 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARS: Sparse Learning Correlation Filter with Spatio-temporal Regularization and Super-resolution Reconstruction for Thermal Infrared Target Tracking
Apr 20, 2025Thermal infrared (TIR) target tracking methods often adopt the correlation filter (CF) framework due to its computational efficiency. However, the low resolution of TIR images, along with tracking interference, significantly limits the perfor-mance of TIR trackers. To address these challenges, we introduce STARS, a novel sparse learning-based CF tracker that incorporates spatio-temporal regulari-zation and super-resolution reconstruction. First, we apply adaptive sparse filter-ing and temporal domain filtering to extract key features of the target while reduc-ing interference from background clutter and noise. Next, we introduce an edge-preserving sparse regularization method to stabilize target features and prevent excessive blurring. This regularization integrates multiple terms and employs the alternating direction method of multipliers to optimize the solution. Finally, we propose a gradient-enhanced super-resolution method to extract fine-grained TIR target features and improve the resolution of TIR images, addressing performance degradation in tracking caused by low-resolution sequences. To the best of our knowledge, STARS is the first to integrate super-resolution methods within a sparse learning-based CF framework. Extensive experiments on the LSOTB-TIR, PTB-TIR, VOT-TIR2015, and VOT-TIR2017 benchmarks demonstrate that STARS outperforms state-of-the-art trackers in terms of robustness.
SConU: Selective Conformal Uncertainty in Large Language Models
Apr 19, 2025As large language models are increasingly utilized in real-world applications, guarantees of task-specific metrics are essential for their reliable deployment. Previous studies have introduced various criteria of conformal uncertainty grounded in split conformal prediction, which offer user-specified correctness coverage. However, existing frameworks often fail to identify uncertainty data outliers that violate the exchangeability assumption, leading to unbounded miscoverage rates and unactionable prediction sets. In this paper, we propose a novel approach termed Selective Conformal Uncertainty (SConU), which, for the first time, implements significance tests, by developing two conformal p-values that are instrumental in determining whether a given sample deviates from the uncertainty distribution of the calibration set at a specific manageable risk level. Our approach not only facilitates rigorous management of miscoverage rates across both single-domain and interdisciplinary contexts, but also enhances the efficiency of predictions. Furthermore, we comprehensively analyze the components of the conformal procedures, aiming to approximate conditional coverage, particularly in high-stakes question-answering tasks.
DCFG: Diverse Cross-Channel Fine-Grained Feature Learning and Progressive Fusion Siamese Tracker for Thermal Infrared Target Tracking
Apr 19, 2025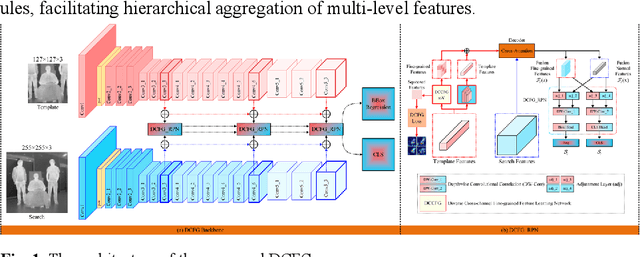

