 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViTPose+: Vision Transformer Foundation Model for Generic Body Pose Estimation
Dec 07, 2022In this paper, we show the surprisingly good properties of plain vision transformers for body pose estimation from various aspects, namely simplicity in model structure, scalability in model size, flexibility in training paradigm, and transferability of knowledge between models, through a simple baseline model dubbed ViTPose. Specifically, ViTPose employs the plain and non-hierarchical vision transformer as an encoder to encode features and a lightweight decoder to decode body keypoints in either a top-down or a bottom-up manner. It can be scaled up from about 20M to 1B parameters by taking advantage of the scalable model capacity and high parallelism of the vision transformer, setting a new Pareto front for throughput and performance. Besides, ViTPose is very flexible regarding the attention type, input resolution, and pre-training and fine-tuning strategy. Based on the flexibility, a novel ViTPose+ model is proposed to deal with heterogeneous body keypoint categories in different types of body pose estimation tasks via knowledge factorization, i.e., adopting task-agnostic and task-specific feed-forward networks in the transformer. We also empirically demonstrate that the knowledge of large ViTPose models can be easily transferred to small ones via a simple knowledge token. Experimental results show that our ViTPose model outperforms representative methods on the challenging MS COCO Human Keypoint Detection benchmark at both top-down and bottom-up settings. Furthermore, our ViTPose+ model achieves state-of-the-art performance simultaneously on a series of body pose estimation tasks, including MS COCO, AI Challenger, OCHuman, MPII for human keypoint detection, COCO-Wholebody for whole-body keypoint detection, as well as AP-10K and APT-36K for animal keypoint detection, without sacrificing inference speed.
1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022



The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.
Rethinking Hierarchies in Pre-trained Plain Vision Transformer
Nov 08, 2022Self-supervised pre-training vision transformer (ViT) via masked image modeling (MIM) has been proven very effective. However, customized algorithms should be carefully designed for the hierarchical ViTs, e.g., GreenMIM, instead of using the vanilla and simple MAE for the plain ViT. More importantly, since these hierarchical ViTs cannot reuse the off-the-shelf pre-trained weights of the plain ViTs, the requirement of pre-training them leads to a massive amount of computational cost, thereby incurring both algorithmic and computational complexity. In this paper, we address this problem by proposing a novel idea of disentangling the hierarchical architecture design from the self-supervised pre-training. We transform the plain ViT into a hierarchical one with minimal changes. Technically, we change the stride of linear embedding layer from 16 to 4 and add convolution (or simple average) pooling layers between the transformer blocks, thereby reducing the feature size from 1/4 to 1/32 sequentially. Despite its simplicity, it outperforms the plain ViT baseline in classification, detection, and segmentation tasks on ImageNet, MS COCO, Cityscapes, and ADE20K benchmarks, respectively. We hope this preliminary study could draw more attention from the community on developing effective (hierarchical) ViTs while avoiding the pre-training cost by leveraging the off-the-shelf checkpoints. The code and models will be released at https://github.com/ViTAE-Transformer/HPViT.
