 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll are Worth Words: a ViT Backbone for Score-based Diffusion Models
Sep 25, 2022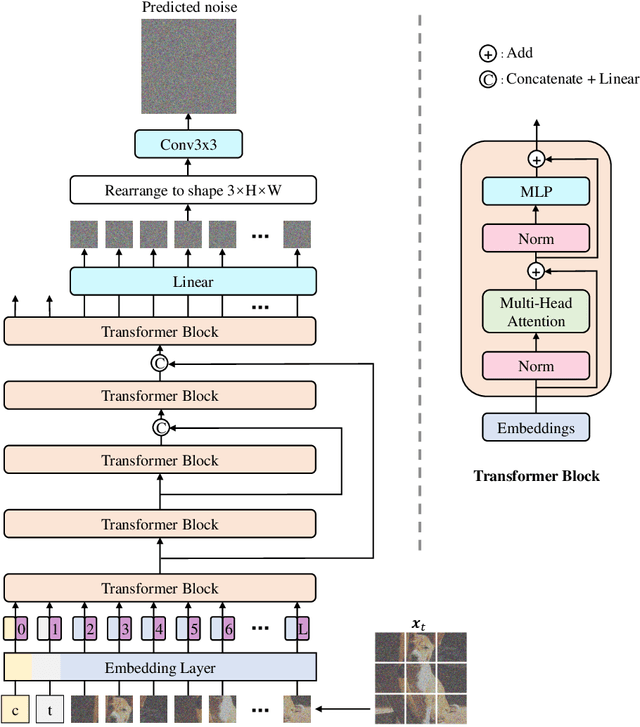
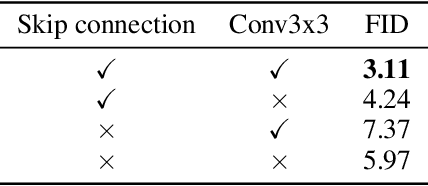
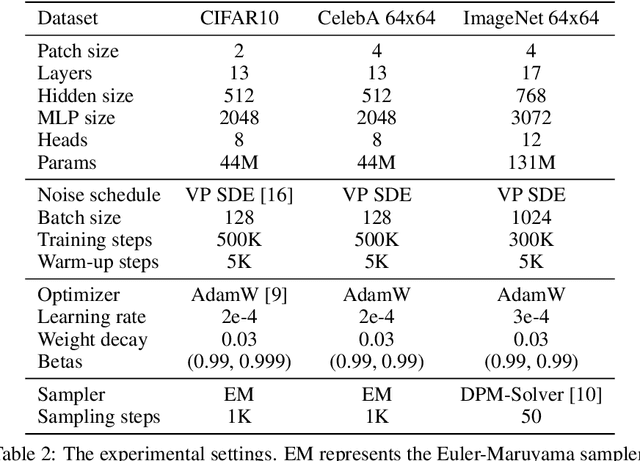

Vision transformers (ViT) have shown promise in various vision tasks including low-level ones while the U-Net remains dominant in score-based diffusion models. In this paper, we perform a systematical empirical study on the ViT-based architectures in diffusion models. Our results suggest that adding extra long skip connections (like the U-Net) to ViT is crucial to diffusion models. The new ViT architecture, together with other improvements, is referred to as U-ViT. On several popular visual datasets, U-ViT achieves competitive generation results to SOTA U-Net while requiring comparable amount of parameters and computation if not less.
