 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneity-Aware Asynchronous Decentralized Training
Sep 17, 2019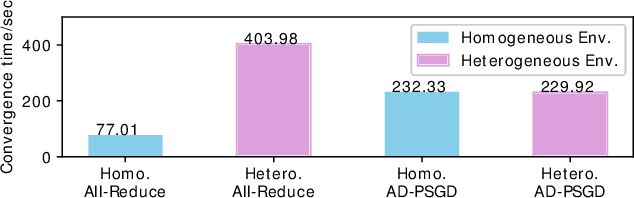
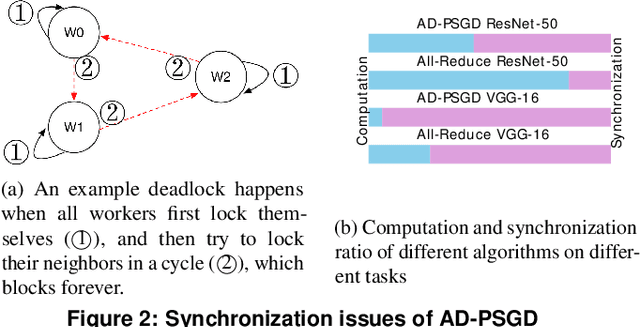
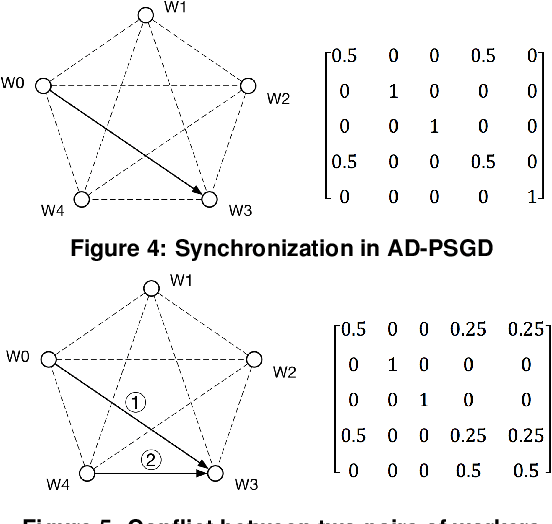
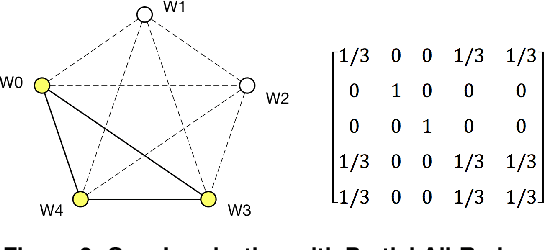
Distributed deep learning training usually adopts All-Reduce as the synchronization mechanism for data parallel algorithms due to its high performance in homogeneous environment. However, its performance is bounded by the slowest worker among all workers, and is significantly slower in heterogeneous situations. AD-PSGD, a newly proposed synchronization method which provides numerically fast convergence and heterogeneity tolerance, suffers from deadlock issues and high synchronization overhead. Is it possible to get the best of both worlds - designing a distributed training method that has both high performance as All-Reduce in homogeneous environment and good heterogeneity tolerance as AD-PSGD? In this paper, we propose Ripples, a high-performance heterogeneity-aware asynchronous decentralized training approach. We achieve the above goal with intensive synchronization optimization, emphasizing the interplay between algorithm and system implementation. To reduce synchronization cost, we propose a novel communication primitive Partial All-Reduce that allows a large group of workers to synchronize quickly. To reduce synchronization conflict, we propose static group scheduling in homogeneous environment and simple techniques (Group Buffer and Group Division) to avoid conflicts with slightly reduced randomness. Our experiments show that in homogeneous environment, Ripples is 1.1 times faster than the state-of-the-art implementation of All-Reduce, 5.1 times faster than Parameter Server and 4.3 times faster than AD-PSGD. In a heterogeneous setting, Ripples shows 2 times speedup over All-Reduce, and still obtains 3 times speedup over the Parameter Server baseline.
