 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe JDDC 2.0 Corpus: A Large-Scale Multimodal Multi-Turn Chinese Dialogue Dataset for E-commerce Customer Service
Sep 27, 2021
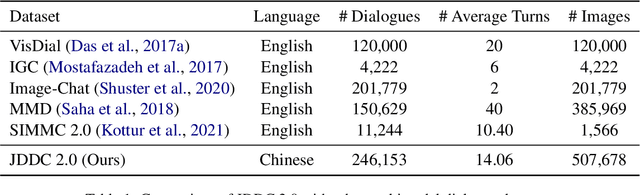
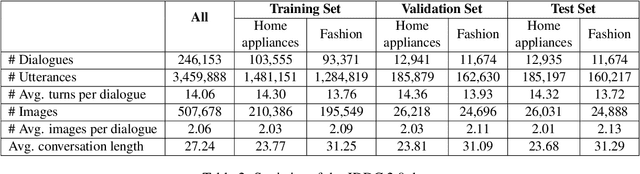
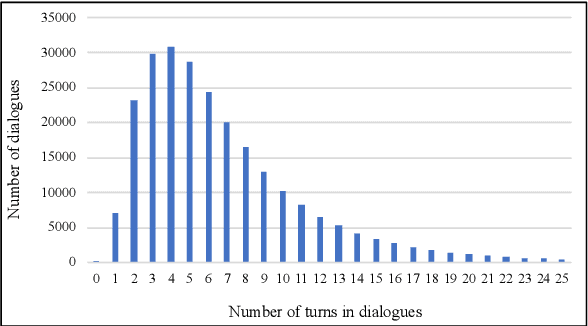
With the development of the Internet, more and more people get accustomed to online shopping. When communicating with customer service, users may express their requirements by means of text, images, and videos, which precipitates the need for understanding these multimodal information for automatic customer service systems. Images usually act as discriminators for product models, or indicators of product failures, which play important roles in the E-commerce scenario. On the other hand, detailed information provided by the images is limited, and typically, customer service systems cannot understand the intents of users without the input text. Thus, bridging the gap of the image and text is crucial for the multimodal dialogue task. To handle this problem, we construct JDDC 2.0, a large-scale multimodal multi-turn dialogue dataset collected from a mainstream Chinese E-commerce platform (JD.com), containing about 246 thousand dialogue sessions, 3 million utterances, and 507 thousand images, along with product knowledge bases and image category annotations. We present the solutions of top-5 teams participating in the JDDC multimodal dialogue challenge based on this dataset, which provides valuable insights for further researches on the multimodal dialogue task.
RoR: Read-over-Read for Long Document Machine Reading Comprehension
Sep 14, 2021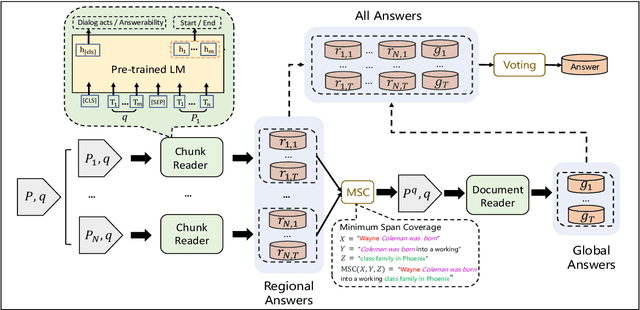
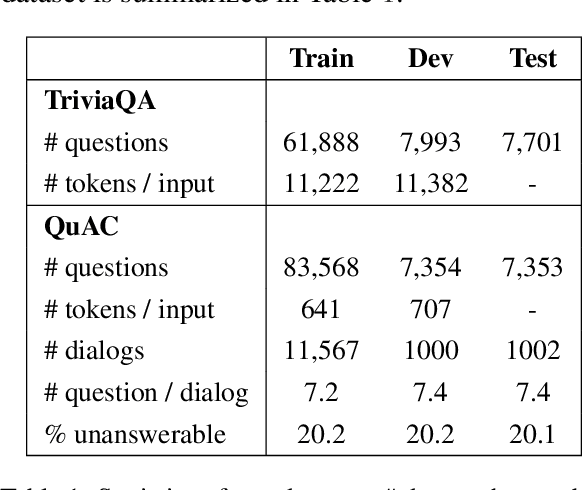
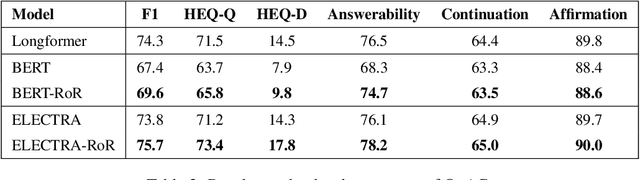
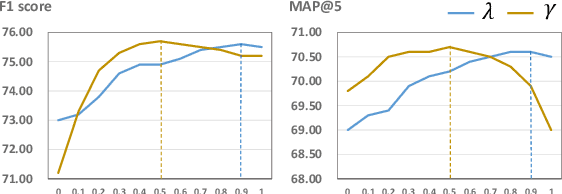