Geo-Spatio-Temporal Information Based 3D Cooperative Positioning in LOS/NLOS Mixed Environments
Sep 02, 2022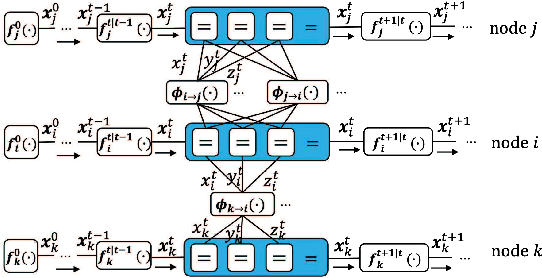
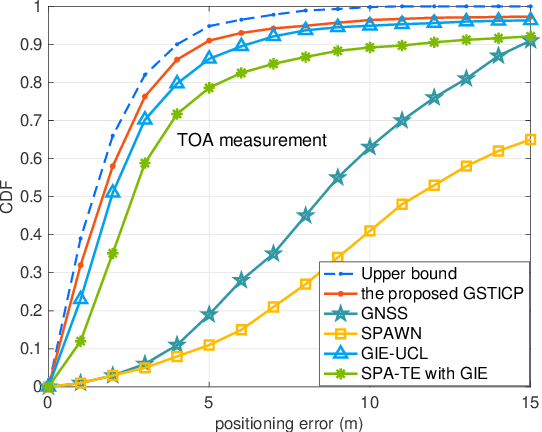
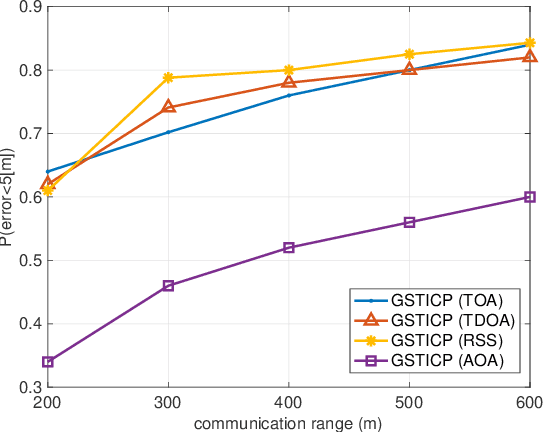
We propose a geographic and spatio-temporal information based distributed cooperative positioning (GSTICP) algorithm for wireless networks that require three-dimensional (3D) coordinates and operate in the line-of-sight (LOS) and nonline-of-sight (NLOS) mixed environments. First, a factor graph (FG) is created by factorizing the a posteriori distribution of the position-vector estimates and mapping the spatial-domain and temporal-domain operations of nodes onto the FG. Then, we exploit a geographic information based NLOS identification scheme to reduce the performance degradation caused by NLOS measurements. Furthermore, we utilize a finite symmetric sampling based scaled unscented transform (SUT) method to approximate the nonlinear terms of the messages passing on the FG with high precision, despite using only a small number of samples. Finally, we propose an enhanced anchor upgrading (EAU) mechanism to avoid redundant iterations. Our GSTICP algorithm supports any type of ranging measurement that can determine the distance between nodes. Simulation results and analysis demonstrate that our GSTICP has a lower computational complexity than the state-of-the-art belief propagation (BP) based localizers, while achieving an even more competitive positioning performance.
Distributed Spatio-Temporal Information Based Cooperative 3D Positioning in GNSS-Denied Environments
Aug 25, 2022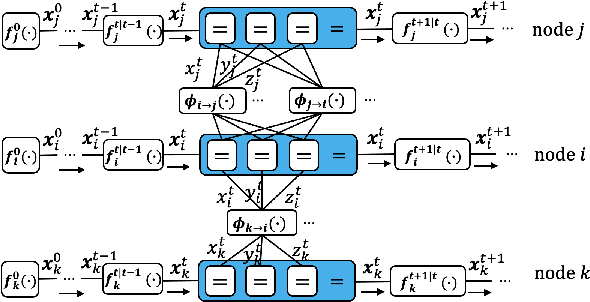
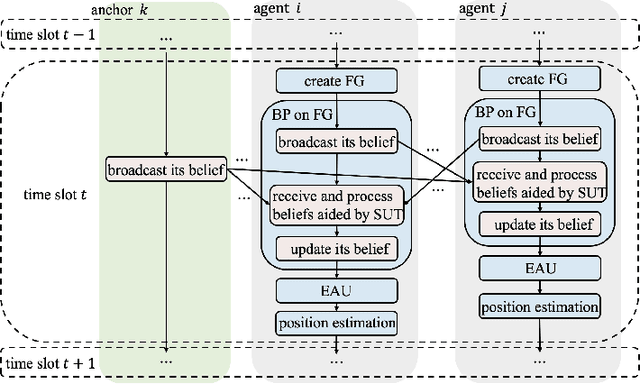
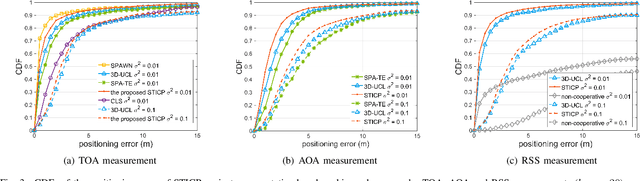
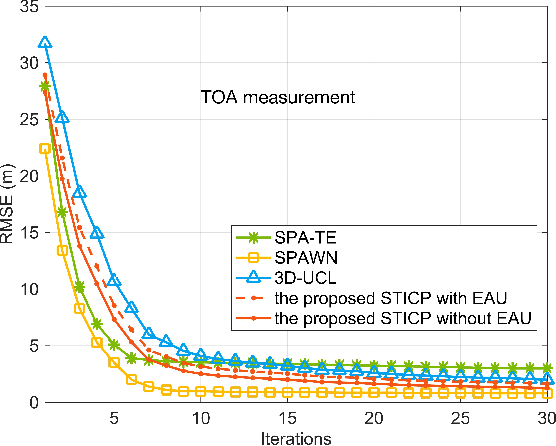
