 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Virtues of Laziness in Model-based RL: A Unified Objective and Algorithms
Mar 01, 2023We propose a novel approach to addressing two fundamental challenges in Model-based Reinforcement Learning (MBRL): the computational expense of repeatedly finding a good policy in the learned model, and the objective mismatch between model fitting and policy computation. Our "lazy" method leverages a novel unified objective, Performance Difference via Advantage in Model, to capture the performance difference between the learned policy and expert policy under the true dynamics. This objective demonstrates that optimizing the expected policy advantage in the learned model under an exploration distribution is sufficient for policy computation, resulting in a significant boost in computational efficiency compared to traditional planning methods. Additionally, the unified objective uses a value moment matching term for model fitting, which is aligned with the model's usage during policy computation. We present two no-regret algorithms to optimize the proposed objective, and demonstrate their statistical and computational gains compared to existing MBRL methods through simulated benchmarks.
ClassPruning: Speed Up Image Restoration Networks by Dynamic N:M Pruning
Nov 10, 2022Image restoration tasks have achieved tremendous performance improvements with the rapid advancement of deep neural networks. However, most prevalent deep learning models perform inference statically, ignoring that different images have varying restoration difficulties and lightly degraded images can be well restored by slimmer subnetworks. To this end, we propose a new solution pipeline dubbed ClassPruning that utilizes networks with different capabilities to process images with varying restoration difficulties. In particular, we use a lightweight classifier to identify the image restoration difficulty, and then the sparse subnetworks with different capabilities can be sampled based on predicted difficulty by performing dynamic N:M fine-grained structured pruning on base restoration networks. We further propose a novel training strategy along with two additional loss terms to stabilize training and improve performance. Experiments demonstrate that ClassPruning can help existing methods save approximately 40% FLOPs while maintaining performance.
Representation Learning for General-sum Low-rank Markov Games
Oct 30, 2022



We study multi-agent general-sum Markov games with nonlinear function approximation. We focus on low-rank Markov games whose transition matrix admits a hidden low-rank structure on top of an unknown non-linear representation. The goal is to design an algorithm that (1) finds an $\varepsilon$-equilibrium policy sample efficiently without prior knowledge of the environment or the representation, and (2) permits a deep-learning friendly implementation. We leverage representation learning and present a model-based and a model-free approach to construct an effective representation from the collected data. For both approaches, the algorithm achieves a sample complexity of poly$(H,d,A,1/\varepsilon)$, where $H$ is the game horizon, $d$ is the dimension of the feature vector, $A$ is the size of the joint action space and $\varepsilon$ is the optimality gap. When the number of players is large, the above sample complexity can scale exponentially with the number of players in the worst case. To address this challenge, we consider Markov games with a factorized transition structure and present an algorithm that escapes such exponential scaling. To our best knowledge, this is the first sample-efficient algorithm for multi-agent general-sum Markov games that incorporates (non-linear) function approximation. We accompany our theoretical result with a neural network-based implementation of our algorithm and evaluate it against the widely used deep RL baseline, DQN with fictitious play.