Transformer-based pre-trained models, such as BERT, have achieved remarkable results on machine reading comprehension. However, due to the constraint of encoding length (e.g., 512 WordPiece tokens), a long document is usually split into multiple chunks that are independently read. It results in the reading field being limited to individual chunks without information collaboration for long document machine reading comprehension. To address this problem, we propose RoR, a read-over-read method, which expands the reading field from chunk to document. Specifically, RoR includes a chunk reader and a document reader. The former first predicts a set of regional answers for each chunk, which are then compacted into a highly-condensed version of the original document, guaranteeing to be encoded once. The latter further predicts the global answers from this condensed document. Eventually, a voting strategy is utilized to aggregate and rerank the regional and global answers for final prediction. Extensive experiments on two benchmarks QuAC and TriviaQA demonstrate the effectiveness of RoR for long document reading. Notably, RoR ranks 1st place on the QuAC leaderboard (https://quac.ai/) at the time of submission (May 17th, 2021).
CUSTOM: Aspect-Oriented Product Summarization for E-Commerce
Aug 18, 2021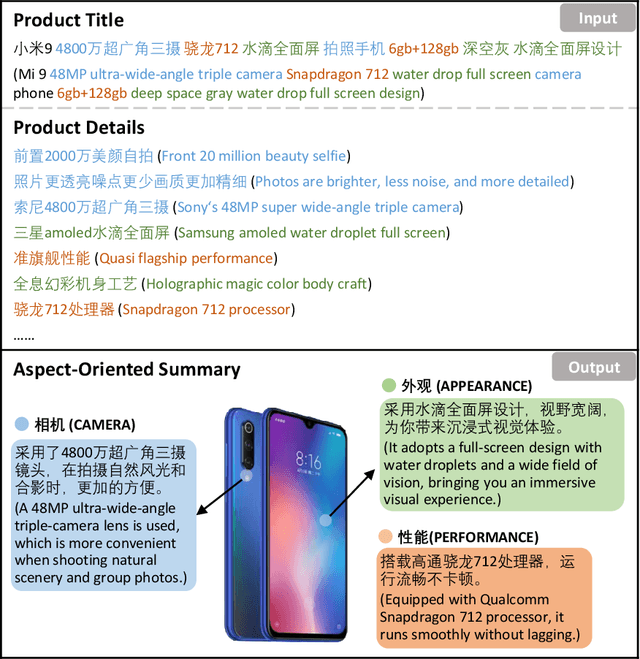
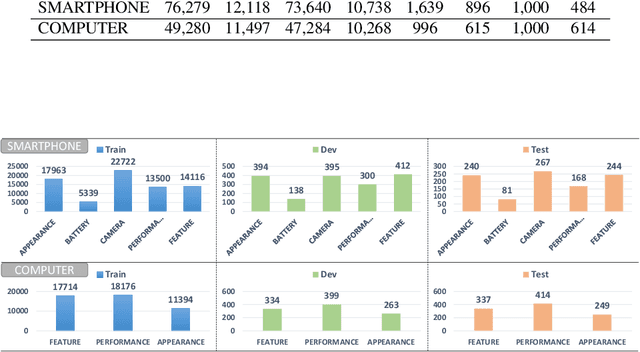
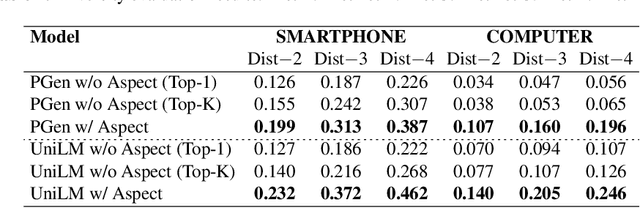
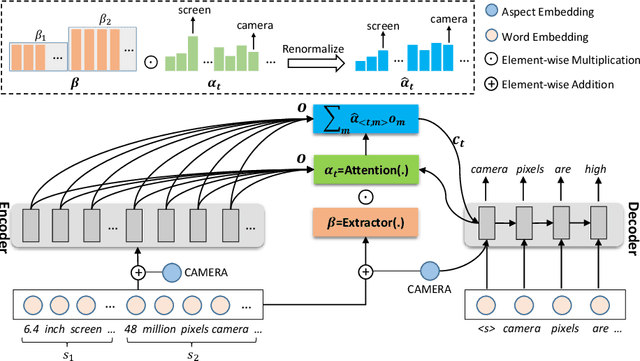
Product summarization aims to automatically generate product descriptions, which is of great commercial potential. Considering the customer preferences on different product aspects, it would benefit from generating aspect-oriented customized summaries. However, conventional systems typically focus on providing general product summaries, which may miss the opportunity to match products with customer interests. To address the problem, we propose CUSTOM, aspect-oriented product summarization for e-commerce, which generates diverse and controllable summaries towards different product aspects. To support the study of CUSTOM and further