 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMGN: A Regional Mask Guided Network for Parser-free Virtual Try-on
Paper and Code
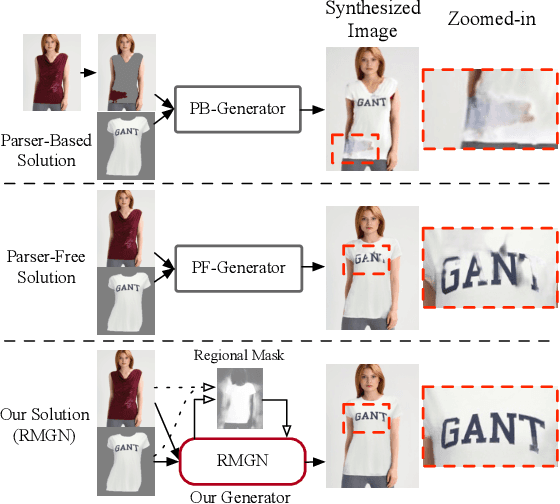
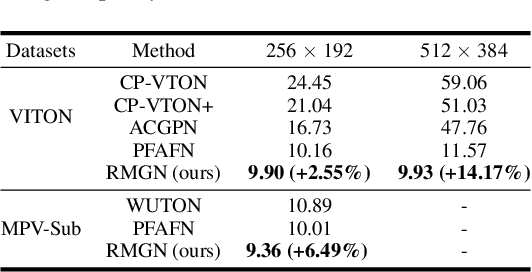
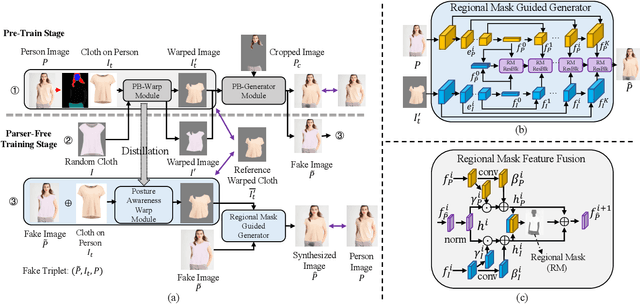
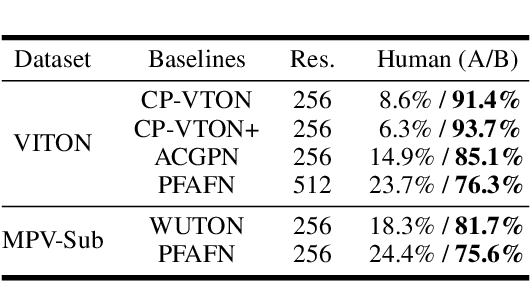
Virtual try-on(VTON) aims at fitting target clothes to reference person images, which is widely adopted in e-commerce.Existing VTON approaches can be narrowly categorized into Parser-Based(PB) and Parser-Free(PF) by whether relying on the parser information to mask the persons' clothes and synthesize try-on images. Although abandoning parser information has improved the applicability of PF methods, the ability of detail synthesizing has also been sacrificed. As a result, the distraction from original cloth may persistin synthesized images, especially in complicated postures and high resolution applications. To address the aforementioned issue, we propose a novel PF method named Regional Mask Guided Network(RMGN). More specifically, a regional mask is proposed to explicitly fuse the features of target clothes and reference persons so that the persisted distraction can be eliminated. A posture awareness loss and a multi-level feature extractor are further proposed to handle the complicated postures and synthesize high resolution images. Extensive experiments demonstrate that our proposed RMGN outperforms both state-of-the-art PB and PF methods.Ablation studies further verify the effectiveness ofmodules in RMGN.