Hop: Heterogeneity-Aware Decentralized Training
Feb 07, 2019
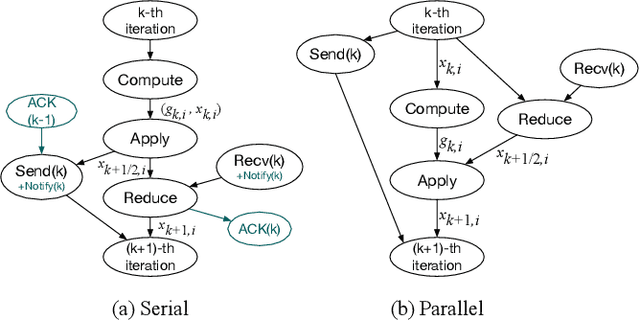
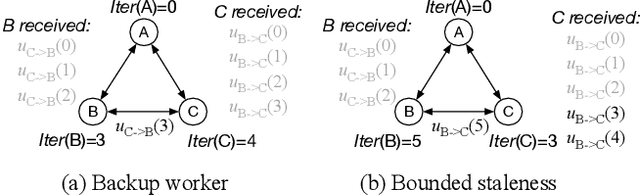

Recent work has shown that decentralized algorithms can deliver superior performance over centralized ones in the context of machine learning. The two approaches, with the main difference residing in their distinct communication patterns, are both susceptible to performance degradation in heterogeneous environments. Although vigorous efforts have been devoted to supporting centralized algorithms against heterogeneity, little has been explored in decentralized algorithms regarding this problem. This paper proposes Hop, the first heterogeneity-aware decentralized training protocol. Based on a unique characteristic of decentralized training that we have identified, the iteration gap, we propose a queue-based synchronization mechanism that can efficiently implement backup workers and bounded staleness in the decentralized setting. To cope with deterministic slowdown, we propose skipping iterations so that the effect of slower workers is further mitigated. We build a prototype implementation of Hop on TensorFlow. The experiment results on CNN and SVM show significant speedup over standard decentralized training in heterogeneous settings.
HyPar: Towards Hybrid Parallelism for Deep Learning Accelerator Array
Jan 07, 2019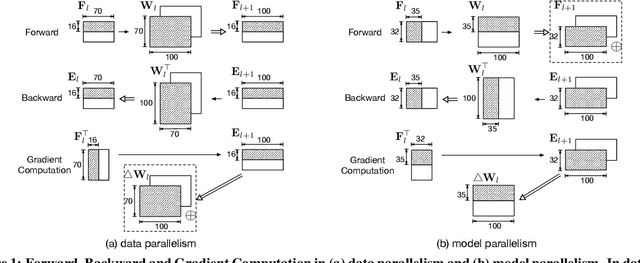
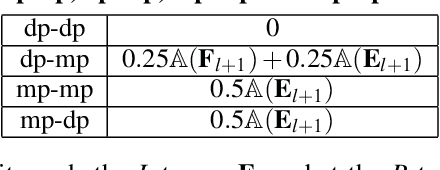
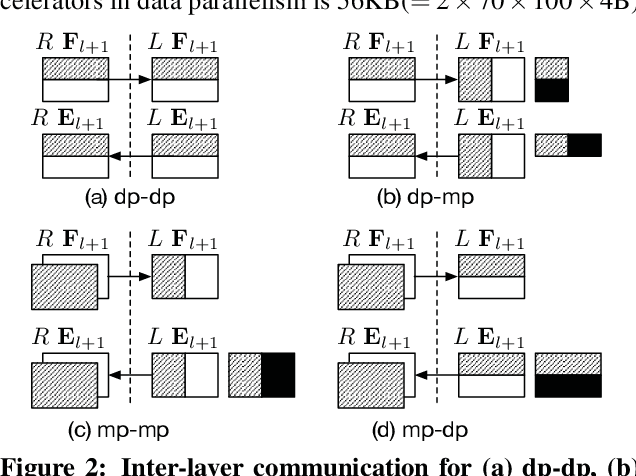
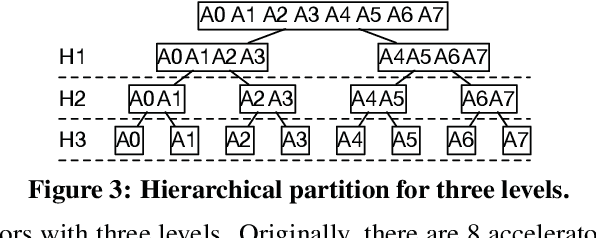
With the rise of artificial intelligence in recent years, Deep Neural Networks (DNNs) have been widely used in many domains. To achieve high performance and energy efficiency, hardware acceleration (especially inference) of DNNs is intensively studied both in academia and industry. However, we still face two challenges: large DNN models and datasets, which incur frequent off-chip memory accesses; and the training of DNNs, which is not well-explored in recent accelerator designs. To truly provide high throughput and energy efficient acceleration for the training of deep and large models, we inevitably need to use multiple accelerators to explore the coarse-grain parallelism, compared to the fine-grain parallelism inside a layer considered in most of the existing architectures. It poses the key research question to seek the best organization of computation and dataflow among accelerators. In this paper, we propose a solution HyPar to determine layer-wise parallelism for deep neural network training with an array of DNN accelerators. HyPar partitions the feature map tensors (input and output), the kernel tensors, the gradient tensors, and the error tensors for the DNN accelerators. A partition constitutes the choice of parallelism for weighted layers. The optimization target is to search a partition that minimizes the total communication during training a complete DNN. To solve this problem, we propose a communication model to explain the source and amount of communications. Then, we use a hierarchical layer-wise dynamic programming method to search for the partition for each layer.