this line of research, we construct two Chinese datasets, i.e., SMARTPHONE and COMPUTER, including 76,279 / 49,280 short summaries for 12,118 / 11,497 real-world commercial products, respectively. Furthermore, we introduce EXT, an extraction-enhanced generation framework for CUSTOM, where two famous sequence-to-sequence models are implemented in this paper. We conduct extensive experiments on the two proposed datasets for CUSTOM and show results of two famous baseline models and EXT, which indicates that EXT can generate diverse, high-quality, and consistent summaries.
EviDR: Evidence-Emphasized Discrete Reasoning for Reasoning Machine Reading Comprehension
Aug 18, 2021
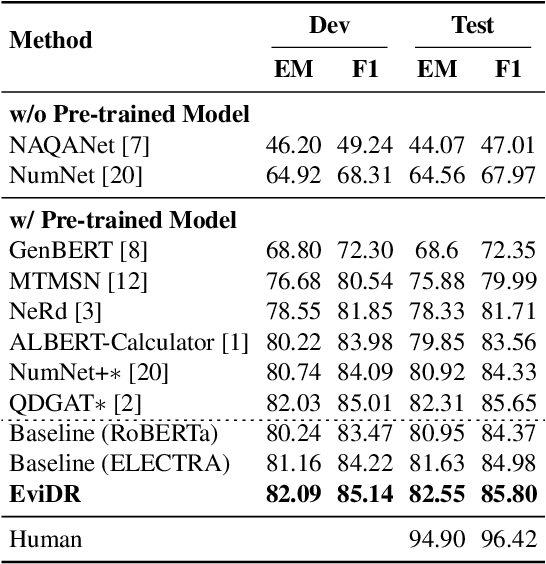
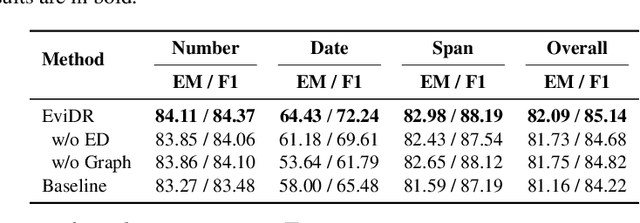

Reasoning machine reading comprehension (R-MRC) aims to answer complex questions that require discrete reasoning based on text. To support discrete reasoning, evidence, typically the concise textual fragments that describe question-related facts, including topic entities and attribute values, are crucial clues from question to answer. However, previous end-to-end methods that achieve state-of-the-art performance rarely solve the problem by paying enough emphasis on the modeling of evidence, missing the opportunity to further improve the model's reasoning ability for R-MRC. To alleviate the above issue, in this paper, we propose an evidence-emphasized discrete reasoning approach (EviDR), in which sentence and clause level evidence is first detected based on distant supervision, and then used to drive a reasoning module implemented with a relational heterogeneous graph convolutional network to derive answers. Extensive experiments are conducted on DROP (discrete reasoning over paragraphs) dataset, and the results demonstrate the effectiveness of our proposed approach. In addition, qualitative analysis verifies the capability of the proposed evidence-emphasized discrete reasoning for R-MRC.
