 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMono3DVG: 3D Visual Grounding in Monocular Images
Dec 13, 2023We introduce a novel task of 3D visual grounding in monocular RGB images using language descriptions with both appearance and geometry information. Specifically, we build a large-scale dataset, Mono3DRefer, which contains 3D object targets with their corresponding geometric text descriptions, generated by ChatGPT and refined manually. To foster this task, we propose Mono3DVG-TR, an end-to-end transformer-based network, which takes advantage of both the appearance and geometry information in text embeddings for multi-modal learning and 3D object localization. Depth predictor is designed to explicitly learn geometry features. The dual text-guided adapter is proposed to refine multiscale visual and geometry features of the referred object. Based on depth-text-visual stacking attention, the decoder fuses object-level geometric cues and visual appearance into a learnable query. Comprehensive benchmarks and some insightful analyses are provided for Mono3DVG. Extensive comparisons and ablation studies show that our method significantly outperforms all baselines. The dataset and code will be publicly available at: https://github.com/ZhanYang-nwpu/Mono3DVG.
Improving Factual Error Correction by Learning to Inject Factual Errors
Dec 12, 2023Factual error correction (FEC) aims to revise factual errors in false claims with minimal editing, making them faithful to the provided evidence. This task is crucial for alleviating the hallucination problem encountered by large language models. Given the lack of paired data (i.e., false claims and their corresponding correct claims), existing methods typically adopt the mask-then-correct paradigm. This paradigm relies solely on unpaired false claims and correct claims, thus being referred to as distantly supervised methods. These methods require a masker to explicitly identify factual errors within false claims before revising with a corrector. However, the absence of paired data to train the masker makes accurately pinpointing factual errors within claims challenging. To mitigate this, we propose to improve FEC by Learning to Inject Factual Errors (LIFE), a three-step distantly supervised method: mask-corrupt-correct. Specifically, we first train a corruptor using the mask-then-corrupt procedure, allowing it to deliberately introduce factual errors into correct text. The corruptor is then applied to correct claims, generating a substantial amount of paired data. After that, we filter out low-quality data, and use the remaining data to train a corrector. Notably, our corrector does not require a masker, thus circumventing the bottleneck associated with explicit factual error identification. Our experiments on a public dataset verify the effectiveness of LIFE in two key aspects: Firstly, it outperforms the previous best-performing distantly supervised method by a notable margin of 10.59 points in SARI Final (19.3% improvement). Secondly, even compared to ChatGPT prompted with in-context examples, LIFE achieves a superiority of 7.16 points in SARI Final.
Cross-modal Generative Model for Visual-Guided Binaural Stereo Generation
Nov 13, 2023Binaural stereo audio is recorded by imitating the way the human ear receives sound, which provides people with an immersive listening experience. Existing approaches leverage autoencoders and directly exploit visual spatial information to synthesize binaural stereo, resulting in a limited representation of visual guidance. For the first time, we propose a visually guided generative adversarial approach for generating binaural stereo audio from mono audio. Specifically, we develop a Stereo Audio Generation Model (SAGM), which utilizes shared spatio-temporal visual information to guide the generator and the discriminator to work separately. The shared visual information is updated alternately in the generative adversarial stage, allowing the generator and discriminator to deliver their respective guided knowledge while visually sharing. The proposed method learns bidirectional complementary visual information, which facilitates the expression of visual guidance in generation. In addition, spatial perception is a crucial attribute of binaural stereo audio, and thus the evaluation of stereo spatial perception is essential. However, previous metrics failed to measure the spatial perception of audio. To this end, a metric to measure the spatial perception of audio is proposed for the first time. The proposed metric is capable of measuring the magnitude and direction of spatial perception in the temporal dimension. Further, considering its function, it is feasible to utilize it instead of demanding user studies to some extent. The proposed method achieves state-of-the-art performance on 2 datasets and 5 evaluation metrics. Qualitative experiments and user studies demonstrate that the method generates space-realistic stereo audio.
Continuous Invariance Learning
Oct 09, 2023



Invariance learning methods aim to learn invariant features in the hope that they generalize under distributional shifts. Although many tasks are naturally characterized by continuous domains, current invariance learning techniques generally assume categorically indexed domains. For example, auto-scaling in cloud computing often needs a CPU utilization prediction model that generalizes across different times (e.g., time of a day and date of a year), where `time' is a continuous domain index. In this paper, we start by theoretically showing that existing invariance learning methods can fail for continuous domain problems. Specifically, the naive solution of splitting continuous domains into discrete ones ignores the underlying relationship among domains, and therefore potentially leads to suboptimal performance. To address this challenge, we then propose Continuous Invariance Learning (CIL), which extracts invariant features across continuously indexed domains. CIL is a novel adversarial procedure that measures and controls the conditional independence between the labels and continuous domain indices given the extracted features. Our theoretical analysis demonstrates the superiority of CIL over existing invariance learning methods. Empirical results on both synthetic and real-world datasets (including data collected from production systems) show that CIL consistently outperforms strong baselines among all the tasks.