A distributed spatio-temporal information based cooperative positioning (STICP) algorithm is proposed for wireless networks that require three-dimensional (3D) coordinates and operate in the global navigation satellite system (GNSS) denied environments. Our algorithm supports any type of ranging measurements that can determine the distance between nodes. We first utilize a finite symmetric sampling based scaled unscented transform (SUT) method for approximating the nonlinear terms of the messages passing on the associated factor graph (FG) with high precision, despite relying on a small number of samples. Then, we propose an enhanced anchor upgrading mechanism to avoid any redundant iterations. Our simulation results and analysis show that the proposed STICP has a lower computational complexity than the state-of-the-art belief propagation based localizer, despite achieving an even more competitive positioning performance.
Contrastive Information Transfer for Pre-Ranking Systems
Jul 07, 2022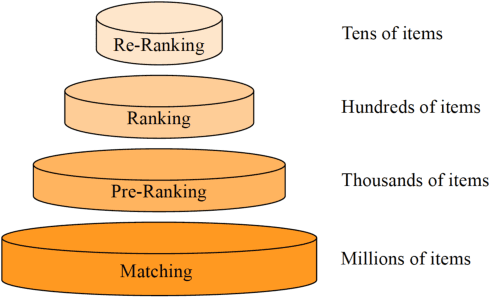
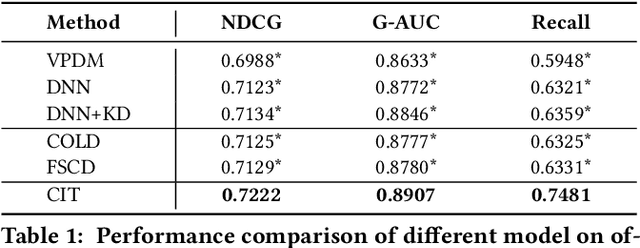
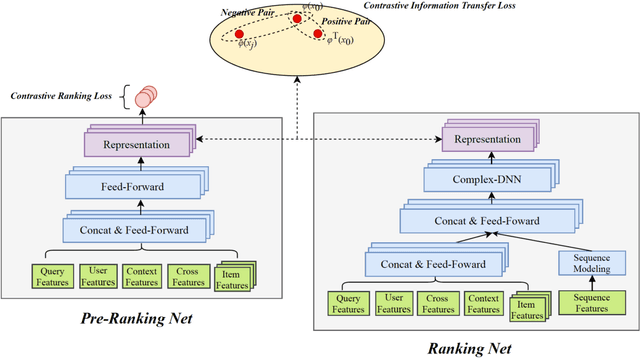
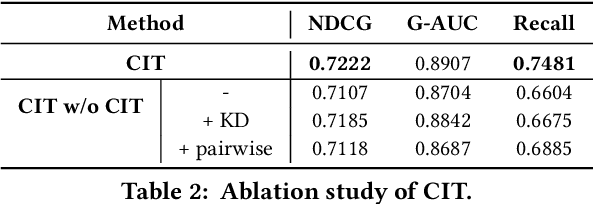
Real-word search and recommender systems usually adopt a multi-stage ranking architecture, including matching, pre-ranking, ranking, and re-ranking. Previous works mainly focus on the ranking stage while very few focus on the pre-ranking stage. In this paper, we focus on the information transfer from ranking to pre-ranking stage. We propose a new Contrastive Information Transfer (CIT) framework to transfer useful information from ranking model to pre-ranking model. We train the pre-ranking model to distinguish the positive pair of representation from a set of positive and negative pairs with a contrastive objective. As a consequence, the pre-ranking model can make full use of rich information in ranking model's representations. The CIT framework also has the advantage of alleviating selection bias and improving the performance of recall