RevCore: Review-augmented Conversational Recommendation
Jun 02, 2021
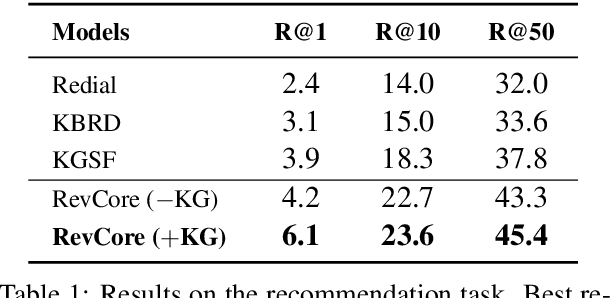
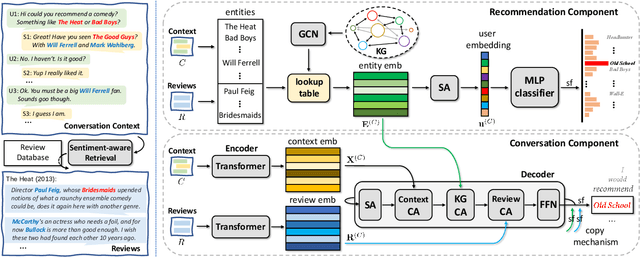
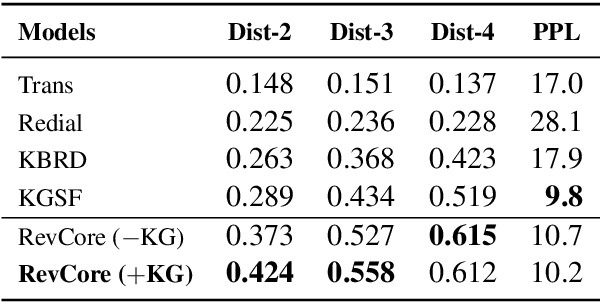
Existing conversational recommendation (CR) systems usually suffer from insufficient item information when conducted on short dialogue history and unfamiliar items. Incorporating external information (e.g., reviews) is a potential solution to alleviate this problem. Given that reviews often provide a rich and detailed user experience on different interests, they are potential ideal resources for providing high-quality recommendations within an informative conversation. In this paper, we design a novel end-to-end framework, namely, Review-augmented Conversational Recommender (RevCore), where reviews are seamlessly incorporated to enrich item information and assist in generating both coherent and informative responses. In detail, we extract sentiment-consistent reviews, perform review-enriched and entity-based recommendations for item suggestions, as well as use a review-attentive encoder-decoder for response generation. Experimental results demonstrate the superiority of our approach in yielding better performance on both recommendation and conversation responding.
Conversational AI Systems for Social Good: Opportunities and Challenges
May 13, 2021
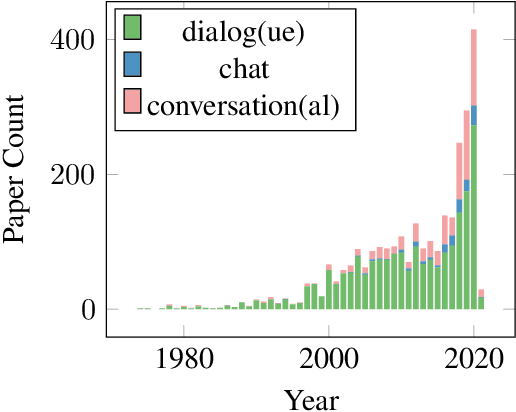
Conversational artificial intelligence (ConvAI) systems have attracted much academic and commercial attention recently, making significant progress on both fronts. However, little existing work discusses how these systems can be developed and deployed for social good. In this paper, we briefly review the progress the community has made towards better ConvAI systems and reflect on how existing technologies can help advance social good initiatives from various angles that are unique for ConvAI, or not yet become common knowledge in the community. We further discuss about the challenges ahead for ConvAI systems to better help us achieve these goals and highlight the risks involved in their development and deployment in the real world.