Advancing Plain Vision Transformer Towards Remote Sensing Foundation Model
Aug 10, 2022
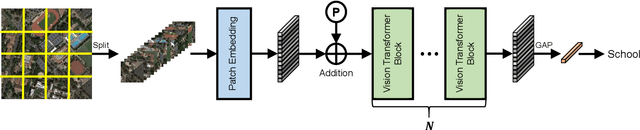
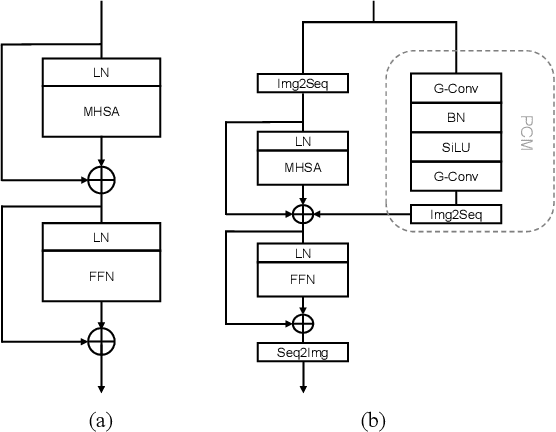
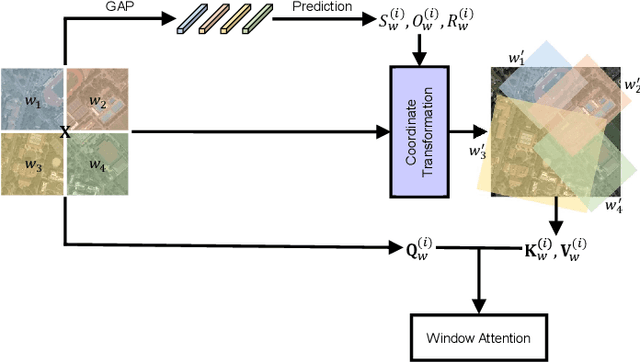
Large-scale vision foundation models have made significant progress in visual tasks on natural images, where the vision transformers are the primary choice for their good scalability and representation ability. However, the utilization of large models in the remote sensing (RS) community remains under-explored where existing models are still at small-scale, which limits the performance. In this paper, we resort to plain vision transformers with about 100 million parameters and make the first attempt to propose large vision models customized for RS tasks and explore how such large models perform. Specifically, to handle the large image size and objects of various orientations in RS images, we propose a new rotated varied-size window attention to substitute the original full attention in transformers, which could significantly reduce the computational cost and memory footprint while learn better object representation by extracting rich context from the generated diverse windows. Experiments on detection tasks demonstrate the superiority of our model over all state-of-the-art models, achieving 81.16% mAP on the DOTA-V1.0 dataset. The results of our models on downstream classification and segmentation tasks also demonstrate competitive performance compared with the existing advanced methods. Further experiments show the advantages of our models on computational complexity and few-shot learning.
Transformer-based Context Condensation for Boosting Feature Pyramids in Object Detection
Jul 14, 2022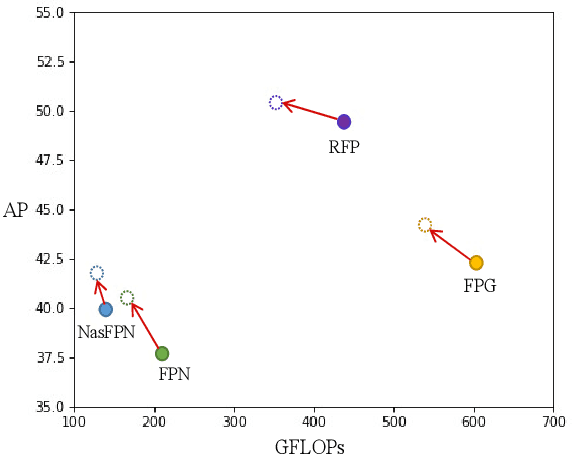
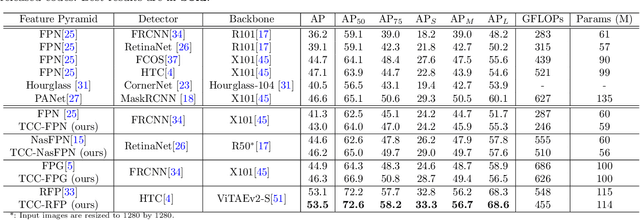
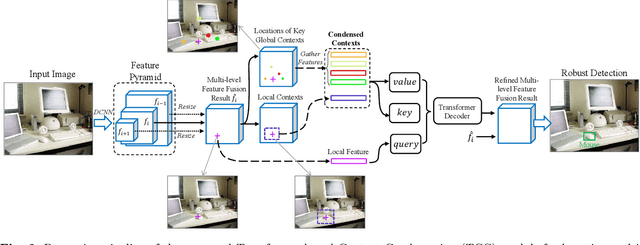

Current object detectors typically have a feature pyramid (FP) module for multi-level feature fusion (MFF) which aims to mitigate the gap between features from different levels and form a comprehensive object representation to achieve better detection performance. However, they usually require heavy cross-level connections or iterative refinement to obtain better MFF result, making them complicated in structure and inefficient in computation. To address these issues, we propose a novel and efficient context modeling mechanism that can help existing FPs deliver better MFF results while reducing the computational costs effectively. In particular, we introduce a novel insight that comprehensive contexts can be decomposed and condensed into two types of representations for higher efficiency. The two representations include a locally concentrated representation