 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing the Accuracy-Communication-Privacy Trade-off in Distributed Stochastic Convex Optimization
Jan 06, 2025We consider the problem of differentially private stochastic convex optimization (DP-SCO) in a distributed setting with $M$ clients, where each of them has a local dataset of $N$ i.i.d. data samples from an underlying data distribution. The objective is to design an algorithm to minimize a convex population loss using a collaborative effort across $M$ clients, while ensuring the privacy of the local datasets. In this work, we investigate the accuracy-communication-privacy trade-off for this problem. We establish matching converse and achievability results using a novel lower bound and a new algorithm for distributed DP-SCO based on Vaidya's plane cutting method. Thus, our results provide a complete characterization of the accuracy-communication-privacy trade-off for DP-SCO in the distributed setting.
Vertical Federated Learning with Missing Features During Training and Inference
Oct 29, 2024


Vertical federated learning trains models from feature-partitioned datasets across multiple clients, who collaborate without sharing their local data. Standard approaches assume that all feature partitions are available during both training and inference. Yet, in practice, this assumption rarely holds, as for many samples only a subset of the clients observe their partition. However, not utilizing incomplete samples during training harms generalization, and not supporting them during inference limits the utility of the model. Moreover, if any client leaves the federation after training, its partition becomes unavailable, rendering the learned model unusable. Missing feature blocks are therefore a key challenge limiting the applicability of vertical federated learning in real-world scenarios. To address this, we propose LASER-VFL, a vertical federated learning method for efficient training and inference of split neural network-based models that is capable of handling arbitrary sets of partitions. Our approach is simple yet effective, relying on the strategic sharing of model parameters and on task-sampling to train a family of predictors. We show that LASER-VFL achieves a $\mathcal{O}({1}/{\sqrt{T}})$ convergence rate for nonconvex objectives in general, $\mathcal{O}({1}/{T})$ for sufficiently large batch sizes, and linear convergence under the Polyak-{\L}ojasiewicz inequality. Numerical experiments show improved performance of LASER-VFL over the baselines. Remarkably, this is the case even in the absence of missing features. For example, for CIFAR-100, we see an improvement in accuracy of $21.4\%$ when each of four feature blocks is observed with a probability of 0.5 and of $12.2\%$ when all features are observed.
ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM Inference
Oct 28, 2024With the widespread deployment of long-context large language models (LLMs), there has been a growing demand for efficient support of high-throughput inference. However, as the key-value (KV) cache expands with the sequence length, the increasing memory footprint and the need to access it for each token generation both result in low throughput when serving long-context LLMs. While various dynamic sparse attention methods have been proposed to speed up inference while maintaining generation quality, they either fail to sufficiently reduce GPU memory consumption or introduce significant decoding latency by offloading the KV cache to the CPU. We present ShadowKV, a high-throughput long-context LLM inference system that stores the low-rank key cache and offloads the value cache to reduce the memory footprint for larger batch sizes and longer sequences. To minimize decoding latency, ShadowKV employs an accurate KV selection strategy that reconstructs minimal sparse KV pairs on-the-fly. By evaluating ShadowKV on a broad range of benchmarks, including RULER, LongBench, and Needle In A Haystack, and models like Llama-3.1-8B, Llama-3-8B-1M, GLM-4-9B-1M, Yi-9B-200K, Phi-3-Mini-128K, and Qwen2-7B-128K, we demonstrate that it can support up to 6$\times$ larger batch sizes and boost throughput by up to 3.04$\times$ on an A100 GPU without sacrificing accuracy, even surpassing the performance achievable with infinite batch size under the assumption of infinite GPU memory. The code is available at https://github.com/bytedance/ShadowKV.
Faster WIND: Accelerating Iterative Best-of-$N$ Distillation for LLM Alignment
Oct 28, 2024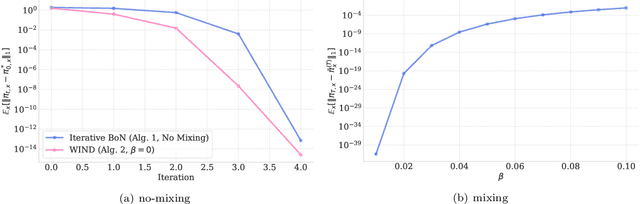
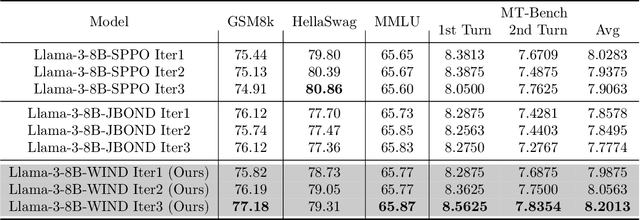
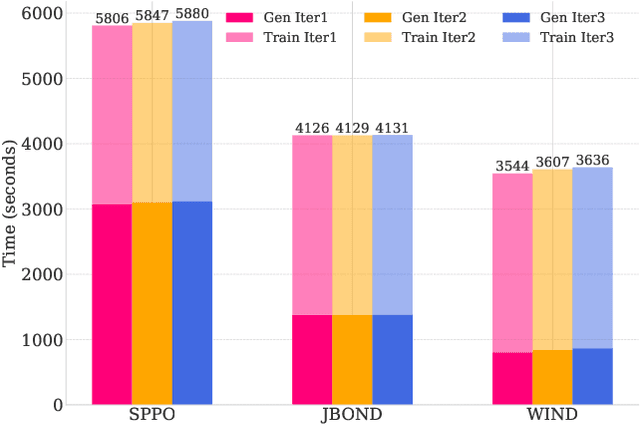
Recent advances in aligning large language models with human preferences have corroborated the growing importance of best-of-N distillation (BOND). However, the iterative BOND algorithm is prohibitively expensive in practice due to the sample and computation inefficiency. This paper addresses the problem by revealing a unified game-theoretic connection between iterative BOND and self-play alignment, which unifies seemingly disparate algorithmic paradigms. Based on the connection, we establish a novel framework, WIN rate Dominance (WIND), with a series of efficient algorithms for regularized win rate dominance optimization that approximates iterative BOND in the parameter space. We provides provable sample efficiency guarantee for one of the WIND variant with the square loss objective. The experimental results confirm that our algorithm not only accelerates the computation, but also achieves superior sample efficiency compared to existing methods.
Leveraging Multimodal Diffusion Models to Accelerate Imaging with Side Information
Oct 07, 2024