SGG: Learning to Select, Guide, and Generate for Keyphrase Generation
May 06, 2021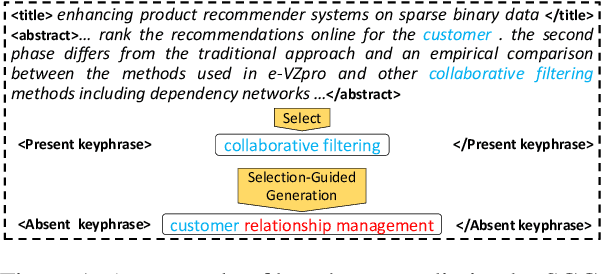
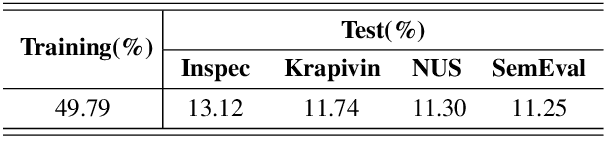
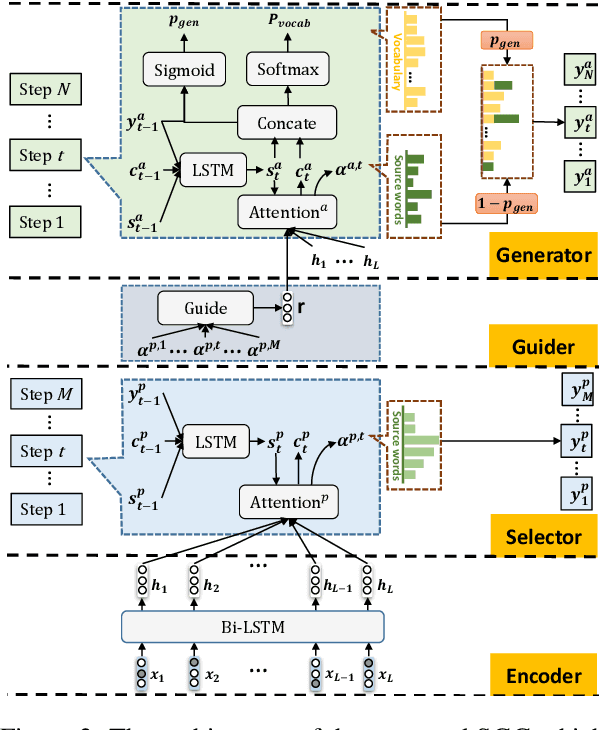
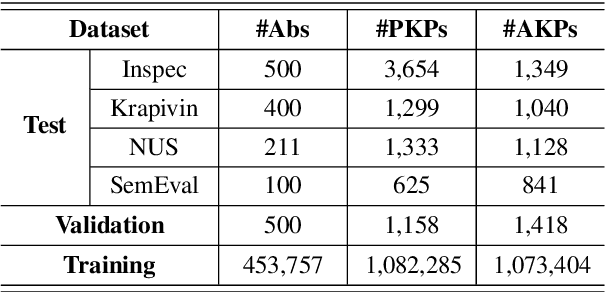
Keyphrases, that concisely summarize the high-level topics discussed in a document, can be categorized into present keyphrase which explicitly appears in the source text, and absent keyphrase which does not match any contiguous subsequence but is highly semantically related to the source. Most existing keyphrase generation approaches synchronously generate present and absent keyphrases without explicitly distinguishing these two categories. In this paper, a Select-Guide-Generate (SGG) approach is proposed to deal with present and absent keyphrase generation separately with different mechanisms. Specifically, SGG is a hierarchical neural network which consists of a pointing-based selector at low layer concentrated on present keyphrase generation, a selection-guided generator at high layer dedicated to absent keyphrase generation, and a guider in the middle to transfer information from selector to generator. Experimental results on four keyphrase generation benchmarks demonstrate the effectiveness of our model, which significantly outperforms the strong baselines for both present and absent keyphrases generation. Furthermore, we extend SGG to a title generation task which indicates its extensibility in natural language generation tasks.