metrics, which is crucial for pre-ranking models. We conduct extensive experiments including offline datasets and online A/B testing. Experimental results show that CIT achieves superior results than competitive models. In addition, a strict online A/B testing at one of the world's largest E-commercial platforms shows that the proposed model achieves 0.63\% improvements on CTR and 1.64\% improvements on VBR. The proposed model now has been deployed online and serves the main traffic of this system, contributing a remarkable business growth.
On Data Scaling in Masked Image Modeling
Jun 09, 2022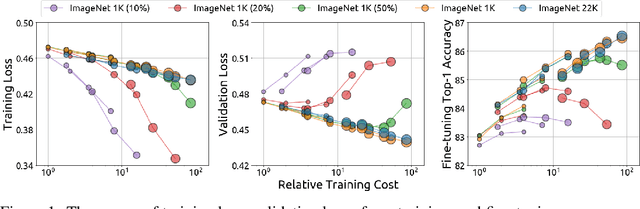


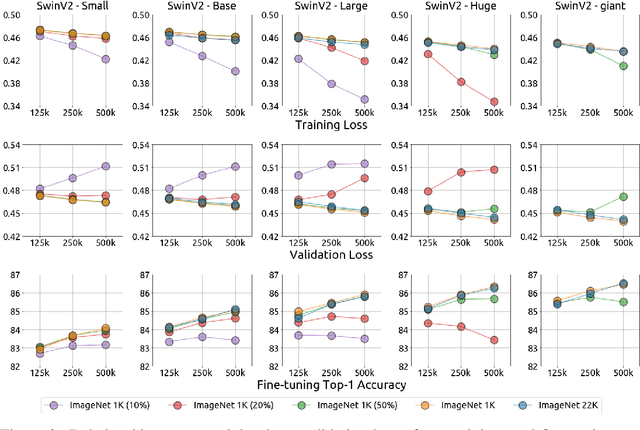
An important goal of self-supervised learning is to enable model pre-training to benefit from almost unlimited data. However, one method that has recently become popular, namely masked image modeling (MIM), is suspected to be unable to benefit from larger data. In this work, we break this misconception through extensive experiments, with data scales ranging from 10\% of ImageNet-1K to full ImageNet-22K, model sizes ranging from 49 million to 1 billion, and training lengths ranging from 125K iterations to 500K iterations. Our study reveals that: (i) Masked image modeling is also demanding on larger data. We observed that very large models got over-fitted with relatively small data; (ii) The length of training matters. Large models trained with masked image modeling can benefit from more data with longer training; (iii) The validation loss in pre-training is a good indicator to measure how well the model performs for fine-tuning on multiple tasks. This observation allows us to pre-evaluate pre-trained models in advance without having to make costly trial-and-error assessments of downstream tasks. We hope that our findings will advance the understanding of masked image modeling in terms of scaling ability.