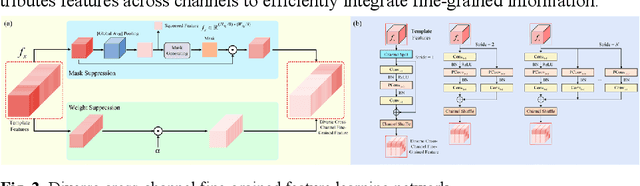

To address the challenge of capturing highly discriminative features in ther-mal infrared (TIR) tracking, we propose a novel Siamese tracker based on cross-channel fine-grained feature learning and progressive fusion. First, we introduce a cross-channel fine-grained feature learning network that employs masks and suppression coefficients to suppress dominant target features, en-abling the tracker to capture more detailed and subtle information. The net-work employs a channel rearrangement mechanism to enhance efficient in-formation flow, coupled with channel equalization to reduce parameter count. Additionally, we incorporate layer-by-layer combination units for ef-fective feature extraction and fusion, thereby minimizing parameter redun-dancy and computational complexity. The network further employs feature redirection and channel shuffling strategies to better integrate fine-grained details. Second, we propose a specialized cross-channel fine-grained loss function designed to guide feature groups toward distinct discriminative re-gions of the target, thus improving overall target representation. This loss function includes an inter-channel loss term that promotes orthogonality be-tween channels, maximizing feature diversity and facilitating finer detail capture. Extensive experiments demonstrate that our proposed tracker achieves the highest accuracy, scoring 0.81 on the VOT-TIR 2015 and 0.78 on the VOT-TIR 2017 benchmark, while also outperforming other methods across all evaluation metrics on the LSOTB-TIR and PTB-TIR benchmarks.
FGSGT: Saliency-Guided Siamese Network Tracker Based on Key Fine-Grained Feature Information for Thermal Infrared Target Tracking
Apr 19, 2025Thermal infrared (TIR) images typically lack detailed features and have low contrast, making it challenging for conventional feature extraction models to capture discriminative target characteristics. As a result, trackers are often affected by interference from visually similar objects and are susceptible to tracking drift. To address these challenges, we propose a novel saliency-guided Siamese network tracker based on key fine-grained feature infor-mation. First, we introduce a fine-grained feature parallel learning convolu-tional block with a dual-stream architecture and convolutional kernels of varying sizes. This design captures essential global features from shallow layers, enhances feature diversity, and minimizes the loss of fine-grained in-formation typically encountered in residual connections. In addition, we propose a multi-layer fine-grained feature fusion module that uses bilinear matrix multiplication to effectively integrate features across both deep and shallow layers. Next, we introduce a Siamese residual refinement block that corrects saliency map prediction errors using residual learning. Combined with deep supervision, this mechanism progressively refines predictions, ap-plying supervision at each recursive step to ensure consistent improvements in accuracy. Finally, we present a saliency loss function to constrain the sali-ency predictions, directing the network to focus on highly discriminative fi-ne-grained features. Extensive experiment results demonstrate that the pro-posed tracker achieves the highest precision and success rates on the PTB-TIR and LSOTB-TIR benchmarks. It also achieves a top accuracy of 0.78 on the VOT-TIR 2015 benchmark and 0.75 on the VOT-TIR 2017 benchmark.
RAMCT: Novel Region-adaptive Multi-channel Tracker with Iterative Tikhonov Regularization for Thermal Infrared Tracking
Apr 19, 2025Correlation filter (CF)-based trackers have gained significant attention for their computational efficiency in thermal infrared (TIR) target tracking. However, ex-isting methods struggle with challenges such as low-resolution imagery, occlu-sion, background clutter, and target deformation, which severely impact tracking performance. To overcome these limitations, we propose RAMCT, a region-adaptive sparse correlation filter tracker that integrates multi-channel feature opti-mization with an adaptive regularization strategy. Firstly, we refine the CF learn-ing process by introducing a spatially adaptive binary mask, which enforces spar-sity in the target region while dynamically suppressing background interference. Secondly, we introduce generalized singular value decomposition (GSVD) and propose a novel GSVD-based region-adaptive iterative Tikhonov regularization method. This enables flexible and robust optimization across multiple feature channels, improving resilience to occlusion and background variations. Thirdly, we propose an online optimization strategy with dynamic discrepancy-based pa-rameter adjustment. This mechanism facilitates real time adaptation to target and background variations, thereby improving tracking accuracy and robustness. Ex-tensive experiments on LSOTB-TIR, PTB-TIR, VOT-TIR2015, and VOT-TIR2017 benchmarks demonstrate that RAMCT outperforms other state-of-the-art trackers in terms of accuracy and robustness.
An Efficient Quantum Classifier Based on Hamiltonian Representations
Apr 13, 2025



Quantum machine learning (QML) is a discipline that seeks to transfer the advantages of quantum computing to data-driven tasks. However, many studies rely on toy datasets or heavy feature reduction, raising concerns about their scalability. Progress is further hindered by hardware limitations and the significant costs of encoding dense vector representations on quantum devices. To address these challenges, we propose an efficient approach called Hamiltonian classifier that circumvents the costs associated with data encoding by mapping inputs to a finite set of Pauli strings and computing predictions as their expectation values. In addition, we introduce two classifier variants with different scaling in terms of parameters and sample complexity. We evaluate our approach on text and image classification tasks, against well-established classical and quantum models. The Hamiltonian classifier delivers performance comparable to or better than these methods. Notably, our method achieves logarithmic complexity in both qubits and quantum gates, making it well-suited for large-scale, real-world applications. We make our implementation available on GitHub.
Enhancing Mobile Crowdsensing Efficiency: A Coverage-aware Resource Allocation Approach
Mar 27, 2025