Resource-Adaptive Newton's Method for Distributed Learning
Sep 02, 2023Distributed stochastic optimization methods based on Newton's method offer significant advantages over first-order methods by leveraging curvature information for improved performance. However, the practical applicability of Newton's method is hindered in large-scale and heterogeneous learning environments due to challenges such as high computation and communication costs associated with the Hessian matrix, sub-model diversity, staleness in training, and data heterogeneity. To address these challenges, this paper introduces a novel and efficient algorithm called RANL, which overcomes the limitations of Newton's method by employing a simple Hessian initialization and adaptive assignments of training regions. The algorithm demonstrates impressive convergence properties, which are rigorously analyzed under standard assumptions in stochastic optimization. The theoretical analysis establishes that RANL achieves a linear convergence rate while effectively adapting to available resources and maintaining high efficiency. Unlike traditional first-order methods, RANL exhibits remarkable independence from the condition number of the problem and eliminates the need for complex parameter tuning. These advantages make RANL a promising approach for distributed stochastic optimization in practical scenarios.
Parameter-Efficient Transfer Learning for Remote Sensing Image-Text Retrieval
Aug 24, 2023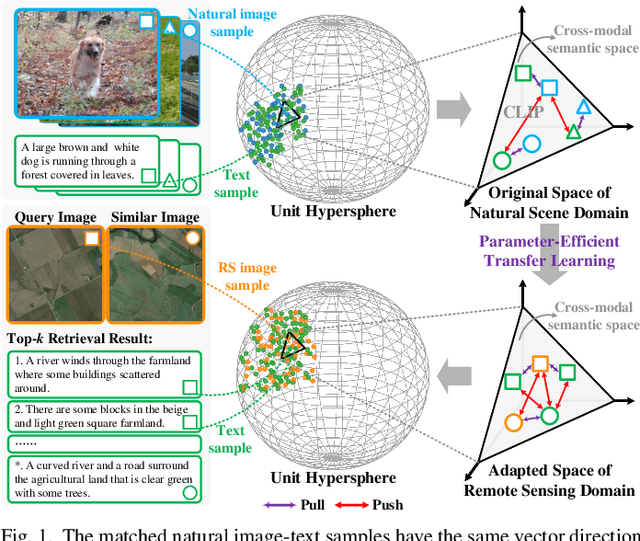



Vision-and-language pre-training (VLP) models have experienced a surge in popularity recently. By fine-tuning them on specific datasets, significant performance improvements have been observed in various tasks. However, full fine-tuning of VLP models not only consumes a significant amount of computational resources but also has a significant environmental impact. Moreover, as remote sensing (RS) data is constantly being updated, full fine-tuning may not be practical for real-world applications. To address this issue, in this work, we investigate the parameter-efficient transfer learning (PETL) method to effectively and efficiently transfer visual-language knowledge from the natural domain to the RS domain on the image-text retrieval task. To this end, we make the following contributions. 1) We construct a novel and sophisticated PETL framework for the RS image-text retrieval (RSITR) task, which includes the pretrained CLIP model, a multimodal remote sensing adapter, and a hybrid multi-modal contrastive (HMMC) learning objective; 2) To deal with the problem of high intra-modal similarity in RS data, we design a simple yet effective HMMC loss; 3) We provide comprehensive empirical studies for PETL-based RS image-text retrieval. Our results demonstrate that the proposed method is promising and of great potential for practical applications. 4) We benchmark extensive state-of-the-art PETL methods on the RSITR task. Our proposed model only contains 0.16M training parameters, which can achieve a parameter reduction of 98.9% compared to full fine-tuning, resulting in substantial savings in training costs. Our retrieval performance exceeds traditional methods by 7-13% and achieves comparable or better performance than full fine-tuning. This work can provide new ideas and useful insights for RS vision-language tasks.