Hybrid RL: Using Both Offline and Online Data Can Make RL Efficient
Oct 13, 2022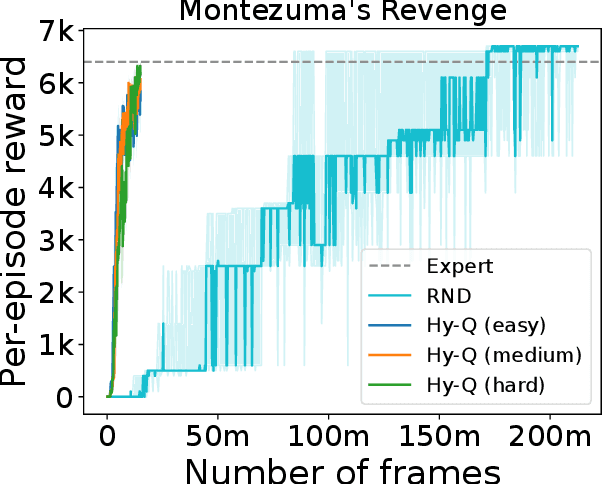
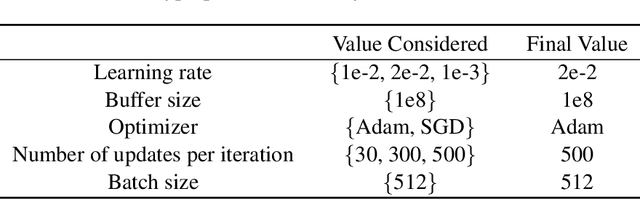
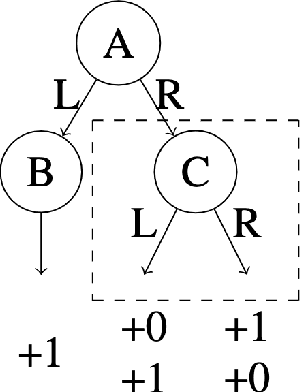
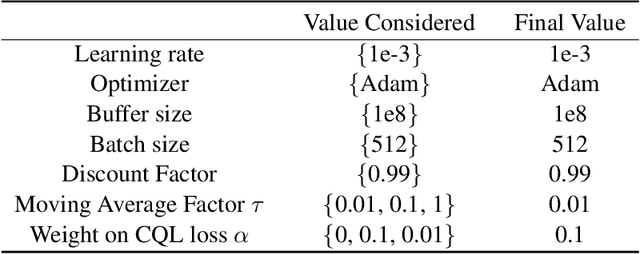
We consider a hybrid reinforcement learning setting (Hybrid RL), in which an agent has access to an offline dataset and the ability to collect experience via real-world online interaction. The framework mitigates the challenges that arise in both pure offline and online RL settings, allowing for the design of simple and highly effective algorithms, in both theory and practice. We demonstrate these advantages by adapting the classical Q learning/iteration algorithm to the hybrid setting, which we call Hybrid Q-Learning or Hy-Q. In our theoretical results, we prove that the algorithm is both computationally and statistically efficient whenever the offline dataset supports a high-quality policy and the environment has bounded bilinear rank. Notably, we require no assumptions on the coverage provided by the initial distribution, in contrast with guarantees for policy gradient/iteration methods. In our experimental results, we show that Hy-Q with neural network function approximation outperforms state-of-the-art online, offline, and hybrid RL baselines on challenging benchmarks, including Montezuma's Revenge.
Modular Degradation Simulation and Restoration for Under-Display Camera
Sep 23, 2022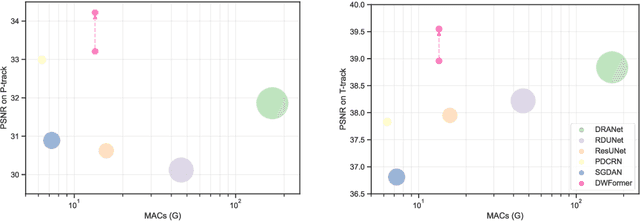
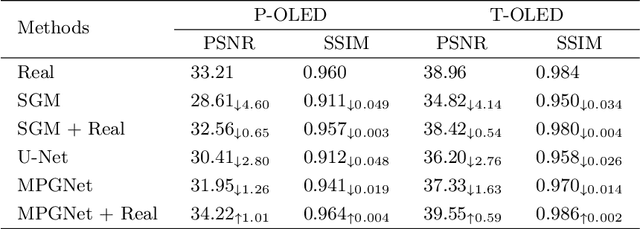
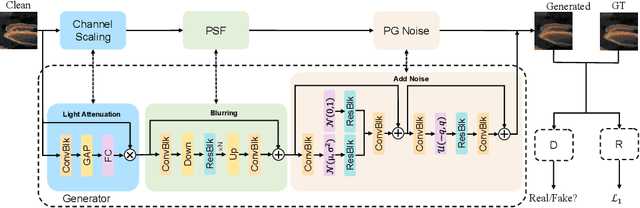
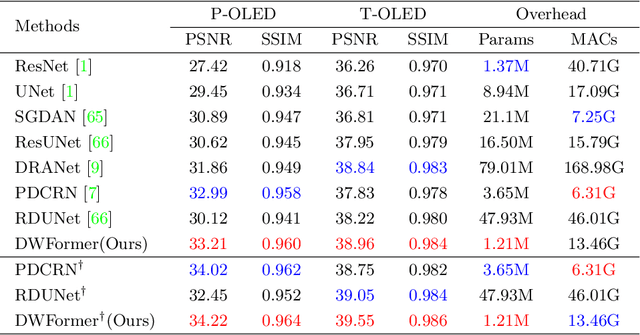
Under-display camera (UDC) provides an elegant solution for full-screen smartphones. However, UDC captured images suffer from severe degradation since sensors lie under the display. Although this issue can be tackled by image restoration networks, these networks require large-scale image pairs for training. To this end, we propose a modular network dubbed MPGNet trained using the generative adversarial network (GAN) framework for simulating UDC imaging. Specifically, we note that the UDC imaging degradation process contains brightness attenuation, blurring, and noise corruption. Thus we model each degradation with a characteristic-related modular network, and all modular networks are cascaded to form the generator. Together with a pixel-wise discriminator and supervised loss, we can train the generator to simulate the UDC imaging degradation process. Furthermore, we present a Transformer-style network named DWFormer for UDC image restoration. For practical purposes, we use depth-wise convolution instead of the multi-head self-attention to aggregate local spatial information. Moreover, we propose a novel channel attention module to aggregate global information, which is critical for brightness recovery. We conduct evaluations on the UDC benchmark, and our method surpasses the previous state-of-the-art models by 1.23 dB on the P-OLED track and 0.71 dB on the T-OLED track, respectively.