and a globally summarized representation, where the former focuses on extracting context cues from nearby areas while the latter extracts key representations of the whole image scene as global context cues. By collecting the condensed contexts, we employ a Transformer decoder to investigate the relations between them and each local feature from the FP and then refine the MFF results accordingly. As a result, we obtain a simple and light-weight Transformer-based Context Condensation (TCC) module, which can boost various FPs and lower their computational costs simultaneously. Extensive experimental results on the challenging MS COCO dataset show that TCC is compatible to four representative FPs and consistently improves their detection accuracy by up to 7.8 % in terms of average precision and reduce their complexities by up to around 20% in terms of GFLOPs, helping them achieve state-of-the-art performance more efficiently. Code will be released.
APT-36K: A Large-scale Benchmark for Animal Pose Estimation and Tracking
Jun 12, 2022
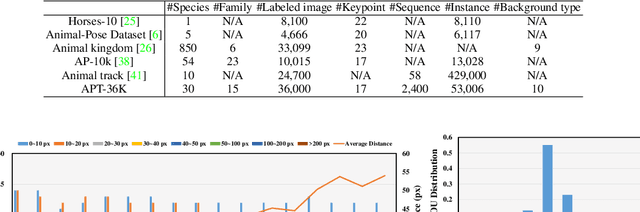
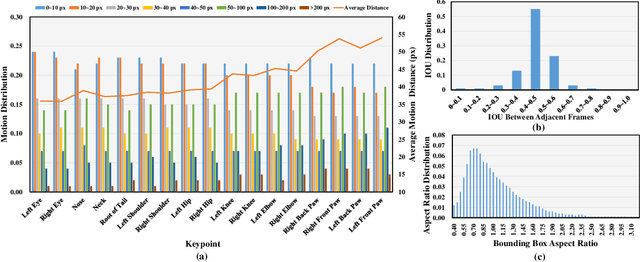

Animal pose estimation and tracking (APT) is a fundamental task for detecting and tracking animal keypoints from a sequence of video frames. Previous animal-related datasets focus either on animal tracking or single-frame animal pose estimation, and never on both aspects. The lack of APT datasets hinders the development and evaluation of video-based animal pose estimation and tracking methods, limiting real-world applications, e.g., understanding animal behavior in wildlife conservation. To fill this gap, we make the first step and propose APT-36K, i.e., the first large-scale benchmark for animal pose estimation and tracking. Specifically, APT-36K consists of 2,400 video clips collected and filtered from 30 animal species with 15 frames for each video, resulting in 36,000 frames in total. After manual annotation and careful double-check, high-quality keypoint and tracking annotations are provided for all the animal instances. Based on APT-36K, we benchmark several representative models on the following three tracks: (1) supervised animal pose estimation on a single frame under intra- and inter-domain transfer learning settings, (2) inter-species domain generalization test for unseen animals, and (3) animal pose estimation with animal tracking. Based on the experimental results, we gain some empirical insights and show that APT-36K provides a valuable animal pose estimation and tracking benchmark, offering new challenges and opportunities for future research. The code and dataset will be made publicly available at https://github.com/pandorgan/APT-36K.
ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
Apr 26, 2022


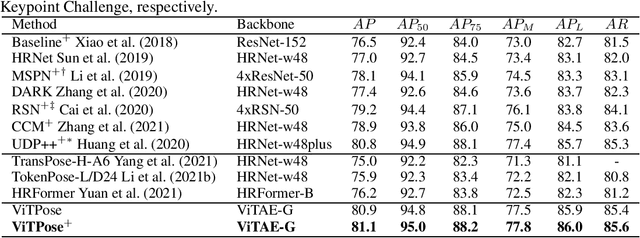
Recently, customized vision transformers have been adapted for human pose estimation and have achieved superior performance with elaborate structures. However, it is still unclear whether plain vision transformers can facilitate pose estimation. In this paper, we take the first step toward answering the question by employing a plain and non-hierarchical vision transformer together with simple deconvolution decoders termed ViTPose for human pose estimation. We demonstrate that a plain vision transformer with MAE pretraining can obtain superior performance after finetuning on human pose estimation datasets. ViTPose has good scalability with respect to model size and flexibility regarding input resolution and token number. Moreover, it can be easily pretrained using the unlabeled pose data without the need for large-scale upstream ImageNet data. Our biggest ViTPose model based on the ViTAE-G backbone with 1 billion parameters obtains the best 80.9 mAP on the MS COCO test-dev set, while the ensemble models further set a new state-of-the-art for human pose estimation, i.e., 81.1 mAP. The source code and models will be released at https://github.com/ViTAE-Transformer/ViTPose.
VSA: Learning Varied-Size Window Attention in Vision Transformers
Apr 18, 2022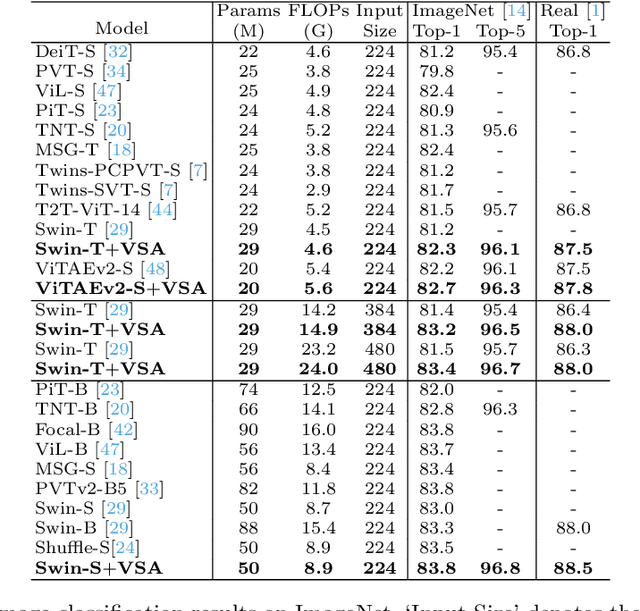
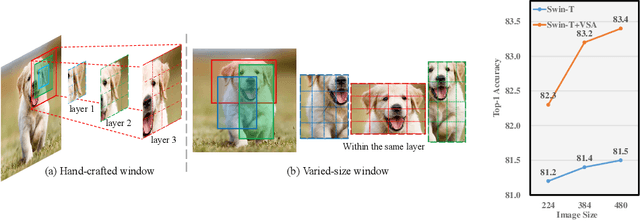
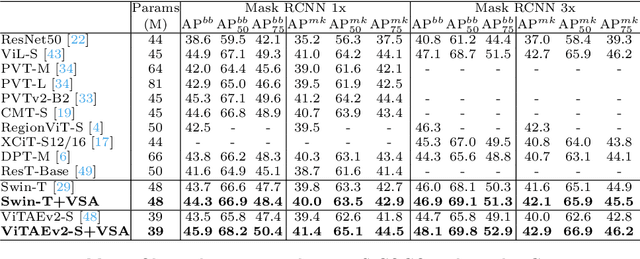
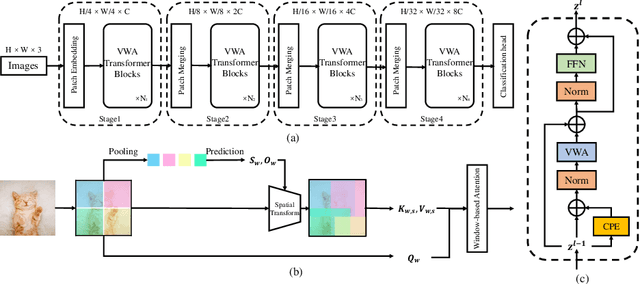