K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce
Apr 14, 2021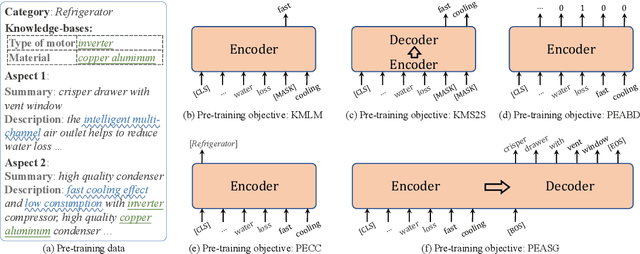
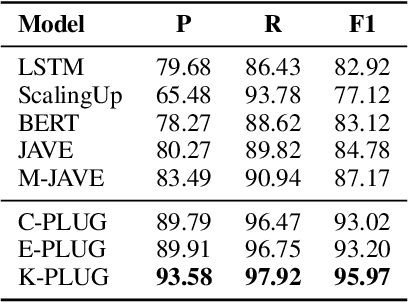
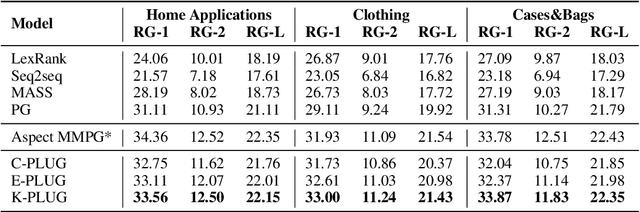
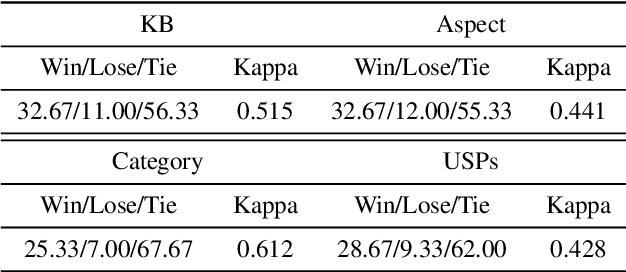
Existing pre-trained language models (PLMs) have demonstrated the effectiveness of self-supervised learning for a broad range of natural language processing (NLP) tasks. However, most of them are not explicitly aware of domain-specific knowledge, which is essential for downstream tasks in many domains, such as tasks in e-commerce scenarios. In this paper, we propose K-PLUG, a knowledge-injected pre-trained language model based on the encoder-decoder transformer that can be transferred to both natural language understanding and generation tasks. We verify our method in a diverse range of e-commerce scenarios that require domain-specific knowledge. Specifically, we propose five knowledge-aware self-supervised pre-training objectives to formulate the learning of domain-specific knowledge, including e-commerce domain-specific knowledge-bases, aspects of product entities, categories of product entities, and unique selling propositions of product entities. K-PLUG achieves new state-of-the-art results on a suite of domain-specific NLP tasks, including product knowledge base completion, abstractive product summarization, and multi-turn dialogue, significantly outperforms baselines across the board, which demonstrates that the proposed method effectively learns a diverse set of domain-specific knowledge for both language understanding and generation tasks.