Contrastive Learning Rivals Masked Image Modeling in Fine-tuning via Feature Distillation
May 27, 2022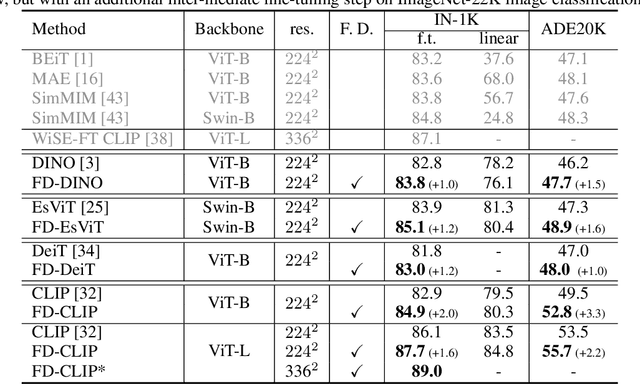
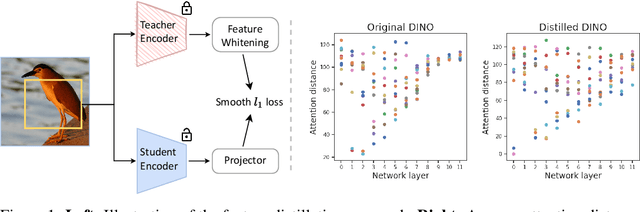
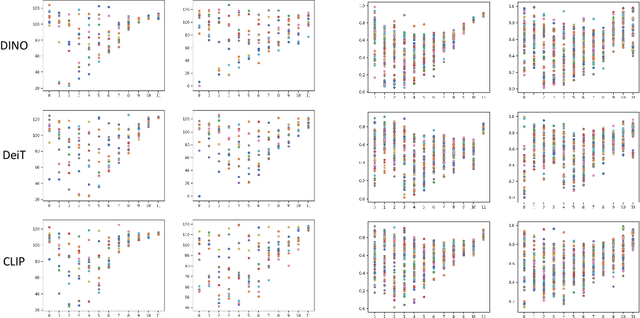
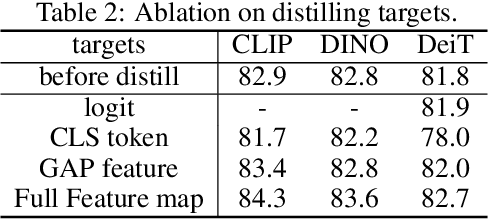
Masked image modeling (MIM) learns representations with remarkably good fine-tuning performances, overshadowing previous prevalent pre-training approaches such as image classification, instance contrastive learning, and image-text alignment. In this paper, we show that the inferior fine-tuning performance of these pre-training approaches can be significantly improved by a simple post-processing in the form of feature distillation (FD). The feature distillation converts the old representations to new representations that have a few desirable properties just like those representations produced by MIM. These properties, which we aggregately refer to as optimization friendliness, are identified and analyzed by a set of attention- and optimization-related diagnosis tools. With these properties, the new representations show strong fine-tuning performance. Specifically, the contrastive self-supervised learning methods are made as competitive in fine-tuning as the state-of-the-art masked image modeling (MIM) algorithms. The CLIP models' fine-tuning performance is also significantly improved, with a CLIP ViT-L model reaching 89.0% top-1 accuracy on ImageNet-1K classification. More importantly, our work provides a way for the future research to focus more effort on the generality and scalability of the learnt representations without being pre-occupied with optimization friendliness since it can be enhanced rather easily. The code will be available at https://github.com/SwinTransformer/Feature-Distillation.