Diffusion models have found phenomenal success as expressive priors for solving inverse problems, but their extension beyond natural images to more structured scientific domains remains limited. Motivated by applications in materials science, we aim to reduce the number of measurements required from an expensive imaging modality of interest, by leveraging side information from an auxiliary modality that is much cheaper to obtain. To deal with the non-differentiable and black-box nature of the forward model, we propose a framework to train a multimodal diffusion model over the joint modalities, turning inverse problems with black-box forward models into simple linear inpainting problems. Numerically, we demonstrate the feasibility of training diffusion models over materials imagery data, and show that our approach achieves superior image reconstruction by leveraging the available side information, requiring significantly less amount of data from the expensive microscopy modality.
Can We Break the Curse of Multiagency in Robust Multi-Agent Reinforcement Learning?
Sep 30, 2024
Standard multi-agent reinforcement learning (MARL) algorithms are vulnerable to sim-to-real gaps. To address this, distributionally robust Markov games (RMGs) have been proposed to enhance robustness in MARL by optimizing the worst-case performance when game dynamics shift within a prescribed uncertainty set. Solving RMGs remains under-explored, from problem formulation to the development of sample-efficient algorithms. A notorious yet open challenge is if RMGs can escape the curse of multiagency, where the sample complexity scales exponentially with the number of agents. In this work, we propose a natural class of RMGs where the uncertainty set of each agent is shaped by both the environment and other agents' strategies in a best-response manner. We first establish the well-posedness of these RMGs by proving the existence of game-theoretic solutions such as robust Nash equilibria and coarse correlated equilibria (CCE). Assuming access to a generative model, we then introduce a sample-efficient algorithm for learning the CCE whose sample complexity scales polynomially with all relevant parameters. To the best of our knowledge, this is the first algorithm to break the curse of multiagency for RMGs.
The Sample-Communication Complexity Trade-off in Federated Q-Learning
Aug 30, 2024



We consider the problem of federated Q-learning, where $M$ agents aim to collaboratively learn the optimal Q-function of an unknown infinite-horizon Markov decision process with finite state and action spaces. We investigate the trade-off between sample and communication complexities for the widely used class of intermittent communication algorithms. We first establish the converse result, where it is shown that a federated Q-learning algorithm that offers any speedup with respect to the number of agents in the per-agent sample complexity needs to incur a communication cost of at least an order of $\frac{1}{1-\gamma}$ up to logarithmic factors, where $\gamma$ is the discount factor. We also propose a new algorithm, called Fed-DVR-Q, which is the first federated Q-learning algorithm to simultaneously achieve order-optimal sample and communication complexities. Thus, together these results provide a complete characterization of the sample-communication complexity trade-off in federated Q-learning.
In-Context Learning with Representations: Contextual Generalization of Trained Transformers
Aug 19, 2024



In-context learning (ICL) refers to a remarkable capability of pretrained large language models, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to in-contextly predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.
A Sharp Convergence Theory for The Probability Flow ODEs of Diffusion Models
Aug 05, 2024Diffusion models, which convert noise into new data instances by learning to reverse a diffusion process, have become a cornerstone in contemporary generative modeling. In this work, we develop non-asymptotic convergence theory for a popular diffusion-based sampler (i.e., the probability flow ODE sampler) in discrete time, assuming access to $\ell_2$-accurate estimates of the (Stein) score functions. For distributions in $\mathbb{R}^d$, we prove that $d/\varepsilon$ iterations -- modulo some logarithmic and lower-order terms -- are sufficient to approximate the target distribution to within $\varepsilon$ total-variation distance. This is the first result establishing nearly linear dimension-dependency (in $d$) for the probability flow ODE sampler. Imposing only minimal assumptions on the target data distribution (e.g., no smoothness assumption is imposed), our results also characterize how $\ell_2$ score estimation errors affect the quality of the data generation processes. In contrast to prior works, our theory is developed based on an elementary yet versatile non-asymptotic approach without the need of resorting to SDE and ODE toolboxes.
Learning Discrete Concepts in Latent Hierarchical Models
Jun 01, 2024



Learning concepts from natural high-dimensional data (e.g., images) holds potential in building human-aligned and interpretable machine learning models. Despite its encouraging prospect, formalization and theoretical insights into this crucial task are still lacking. In this work, we formalize concepts as discrete latent causal variables that are related via a hierarchical causal model that encodes different abstraction levels of concepts embedded in high-dimensional data (e.g., a dog breed and its eye shapes in natural images). We formulate conditions to facilitate the identification of the proposed causal model, which reveals when learning such concepts from unsupervised data is possible. Our conditions permit complex causal hierarchical structures beyond latent trees and multi-level directed acyclic graphs in prior work and can handle high-dimensional, continuous observed variables, which is well-suited for unstructured data modalities such as images. We substantiate our theoretical claims with synthetic data experiments. Further, we discuss our theory's implications for understanding the underlying mechanisms of latent diffusion models and provide corresponding empirical evidence for our theoretical insights.