Conversational Query Rewriting with Self-supervised Learning
Feb 19, 2021

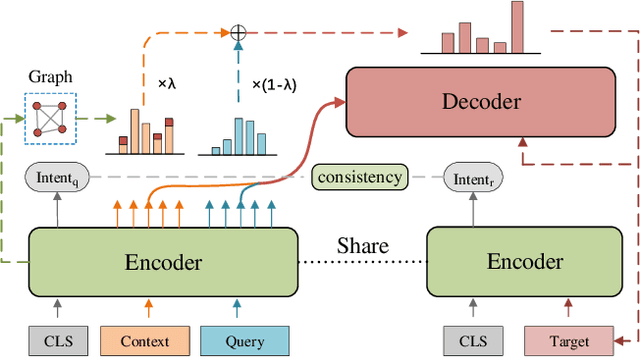
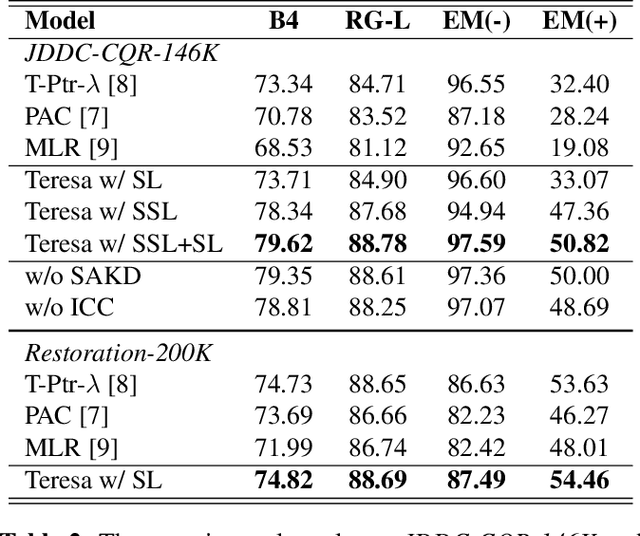
Context modeling plays a critical role in building multi-turn dialogue systems. Conversational Query Rewriting (CQR) aims to simplify the multi-turn dialogue modeling into a single-turn problem by explicitly rewriting the conversational query into a self-contained utterance. However, existing approaches rely on massive supervised training data, which is labor-intensive to annotate. And the detection of the omitted important information from context can be further improved. Besides, intent consistency constraint between contextual query and rewritten query is also ignored. To tackle these issues, we first propose to construct a large-scale CQR dataset automatically via self-supervised learning, which does not need human annotation. Then we introduce a novel CQR model Teresa based on Transformer, which is enhanced by self-attentive keywords detection and intent consistency constraint. Finally, we conduct extensive experiments on two public datasets. Experimental results demonstrate that our proposed model outperforms existing CQR baselines significantly, and also prove the effectiveness of self-supervised learning on improving the CQR performance.
Learning to Decouple Relations: Few-Shot Relation Classification with Entity-Guided Attention and Confusion-Aware Training
Oct 21, 2020
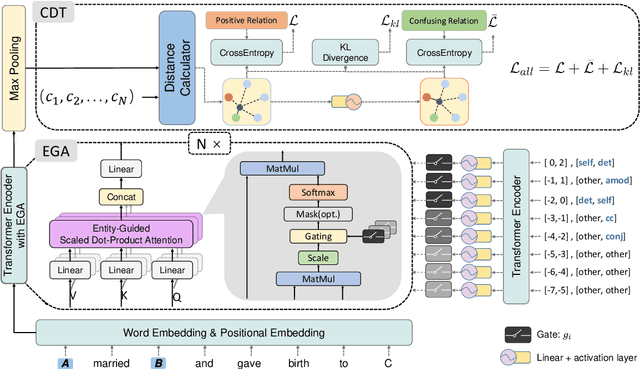


This paper aims to enhance the few-shot relation classification especially for sentences that jointly describe multiple relations. Due to the fact that some relations usually keep high co-occurrence in the same context, previous few-shot relation classifiers struggle to distinguish them with few annotated instances. To alleviate the above relation confusion problem, we propose CTEG, a model equipped with two mechanisms to learn to decouple these easily-confused relations. On the one hand, an Entity-Guided Attention (EGA) mechanism, which leverages the syntactic relations and relative positions between each word and the specified entity pair, is introduced to guide the attention to filter out information causing confusion. On the other hand, a Confusion-Aware Training (CAT) method is proposed to explicitly learn to distinguish relations by playing a pushing-away game between classifying a sentence into a true relation and its confusing relation. Extensive experiments are conducted on the FewRel dataset, and the results show that our proposed model achieves comparable and even much better results to strong baselines in terms of accuracy. Furthermore, the ablation test and case study verify the effectiveness of our proposed EGA and CAT, especially in addressing the relation confusion problem.