In this study, we investigate the resource management challenges in next-generation mobile crowdsensing networks with the goal of minimizing task completion latency while ensuring coverage performance, i.e., an essential metric to ensure comprehensive data collection across the monitored area, yet it has been commonly overlooked in existing studies. To this end, we formulate a weighted latency and coverage gap minimization problem via jointly optimizing user selection, subchannel allocation, and sensing task allocation. The formulated minimization problem is a non-convex mixed-integer programming issue. To facilitate the analysis, we decompose the original optimization problem into two subproblems. One focuses on optimizing sensing task and subband allocation under fixed sensing user selection, which is optimally solved by the Hungarian algorithm via problem reformulation. Building upon these findings, we introduce a time-efficient two-sided swapping method to refine the scheduled user set and enhance system performance. Extensive numerical results demonstrate the effectiveness of our proposed approach compared to various benchmark strategies.
A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond
Mar 27, 2025Recent Large Reasoning Models (LRMs), such as DeepSeek-R1 and OpenAI o1, have demonstrated strong performance gains by scaling up the length of Chain-of-Thought (CoT) reasoning during inference. However, a growing concern lies in their tendency to produce excessively long reasoning traces, which are often filled with redundant content (e.g., repeated definitions), over-analysis of simple problems, and superficial exploration of multiple reasoning paths for harder tasks. This inefficiency introduces significant challenges for training, inference, and real-world deployment (e.g., in agent-based systems), where token economy is critical. In this survey, we provide a comprehensive overview of recent efforts aimed at improving reasoning efficiency in LRMs, with a particular focus on the unique challenges that arise in this new paradigm. We identify common patterns of inefficiency, examine methods proposed across the LRM lifecycle, i.e., from pretraining to inference, and discuss promising future directions for research. To support ongoing development, we also maintain a real-time GitHub repository tracking recent progress in the field. We hope this survey serves as a foundation for further exploration and inspires innovation in this rapidly evolving area.
Rethinking Vision-Language Model in Face Forensics: Multi-Modal Interpretable Forged Face Detector
Mar 26, 2025Deepfake detection is a long-established research topic vital for mitigating the spread of malicious misinformation. Unlike prior methods that provide either binary classification results or textual explanations separately, we introduce a novel method capable of generating both simultaneously. Our method harnesses the multi-modal learning capability of the pre-trained CLIP and the unprecedented interpretability of large language models (LLMs) to enhance both the generalization and explainability of deepfake detection. Specifically, we introduce a multi-modal face forgery detector (M2F2-Det) that employs tailored face forgery prompt learning, incorporating the pre-trained CLIP to improve generalization to unseen forgeries. Also, M2F2-Det incorporates an LLM to provide detailed textual explanations of its detection decisions, enhancing interpretability by bridging the gap between natural language and subtle cues of facial forgeries. Empirically, we evaluate M2F2-Det on both detection and explanation generation tasks, where it achieves state-of-the-art performance, demonstrating its effectiveness in identifying and explaining diverse forgeries.
Exploring Model Editing for LLM-based Aspect-Based Sentiment Classification
Mar 19, 2025



Model editing aims at selectively updating a small subset of a neural model's parameters with an interpretable strategy to achieve desired modifications. It can significantly reduce computational costs to adapt to large language models (LLMs). Given its ability to precisely target critical components within LLMs, model editing shows great potential for efficient fine-tuning applications. In this work, we investigate model editing to serve an efficient method for adapting LLMs to solve aspect-based sentiment classification. Through causal interventions, we trace and determine which neuron hidden states are essential for the prediction of the model. By performing interventions and restorations on each component of an LLM, we identify the importance of these components for aspect-based sentiment classification. Our findings reveal that a distinct set of mid-layer representations is essential for detecting the sentiment polarity of given aspect words. Leveraging these insights, we develop a model editing approach that focuses exclusively on these critical parts of the LLM, leading to a more efficient method for adapting LLMs. Our in-domain and out-of-domain experiments demonstrate that this approach achieves competitive results compared to the currently strongest methods with significantly fewer trainable parameters, highlighting a more efficient and interpretable fine-tuning strategy.