Attention within windows has been widely explored in vision transformers to balance the performance, computation complexity, and memory footprint. However, current models adopt a hand-crafted fixed-size window design, which restricts their capacity of modeling long-term dependencies and adapting to objects of different sizes. To address this drawback, we propose \textbf{V}aried-\textbf{S}ize Window \textbf{A}ttention (VSA) to learn adaptive window configurations from data. Specifically, based on the tokens within each default window, VSA employs a window regression module to predict the size and location of the target window, i.e., the attention area where the key and value tokens are sampled. By adopting VSA independently for each attention head, it can model long-term dependencies, capture rich context from diverse windows, and promote information exchange among overlapped windows. VSA is an easy-to-implement module that can replace the window attention in state-of-the-art representative models with minor modifications and negligible extra computational cost while improving their performance by a large margin, e.g., 1.1\% for Swin-T on ImageNet classification. In addition, the performance gain increases when using larger images for training and test. Experimental results on more downstream tasks, including object detection, instance segmentation, and semantic segmentation, further demonstrate the superiority of VSA over the vanilla window attention in dealing with objects of different sizes. The code will be released https://github.com/ViTAE-Transformer/ViTAE-VSA.
ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond
Feb 21, 2022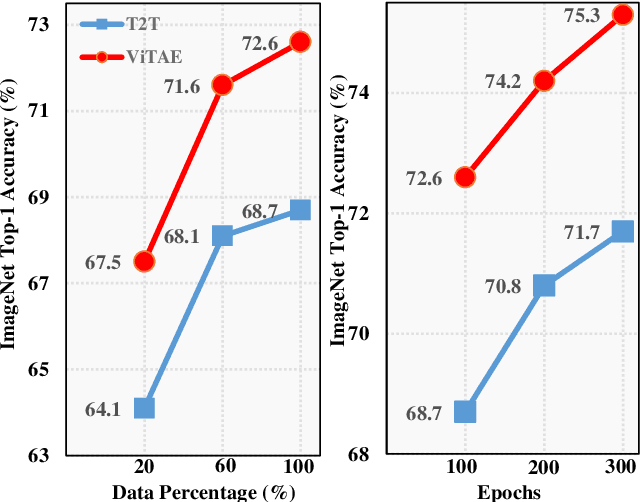
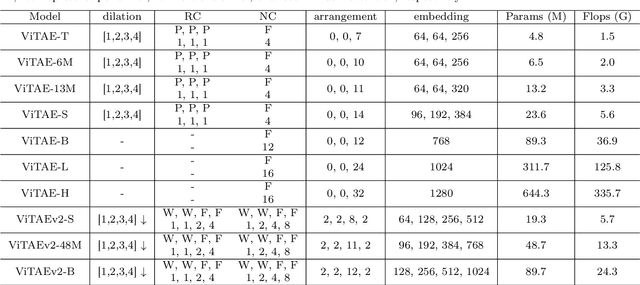
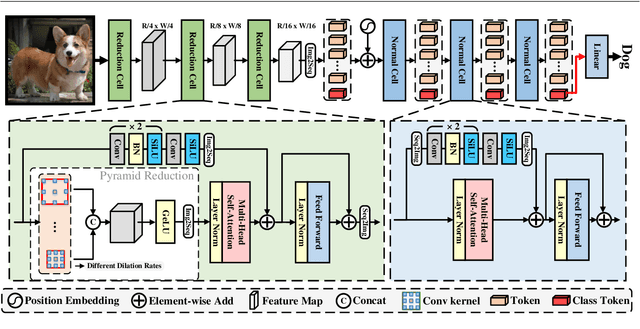
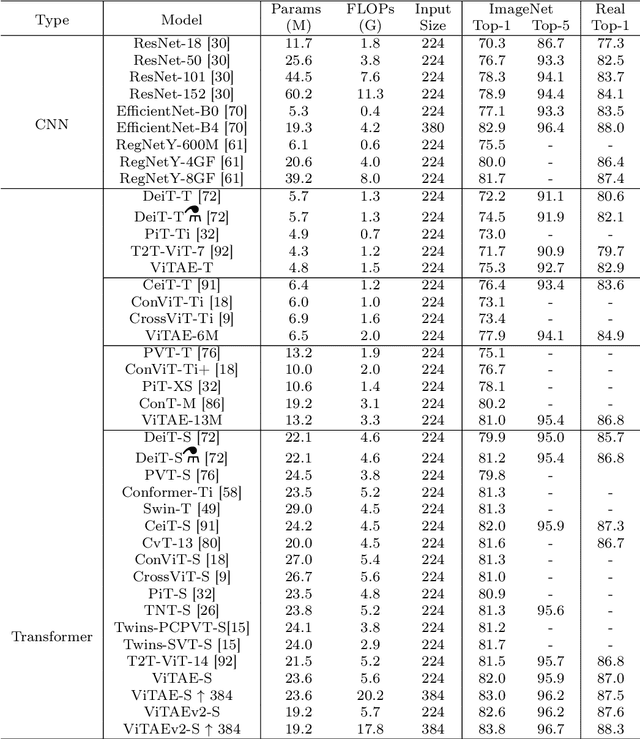