Revealing the Dark Secrets of Masked Image Modeling
May 27, 2022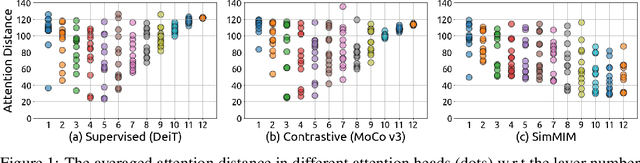

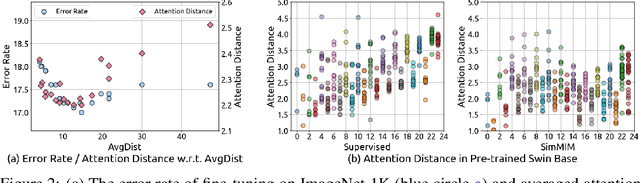
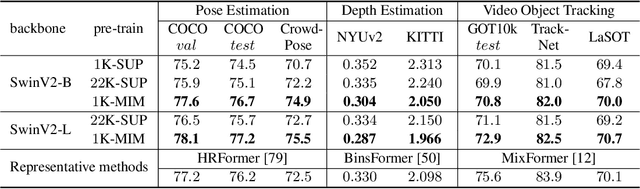
Masked image modeling (MIM) as pre-training is shown to be effective for numerous vision downstream tasks, but how and where MIM works remain unclear. In this paper, we compare MIM with the long-dominant supervised pre-trained models from two perspectives, the visualizations and the experiments, to uncover their key representational differences. From the visualizations, we find that MIM brings locality inductive bias to all layers of the trained models, but supervised models tend to focus locally at lower layers but more globally at higher layers. That may be the reason why MIM helps Vision Transformers that have a very large receptive field to optimize. Using MIM, the model can maintain a large diversity on attention heads in all layers. But for supervised models, the diversity on attention heads almost disappears from the last three layers and less diversity harms the fine-tuning performance. From the experiments, we find that MIM models can perform significantly better on geometric and motion tasks with weak semantics or fine-grained classification tasks, than their supervised counterparts. Without bells and whistles, a standard MIM pre-trained SwinV2-L could achieve state-of-the-art performance on pose estimation (78.9 AP on COCO test-dev and 78.0 AP on CrowdPose), depth estimation (0.287 RMSE on NYUv2 and 1.966 RMSE on KITTI), and video object tracking (70.7 SUC on LaSOT). For the semantic understanding datasets where the categories are sufficiently covered by the supervised pre-training, MIM models can still achieve highly competitive transfer performance. With a deeper understanding of MIM, we hope that our work can inspire new and solid research in this direction.
Sampling Is All You Need on Modeling Long-Term User Behaviors for CTR Prediction
May 20, 2022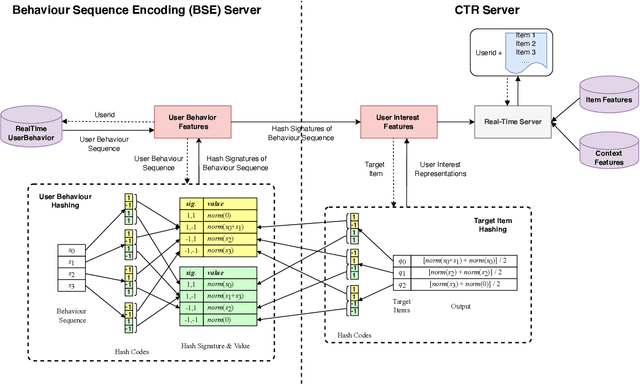

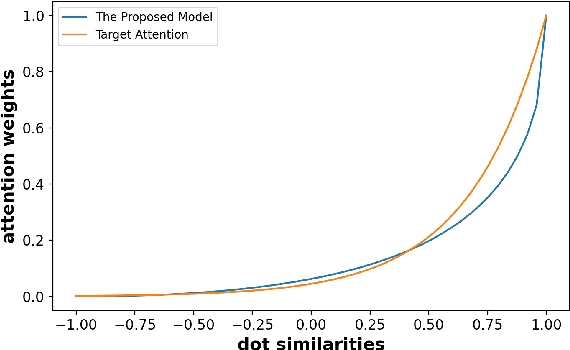
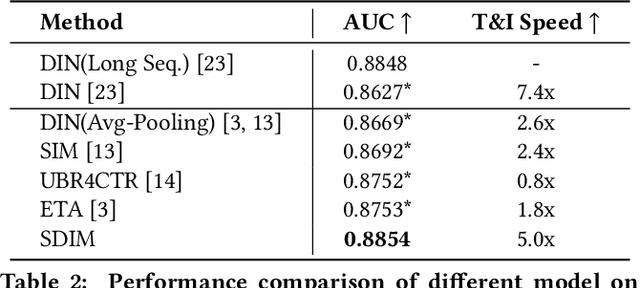
Rich user behavior data has been proven to be of great value for Click-Through Rate (CTR) prediction applications, especially in industrial recommender, search, or advertising systems. However, it's non-trivial for real-world systems to make full use of long-term user behaviors due to the strict requirements of online serving time. Most previous works adopt the retrieval-based strategy, where a small number of user behaviors are retrieved first for subsequent attention. However, the retrieval-based methods are sub-optimal and would cause more or less information losses, and it's difficult to balance the effectiveness and efficiency of the retrieval algorithm. In this paper, we propose \textbf{SDIM} (\textbf{S}ampling-based \textbf{D}eep \textbf{I}nterest \textbf{M}odeling), a