 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAISM: Digital Approximate In-SRAM Multiplier-based Accelerator for DNN Training and Inference
May 12, 2023



DNNs are one of the most widely used Deep Learning models. The matrix multiplication operations for DNNs incur significant computational costs and are bottlenecked by data movement between the memory and the processing elements. Many specialized accelerators have been proposed to optimize matrix multiplication operations. One popular idea is to use Processing-in-Memory where computations are performed by the memory storage element, thereby reducing the overhead of data movement between processor and memory. However, most PIM solutions rely either on novel memory technologies that have yet to mature or bit-serial computations which have significant performance overhead and scalability issues. In this work, an in-SRAM digital multiplier is proposed to take the best of both worlds, i.e. performing GEMM in memory but using only conventional SRAMs without the drawbacks of bit-serial computations. This allows the user to design systems with significant performance gains using existing technologies with little to no modifications. We first design a novel approximate bit-parallel multiplier that approximates multiplications with bitwise OR operations by leveraging multiple wordlines activation in the SRAM. We then propose DAISM - Digital Approximate In-SRAM Multiplier architecture, an accelerator for convolutional neural networks, based on our novel multiplier. This is followed by a comprehensive analysis of trade-offs in area, accuracy, and performance. We show that under similar design constraints, DAISM reduces energy consumption by 25\% and the number of cycles by 43\% compared to state-of-the-art baselines.
Augment and Criticize: Exploring Informative Samples for Semi-Supervised Monocular 3D Object Detection
Mar 20, 2023In this paper, we improve the challenging monocular 3D object detection problem with a general semi-supervised framework. Specifically, having observed that the bottleneck of this task lies in lacking reliable and informative samples to train the detector, we introduce a novel, simple, yet effective `Augment and Criticize' framework that explores abundant informative samples from unlabeled data for learning more robust detection models. In the `Augment' stage, we present the Augmentation-based Prediction aGgregation (APG), which aggregates detections from various automatically learned augmented views to improve the robustness of pseudo label generation. Since not all pseudo labels from APG are beneficially informative, the subsequent `Criticize' phase is presented. In particular, we introduce the Critical Retraining Strategy (CRS) that, unlike simply filtering pseudo labels using a fixed threshold (e.g., classification score) as in 2D semi-supervised tasks, leverages a learnable network to evaluate the contribution of unlabeled images at different training timestamps. This way, the noisy samples prohibitive to model evolution could be effectively suppressed. To validate our framework, we apply it to MonoDLE and MonoFlex. The two new detectors, dubbed 3DSeMo_DLE and 3DSeMo_FLEX, achieve state-of-the-art results with remarkable improvements for over 3.5% AP_3D/BEV (Easy) on KITTI, showing its effectiveness and generality. Code and models will be released.
To Make Yourself Invisible with Adversarial Semantic Contours
Mar 01, 2023Modern object detectors are vulnerable to adversarial examples, which may bring risks to real-world applications. The sparse attack is an important task which, compared with the popular adversarial perturbation on the whole image, needs to select the potential pixels that is generally regularized by an $\ell_0$-norm constraint, and simultaneously optimize the corresponding texture. The non-differentiability of $\ell_0$ norm brings challenges and many works on attacking object detection adopted manually-designed patterns to address them, which are meaningless and independent of objects, and therefore lead to relatively poor attack performance. In this paper, we propose Adversarial Semantic Contour (ASC), an MAP estimate of a Bayesian formulation of sparse attack with a deceived prior of object contour. The object contour prior effectively reduces the search space of pixel selection and improves the attack by introducing more semantic bias. Extensive experiments demonstrate that ASC can corrupt the prediction of 9 modern detectors with different architectures (\e.g., one-stage, two-stage and Transformer) by modifying fewer than 5\% of the pixels of the object area in COCO in white-box scenario and around 10\% of those in black-box scenario. We further extend the attack to datasets for autonomous driving systems to verify the effectiveness. We conclude with cautions about contour being the common weakness of object detectors with various architecture and the care needed in applying them in safety-sensitive scenarios.
* 11 pages, 7 figures, published in Computer Vision and Image Understanding in 2023
Improving Model Generalization by On-manifold Adversarial Augmentation in the Frequency Domain
Feb 28, 2023Deep neural networks (DNNs) may suffer from significantly degenerated performance when the training and test data are of different underlying distributions. Despite the importance of model generalization to out-of-distribution (OOD) data, the accuracy of state-of-the-art (SOTA) models on OOD data can plummet. Recent work has demonstrated that regular or off-manifold adversarial examples, as a special case of data augmentation, can be used to improve OOD generalization. Inspired by this, we theoretically prove that on-manifold adversarial examples can better benefit OOD generalization. Nevertheless, it is nontrivial to generate on-manifold adversarial examples because the real manifold is generally complex. To address this issue, we proposed a novel method of Augmenting data with Adversarial examples via a Wavelet module (AdvWavAug), an on-manifold adversarial data augmentation technique that is simple to implement. In particular, we project a benign image into a wavelet domain. With the assistance of the sparsity characteristic of wavelet transformation, we can modify an image on the estimated data manifold. We conduct adversarial augmentation based on AdvProp training framework. Extensive experiments on different models and different datasets, including ImageNet and its distorted versions, demonstrate that our method can improve model generalization, especially on OOD data. By integrating AdvWavAug into the training process, we have achieved SOTA results on some recent transformer-based models.
A Comprehensive Study on Robustness of Image Classification Models: Benchmarking and Rethinking
Feb 28, 2023