Vision transformers have shown great potential in various computer vision tasks owing to their strong capability to model long-range dependency using the self-attention mechanism. Nevertheless, they treat an image as a 1D sequence of visual tokens, lacking an intrinsic inductive bias (IB) in modeling local visual structures and dealing with scale variance, which is instead learned implicitly from large-scale training data with longer training schedules. In this paper, we propose a Vision Transformer Advanced by Exploring intrinsic IB from convolutions, i.e., ViTAE. Technically, ViTAE has several spatial pyramid reduction modules to downsample and embed the input image into tokens with rich multi-scale context using multiple convolutions with different dilation rates. In this way, it acquires an intrinsic scale invariance IB and can learn robust feature representation for objects at various scales. Moreover, in each transformer layer, ViTAE has a convolution block parallel to the multi-head self-attention module, whose features are fused and fed into the feed-forward network. Consequently, it has the intrinsic locality IB and is able to learn local features and global dependencies collaboratively. The proposed two kinds of cells are stacked in both isotropic and multi-stage manners to formulate two families of ViTAE models, i.e., the vanilla ViTAE and ViTAEv2. Experiments on the ImageNet dataset as well as downstream tasks on the MS COCO, ADE20K, and AP10K datasets validate the superiority of our models over the baseline transformer models and concurrent works. Besides, we scale up our ViTAE model to 644M parameters and obtain the state-of-the-art classification performance, i.e., 88.5% Top-1 classification accuracy on ImageNet validation set and the best 91.2% Top-1 accuracy on ImageNet real validation set, without using extra private data.
RegionCL: Can Simple Region Swapping Contribute to Contrastive Learning?