Rethinking Performance Gains in Image Dehazing Networks
Sep 23, 2022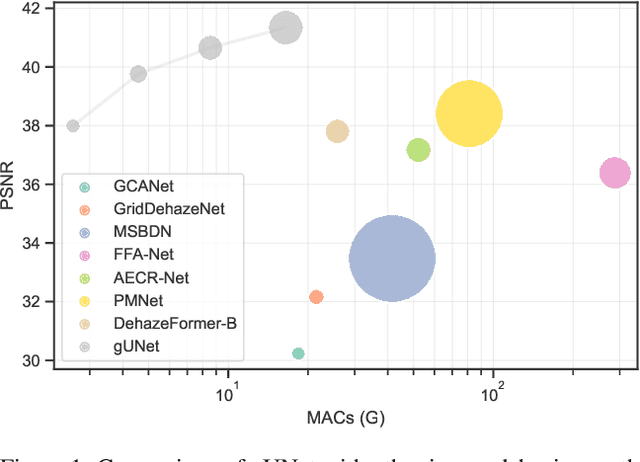
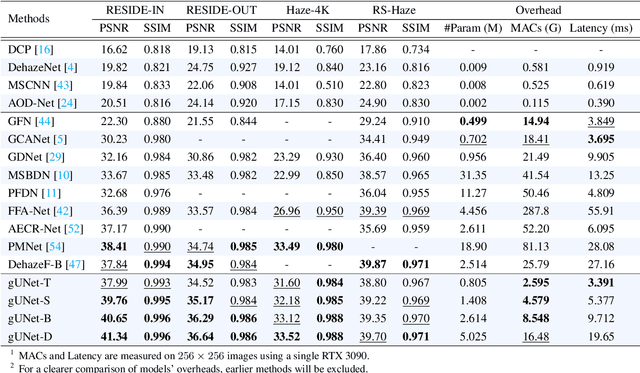
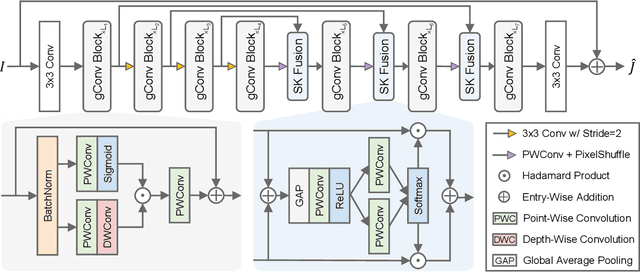
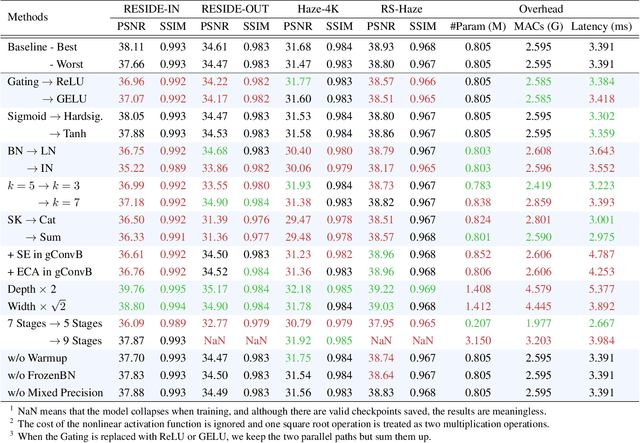
Image dehazing is an active topic in low-level vision, and many image dehazing networks have been proposed with the rapid development of deep learning. Although these networks' pipelines work fine, the key mechanism to improving image dehazing performance remains unclear. For this reason, we do not target to propose a dehazing network with fancy modules; rather, we make minimal modifications to popular U-Net to obtain a compact dehazing network. Specifically, we swap out the convolutional blocks in U-Net for residual blocks with the gating mechanism, fuse the feature maps of main paths and skip connections using the selective kernel, and call the resulting U-Net variant gUNet. As a result, with a significantly reduced overhead, gUNet is superior to state-of-the-art methods on multiple image dehazing datasets. Finally, we verify these key designs to the performance gain of image dehazing networks through extensive ablation studies.