The robustness of deep neural networks is usually lacking under adversarial examples, common corruptions, and distribution shifts, which becomes an important research problem in the development of deep learning. Although new deep learning methods and robustness improvement techniques have been constantly proposed, the robustness evaluations of existing methods are often inadequate due to their rapid development, diverse noise patterns, and simple evaluation metrics. Without thorough robustness evaluations, it is hard to understand the advances in the field and identify the effective methods. In this paper, we establish a comprehensive robustness benchmark called \textbf{ARES-Bench} on the image classification task. In our benchmark, we evaluate the robustness of 55 typical deep learning models on ImageNet with diverse architectures (e.g., CNNs, Transformers) and learning algorithms (e.g., normal supervised training, pre-training, adversarial training) under numerous adversarial attacks and out-of-distribution (OOD) datasets. Using robustness curves as the major evaluation criteria, we conduct large-scale experiments and draw several important findings, including: 1) there is an inherent trade-off between adversarial and natural robustness for the same model architecture; 2) adversarial training effectively improves adversarial robustness, especially when performed on Transformer architectures; 3) pre-training significantly improves natural robustness based on more training data or self-supervised learning. Based on ARES-Bench, we further analyze the training tricks in large-scale adversarial training on ImageNet. By designing the training settings accordingly, we achieve the new state-of-the-art adversarial robustness. We have made the benchmarking results and code platform publicly available.
Reveal the Unknown: Out-of-Knowledge-Base Mention Discovery with Entity Linking
Feb 14, 2023



Discovering entity mentions that are out of a Knowledge Base (KB) from texts plays a critical role in KB maintenance, but has not yet been fully explored. The current methods are mostly limited to the simple threshold-based approach and feature-based classification; the datasets for evaluation are relatively rare. In this work, we propose BLINKout, a new BERT-based Entity Linking (EL) method which can identify mentions that do not have a corresponding KB entity by matching them to a special NIL entity. To this end, we integrate novel techniques including NIL representation, NIL classification, and synonym enhancement. We also propose Ontology Pruning and Versioning strategies to construct out-of-KB mentions from normal, in-KB EL datasets. Results on four datasets of clinical notes and publications show that BLINKout outperforms existing methods to detect out-of-KB mentions for medical ontologies UMLS and SNOMED CT.
Language Model Analysis for Ontology Subsumption Inference
Feb 14, 2023