E-RNN: Design Optimization for Efficient Recurrent Neural Networks in FPGAs
Dec 12, 2018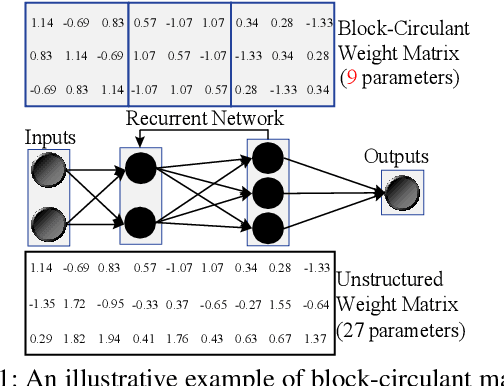

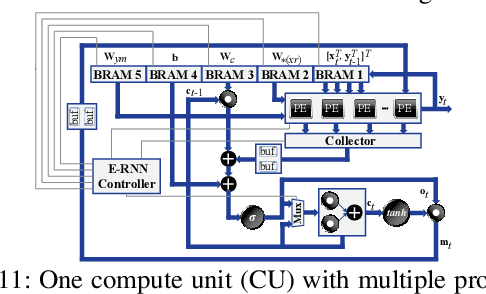
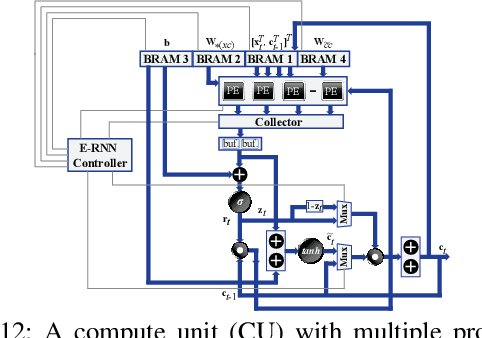
Recurrent Neural Networks (RNNs) are becoming increasingly important for time series-related applications which require efficient and real-time implementations. The two major types are Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks. It is a challenging task to have real-time, efficient, and accurate hardware RNN implementations because of the high sensitivity to imprecision accumulation and the requirement of special activation function implementations. A key limitation of the prior works is the lack of a systematic design optimization framework of RNN model and hardware implementations, especially when the block size (or compression ratio) should be jointly optimized with RNN type, layer size, etc. In this paper, we adopt the block-circulant matrix-based framework, and present the Efficient RNN (E-RNN) framework for FPGA implementations of the Automatic Speech Recognition (ASR) application. The overall goal is to improve performance/energy efficiency under accuracy requirement. We use the alternating direction method of multipliers (ADMM) technique for more accurate block-circulant training, and present two design explorations providing guidance on block size and reducing RNN training trials. Based on the two observations, we decompose E-RNN in two phases: Phase I on determining RNN model to reduce computation and storage subject to accuracy requirement, and Phase II on hardware implementations given RNN model, including processing element design/optimization, quantization, activation implementation, etc. Experimental results on actual FPGA deployments show that E-RNN achieves a maximum energy efficiency improvement of 37.4$\times$ compared with ESE, and more than 2$\times$ compared with C-LSTM, under the same accuracy.
CirCNN: Accelerating and Compressing Deep Neural Networks Using Block-CirculantWeight Matrices
Aug 29, 2017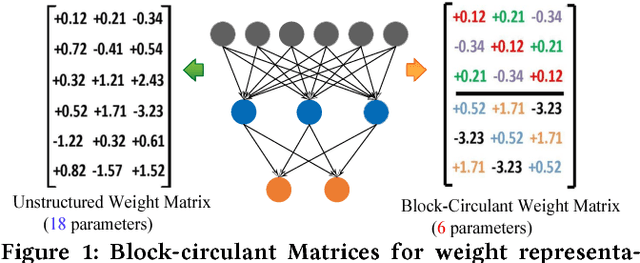
Large-scale deep neural networks (DNNs) are both compute and memory intensive. As the size of DNNs continues to grow, it is critical to improve the energy efficiency and performance while maintaining accuracy. For DNNs, the model size is an important factor affecting performance, scalability and energy efficiency. Weight pruning achieves good compression ratios but suffers from three drawbacks: 1) the irregular network structure after pruning; 2) the increased training complexity; and 3) the lack of rigorous guarantee of compression ratio and inference accuracy. To overcome these limitations, this paper proposes CirCNN, a principled approach to represent weights and process neural networks using block-circulant matrices. CirCNN utilizes the Fast Fourier Transform (FFT)-based fast multiplication, simultaneously reducing the computational complexity (both in inference and training) from O(n2) to O(nlogn) and the storage complexity from O(n2) to O(n), with negligible accuracy loss. Compared to other approaches, CirCNN is distinct due to its mathematical rigor: it can converge to the same effectiveness as DNNs without compression. The CirCNN architecture, a universal DNN inference engine that can be implemented on various hardware/software platforms with configurable network architecture. To demonstrate the performance and energy efficiency, we test CirCNN in FPGA, ASIC and embedded processors. Our results show that CirCNN architecture achieves very high energy efficiency and performance with a small hardware footprint. Based on the FPGA implementation and ASIC synthesis results, CirCNN achieves 6-102X energy efficiency improvements compared with the best state-of-the-art results.