggregated to the class-level effective path, through which we observe that adversarial images activate effective path different from normal images. We propose an effective path similarity-based method to detect adversarial images with an interpretable model, which achieve better accuracy and broader applicability than the state-of-the-art technique.
Joint Iris Segmentation and Localization Using Deep Multi-task Learning Framework
Jan 31, 2019
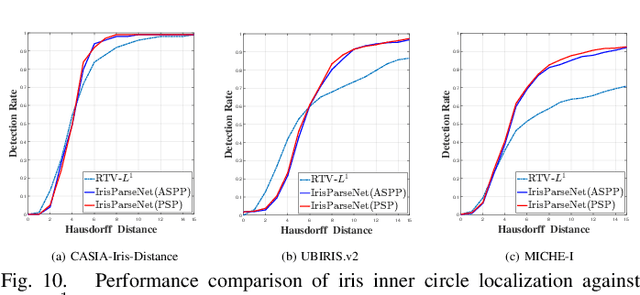
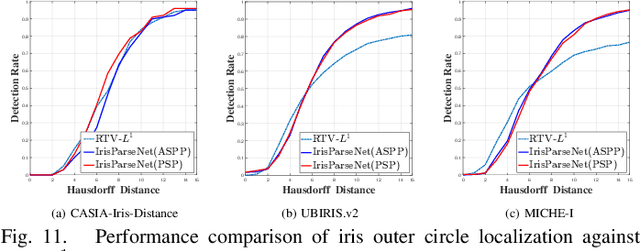
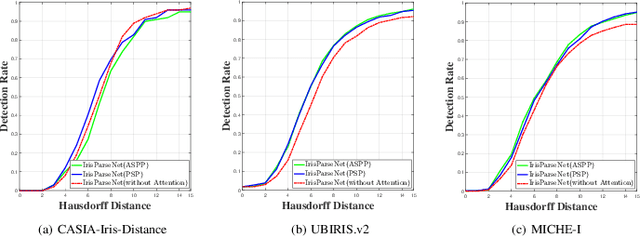
Iris segmentation and localization in non-cooperative environment is challenging due to illumination variations, long distances, moving subjects and limited user cooperation, etc. Traditional methods often suffer from poor performance when confronted with iris images captured in these conditions. Recent studies have shown that deep learning methods could achieve impressive performance on iris segmentation task. In addition, as iris is defined as an annular region between pupil and sclera, geometric constraints could be imposed to help locating the iris more accurately and improve the segmentation results. In this paper, we propose a deep multi-task learning framework, named as IrisParseNet, to exploit the inherent correlations between pupil, iris and sclera to boost up the performance of iris segmentation and localization in a unified model. In particular, IrisParseNet firstly applies a Fully Convolutional Encoder-Decoder Attention Network to simultaneously estimate pupil center, iris segmentation mask and iris inner/outer boundary. Then, an effective post-processing method is adopted for iris inner/outer circle localization.To train and evaluate the proposed method, we manually label three challenging iris datasets, namely CASIA-Iris-Distance, UBIRIS.v2, and MICHE-I, which cover various types of noises. Extensive experiments are conducted on these newly annotated datasets, and results show that our method outperforms state-of-the-art methods on various benchmarks. All the ground-truth annotations, annotation codes and evaluation protocols are publicly available at https://github.com/xiamenwcy/IrisParseNet.