Pre-trained language models (LMs) have made significant advances in various Natural Language Processing (NLP) domains, but it is unclear to what extent they can infer formal semantics in ontologies, which are often used to represent conceptual knowledge and serve as the schema of data graphs. To investigate an LM's knowledge of ontologies, we propose OntoLAMA, a set of inference-based probing tasks and datasets from ontology subsumption axioms involving both atomic and complex concepts. We conduct extensive experiments on ontologies of different domains and scales, and our results demonstrate that LMs encode relatively less background knowledge of Subsumption Inference (SI) than traditional Natural Language Inference (NLI) but can improve on SI significantly when a small number of samples are given. We will open-source our code and datasets.
Structured Knowledge Distillation Towards Efficient and Compact Multi-View 3D Detection
Nov 21, 2022Detecting 3D objects from multi-view images is a fundamental problem in 3D computer vision. Recently, significant breakthrough has been made in multi-view 3D detection tasks. However, the unprecedented detection performance of these vision BEV (bird's-eye-view) detection models is accompanied with enormous parameters and computation, which make them unaffordable on edge devices. To address this problem, in this paper, we propose a structured knowledge distillation framework, aiming to improve the efficiency of modern vision-only BEV detection models. The proposed framework mainly includes: (a) spatial-temporal distillation which distills teacher knowledge of information fusion from different timestamps and views, (b) BEV response distillation which distills teacher response to different pillars, and (c) weight-inheriting which solves the problem of inconsistent inputs between students and teacher in modern transformer architectures. Experimental results show that our method leads to an average improvement of 2.16 mAP and 2.27 NDS on the nuScenes benchmark, outperforming multiple baselines by a large margin.
Towards Understanding and Boosting Adversarial Transferability from a Distribution Perspective
Oct 09, 2022
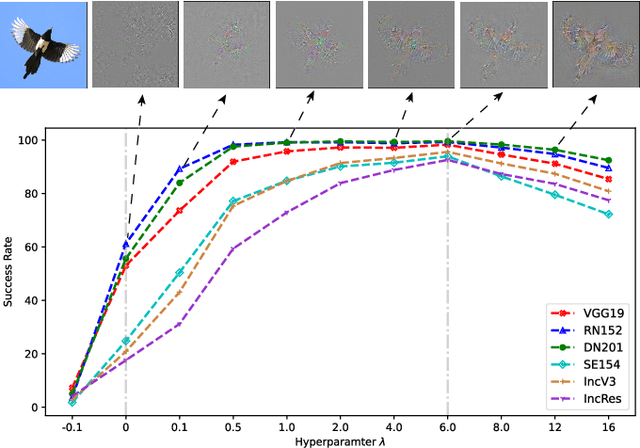
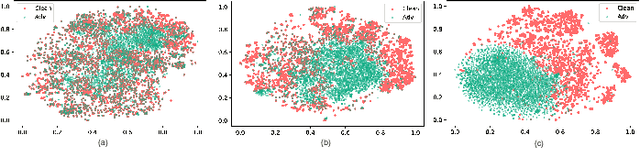
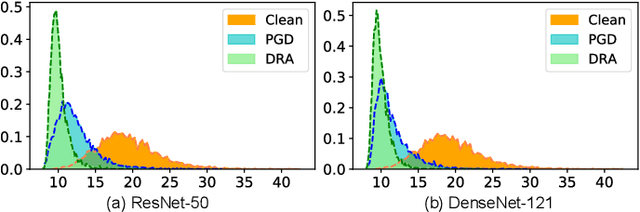
Transferable adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective, e.g., decision boundary, model architecture, and model capacity. adversarial attacks against Deep neural networks (DNNs) have received broad attention in recent years. An adversarial example can be crafted by a surrogate model and then attack the unknown target model successfully, which brings a severe threat to DNNs. The exact underlying reasons for the transferability are still not completely understood. Previous work mostly explores the causes from the model perspective. Here, we investigate the transferability from the data distribution perspective and hypothesize that pushing the image away from its original distribution can enhance the adversarial transferability. To be specific, moving the image out of its original distribution makes different models hardly classify the image correctly, which benefits the untargeted attack, and dragging the image into the target distribution misleads the models to classify the image as the target class, which benefits the targeted attack. Towards this end, we propose a novel method that crafts adversarial examples by manipulating the distribution of the image. We conduct comprehensive transferable attacks against multiple DNNs to demonstrate the effectiveness of the proposed method. Our method can significantly improve the transferability of the crafted attacks and achieves state-of-the-art performance in both untargeted and targeted scenarios, surpassing the previous best method by up to 40$\%$ in some cases.
Saiyan: Design and Implementation of a Low-power Demodulator for LoRa Backscatter Systems
Sep 30, 2022

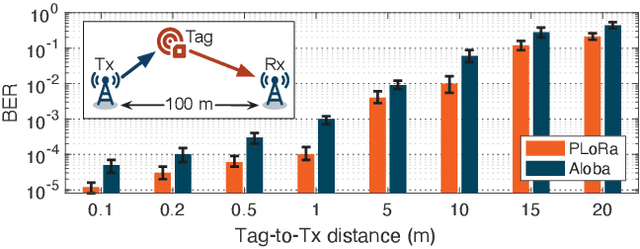

The radio range of backscatter systems continues growing as new wireless communication primitives are continuously invented. Nevertheless, both the bit error rate and the packet loss rate of backscatter signals increase rapidly with the radio range, thereby necessitating the cooperation between the access point and the backscatter tags through a feedback loop. Unfortunately, the low-power nature of backscatter tags limits their ability to demodulate feedback signals from a remote access point and scales down to such circumstances. This paper presents Saiyan, an ultra-low-power demodulator for long-range LoRa backscatter systems. With Saiyan, a backscatter tag can demodulate feedback signals from a remote access point with moderate power consumption and then perform an immediate packet retransmission in the presence of packet loss. Moreover, Saiyan enables rate adaption and channel hopping-two PHY-layer operations that are important to channel efficiency yet unavailable on long-range backscatter systems. We prototype Saiyan on a two-layer PCB board and evaluate its performance in different environments. Results show that Saiyan achieves 5 gain on the demodulation range, compared with state-of-the-art systems. Our ASIC simulation shows that the power consumption of Saiyan is around 93.2 uW. Code and hardware schematics can be found at: https://github.com/ZangJac/Saiyan.