Provable Benefits of Representational Transfer in Reinforcement Learning
May 29, 2022

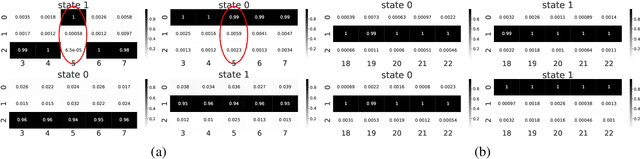
We study the problem of representational transfer in RL, where an agent first pretrains in a number of source tasks to discover a shared representation, which is subsequently used to learn a good policy in a target task. We propose a new notion of task relatedness between source and target tasks, and develop a novel approach for representational transfer under this assumption. Concretely, we show that given generative access to source tasks, we can discover a representation, using which subsequent linear RL techniques quickly converge to a near-optimal policy, with only online access to the target task. The sample complexity is close to knowing the ground truth features in the target task, and comparable to prior representation learning results in the source tasks. We complement our positive results with lower bounds without generative access, and validate our findings with empirical evaluation on rich observation MDPs that require deep exploration.
Vision Transformers for Single Image Dehazing
Apr 08, 2022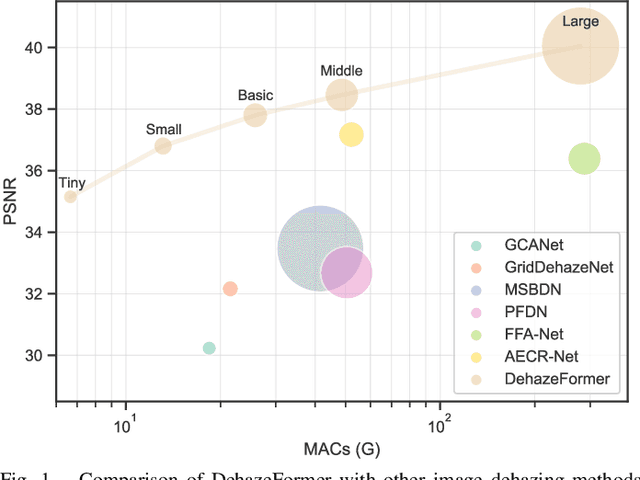


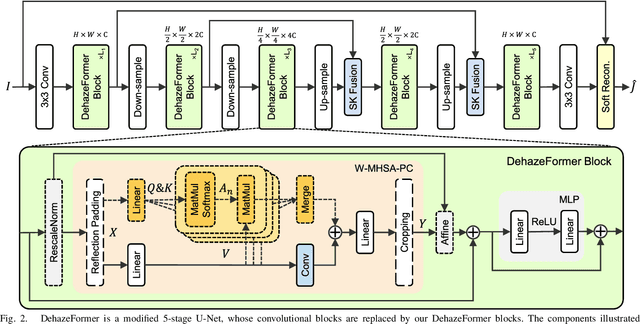
Image dehazing is a representative low-level vision task that estimates latent haze-free images from hazy images. In recent years, convolutional neural network-based methods have dominated image dehazing. However, vision Transformers, which has recently made a breakthrough in high-level vision tasks, has not brought new dimensions to image dehazing. We start with the popular Swin Transformer and find that several of its key designs are unsuitable for image dehazing. To this end, we propose DehazeFormer, which consists of various improvements, such as the modified normalization layer, activation function, and spatial information aggregation scheme. We train multiple variants of DehazeFormer on various datasets to demonstrate its effectiveness. Specifically, on the most frequently used SOTS indoor set, our small model outperforms FFA-Net with only 25% #Param and 5% computational cost. To the best of our knowledge, our large model is the first method with the PSNR over 40 dB on the SOTS indoor set, dramatically outperforming the previous state-of-the-art methods. We also collect a large-scale realistic remote sensing dehazing dataset for evaluating the method's capability to remove highly non-homogeneous haze.