A Two-Part Machine Learning Approach to Characterizing Network Interference in A/B Testing
Aug 18, 2023



The reliability of controlled experiments, or "A/B tests," can often be compromised due to the phenomenon of network interference, wherein the outcome for one unit is influenced by other units. To tackle this challenge, we propose a machine learning-based method to identify and characterize heterogeneous network interference. Our approach accounts for latent complex network structures and automates the task of "exposure mapping'' determination, which addresses the two major limitations in the existing literature. We introduce "causal network motifs'' and employ transparent machine learning models to establish the most suitable exposure mapping that reflects underlying network interference patterns. Our method's efficacy has been validated through simulations on two synthetic experiments and a real-world, large-scale test involving 1-2 million Instagram users, outperforming conventional methods such as design-based cluster randomization and analysis-based neighborhood exposure mapping. Overall, our approach not only offers a comprehensive, automated solution for managing network interference and improving the precision of A/B testing results, but it also sheds light on users' mutual influence and aids in the refinement of marketing strategies.
Enhancing Visibility in Nighttime Haze Images Using Guided APSF and Gradient Adaptive Convolution
Aug 05, 2023Visibility in hazy nighttime scenes is frequently reduced by multiple factors, including low light, intense glow, light scattering, and the presence of multicolored light sources. Existing nighttime dehazing methods often struggle with handling glow or low-light conditions, resulting in either excessively dark visuals or unsuppressed glow outputs. In this paper, we enhance the visibility from a single nighttime haze image by suppressing glow and enhancing low-light regions. To handle glow effects, our framework learns from the rendered glow pairs. Specifically, a light source aware network is proposed to detect light sources of night images, followed by the APSF (Angular Point Spread Function)-guided glow rendering. Our framework is then trained on the rendered images, resulting in glow suppression. Moreover, we utilize gradient-adaptive convolution, to capture edges and textures in hazy scenes. By leveraging extracted edges and textures, we enhance the contrast of the scene without losing important structural details. To boost low-light intensity, our network learns an attention map, then adjusted by gamma correction. This attention has high values on low-light regions and low values on haze and glow regions. Extensive evaluation on real nighttime haze images, demonstrates the effectiveness of our method. Our experiments demonstrate that our method achieves a PSNR of 30.38dB, outperforming state-of-the-art methods by 13$\%$ on GTA5 nighttime haze dataset. Our data and code is available at: \url{https://github.com/jinyeying/nighttime_dehaze}.
* Accepted to ACMMM2023, https://github.com/jinyeying/nighttime_dehaze
Spatio-temporal Diffusion Point Processes
May 21, 2023



Spatio-temporal point process (STPP) is a stochastic collection of events accompanied with time and space. Due to computational complexities, existing solutions for STPPs compromise with conditional independence between time and space, which consider the temporal and spatial distributions separately. The failure to model the joint distribution leads to limited capacities in characterizing the spatio-temporal entangled interactions given past events. In this work, we propose a novel parameterization framework for STPPs, which leverages diffusion models to learn complex spatio-temporal joint distributions. We decompose the learning of the target joint distribution into multiple steps, where each step can be faithfully described by a Gaussian distribution. To enhance the learning of each step, an elaborated spatio-temporal co-attention module is proposed to capture the interdependence between the event time and space adaptively. For the first time, we break the restrictions on spatio-temporal dependencies in existing solutions, and enable a flexible and accurate modeling paradigm for STPPs. Extensive experiments from a wide range of fields, such as epidemiology, seismology, crime, and urban mobility, demonstrate that our framework outperforms the state-of-the-art baselines remarkably, with an average improvement of over 50%. Further in-depth analyses validate its ability to capture spatio-temporal interactions, which can learn adaptively for different scenarios. The datasets and source code are available online: https://github.com/tsinghua-fib-lab/Spatio-temporal-Diffusion-Point-Processes.
Imbalanced Aircraft Data Anomaly Detection
May 17, 2023Anomaly detection in temporal data from sensors under aviation scenarios is a practical but challenging task: 1) long temporal data is difficult to extract contextual information with temporal correlation; 2) the anomalous data are rare in time series, causing normal/abnormal imbalance in anomaly detection, making the detector classification degenerate or even fail. To remedy the aforementioned problems, we propose a Graphical Temporal Data Analysis (GTDA) framework. It consists three modules, named Series-to-Image (S2I), Cluster-based Resampling Approach using Euclidean Distance (CRD) and Variance-Based Loss (VBL). Specifically, for better extracts global information in temporal data from sensors, S2I converts the data to curve images to demonstrate abnormalities in data changes. CRD and VBL balance the classification to mitigate the unequal distribution of classes. CRD extracts minority samples with similar features to majority samples by clustering and over-samples them. And VBL fine-tunes the decision boundary by balancing the fitting degree of the network to each class. Ablation experiments on the Flights dataset indicate the effectiveness of CRD and VBL on precision and recall, respectively. Extensive experiments demonstrate the synergistic advantages of CRD and VBL on F1-score on Flights and three other temporal datasets.