simple yet effective sampling-based end-to-end approach for modeling long-term user behaviors. We sample from multiple hash functions to generate hash signatures of the candidate item and each item in the user behavior sequence, and obtain the user interest by directly gathering behavior items associated with the candidate item with the same hash signature. We show theoretically and experimentally that the proposed method performs on par with standard attention-based models on modeling long-term user behaviors, while being sizable times faster. We also introduce the deployment of SDIM in our system. Specifically, we decouple the behavior sequence hashing, which is the most time-consuming part, from the CTR model by designing a separate module named BSE (behavior Sequence Encoding). BSE is latency-free for the CTR server, enabling us to model extremely long user behaviors. Both offline and online experiments are conducted to demonstrate the effectiveness of SDIM. SDIM now has been deployed online in the search system of Meituan APP.
iCAR: Bridging Image Classification and Image-text Alignment for Visual Recognition
Apr 22, 2022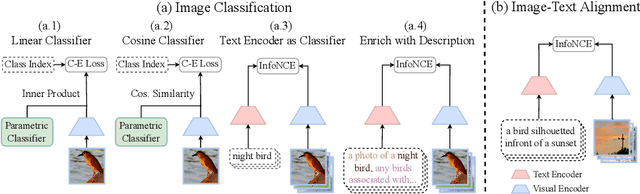

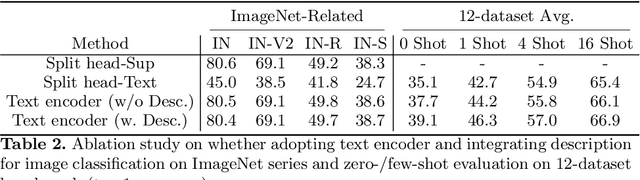
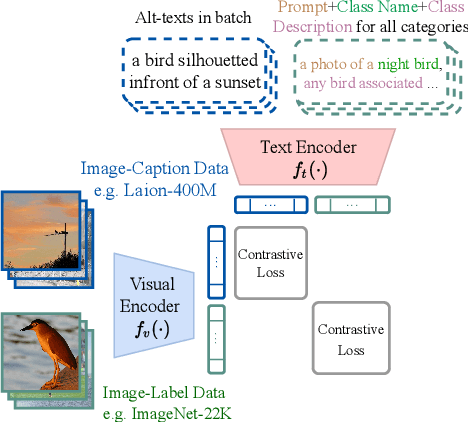
Image classification, which classifies images by pre-defined categories, has been the dominant approach to visual representation learning over the last decade. Visual learning through image-text alignment, however, has emerged to show promising performance, especially for zero-shot recognition. We believe that these two learning tasks are complementary, and suggest combining them for better visual learning. We propose a deep fusion method with three adaptations that effectively bridge two learning tasks, rather than shallow fusion through naive multi-task learning. First, we modify the previous common practice in image classification, a linear classifier, with a cosine classifier which shows comparable performance. Second, we convert the image classification problem from learning parametric category classifier weights to learning a text encoder as a meta network to generate category classifier weights. The learnt text encoder is shared between image classification and image-text alignment. Third, we enrich each class name with a description to avoid confusion between classes and make the classification method closer to the image-text alignment. We prove that this deep fusion approach performs better on a variety of visual recognition tasks and setups than the individual learning or shallow fusion approach, from zero-shot/few-shot image classification, such as the Kornblith 12-dataset benchmark, to downstream tasks of action recognition, semantic segmentation, and object detection in fine-tuning and open-vocabulary settings. The code will be available at https://github.com/weiyx16/iCAR.