Online No-regret Model-Based Meta RL for Personalized Navigation
Apr 05, 2022
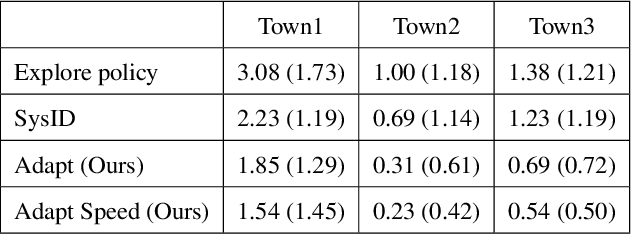
The interaction between a vehicle navigation system and the driver of the vehicle can be formulated as a model-based reinforcement learning problem, where the navigation systems (agent) must quickly adapt to the characteristics of the driver (environmental dynamics) to provide the best sequence of turn-by-turn driving instructions. Most modern day navigation systems (e.g, Google maps, Waze, Garmin) are not designed to personalize their low-level interactions for individual users across a wide range of driving styles (e.g., vehicle type, reaction time, level of expertise). Towards the development of personalized navigation systems that adapt to a variety of driving styles, we propose an online no-regret model-based RL method that quickly conforms to the dynamics of the current user. As the user interacts with it, the navigation system quickly builds a user-specific model, from which navigation commands are optimized using model predictive control. By personalizing the policy in this way, our method is able to give well-timed driving instructions that match the user's dynamics. Our theoretical analysis shows that our method is a no-regret algorithm and we provide the convergence rate in the agnostic setting. Our empirical analysis with 60+ hours of real-world user data using a driving simulator shows that our method can reduce the number of collisions by more than 60%.
Multi-Curve Translator for Real-Time High-Resolution Image-to-Image Translation
Mar 15, 2022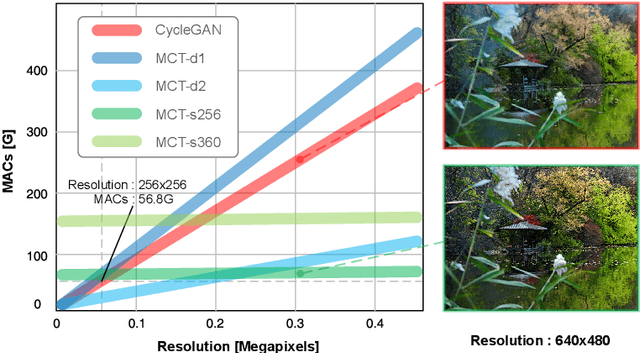
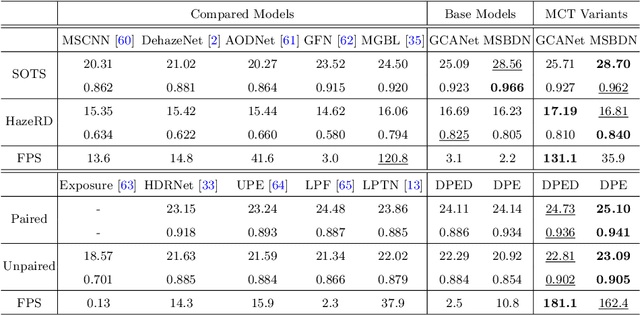
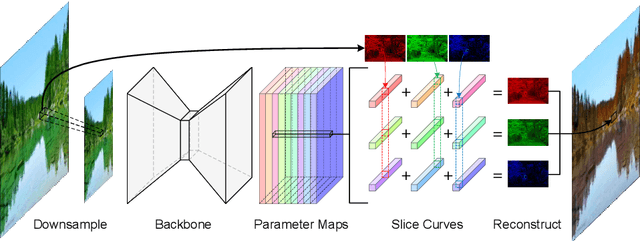
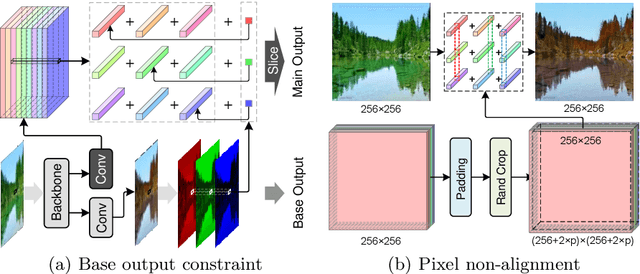
The dominant image-to-image translation methods are based on fully convolutional networks, which extract and translate an image's features and then reconstruct the image. However, they have unacceptable computational costs when working with high-resolution images. To this end, we present the Multi-Curve Translator (MCT), which not only predicts the translated pixels for the corresponding input pixels but also for their neighboring pixels. And if a high-resolution image is downsampled to its low-resolution version, the lost pixels are the remaining pixels' neighboring pixels. So MCT makes it possible to feed the network only the downsampled image to perform the mapping for the full-resolution image, which can dramatically lower the computational cost. Besides, MCT is a plug-in approach that utilizes existing base models and requires only replacing their output layers. Experiments demonstrate that the MCT variants can process 4K images in real-time and achieve comparable or even better performance than the base models on various image-to-image translation tasks.