Nov 24, 2021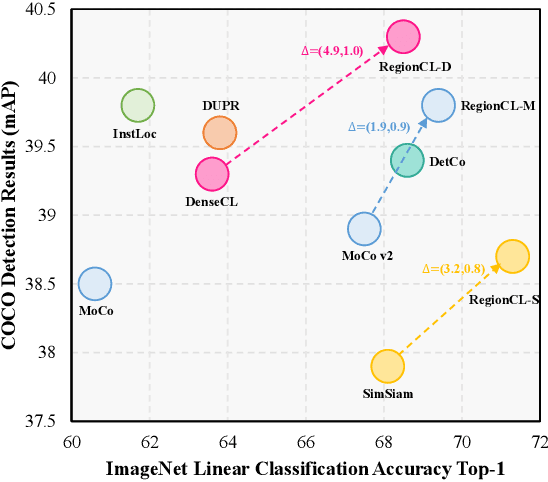
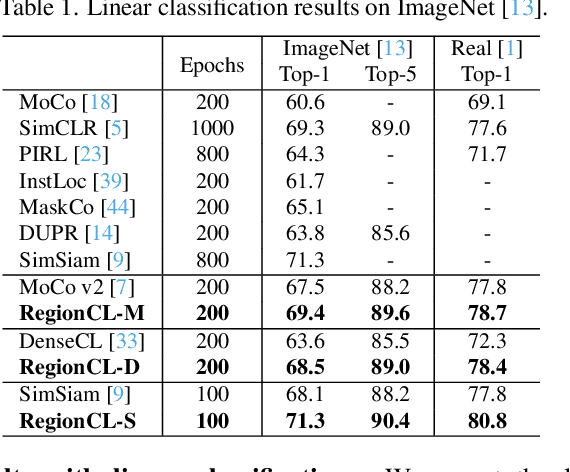
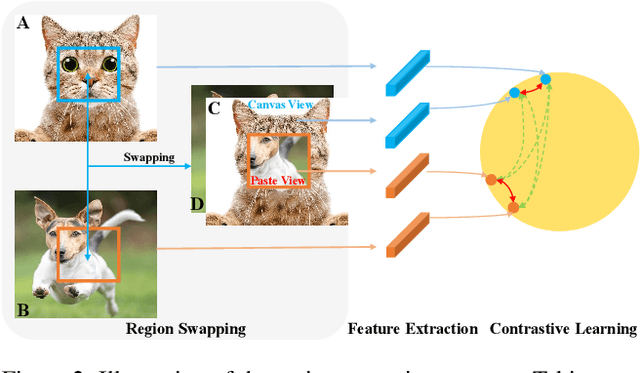
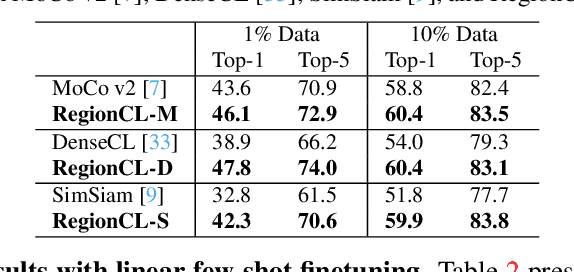
Self-supervised methods (SSL) have achieved significant success via maximizing the mutual information between two augmented views, where cropping is a popular augmentation technique. Cropped regions are widely used to construct positive pairs, while the left regions after cropping have rarely been explored in existing methods, although they together constitute the same image instance and both contribute to the description of the category. In this paper, we make the first attempt to demonstrate the importance of both regions in cropping from a complete perspective and propose a simple yet effective pretext task called Region Contrastive Learning (RegionCL). Specifically, given two different images, we randomly crop a region (called the paste view) from each image with the same size and swap them to compose two new images together with the left regions (called the canvas view), respectively. Then, contrastive pairs can be efficiently constructed according to the following simple criteria, i.e., each view is (1) positive with views augmented from the same original image and (2) negative with views augmented from other images. With minor modifications to popular SSL methods, RegionCL exploits those abundant pairs and helps the model distinguish the regions features from both canvas and paste views, therefore learning better visual representations. Experiments on ImageNet, MS COCO, and Cityscapes demonstrate that RegionCL improves MoCo v2, DenseCL, and SimSiam by large margins and achieves state-of-the-art performance on classification, detection, and segmentation tasks. The code will be available at https://github.com/Annbless/RegionCL.git.