Incorporating Semi-Supervised and Positive-Unlabeled Learning for Boosting Full Reference Image Quality Assessment
Apr 19, 2022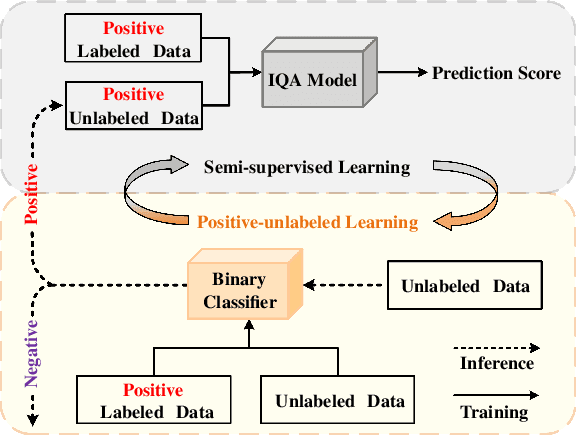
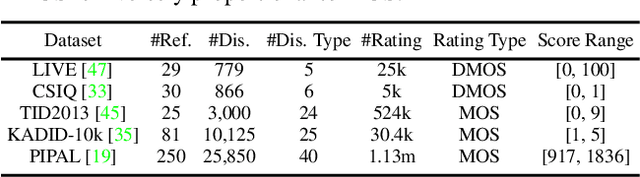
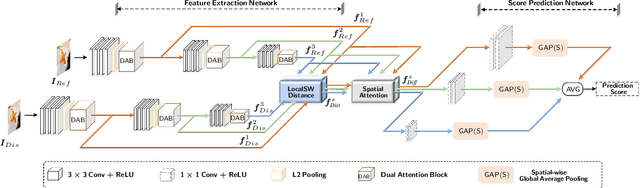
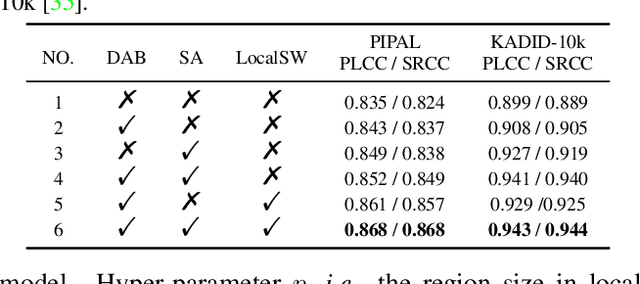
Full-reference (FR) image quality assessment (IQA) evaluates the visual quality of a distorted image by measuring its perceptual difference with pristine-quality reference, and has been widely used in low-level vision tasks. Pairwise labeled data with mean opinion score (MOS) are required in training FR-IQA model, but is time-consuming and cumbersome to collect. In contrast, unlabeled data can be easily collected from an image degradation or restoration process, making it encouraging to exploit unlabeled training data to boost FR-IQA performance. Moreover, due to the distribution inconsistency between labeled and unlabeled data, outliers may occur in unlabeled data, further increasing the training difficulty. In this paper, we suggest to incorporate semi-supervised and positive-unlabeled (PU) learning for exploiting unlabeled data while mitigating the adverse effect of outliers. Particularly, by treating all labeled data as positive samples, PU learning is leveraged to identify negative samples (i.e., outliers) from unlabeled data. Semi-supervised learning (SSL) is further deployed to exploit positive unlabeled data by dynamically generating pseudo-MOS. We adopt a dual-branch network including reference and distortion branches. Furthermore, spatial attention is introduced in the reference branch to concentrate more on the informative regions, and sliced Wasserstein distance is used for robust difference map computation to address the misalignment issues caused by images recovered by GAN models. Extensive experiments show that our method performs favorably against state-of-the-arts on the benchmark datasets PIPAL, KADID-10k, TID2013, LIVE and CSIQ.